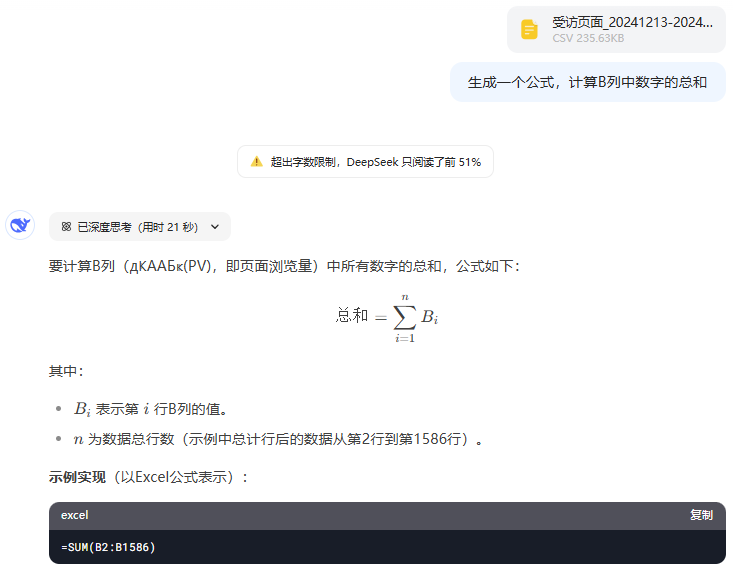
KI zum Innehalten und Nachdenken bringen: Wie Anthropics "Think"-Tool das Claude Reasoning verbessert

Kürzlich hat Anthropic ein neues Tool namens "think" eingeführt, das dazu dient, die Claude Modelle bei der Lösung komplexer Probleme. In diesem Beitrag werden wir uns mit den Designkonzepten, der Leistung und den besten Praktiken des "Think"-Tools in realen Anwendungen befassen und seine potenziellen Auswirkungen auf die zukünftige Entwicklung von KI-Systemen analysieren.
Das "Denk"-Werkzeug: Claude soll zum Innehalten und Nachdenken gebracht werden.
Um Claudes Fähigkeit, komplexe Probleme zu lösen, weiter zu verbessern, hat Anthropic einen einfachen, aber effektiven Weg gefunden: die Einführung des "Denk"-Werkzeugs. Das "think"-Werkzeug bietet Claude einen eigenen Raum für strukturiertes Denken bei der Arbeit an komplexen Aufgaben.
Es ist erwähnenswert, dass das "think"-Tool ähnlich wie Claudes früheres "erweitertes DenkenDie Funktion von "Expanded Thinking" ist anders. "Expanded Thinking" betont die Rolle von Claude bei der Erzeugung von Antworten. im Vorfeld von tiefgreifendem Denken und iterativer Planung. Und das "think"-Tool wurde in Claude entwickelt Nachdem Sie mit der Erstellung der Antwort begonnen haben Fügen Sie einen Schritt hinzu, damit er innehält und überlegt, ob er alle notwendigen Informationen hat, um weiterzumachen. Dies ist besonders nützlich, wenn lange Werkzeugaufrufketten durchgeführt werden oder wenn ein mehrstufiger Dialog mit den Benutzern geführt wird.
Im Gegensatz dazu eignet sich das "Think"-Tool besser für Situationen, in denen Claude nicht alle erforderlichen Informationen allein aus Benutzeranfragen erhalten kann und externe Informationen (z. B. die Ergebnisse von Tool-Aufrufen) verarbeiten muss. Die vom "think"-Tool durchgeführten Überlegungen sind nicht so umfassend wie die des "erweiterten Denkens" und konzentrieren sich eher auf die Modellfindung der meso- (Chemie) Informationen.
Anthropisch "Erweitertes Denken" wird für einfachere Szenarien der Werkzeugnutzung empfohlen, z. B. für nicht-sequentielle Werkzeugaufrufe oder das direkte Befolgen von Anweisungen. "Erweitertes Denken" eignet sich auch für Szenarien, in denen Claude keine Werkzeuge aufrufen muss, wie z. B. beim Programmieren, in Mathematik und Physik. think"-Werkzeuge eignen sich besser für Szenarien, in denen Claude komplexe Werkzeuge aufrufen, die Ergebnisse von Werkzeugen in langen Ketten von Werkzeugaufrufen sorgfältig analysieren, in einer Strategieumgebung mit detaillierten Richtlinien navigieren oder sequenzielle Entscheidungen treffen muss, bei denen jeder Schritt auf dem vorherigen aufbaut (und Fehler teuer sind).
