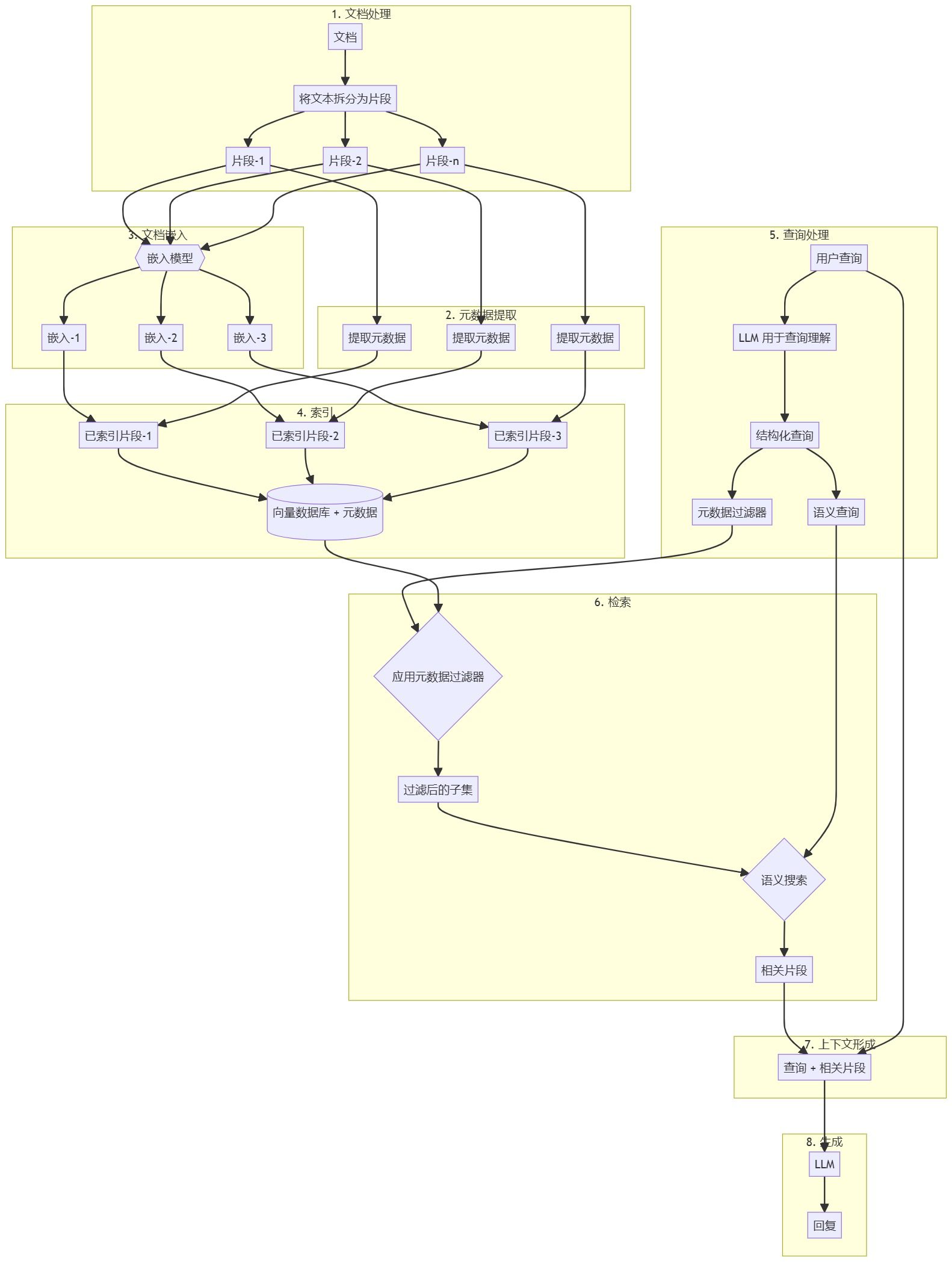
Einfache, effektive RAG-Retrieval-Strategie: sparse + dense Hybrid-Suche und -Umordnung sowie Verwendung von "cue caching" zur Generierung von dokumentenrelevantem Gesamtkontext für Textabschnitte.


