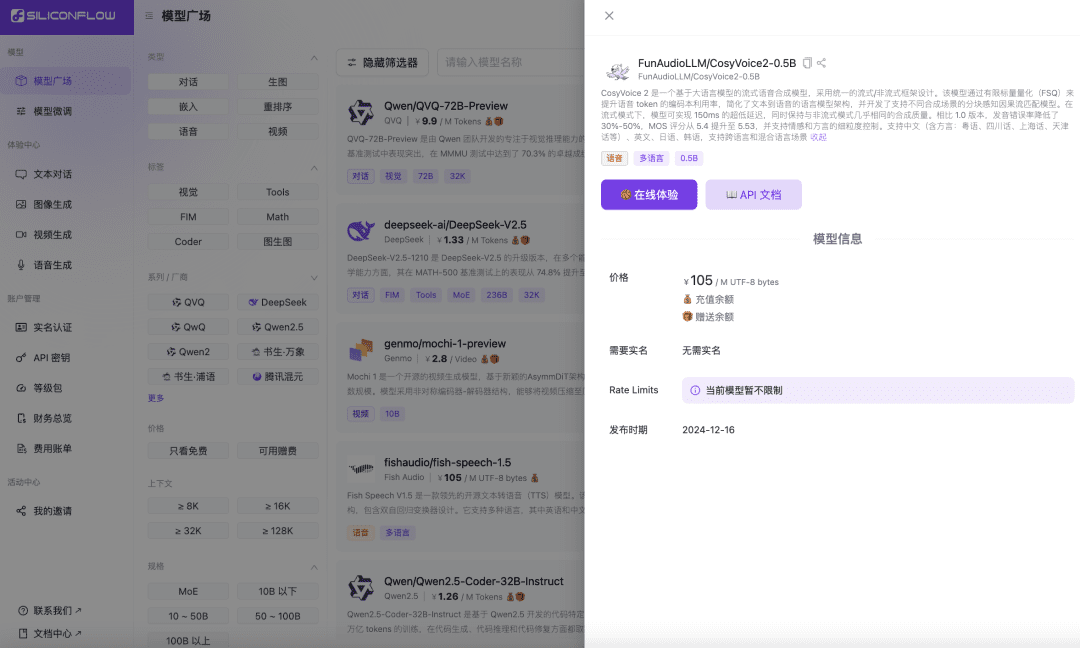
Kürzlich hat das Sprachteam von Ali Tongyi Lab offiziell das SprachsynthesemodellCosyVoice2. Das Modell unterstützt bidirektionales Streaming von Text und Sprache, unterstützt Mehrsprachigkeit, gemischte Sprachen und Dialekte und bietet genauere, stabilere, schnellere und bessere Spracherzeugungsfunktionen. Jetzt, Siliconcloud, die Silizium-basierte Flow Siliconcloud ist offiziell online mit der Inferenzbeschleunigung Version CosyVoice2-0.5B (Preis ¥105/ M UTF-8 Bytes, jedes Zeichen belegt 1 bis 4 Bytes), die die Netzwerkübertragungszeit, so dass das Modell Ausgabe Latenz so niedrig wie 150ms, bringt eine effizientere Benutzererfahrung für Ihre generative AI-Anwendungen. Wie andere Sprachsynthesemodelle auf SiliconCloud unterstützt CosyVoice2 8 voreingestellte Töne, vom Benutzer voreingestellte Töne und dynamische Töne sowie eine anpassbare Sprachrate, Audioverstärkung und Ausgangssample-Rate.
Online-Erfahrung
https://cloud.siliconflow.cn/playground/text-to-speech/17885302679
API-Dokumentation
https://docs.siliconflow.cn/api-reference/audio/create-speech
Machen Sie sich ein Bild von SiliconClouds argumentationsbeschleunigter Version von CosyVoice 2.0.
Kombiniert mit SiliconClouds zuvor liveAli-Spracherkennungsmodell SenseVoice-Small (kostenlos erhältlich)Mit Hilfe der Modell-API können Entwickler effizient End-to-End-Sprachinteraktionsanwendungen entwickeln, darunter Hörbücher, Streaming-Audioausgaben, virtuelle Assistenten und andere Anwendungen.
Modellmerkmale und Leistung
CosyVoice2 ist ein Streaming-Sprachsynthesemodell auf der Grundlage eines großen Sprachmodells, das in einem einheitlichen Streaming/Non-Streaming-Rahmen entwickelt wurde. Das Modell verbessert die Codebuchnutzung von Sprachtoken durch Finite-Skalar-Quantisierung (FSQ), vereinfacht die Architektur des Text-zu-Sprache-Sprachmodells und entwickelt ein Chunk-bewusstes kausales Stream-Matching-Modell, das verschiedene Syntheseszenarien unterstützt. Im Streaming-Modus erreicht das Modell eine extrem niedrige Latenzzeit von 150 ms, während es fast die gleiche Synthesequalität wie im Nicht-Streaming-Modus beibehält.
