kurz
Heute freuen wir uns, die leistungsstarken, vielfältigen und nützlichen Modelle der Qwen2.5-Coder-Familie als Open Source zur Verfügung stellen zu können, und wir sind entschlossen, die Entwicklung von Open CodeLLMs weiter voranzutreiben.
- BeeindruckendQwen2.5-Coder-32B-Instruct wird das aktuelle Open-Source-Modell für SOTA, mit Code-Fähigkeiten, die an GPT-4o heranreichen und starke und umfassende Code-Fähigkeiten sowie gute Allzweck- und mathematische Fähigkeiten demonstrieren.
- VerteilerQwen2.5-Coder hat die sechs wichtigsten Modellgrößen abgedeckt, um den Bedürfnissen verschiedener Entwickler gerecht zu werden: Letzten Monat haben wir die Größen 1,5B und 7B freigegeben, und dieses Mal haben wir die Größen 0,5B, 3B, 14B und 32B freigegeben.
- pragmatischWir untersuchen die Nützlichkeit von Qwen2.5-Coder sowohl in Code Assistant- als auch in Artifacts-Szenarien und demonstrieren anhand einiger Beispiele das Potenzial von Qwen2.5-Coder in realen Szenarien.
Leistungsstark: Codefähigkeit bis hin zum Open-Source-Modell SOTA

- Code-ErstellungQwen2.5-Coder-32B-Instruct, das Flaggschiff dieser Open-Source-Lösung, hat die beste Leistung unter den Open-Source-Modellen bei mehreren populären Code-Generierungs-Benchmarks (z. B. EvalPlus, LiveCodeBench und BigCodeBench) erzielt und eine konkurrenzfähige Leistung mit GPT-4o erreicht.
- Code-KorrekturenQwen2.5-Coder-32B-Instruct kann Anwendern helfen, Fehler in ihrem Code zu beheben und die Programmierung effizienter zu machen. Aider ist ein beliebter Benchmark für die Codebehebung, und Qwen2.5-Coder-32B-Instruct erreicht eine Punktzahl von 73,7, die mit GPT auf Aider vergleichbar ist. Qwen2.5-Coder-32B-Instruct erreichte bei Aider eine Punktzahl von 73,7 und schnitt damit genauso gut ab wie GPT-4o.
- verschlüsselte ArgumentationCode-Inferenz bezieht sich auf die Fähigkeit eines Modells, den Prozess der Codeausführung zu erlernen und die Eingaben und Ausgaben des Modells genau vorherzusagen. Qwen2.5-Coder-7B-Instruct, das letzten Monat veröffentlicht wurde, hat bereits eine gute Leistung bei der Code-Schlussfolgernden Fähigkeit gezeigt, und das 32B-Modell geht sogar noch weiter.

- mehrsprachigIntelligente Programmierassistenten sollten mit allen Programmiersprachen vertraut sein, und Qwen2.5-Coder-32B-Instruct zeigt gute Leistungen in mehr als 40 Programmiersprachen und erreicht eine Punktzahl von 65,9 bei McEval, mit beeindruckenden Leistungen in Haskell, Racket und anderen, dank unserer einzigartigen Datenbereinigung und -rationalisierung in der Vorübungsphase.


Überraschend ist auch die Fähigkeit von Qwen2.5-Coder-32B-Instruct, Code in mehreren Programmiersprachen zu korrigieren, was dem Benutzer helfen wird, seine vertrauten Programmiersprachen zu verstehen und zu ändern und die Lernkosten für unbekannte Sprachen erheblich zu senken.
Ähnlich wie McEval ist MdEval ein Benchmark für die Korrektur von Code in mehreren Programmiersprachen, und Qwen2.5-Coder-32B-Instruct erreichte bei MdEval eine Punktzahl von 75,2, was den Spitzenwert unter allen Open-Source-Modellen darstellt.

- Ausrichtung der menschlichen PräferenzenUm die Alignment-Leistung von Qwen2.5-Coder-32B-Instruct anhand menschlicher Präferenzen zu testen, haben wir Code Arena (ähnlich wie Arena Hard) entwickelt, einen Benchmark zur Bewertung von Code-Präferenzen anhand interner Annotationen. Wir verwenden GPT-4o als Bewertungsmodell für das Präferenz-Alignment, mit einer "A vs. B win" Bewertung - d.h. der Prozentsatz, um den Modell A gegenüber Modell B in einer Testmenge von Instanzen punktet. Die Ergebnisse in der folgenden Abbildung zeigen den Vorteil von Qwen2.5-Coder-32B-Instruct beim Präferenzabgleich.