Damit ein KI-Modell in einem bestimmten Szenario nützlich sein kann, benötigt es in der Regel Zugang zu Hintergrundwissen. Ein Chatbot für den Kundensupport muss zum Beispiel das spezifische Geschäft verstehen, das er bedient, während ein Bot für juristische Analysen Zugang zu einer großen Anzahl vergangener Fälle haben muss.
Entwickler erweitern das Wissen von KI-Modellen häufig mit Retrieval-Augmented Generation (RAG), einer Methode, bei der relevante Informationen aus einer Wissensbasis abgerufen und an Benutzeraufforderungen angehängt werden, um die Reaktionsfähigkeit des Modells deutlich zu verbessern. Das Problem ist, dass traditionelle RAG Programme verlieren bei der Kodierung von Informationen den Kontext, was häufig dazu führt, dass das System nicht in der Lage ist, relevante Informationen aus der Wissensdatenbank abzurufen.
In diesem Beitrag wird ein Ansatz vorgestellt, der den Abrufschritt in RAG erheblich verbessern kann. Dieser Ansatz wird Contextual Retrieval genannt und verwendet zwei Untertechniken: Contextual Embeddings und Contextual BM25. Dieser Ansatz reduziert die Anzahl der Retrieval-Fehler um 491 TP3T und 671 TP3T, wenn er mit Reranking kombiniert wird. Diese Verbesserungen erhöhen die Retrieval-Genauigkeit dramatisch, was sich direkt in einer verbesserten Leistung bei nachgelagerten Aufgaben niederschlägt.
Im Wesentlichen handelt es sich um eine Mischung aus semantisch ähnlichen und wortfrequenzähnlichen Ergebnissen, und manchmal entsprechen die semantischen Ergebnisse nicht der wahren Absicht. Lesen Sie den Link am Ende des Textes. Es ist zwei Jahre her, dass diese "alte" Strategie veröffentlicht wurde, und die Methode wird immer noch selten verwendet, da sie entweder in die extrem komplexe RAG-Strategie fällt oder nur Einbettung und Umordnung verwendet.
In diesem Artikel wird eine kleine Verbesserung dieser alten Strategie vorgestellt, nämlich die Verwendung von "Cache-Hinweisen" zur Erzeugung von Kontext für Textblöcke, die mit geringem Aufwand in den Gesamtkontext des Dokuments passen. Es ist eine kleine Änderung, aber die Ergebnisse sind beeindruckend!
Sie können dies tun, indem Sie Unser Beispielcode ausnutzen Claude Stellen Sie Ihre eigene kontextbezogene Abfragelösung bereit.
Ein Hinweis auf die einfache Verwendung längerer Spitzen
Manchmal ist die einfachste Lösung auch die beste. Wenn Ihre Wissensdatenbank weniger als 200.000 Token (ca. 500 Seiten Material) umfasst, können Sie die gesamte Wissensdatenbank direkt in die Aufforderungen an das Modell aufnehmen, so dass eine RAG- oder ähnliche Methode überflüssig ist.
Vor ein paar Wochen haben wir für Claude Cue-CacheZusätzlich zur neuen API haben wir diesen Ansatz erheblich beschleunigt und die Kosten reduziert. Entwickler können nun häufig verwendete Hinweise zwischen API-Aufrufen zwischenspeichern, wodurch sich die Latenzzeit um mehr als das Doppelte und die Kosten um bis zu 90% verringern (wie das funktioniert, können Sie in unserem Hinweis-Cache Beispielcode (Verstehen, wie es funktioniert).
Wenn Ihre Wissensbasis jedoch wächst, benötigen Sie eine skalierbarere Lösung, und hier kommt die kontextbezogene Suche ins Spiel. Nachdem dieser Hintergrund nun geklärt ist, kommen wir zur Sache.