Nachfolgend finden Sie eine Liste der häufigsten Verwendungsmöglichkeiten der τ-Bank Beispiel für die Implementierung eines Standardformats für Werkzeugspezifikationen:
{
"name": "think",
"description": "使用该工具进行思考。它不会获取新信息或更改数据库,只会将想法附加到日志中。在需要复杂推理或某些缓存记忆时使用。",
"input_schema": {
"type": "object",
"properties": {
"thought": {
"type": "string",
"description": "一个需要思考的想法。"
}
},
"required": ["thought"]
}
}
τ-Bench Performance Test: Signifikante Verbesserung
Um die Leistung des "think"-Werkzeugs zu bewerten, testete Anthropic es mit der τ-Bench (tau-bench), einem umfassenden Benchmark, der die Fähigkeit eines Modells zur Nutzung des Werkzeugs in realistischen Kundendienstszenarien testen soll, wobei das "think"-Werkzeug Teil der Standardumgebung für die Bewertung ist.
Der vom Sierra Research Team entwickelte und kürzlich veröffentlichte τ-Bench konzentriert sich auf die Bewertung der Fähigkeiten von Claude in den folgenden Bereichen:
- Simulieren Sie echte Benutzerdialoge.
- Befolgen Sie den Leitfaden zur Strategie für komplexe Kundendienstmitarbeiter.
- Zugang zu und Bearbeitung von Umweltdatenbanken mit Hilfe verschiedener Tools.
Der wichtigste Bewertungsmaßstab von τ-Bench ist passkDie pass@k-Metrik misst die Wahrscheinlichkeit, dass alle k unabhängigen Aufgabenversuche in einer bestimmten Aufgabe erfolgreich sind, gemittelt über alle Aufgaben. Im Gegensatz zur pass@k-Metrik (die den Erfolg von mindestens einem von k Versuchen misst), die in anderen LLM-Bewertungen üblich ist, ist passk Die Bewertung bezieht sich auf Konsistenz und Verlässlichkeit - ein entscheidender Faktor für Anwendungen im Kundenservice, bei denen es wichtig ist, dass die Richtlinien immer eingehalten werden.
Leistungsanalyse
In der Bewertung von Anthropic wurden die folgenden verschiedenen Konfigurationen verglichen:
- Baseline (kein "Think"-Tool, keine erweiterte Denkweise)
- Nur erweiterte Denkweise
- nur "think"-Werkzeug
- "think"-Tool mit Optimierungstipps (für die Luftfahrt)
Die Ergebnisse zeigen, dass, wenn das Claude 3.5 Sonnet-Modell das "think"-Tool effektiv einsetzt, signifikante Verbesserungen sowohl in den "Airline"- als auch in den "Retail"-Kundenservicebereichen des Benchmarks erzielt werden:
- LuftfahrtDas "think"-Tool mit Optimierungshinweisen ist in pass verfügbar.1 Indikator erreichte einen Wert von 0,570 im Vergleich zu 0,370 bei Studienbeginn, was einer relativen Verbesserung von 541 TP3T entspricht.
- EinzelhandelDas Tool "think" allein erreicht einen Wert von 0,812, verglichen mit dem Ausgangswert von 0,783.