Vielseitigkeit: eine Vielzahl von Modellgrößen
Die Open-Source-Modellfamilie Qwen2.5-Coder besteht aus sechs Größen: 0,5B, 1,5B, 3B, 7B, 14B und 32B, die nicht nur den Bedürfnissen von Entwicklern in verschiedenen Ressourcenszenarien gerecht werden, sondern auch ein gutes Experimentierfeld für die Forschungsgemeinschaft darstellen. Die folgende Tabelle zeigt die detaillierten Modellinformationen:
| Modelle | Params | Nicht-Emb Params | Schichten | Köpfe (KV) | Krawatte einbetten | Kontext Länge | Lizenz |
|---|---|---|---|---|---|---|---|
| Qwen2.5-Coder-0.5B | 0.49B | 0.36B | 24 | 14 / 2 | Ja | 32K | Apache 2.0 |
| Qwen2.5-Coder-1.5B | 1.54B | 1.31B | 28 | 12 / 2 | Ja | 32K | Apache 2.0 |
| Qwen2.5-Coder-3B | 3.09B | 2.77B | 36 | 16 / 2 | Ja | 32K | Qwen Forschung |
| Qwen2.5-Coder-7B | 7.61B | 6.53B | 28 | 28 / 4 | Nein | 128K | Apache 2.0 |
| Qwen2.5-Coder-14B | 14.7B | 13.1B | 48 | 40 / 8 | Nein | 128K | Apache 2.0 |
| Qwen2.5-Coder-32B | 32.5B | 31.0B | 64 | 40 / 8 | Nein | 128K | Apache 2.0 |
Wir haben immer geglaubt Skalierungsgesetz Philosophie. Wir evaluieren die Leistung von Qwen2.5-Coder-Modellen unterschiedlicher Größe auf allen Datensätzen, um die Wirksamkeit von Scaling on Code LLMs zu überprüfen.
Für jede Größe haben wir ein offenes Basis- und ein offenes Instruct-Modell, wobei das Basismodell den Entwicklern als Grundlage für die Feinabstimmung ihrer Modelle dient, während das Instruct-Modell das offizielle Ausrichtungsmodell ist, das für den direkten Chat zur Verfügung steht.
Hier sehen Sie, wie sich das Basismodell bei verschiedenen Größen verhält:

Hier sehen Sie, wie sich das Instruct-Modell bei verschiedenen Größen verhält:

Um es intuitiver zu machen, zeigen wir einen Vergleich zwischen verschiedenen Größen des Qwen2.5-Coder-Modells und anderen Open-Source-Modellen auf dem Kerndatensatz.
- Für das Basismodell wählen wir MBPP-3shot als Bewertungsindex, und unsere umfangreichen Experimente zeigen, dass MBPP-3shot für die Bewertung des Basismodells besser geeignet ist und gut mit der tatsächlichen Wirkung des Modells korrelieren kann.
- Für das Instruct-Modell haben wir LiveCodeBench-Themen aus den letzten 4 Monaten (2024.07 - 2024.11) für die Evaluierung ausgewählt. Diese kürzlich veröffentlichten Themen, bei denen es unwahrscheinlich ist, dass sie in die Trainingsmenge eindringen, spiegeln die OOD-Fähigkeit des Modells wider.
Es gab die erwartete positive Korrelation zwischen Modellgröße und Modelleffektivität, und die Tatsache, dass der Qwen2.5-Coder die SOTA-Leistung bei allen Größen erreichte, ermutigt uns, weiterhin größere Coder-Modelle zu untersuchen.

Praktisch: Treffen Sie Cursor und Artefakte
Ein praktischer Coder war schon immer unsere Vision. Zu diesem Zweck haben wir die praktische Anwendung des Qwen2.5-Coder-Modells im Kontext von Code-Assistenten und Artefakten erforscht.
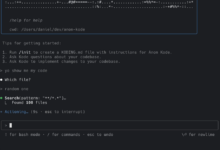
Qwen2.5-Coder 🤝 Cursor
Intelligente Code-Assistenten sind bereits weit verbreitet, beruhen aber derzeit meist auf Closed-Source-Modellen. Wir hoffen, dass die Entwicklung von Qwen2.5-Coder Entwicklern eine freundliche und leistungsfähige Alternative bieten wird.
Darüber hinaus hat Qwen2.5-Coder-32B eine starke Fähigkeit zur Code-Vervollständigung auf dem vortrainierten Modell gezeigt und eine SOTA-Leistung auf fünf Evaluierungssätzen erreicht, darunter Humaneval-Infilling, CrossCodeEval, CrossCodeLongEval, RepoEval und SAFIM.
Um einen fairen Vergleich zu gewährleisten, wird die maximale Sequenzlänge auf 8k begrenzt und der Fill-in-the-Middle-Modus für die Tests verwendet. Bei den 4 Prüfsätzen CrossCodeEval, CrossCodeLongEval, RepoEval und Humaneval-Infilling wird bewertet, ob der generierte Inhalt absolut mit den echten Bezeichnungen übereinstimmt (Exact Match); bei SAFIM wird die Erfolgsrate der einmaligen Ausführung (Pass@1) für die Bewertung.

Qwen2.5-Coder 🤝 Artefakte
Artifacts ist eine der wichtigsten Anwendungen für die Codegenerierung, die den Nutzern dabei hilft, etwas zu erstellen, das für die Visualisierung geeignet ist, und wir haben die WebUI öffnen Erkunden Sie das Potenzial von Qwen2.5-Coder in Artefacts-Szenarien, hier sind einige konkrete Beispiele:
Wir werden bald mit dem Code-Modus auf Tongyis offizieller Website https://tongyi.aliyun.com online gehen, der alle Arten von Visualisierungsanwendungen wie in einem Satz generierte Websites, Minispiele und Datendiagramme unterstützt. Willkommen zum Ausprobieren!