RAG-Grundlagen: Ausweitung auf eine größere Wissensbasis
RAG ist die typische Lösung für große Wissensbasen, die nicht in ein Kontextfenster passen, und bereitet die Wissensbasis in folgenden Schritten vor:
- Zerlegung der Wissensbasis (Dokumenten-"Korpus") in kleinere Textfragmente, in der Regel nicht mehr als ein paar hundert Token; (zu lange Textblöcke drücken mehr Bedeutung aus, d. h. sind zu semantisch reich)
- Die Segmente werden in Vektoreinbettungen umgewandelt, die die Bedeutung mithilfe eines Einbettungsmodells kodieren;
- Speichern Sie diese Einbettungen in einer Vektordatenbank für die Suche nach semantischer Ähnlichkeit.
Wenn der Benutzer zur Laufzeit eine Frage in das Modell eingibt, findet die Vektordatenbank das relevanteste Fragment auf der Grundlage der semantischen Ähnlichkeit der Frage. Das relevanteste Fragment wird dann zu der an das generative Modell gesendeten Eingabeaufforderung hinzugefügt (und beantwortet die Frage als Kontext der größeren Modellreferenz).
Obwohl Einbettungsmodelle gut geeignet sind, semantische Beziehungen zu erfassen, können sie kritische exakte Übereinstimmungen übersehen. Glücklicherweise kann in solchen Fällen eine ältere Technik helfen.BM25 ist eine Ranking-Funktion, die exakte Wort- oder Satzübereinstimmungen durch lexikalischen Abgleich findet. Sie ist besonders effektiv bei Suchanfragen, die eindeutige Bezeichner oder Fachbegriffe enthalten.
BM25 Verbessert auf der Grundlage des Konzepts TF-IDF (Word Frequency-Inverse Document Frequency), das die Bedeutung eines Wortes in einer Sammlung von Dokumenten misst.BM25 verhindert, dass häufige Wörter die Ergebnisse dominieren, indem es die Länge des Dokuments berücksichtigt und eine Sättigungsfunktion auf die Worthäufigkeit anwendet.
So funktioniert BM25, wenn die semantische Einbettung fehlschlägt: Angenommen, ein Nutzer fragt in der Datenbank des technischen Kundendienstes nach dem "Fehlercode TS-999". (Das (Vektor-)Einbettungsmodell findet möglicherweise allgemeine Inhalte über den Fehlercode, aber nicht den genauen "TS-999"-Treffer. Stattdessen sucht das BM25 nach dieser spezifischen Textzeichenfolge, um das entsprechende Dokument zu identifizieren.
Durch die Kombination von Einbettungs- und BM25-Techniken kann das RAG-Programm die relevantesten Fragmente wie folgt genauer finden:
- Die Wissensbasis (der Dokumenten-"Korpus") wird in kleinere Textstücke zerlegt, die in der Regel nicht mehr als ein paar hundert Token umfassen;
- Erstellen Sie TF-IDF-Kodierungen und semantische (Vektor-)Einbettungen für diese Segmente;
- Verwenden Sie BM25, um das beste Fragment auf der Grundlage einer exakten Übereinstimmung zu finden;
- Verwenden Sie die (Vektor-)Einbettung, um die Segmente mit der höchsten semantischen Ähnlichkeit zu finden;
- Die Ergebnisse der Schritte (3) und (4) werden mit Hilfe einer Sortierfusionstechnik, z. B. dem speziellen Reordering-Modell Rerank 3.5, zusammengeführt und entwertet.
- Fügen Sie die ersten K-Segmente zur Eingabeaufforderung hinzu, um eine Antwort zu erzeugen.
Durch die Kombination von BM25 und Einbettungsmodellen sind herkömmliche RAG-Systeme in der Lage, ein Gleichgewicht zwischen präzisem Term-Matching und breiterem semantischen Verständnis herzustellen, um umfassendere und genauere Ergebnisse zu liefern.

Ein standardisiertes Retrieval Augmentation Generation (RAG)-System, das Einbettung und Best Match 25 (BM25) kombiniert, um Informationen abzurufen. Die TF-IDF (Word Frequency-Inverse Document Frequency) misst die Bedeutung von Wörtern und bildet die Grundlage von BM25.
Mit diesem Ansatz können Sie zu geringen Kosten eine viel größere Wissensbasis aufbauen, als eine einzelne Eingabeaufforderung bewältigen kann. Diese traditionellen RAG-Systeme haben jedoch eine wesentliche Einschränkung: Sie brechen oft den Kontext.