Die folgende Tabelle zeigt die Daten für das Modell Claude 3.5 Sonnet für vier verschiedene Konfigurationen der Domäne "Aeronautical", die von τ-Bench ausgewertet wurden:
| konfigurieren. | k =1 | k =2 | k =3 | k =4 | k =5 |
|---|---|---|---|---|---|
| "Denken" + Stichwort Optimierung | 0.584 | 0.444 | 0.384 | 0.356 | 0.340 |
| Nur "Think"-Werkzeug | 0.404 | 0.254 | 0.186 | 0.140 | 0.100 |
| Erweitertes Denken | 0.412 | 0.290 | 0.232 | 0.192 | 0.160 |
| Basislinie (in der geodätischen Vermessung) | 0.332 | 0.206 | 0.148 | 0.116 | 0.100 |
In der Luftfahrt kann eine optimale Leistung erzielt werden, indem das "Think"-Tool mit optimierten Stichworten kombiniert wird. Optimierte Schlagwörter sind Beispiele für Argumentationsmethoden, die bei der Analyse von Kundenanfragen verwendet werden. Im Folgenden finden Sie Beispiele für optimierte Stichworte:
## 使用 think 工具
在采取任何行动或在收到工具结果后回应用户之前,使用 think 工具作为草稿板来:
- 列出适用于当前请求的具体规则
- 检查是否收集了所有必需的信息
- 验证计划的操作是否符合所有策略
- 迭代工具结果以确保正确性
以下是在 think 工具中迭代的一些示例:
<think_tool_example_1>
用户想要取消航班 ABC123
- 需要验证:用户 ID、预订 ID、原因
- 检查取消规则:
* 是否在预订后 24 小时内?
* 如果不是,检查机票等级和保险
- 验证没有航段已飞行或已过时
- 计划:收集缺失信息,验证规则,获取确认
</think_tool_example_1>
<think_tool_example_2>
用户想要预订 3 张前往纽约的机票,每张机票有 2 件托运行李
- 需要用户 ID 来检查:
* 会员等级以确定行李限额
* 个人资料中存在哪些付款方式
- 行李计算:
* 经济舱 × 3 名乘客
* 如果是普通会员:每人 1 件免费行李 → 3 件额外行李 = 150 美元
* 如果是白银会员:每人 2 件免费行李 → 0 件额外行李 = 0 美元
* 如果是黄金会员:每人 3 件免费行李 → 0 件额外行李 = 0 美元
- 需要验证的付款规则:
* 最多 1 张旅行券,1 张信用卡,3 张礼品卡
* 所有付款方式必须在个人资料中
* 旅行券余额作废
- 计划:
1. 获取用户 ID
2. 验证会员级别以确定行李费
3. 检查个人资料中的付款方式以及是否允许组合使用
4. 计算总价:机票价格 + 任何行李费
5. 获取明确的预订确认
</think_tool_example_2>
Von besonderem Interesse ist der Vergleich zwischen den verschiedenen Methoden. Die Verwendung des "think"-Tools mit Optimierungshinweisen führte zu deutlich besseren Ergebnissen als die erweiterte Denkweise (die ähnlich gut abschnitt wie das unaufgeforderte "think"-Tool). Die alleinige Verwendung des "think"-Tools (ohne Hinweise) verbesserte die Leistung im Vergleich zur Baseline, war aber immer noch schlechter als der Optimierungsansatz.
Die Kombination aus dem "think"-Tool und den Optimierungshinweisen liefert eine deutlich bessere Leistung, was darauf zurückzuführen sein könnte, dass die Benchmarks in derLuftfahrtstrategieIm Rahmen der hohen Komplexität profitiert das Modell am meisten von dem Beispiel "Denken".
Im Einzelhandelsbereich testete Anthropic auch verschiedene Konfigurationen, um die spezifischen Auswirkungen der einzelnen Ansätze zu verstehen.

Die nachstehende Tabelle zeigt die Daten für das Modell Claude 3.5 Sonnet in drei verschiedenen Konfigurationen des Bereichs "Einzelhandel", die mit τ-Bench bewertet wurden:
| Konfiguration | k =1 | k =2 | k =3 | k =4 | k =5 |
|---|---|---|---|---|---|
| Nur "Think"-Werkzeug | 0.812 | 0.735 | 0.685 | 0.650 | 0.626 |
| Erweitertes Denken | 0.770 | 0.681 | 0.623 | 0.581 | 0.548 |
| Basislinie (in der geodätischen Vermessung) | 0.783 | 0.695 | 0.643 | 0.607 | 0.583 |
Auch ohne zusätzliche Hinweise erzielt das "Think"-Tool die höchste Erfolgsquote.1 Note 0,812.Retail-StrategieDie Handhabung war wesentlich einfacher als in der Luftfahrt, und Claude konnte seine Leistung verbessern, weil er ohne weitere Anweisungen nachdenken konnte.
