

Experiment: Umwandlung von WordPress-Seiteninhalten in die "Wissensdatenbank" eines KI-Assistenten

ein Faktor (der eine Wirkung hat)
Der Chief AI Sharing Circle hat eine Vielzahl von "praktischen Befehlen" und verschiedenen "KI-Tools" zusammengestellt, die auf der Website unter folgender Adresse zu finden sindStichwortBei der Suche konnte die benötigte Ressource nicht genau gefunden werden. Die Website ist voll von ausgezeichnetenVideo-Tools generierenDie Unfähigkeit, gefunden zu werden, ist unerträglich.

Da wir nicht in der Lage sind, eine Website zu entwickeln, können wir uns bei der Suche auf externe Funktionen verlassen:
Sich darauf zu verlassen, dass die Suchmaschine die "Site Search"-Methode verwendet, um das Problem zu lösen, scheint etwas umständlich zu sein, und der Inhalt ist nicht im Ganzen enthalten:

Oder geben Sie einfach ein: site:aisharenet.com SEO
Natürlich bin ich nicht in der Lage, Website-Inhalte direkt in die semantische Suche umzuwandeln und eine gute Schnittstelle dafür bereitzustellen, daher liegt das Problem im Kern:
Wie man Website-Inhalte in eine leicht abrufbare Wissensdatenbank umwandelt.
Inhaltsanalyse
Die KI-Tools und die Anleitungen zu ihrer Verwendung im Kopfbereich beschreiben weitgehend klar ihre inhaltlichen Merkmale, während der Inhaltsbereich, obwohl er ausführlicher dargestellt wird, eher alsUnterbrechungenText, was die Qualität des Abrufs beeinträchtigt. Außerdem enthält der Inhalt Bilder, die ich den Lesern gerne in einer Vorschau zeigen möchte.
Beispiele für den Inhalt von AI-Tools

Beispiel für die Verwendung des Inhalts eines Befehls

Nachdenken über Suchstrategien
1. der Titel und der Inhalt werden als ganzer Absatz gemischt, um an der semantischen Suche teilzunehmen
Vorteile: Vollständiger Inhalt
Nachteile: Zu viele Inhalte führen zu ungenauen Suchen
2. nur den Titel abrufen und dann das inhaltliche Wissen auf der Grundlage des Titels zitieren
Vorteil: genaue Suche
Nachteile: Eingeschränkter effektiver Suchumfang
3. den Titel und den Inhalt in das große Modell eingeben und in QA-Paare aufteilen
Vorteil: Erhebliche Verbesserung der effektiven Suchreichweite
Nachteile: Höhere Bearbeitungskosten und Zeitaufwand; wichtige Inhalte und Strukturen des Originaltextes gehen verloren
PS: Sie brauchen keine Entwicklungserfahrung, können Sie das DIFY-Projekt Batch-Generierung von QA-Paare, nicht hier demonstriert bereitstellen.
4. die Kartierung von Wissen
Inhalt nicht geeignet, ignorieren.
Ich werde mich auf freie und offene Plattformen zur Bearbeitung von Intelligenzen verlassen, die auch keine Wissensgraphen unterstützen.
Der selektive Abruf2 ist einfach und effizient. Obwohl der effektive Abrufbereich reduziert ist, kann er durch kontinuierliche Iteration schrittweise optimiert werden.
Das Inhaltssubjekt muss auch nicht wirklich an der Abfrage beteiligt sein, solange es der Semantik folgt, um dieBildunterschriftDadurch wird die Anzahl der Ausnahmen reduziert, die durch das große Modell bei langen Kontexten erzeugt werden, und die Rückgabe der URL ermöglicht ein vollständigeres Lesen.
Suche Tool Carrier
Welche Drei-Wege-Plattform wird für die Umsetzung der semantischen Suche verwendet?
Es gibt viele kostenlose Plattformen auf dem Markt, die Wissensdatenbanken unterstützen, z. B. MetaBase, Smart Spectrum, Buckle und Wenshin. Hier werde ich die Plattform auswählen, die den Import von QA-Paaren zum Abruf unterstützt.
Abrufen von QA-Paaren: Rückgabe der Antwort B zu Frage A durch Zurückholen von Frage A in das große Modell und Verwendung von B als Referenzinhalt zur Beantwortung der Frage des Benutzers.
Welche Plattform besser ist, welches semantische Verständnis besser ist, wird hier nicht betrachtet, ihre grundsätzliche Leistungsfähigkeit wird grundsätzlich als ausreichend angesehen.
Wo verwenden die Nutzer es?
Der Haupt-Push ist öffentlich, d. h., die Nutzer können in der Öffentlichkeit suchen.
Smart Spectrum ist gut, aber ich entscheide mich für Wenxin Intelligent Body, das klarere Anweisungen für die Handhabung von QA-Regeln hat. Gleichzeitig kann Wenshin Intelligent Body auf Baidu veröffentlicht werden, um Kunden zu gewinnen. Empfohlene Lektüre:Killer Traffic Portal: Mit AI Intelligent Body langfristig externen Traffic für Websites und öffentliche Telefonnummern erhalten
Anleitung zur Bedienung
1. exportieren Sie XML-Dateien aus WordPress