Apropos hier auf der Grundlage der Suche Schema, um eine vernünftige Gestaltung zu machen, hat noch nicht von der abgeschnittenen Block von Text zu sehen, ist die abgeschnittenen Block von Text, um den gleichen Inhalt zum Ausdruck bringen, sollte nie abgeschnitten werden, aber die oben genannten RAG-Schema gesprochenUnvermeidlich wird der Kontext abgeschnitten. Dies ist ein Problem, das sowohl einfach als auch komplex ist. Lassen Sie uns zum Kern dieses Artikels kommen.
Kontextbedingte Schwierigkeiten bei den traditionellen RAG
In traditionellen RAG werden Dokumente oft in kleinere Stücke aufgeteilt, um sie effizient abrufen zu können. Dieser Ansatz ist für viele Anwendungsszenarien geeignet, kann aber zu Problemen führen, wenn einzelne Chunks nicht genügend Kontext aufweisen.
Nehmen wir an, Sie haben einige Finanzinformationen in Ihre Wissensbasis eingebettet (z. B. einen Bericht der US-Börsenaufsicht SEC) und erhalten die folgende Frage:"Wie hoch ist das Umsatzwachstum von ACME Corporation im zweiten Quartal 2023?"
Ein zusammenhängender Block kann den folgenden Text enthalten:"Die Einnahmen des Unternehmens stiegen im Vergleich zum Vorquartal um 3%." In dem Block selbst werden jedoch weder bestimmte Unternehmen noch relevante Zeiträume ausdrücklich genannt, so dass es schwierig ist, die richtigen Informationen zu finden oder sie effektiv zu nutzen.
Einführung in die kontextbezogene Suche
Die kontextbezogene Suche erfolgt durch Hinzufügen eines spezifischen Blocks zu jedem Block vor der Einbettung derInterpretierender Kontext("Context Embedding") und die Erstellung eines BM25-Index ("Context BM25") löst dieses Problem.
Kehren wir zum Beispiel der SEC-Berichtssammlung zurück. Hier ein Beispiel dafür, wie ein Block konvertiert wird:
original_chunk = "该公司的收入比上一季度增长了 3%。"
contextualized_chunk = "该块来自一份关于 ACME 公司 2023 年第二季度表现的 SEC 报告;上一季度的收入为 3.14 亿美元。该公司的收入比上一季度增长了 3%。"
Es ist erwähnenswert, dass in der Vergangenheit eine Reihe anderer Möglichkeiten vorgeschlagen wurden, den Kontext zur Verbesserung des Abrufs zu nutzen. Andere Vorschläge umfassen:Hinzufügen einer generischen Dokumentenzusammenfassung zu einem Block(Wir haben experimentiert und festgestellt, dass der Gewinn sehr begrenzt ist),Hypothetische Einbettung von Dokumenten im Gesang antworten Digest-basierte Indizierung(Wir haben sie bewertet und festgestellt, dass die Leistung gering ist). Diese Methoden unterscheiden sich von der in diesem Papier vorgeschlagenen Methode.
Viele der Methoden zur Verbesserung der Kontextqualität sind experimentell erwiesenermaßen nur von begrenztem Nutzen, und selbst die oben erwähnten relativ besten Methoden bleiben fragwürdig.Da die Hinzufügung von erklärendem Kontext zu diesem Umwandlungsprozess zu einem Verlust von mehr oder weniger Informationen führt.
Selbst wenn ein kompletter Absatz in Textblöcke zerlegt und mehrere Ebenen von Überschriften zum Inhalt des kompletten Absatzes hinzugefügt werden, kann dieser Absatz isoliert und aus dem Kontext gerissen kein genaues Wissen vermitteln, wie die oben genannten Beispiele gezeigt haben.
Diese Methode löst effektiv das Problem, dass der Inhalt eines Textblocks, wenn er allein steht, aufgrund des fehlenden kontextuellen Hintergrunds isoliert und bedeutungslos ist.