Wichtige Erkenntnisse aus der τ-Bench-Analyse
Die detaillierte Analyse von Anthropic zeigt mehrere Muster auf, die bei der effektiven Implementierung von "Think"-Tools helfen können:
- In schwierigen Bereichen sind Stichwörter unerlässlich. Die bloße Bereitstellung des "Denk"-Tools kann die Leistung leicht verbessern, aber die Kombination mit optimierten Hinweisen kann in schwierigen Bereichen zu deutlich besseren Ergebnissen führen. In einfacheren Bereichen kann jedoch auch die bloße Verwendung des "Think"-Tools von Vorteil sein.
- Verbesserte Konsistenz zwischen den StudienDas "think"-Werkzeug bringt Verbesserungen im Pass. Verbesserungen durch den Einsatz des "think"-Werkzeugs im Passk bei k=5, was darauf hindeutet, dass das Tool Claude hilft, Randfälle und anomale Szenarien effizienter zu behandeln.
SWE-Bench Leistungstest: das Tüpfelchen auf dem i
Bei der Bewertung des Sonnet-Modells Claude 3.5 fügte Anthropic ein ähnliches "Think"-Tool zum SWE-Bench-Setup hinzu, um es auf den Stand der Technik von 0,623 zu bringen. Das geänderte "think"-Tool wird im Folgenden definiert:
{
"name": "think",
"description": "使用该工具进行思考。它不会获取新信息或对存储库进行任何更改,只会记录想法。在需要复杂推理或集思广益时使用。例如,如果您探索存储库并发现了错误的根源,请调用此工具来集思广益几种独特的修复错误的方法,并评估哪些更改可能最简单和最有效。或者,如果您收到一些测试结果,请调用此工具来集思广益修复失败测试的方法。",
"input_schema": {
"type": "object",
"properties": {
"thought": {
"type": "string",
"description": "您的想法。"
}
},
"required": ["thought"]
}
}
Die Experimente von Anthropic (n =30 Proben mit dem Werkzeug "think". n (=144 Stichproben ohne das "Think"-Instrument) zeigte, dass der unabhängige Effekt der Einbeziehung dieses Instruments die Leistung um durchschnittlich 1,6% (Welch's t Test: t (38.89) = 6.71, p < .001, d = 1.47).
Szenarien für das "think"-Tool
Auf der Grundlage der Ergebnisse dieser Bewertungen ermittelte Anthropic spezifische Szenarien, in denen Claude am meisten von dem "think"-Tool profitieren würde:
- Analyse der Ergebnisse des ToolsWenn Claude die Ausgabe eines vorangegangenen Werkzeugaufrufs sorgfältig verarbeiten muss, bevor er handelt, und möglicherweise in seinen Methoden zurückgehen muss.
- strategieintensives UmfeldWenn Claude detaillierte Richtlinien befolgen und deren Einhaltung überprüfen muss.
- sequentielle Entscheidungsfindungwenn jede Aktion auf der vorhergehenden aufbaut und Fehler kostspielig sind (in der Regel in mehrstufigen Bereichen).
Bewährte Verfahren: Nutzen Sie die "Denk"-Tools
Um die Vorteile von Claudes "Think"-Tool voll auszuschöpfen, schlägt Anthropic auf der Grundlage seiner τ-Bench-Experimente die folgenden Best Practices für die Implementierung vor.
1. strategische Tipps und bereichsspezifische Beispiele
Am effektivsten ist es, klare Anweisungen zu geben, wann und wie das "think"-Tool zu verwenden ist, z. B. für die τ-Bench-Domäne Luft- und Raumfahrt. Die Bereitstellung von Beispielen, die auf Ihren spezifischen Anwendungsfall zugeschnitten sind, kann die Effizienz der Nutzung des "think"-Tools durch Ihr Modell erheblich verbessern:
- Der Grad der Detailliertheit, der für den Argumentationsprozess erwartet wird.
- Wie man komplexe Anweisungen in umsetzbare Schritte zerlegt.
- Entscheidungsbäume zur Bewältigung gängiger Szenarien.
- Wie kann man überprüfen, ob alle notwendigen Informationen gesammelt wurden?