2. die XML-Konvertierung in das MD-Format
2.1 Klicken Sie hier zum Herunterladenblog2md-Projekt(math.) GattungEntpacken Sie in das Verzeichnis D:\222\blog2md
2.2 Öffnen Sie das SHELL-Terminal, indem Sie mit der rechten Maustaste am Anfang des blog2md-Verzeichnisses klicken.

2.3 Wahrscheinlich müssen Sie die Abhängigkeiten installieren, geben Sie den folgenden Befehl ein
安装命令: npm install xml2js 验证命令: npm list xml2js
2.4 Benennen Sie die exportierte XML-Datei 111.xml, legen Sie sie im Verzeichnis D:\222\blog2md ab und führen Sie den folgenden Befehl aus
node index.js w 111.xml out
2.5 An dieser Stelle wird das Verzeichnis D:\222\blog2md\out generiert, und Sie können überprüfen, ob der generierte Inhalt korrekt ist, nachdem Sie ihn eingegeben haben.


3.MD EXCEL-Format konvertieren
Das md-Inhaltsgitter ist so strukturiert, dass es gut zu extrahieren ist, hier schreibe ich ein Regular in chatgpt und führe es in Python aus.
Ich möchte Folgendes extrahieren: Dateiname (der Dateiname ist die URL, z. B. https://aisharenet.com/anse/), Titel, Inhaltsbereich (--- der Inhalt darunter)
3.1 Nach dem Ausführen des Python-Skripts wird die Datei output.xlsx im aktuellen Verzeichnis erzeugt.