Aktivieren der kontextuellen Suche
Natürlich ist es zu aufwändig, den Kontext für Tausende oder gar Millionen von Blöcken in einer Wissensdatenbank manuell zu annotieren. Um eine kontextbezogene Suche zu ermöglichen, haben wir uns an Claude gewandt und einen Hinweis geschrieben, der das Modell anweist, einen prägnanten, blockspezifischen Kontext auf der Grundlage des Kontextes des gesamten Dokuments zu liefern. Im Folgenden sehen Sie, wie wir die Hinweise von Claude 3 Haiku verwendet haben, um Kontext für jeden Block zu generieren:
<document>
{{WHOLE_DOCUMENT}}
</document>
这是我们希望置于整个文档中的块
<chunk>
{{CHUNK_CONTENT}}
</chunk>
请提供一个简短且简明的上下文,以便将该块置于整个文档的上下文中,从而改进块的搜索检索。仅回答简洁的上下文,不要包含其他内容。
Der generierte Kontexttext besteht in der Regel aus 50-100 Token und wird dem Block vor der Einbettung und vor der Erstellung des BM25-Index hinzugefügt.
Dieser Cue-Lauf muss auf das vollständige Dokument verweisen, das dem Textblock entspricht (der nicht mehr als 500 Seiten umfassen sollte, richtig?) als Cue-Zwischenspeicher verwenden, um den mit dem Textblock verbundenen Kontext im Verhältnis zum vollständigen Dokument genau zu generieren.
Dies stützt sich auf Claude's Caching-Fähigkeit, das vollständige Dokument als Aufforderung zum Zwischenspeichern der Eingabe muss nicht jedes Mal zu zahlen, Caching, nur einmal zahlen, so dass das Programm, um die Voraussetzungen zu erreichen sindGroßes Modell ermöglicht Zwischenspeicherung langer DokumenteModelle wie DeepSeek haben ähnliche Fähigkeiten.
In der Praxis sieht der Vorverarbeitungsprozess wie folgt aus:

Die kontextbezogene Suche ist eine Vorverarbeitungstechnik, die die Suchgenauigkeit verbessert.
Wenn Sie daran interessiert sind, die kontextbezogene Suche zu nutzen, können Sie sich auf unsere Betriebsanleitung Start.
Reduzierung der Kosten für die kontextuelle Suche mit Hint Caching
Der Abruf über Claude-Kontexte kann dank der erwähnten speziellen Hint-Caching-Funktion mit geringem Aufwand erreicht werden. Mit dem Hint-Caching müssen Sie nicht für jeden Block ein Referenzdokument übergeben. Es genügt, das Dokument einmal in den Cache zu laden und dann auf den zuvor zwischengespeicherten Inhalt zu verweisen. Wenn man von 800 Token pro Block, 8k Token pro Dokument, 50 Token pro Kontextanweisung und 100 Token pro Blockkontext ausgeht, beträgt dieDie einmaligen Kosten für die Erstellung eines kontextualisierten Blocks betragen $1,02 pro Million Dokumenten-Token.
Methodik
Wir haben Experimente in verschiedenen Wissensdomänen (Codebase, Romane, ArXiv-Papiere, wissenschaftliche Arbeiten), Einbettungsmodellen, Suchstrategien und Bewertungsmetriken durchgeführt. Wir führten unsere Experimente durch in Anhang II Einige Beispiele für die Fragen und Antworten, die wir für jeden Bereich verwendet haben, sind in der Tabelle aufgeführt.
Die nachstehende Abbildung zeigt die durchschnittliche Leistung in allen Wissensgebieten bei Verwendung der leistungsfähigsten Einbettungskonfiguration (Gemini Text 004) und der Abfrage der ersten 20 Snippets. Wir haben 1 minus recall@20 als Bewertungsmaßstab verwendet, der den Prozentsatz der relevanten Dokumente misst, die in den ersten 20 Snippets nicht gefunden wurden. Die vollständigen Ergebnisse können im Anhang eingesehen werden - die Kontextualisierung verbessert die Leistung in jeder von uns ausgewerteten Kombination von eingebetteten Quellen.
Leistungsverbesserung
Unsere Experimente zeigen das:
- Durch die kontextuelle Einbettung wurde die Fehlerquote bei der Suche nach den ersten 20 Fragmenten um 35% reduziert.(5,7% → 3,7%).