2. die Platzierung von komplexen Leitfäden in Systemausschreibungen
Anthropic hat festgestellt, dass es bei langen und komplexen Beschreibungen von "Denk"-Werkzeugen effektiver ist, sie in Systemaufforderungen aufzunehmen, als sie in der Werkzeugbeschreibung selbst unterzubringen. Dieser Ansatz bietet einen breiteren Kontext und hilft den Modellen, Denkprozesse besser in ihr Gesamtverhalten zu integrieren.
Wann sollte man das "think"-Tool nicht verwenden?
Das "Think"-Werkzeug kann zwar erhebliche Verbesserungen bringen, ist aber nicht für alle Anwendungsszenarien geeignet und erhöht die Länge der Eingabeaufforderung und den Output. Token Kosten des Tools. Anthropic stellte insbesondere in den folgenden Anwendungsfällen keine Verbesserung durch das "Think"-Tool fest:
- Nicht-sequenzielle WerkzeugaufrufeWenn Claude nur einen einzigen Werkzeugaufruf oder mehrere parallele Aufrufe benötigt, um eine Aufgabe zu erledigen, wird das Hinzufügen des Werkzeugs "think" wahrscheinlich keine Verbesserung bringen.
- Einfacher Befehl nachWenn Claude nicht viele Beschränkungen einhalten muss und sein Standardverhalten gut genug ist, wird sich das zusätzliche "Denken" wahrscheinlich nicht auszahlen.
Schneller Start: wenige einfache Schritte, bedeutende Ergebnisse
Das "Think"-Tool ist eine einfache Ergänzung zur Claude-Implementierung und kann in wenigen Schritten zu bedeutenden Verbesserungen führen:
- Tests mit Proxy-Tool-Nutzungsszenarien. Beginnen Sie mit schwierigen Anwendungsfällen, bei denen Claude derzeit mit der Einhaltung von Richtlinien oder komplexen Schlussfolgerungen in langen Tool-Aufrufketten zu kämpfen hat.
- Hinzufügen von Werkzeugdefinitionen. Implementieren Sie ein auf Ihren Bereich zugeschnittenes "Think"-Tool. Es erfordert nur minimalen Code, ermöglicht aber eine strukturiertere Argumentation. Ziehen Sie auch in Betracht, in die Systemaufforderungen Anweisungen zur Verwendung des Tools aufzunehmen, mit Beispielen, die für Ihren Bereich relevant sind.
- Überwachung und Verbesserung. Beobachten Sie, wie Claude das Werkzeug in der Praxis einsetzt, und passen Sie Ihre Aufforderungen an, um effektivere Denkmuster zu fördern.
Am wichtigsten ist, dass das Hinzufügen dieses Werkzeugs nur wenige Nachteile in Bezug auf die Leistungsergebnisse mit sich bringt. Es wird weder das externe Verhalten ändern noch Ihre bestehenden Werkzeuge oder Arbeitsabläufe beeinträchtigen, es sei denn, Claude beschließt, es zu verwenden.
Zusammenfassung und Ausblick
Die Untersuchungen von Anthropic zeigen, dass das "Think"-Tool die Leistung des Sonnet-Modells von Claude 3.5 bei komplexen Aufgaben, die die Einhaltung von Richtlinien und Schlussfolgerungen über lange Tool-Aufrufketten erfordern, erheblich verbessert. Das "think"-Tool ist zwar keine Einheitslösung, aber es bietet für die richtigen Anwendungsfälle erhebliche Vorteile bei minimaler Implementierungskomplexität.
Wir freuen uns darauf zu sehen, wie Entwickler "think"-Tools einsetzen, um leistungsfähigere, zuverlässigere und transparentere KI-Systeme zu entwickeln. In Zukunft wird Anthropic möglicherweise die Kombination von "think"-Tools mit anderen KI-Technologien wie Reinforcement Learning und Wissensgraphen weiter erforschen, um die Argumentations- und Entscheidungsfähigkeit von KI-Modellen weiter zu verbessern. In der Zwischenzeit wird die Entwicklung effektiverer Cueing-Strategien und die Anwendung des "Think"-Werkzeugs auf ein breiteres Spektrum von Bereichen ebenfalls eine wichtige Richtung sein, die es zu untersuchen gilt.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...