Inhalt des Drehbuchs:
Speichern Sie die Skriptdatei unter einem beliebigen Namen: 111.py und legen Sie das Skript in einem beliebigen Verzeichnis ab, hier in D:\222\blog2md.
Über die Befehlszeile ausführen (die Standardbefehlszeile kann 111.pt nicht direkt ausführen, Sie müssen das Präfix . \-Präfix hinzufügen)
.\111.py
Der Code der Skriptdatei lautet wie folgt, bitte speichern Sie ihn als 111.py (generiert von CHATGPT)
Verzeichnis zum Lesen von md-Dateien: folder_path = "D:\\222\\blog2md\\out"
EXCEL im aktuellen Verzeichnis generieren: output_file = "output.xlsx"
import os
import pandas as pd
import re
import html
def clean_content(content):
# 移除 Markdown 语法中的特殊字符
content = re.sub(r'[*_~`#]', '', content)
# 将 HTML 实体转换为对应字符
content = html.unescape(content)
# 移除可能导致 Excel 问题的字符
content = ''.join(char for char in content if ord(char) < 65536)
# 替换换行符为空格
content = content.replace('\n', ' ').replace('\r', '')
# 移除多余的空格
content = re.sub(r'\s+', ' ', content).strip()
return content
def md_to_excel(folder_path, output_file):
data = []
for filename in os.listdir(folder_path):
if filename.endswith(".md"):
file_path = os.path.join(folder_path, filename)
try:
with open(file_path, "r", encoding="utf-8") as file:
content = file.read()
# 使用正则表达式提取元数据
metadata_pattern = r"---\n(.*?)\n---"
metadata_match = re.search(metadata_pattern, content, re.DOTALL)
if metadata_match:
metadata = metadata_match.group(1)
title = re.search(r"title:\s*['\"](.*?)['\"]", metadata)
title = title.group(1) if title else ""
# 提取内容部分
content_pattern = r"---\n.*?\n---\n\n(.*)"
content_match = re.search(content_pattern, content, re.DOTALL)
text_content = content_match.group(1) if content_match else ""
# 清理内容
cleaned_content = clean_content(text_content)
# 获取文件名(不包含.md后缀)作为URL
url = os.path.splitext(filename)[0]
data.append({
"title": title,
"content": cleaned_content,
"url": url
})
except Exception as e:
print(f"Error processing file {filename}: {str(e)}")
# 将数据转换为DataFrame并保存为Excel文件
df = pd.DataFrame(data)
try:
df.to_excel(output_file, index=False, engine='openpyxl')
print(f"Successfully saved to {output_file}")
except Exception as e:
print(f"Error saving Excel file: {str(e)}")
# 尝试使用 CSV 格式保存
csv_file = output_file.rsplit('.', 1)[0] + '.csv'
df.to_csv(csv_file, index=False, encoding='utf-8-sig')
print(f"Saved as CSV instead: {csv_file}")
# 指定Markdown文件所在的目录和输出的Excel文件路径
folder_path = "D:\\222\\blog2md\\out"
output_file = "output.xlsx"
# 调用函数进行转换
md_to_excel(folder_path, output_file)
3.2 Zusammenstellen der Datei output.xlsx als hochzuladende Wissensdatenbank
Hier wird nur der Titel beibehalten und die vollständige URL herausgeschnitten.

4. die von der intelligenten Einrichtung Manxim hochgeladene Wissensdatenbank
4.1 Zugriff auf den Literacy Mind Intelligence Body und Hochladen der Wissensbasis

4.2 Hochladen von EXCEL-Dateien

4.3 Benutzerdefinierte Suchspalten (dies ist der Grund für den Einsatz von Wenshin Intelligence, anderen Tools fehlt diese Schnittstelle)