- Durch die Kombination von kontextueller Einbettung und kontextuellem BM25 wird die Fehlerquote bei der Suche nach den ersten 20 Fragmenten um 49%(5,7% → 2,9%).

Die Kombination von kontextueller Einbettung und kontextuellem BM25 reduzierte die Fehlerquote bei der Suche nach den ersten 20 Fragmenten um 49%.
Überlegungen zur Implementierung
Bei der Implementierung der kontextbezogenen Suche sind folgende Punkte zu beachten:
- Fragmentgrenzen: Überlegen Sie, wie das Dokument in Fragmente aufgeteilt werden soll. Die Wahl der Fragmentgröße, der Grenzen und der Überlappung kann die Abrufleistung beeinflussen ^1^.
- Modelle einbetten: Während die kontextbezogene Suche die Leistung aller getesteten Einbettungsmodelle verbessert, können bestimmte Modelle stärker davon profitieren. Wir haben festgestellt, dass Zwillinge im Gesang antworten Reise Die Einbettung ist besonders wirksam.
- Benutzerdefinierte kontextbezogene Hinweise: Die von uns bereitgestellten generischen Prompts funktionieren zwar gut, doch lassen sich bessere Ergebnisse erzielen, wenn die Prompts für bestimmte Bereiche oder Anwendungsfälle angepasst werden (z. B. durch Aufnahme eines Glossars mit Schlüsselbegriffen, die in anderen Dokumenten der Wissensdatenbank definiert sein können).
- Anzahl der Clips: Das Hinzufügen weiterer Fragmente zum Kontextfenster kann die Chancen erhöhen, relevante Informationen aufzunehmen. Zu viele Informationen können das Modell jedoch ablenken, weshalb die Anzahl kontrolliert werden muss. Wir haben 5, 10 und 20 Fragmente ausprobiert und festgestellt, dass 20 Fragmente bei diesen Optionen am besten funktionieren (siehe Anhang), aber es lohnt sich, je nach Anwendungsfall zu experimentieren.
Führen Sie immer Bewertungen durch: Die Antwortgenerierung kann verbessert werden, indem kontextualisierte Snippets übergeben und zwischen Kontext und Snippets unterschieden wird.
Neuordnung zur weiteren Leistungssteigerung
Im letzten Schritt können wir das kontextuelle Retrieval mit einer anderen Technik kombinieren, um die Leistung weiter zu verbessern. Beim traditionellen RAG (Retrieval-Augmented Generation) durchsucht das KI-System seine Wissensbasis nach potenziell relevanten Informationen. Bei großen Wissensdatenbanken liefert die anfängliche Suche in der Regel eine große Anzahl von Fragmenten - manchmal bis zu Hunderten - von unterschiedlicher Relevanz und Bedeutung.
Die Neuordnung ist eine gängige Filtertechnik, die sicherstellt, dass nur die wichtigsten Informationen an das Modell weitergeleitet werden. Die Neuordnung sorgt für eine bessere Reaktion und reduziert gleichzeitig Kosten und Latenzzeiten, da das Modell weniger Informationen verarbeitet. Die wichtigsten Schritte sind wie folgt:
- Eine erste Suche wurde durchgeführt, um die wahrscheinlichsten relevanten Segmente zu ermitteln (wir verwendeten die ersten 150);
- Übergeben Sie die ersten N Segmente und die Benutzeranfrage an das Umordnungsmodell;
- Mit Hilfe eines Neuordnungsmodells wurde jeder Clip nach Relevanz und Wichtigkeit für den Hinweis bewertet, und dann wurden die besten K Clips ausgewählt (wir verwendeten die besten 20);
- Die ersten K Segmente werden als Kontext an das Modell übergeben, um das Endergebnis zu erzeugen.
 Die Kombination von kontextbezogener Suche und Neuordnung maximiert die Suchgenauigkeit.
Die Kombination von kontextbezogener Suche und Neuordnung maximiert die Suchgenauigkeit.