Darüber hinaus hat CosyVoice2 erhebliche Fortschritte bei der Integration des Basismodells und des Befehlsmodells gemacht und nicht nur die Unterstützung von Emotionen, Sprechstilen und feinkörnigen Steuerbefehlen fortgesetzt, sondern auch die Fähigkeit hinzugefügt, chinesische Befehle zu verarbeiten.
Im Einzelnen hat die Version 2.0 folgende Vorteile gegenüber der CosyVoice-Version 1.0:
Mehrsprachige Unterstützung
- Unterstützte Sprachen: Chinesisch, Englisch, Japanisch, Koreanisch, chinesische Dialekte (Kantonesisch, Sichuan, Shanghainesisch, Tianjin, Wuhan, usw.)
- Sprachübergreifend und gemischt-sprachig: Unterstützt das Klonen von Null-Sample-Sprache in sprachübergreifenden und Code-Switching-Szenarien.
ultraniedrige Latenzzeit
- Bi-direktionale Streaming-Unterstützung: CosyVoice 2.0 integriert Offline- und Streaming-Modellierungstechnologien.
- Schnelle Synthese des ersten Pakets: Erzielen Sie Verzögerungen von nur 150 Millisekunden bei gleichbleibend hoher Audioqualität.
äußerst präzise
- Verbesserung der Aussprache: Aussprachefehler wurden im Vergleich zu CosyVoice 1.0 um 30% bis 50% reduziert.
- Benchmark-Ergebnis: Erreichen der niedrigsten Zeichenfehlerrate auf dem schwierigen Testsatz des Seed-TTS-Evaluierungssatzes.
hohe Stabilität
- Tonkonsistenz: Sorgt für zuverlässige Tonkonsistenz bei der Null-Sample- und sprachübergreifenden Sprachsynthese.
- Sprachübergreifende Synthese: wesentliche Verbesserungen gegenüber Version 1.0.
natürliche Geläufigkeit
- Rhythmische und klangliche Verbesserung: Erhöhung der MOS-Bewertungsnote von 5,4 auf 5,53.
- Emotions- und Dialektflexibilität: Unterstützt eine feinere Emotionskontrolle und die Anpassung des Dialektakzents.
Bewertung der Entwickler
Nach der Veröffentlichung von CosyVoice 2.0 haben einige Entwickler erste Erfahrungen damit gemacht. Einige Entwickler sagten, dass es ultrafeine Steuerungsfunktionen und eine realistischere und natürlichere Sprachsynthese unterstützt. 
 Einige Benutzer sagten jedoch, dass die Bereitstellung eine große Herausforderung darstellte, obwohl sie von der hervorragenden Sprachgenerierungsleistung überzeugt waren.
Einige Benutzer sagten jedoch, dass die Bereitstellung eine große Herausforderung darstellte, obwohl sie von der hervorragenden Sprachgenerierungsleistung überzeugt waren.  Jetzt, da Siliconcloud mit CosyVoice 2.0 live gegangen ist und die Notwendigkeit komplexer Implementierungen entfällt, können Sie einfach die API aufrufen und auf Ihre eigenen Anwendungen zugreifen.
Jetzt, da Siliconcloud mit CosyVoice 2.0 live gegangen ist und die Notwendigkeit komplexer Implementierungen entfällt, können Sie einfach die API aufrufen und auf Ihre eigenen Anwendungen zugreifen.
Token Factory SiliconCloud Qwen 2.5 (7B) und 20+ andere Modelle kostenlos!
Als One-Stop-Big-Model-Cloud-Service-Plattform ist SiliconCloud bestrebt, Entwicklern extrem reaktionsschnelle, erschwingliche, vollständige und seidenweiche Modell-APIs zur Verfügung zu stellen. Zusätzlich zu CosyVoice2 hat SiliconCloud bereits eine Reihe von Modell-APIs veröffentlicht, darunter QVQ-72B-Preview, DeepSeek-VL2, DeepSeek- V2.5-1210, mochi-1-Vorschau, Llama-3.3-70B-Instruct, HunyuanVideo, fish-speech-1.5, QwQ-32B-Vorschau, Qwen2.5-Coder-32B-Instruct, InternVL2 Qwen2.5-7B/14B/32B/72B, FLUX.1, InternLM2.5-20B-Chat, BCE, BGE, SenseVoice-Small, GLM-4-9B-Chat und Dutzende von quelloffenen großen Sprachmodellen, Bild-/Videogenerierungsmodellen, Sprachmodellen, Code-/Mathematikmodellen und Vektor und Umordnungsmodelle.  Qwen2.5 (7B), Llama3.1 (8B) und weitere 20+ große Modell-APIs können kostenlos genutzt werden, so dass sich Entwickler und Produktmanager keine Gedanken über die rechnerischen Kosten für die Forschungs- und Entwicklungsphase und die groß angelegte Werbung machen müssen und die "Token Freedom" verwirklichen können.
Qwen2.5 (7B), Llama3.1 (8B) und weitere 20+ große Modell-APIs können kostenlos genutzt werden, so dass sich Entwickler und Produktmanager keine Gedanken über die rechnerischen Kosten für die Forschungs- und Entwicklungsphase und die groß angelegte Werbung machen müssen und die "Token Freedom" verwirklichen können.