Weitere Tipps zur Organisation Ihrer Wissensdatenbank finden Sie hier:Literary Mind Intelligence Body Tutorial: (4) Verarbeitung von Dokumenten und Synchronisierung mit der Wissensdatenbank
5 Intelligenzen schaffen und zur Nutzung veröffentlichen
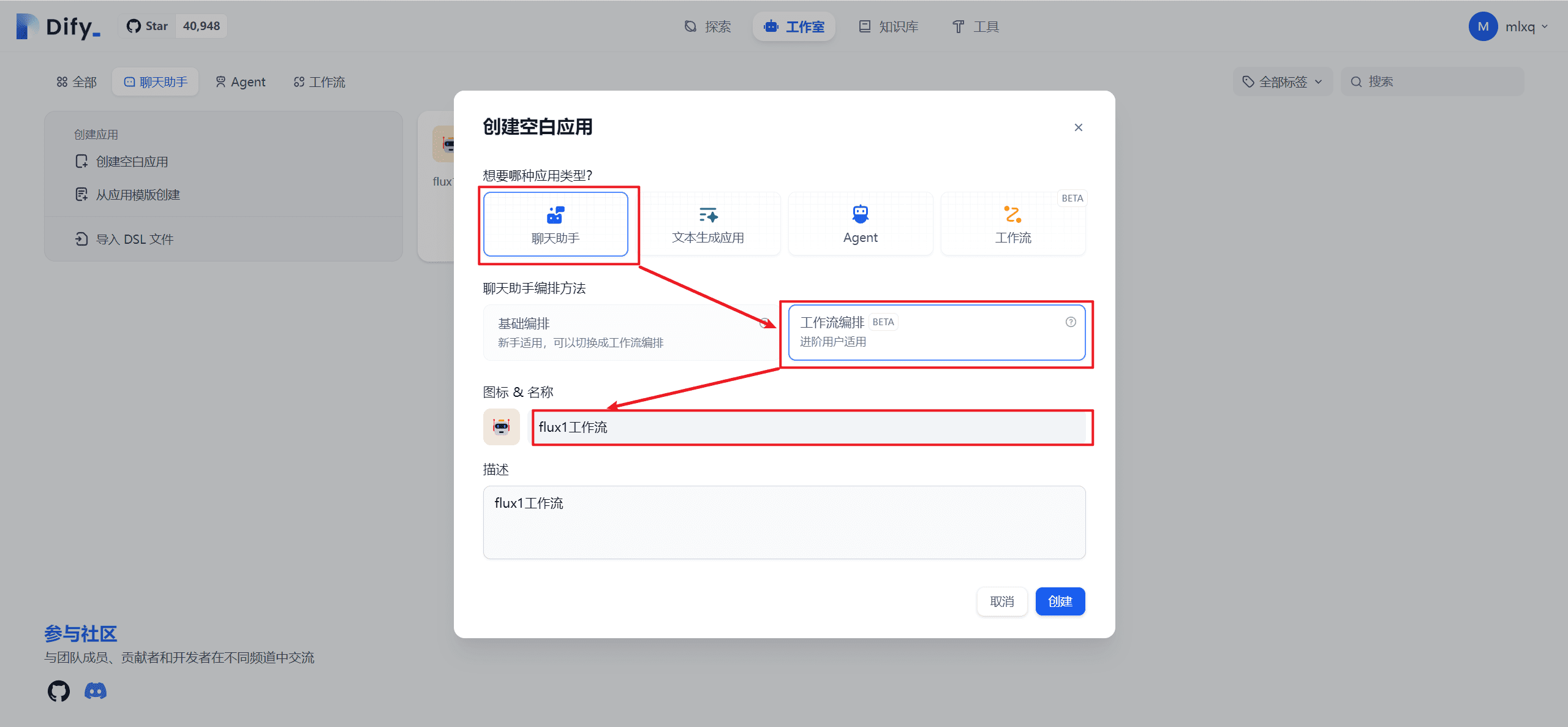
5.1 Intelligenz schaffen
Hier werden wir sie einfach konfigurieren, ohne uns in die Einzelheiten zu vertiefen. Wir beginnen mit der Erstellung von Intelligenzen...
Sie können versuchen, Low-Code-Modus zu verwenden, um intelligente Körper zu schaffen, indem mehrere Wissensbasis Urteil Logik, nachdem alle, die Website hat viele Kanäle Nun, ich werde hier nicht demonstrieren, interessiert sich für Low-Code-Freunde können lesen:Wenxin Intelligent Body Tutorial: (V) Choreografieren von Workflows für intelligente Körper

5.2 Intelligentsia konfigurieren
Deaktivieren Sie die Funktionen, die nicht zur Wissensbasis gehören, um Anomalien zu vermeiden, und lassen Sie die anderen Einstellungen ohne Feinabstimmung auf den Standardwerten.

Die Trefferquote der abgerufenen Wissensbasis sollte kurz getestet werden, da es sonst leicht zu irrelevanten Inhalten kommt.

5.3 Fehlersuche und Vorschau der Ausgabe

5.4 Verlagsintelligenz

ultimativ
Am Ende erhalten Sie einen intelligenten Körper, der schnell nach KI-Tools in der Öffentlichkeit suchen kann - und das alles kostenlos! In der Zwischenzeit, basierend auf dem Wenxin Smartbody Vertriebskanal ( Wenxin Intelligent Body Platform: Intelligente Körperanwendungen auf der Grundlage vollständiger Vertriebskanäle und kommerzieller Verschlüsse ), wird dieses Tool auf der Baidu-Homepage veröffentlicht, um den Nutzern den Zugang zu ermöglichen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...