Leistungsverbesserung
Auf dem Markt gibt es verschiedene Nachbestellungsmodelle. Wir verwenden das Cohere Rekorder Hat den Test durchgeführt. reise Ein Rekorder ist ebenfalls vorhandenaber wir hatten keine Zeit, es zu testen. Unsere Experimente zeigen, dass das Hinzufügen eines Neuordnungsschritts die Suche in einer Vielzahl von Bereichen weiter optimieren kann.
Wir stellen insbesondere fest, dass die Neuordnung der kontextuellen Einbettungen und der kontextuellen BM25 die Fehlerquote beim Abruf der 20 besten Fragmente um 671 TP3T (5,71 TP3T → 1,91 TP3T) reduziert.
 Die Neuordnung der kontextuellen Einbettungen und der kontextuellen BM25 verringerte die Fehlerquote bei der Suche nach den ersten 20 Fragmenten um 67%.
Die Neuordnung der kontextuellen Einbettungen und der kontextuellen BM25 verringerte die Fehlerquote bei der Suche nach den ersten 20 Fragmenten um 67%.
Überlegungen zu Kosten und Verzögerungen
Eine wichtige Überlegung bei der Neuordnung ist die Auswirkung auf die Latenzzeit und die Kosten, insbesondere wenn eine große Anzahl von Fragmenten neu geordnet wird. Da die Neuordnung einen zusätzlichen Schritt zur Laufzeit bedeutet, kommt es zwangsläufig zu einer gewissen Latenz, selbst wenn der Neuordner alle Fragmente nebeneinander bewertet. Es besteht ein Kompromiss zwischen der Neuordnung von mehr Fragmenten für höhere Leistung und der Neuordnung von weniger Fragmenten für geringere Latenz und Kosten. Wir empfehlen, mit verschiedenen Einstellungen für Ihren speziellen Anwendungsfall zu experimentieren, um das optimale Gleichgewicht zu finden.
zu einem Urteil gelangen
Wir haben eine Reihe von Tests durchgeführt, in denen wir verschiedene Kombinationen der oben genannten Techniken verglichen haben (Einbettungsmodelle, Verwendung von BM25, Verwendung von kontextbezogener Suche, Verwendung von Reorderern und Anzahl der Top-K-Ergebnisse) und Experimente mit einer Vielzahl von Datensatztypen durchgeführt haben. Im Folgenden finden Sie eine Zusammenfassung unserer Ergebnisse:
- Einbettung + BM25 ist besser als nur die Einbettung;
- Reise und Zwillinge ist das Einbettungsmodell, das in unseren Tests am besten funktioniert hat;
- Die Weitergabe der ersten 20 Segmente an das Modell ist effektiver als die Weitergabe der ersten 10 oder 5 Segmente;
- Das Hinzufügen von Kontext zu Segmenten verbessert die Abrufgenauigkeit erheblich;
- Neu ordnen ist besser als nicht neu ordnen;
- Alle diese Vorteile sind kumulierbar: Um die Leistung zu maximieren, können wir eine Kombination aus kontextbezogener Einbettung (von Voyage oder Gemini), kontextbezogenem BM25, Neuordnung der Schritte und Hinzufügen von 20 Snippets zur Eingabeaufforderung verwenden.
Wir empfehlen allen Entwicklern, die die Wissensdatenbank nutzen, die Unser Praxishandbuch Experimentieren Sie mit diesen Methoden, um neue Leistungsniveaus zu erschließen.
Anhang I
Nachfolgend finden Sie eine Aufschlüsselung der Retrievals @ 20-Ergebnisse nach Datensätzen, eingebetteten Anbietern, BM25 in Verbindung mit der Einbettung, der Verwendung von kontextbezogenem Retrieval und der Verwendung von Reordering.
Eine Aufschlüsselung der Abrufe @ 10 und @ 5 sowie Beispielfragen und -antworten für jeden Datensatz finden Sie unter Anhang II.
 1 minus Recall @ 20 für den Datensatz und die eingebetteten Anbieterergebnisse.
1 minus Recall @ 20 für den Datensatz und die eingebetteten Anbieterergebnisse.
Fußnoten
- Weitere Informationen zu Segmentierungsstrategien finden Sie in der dieser Link im Gesang antworten dieser Link.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...