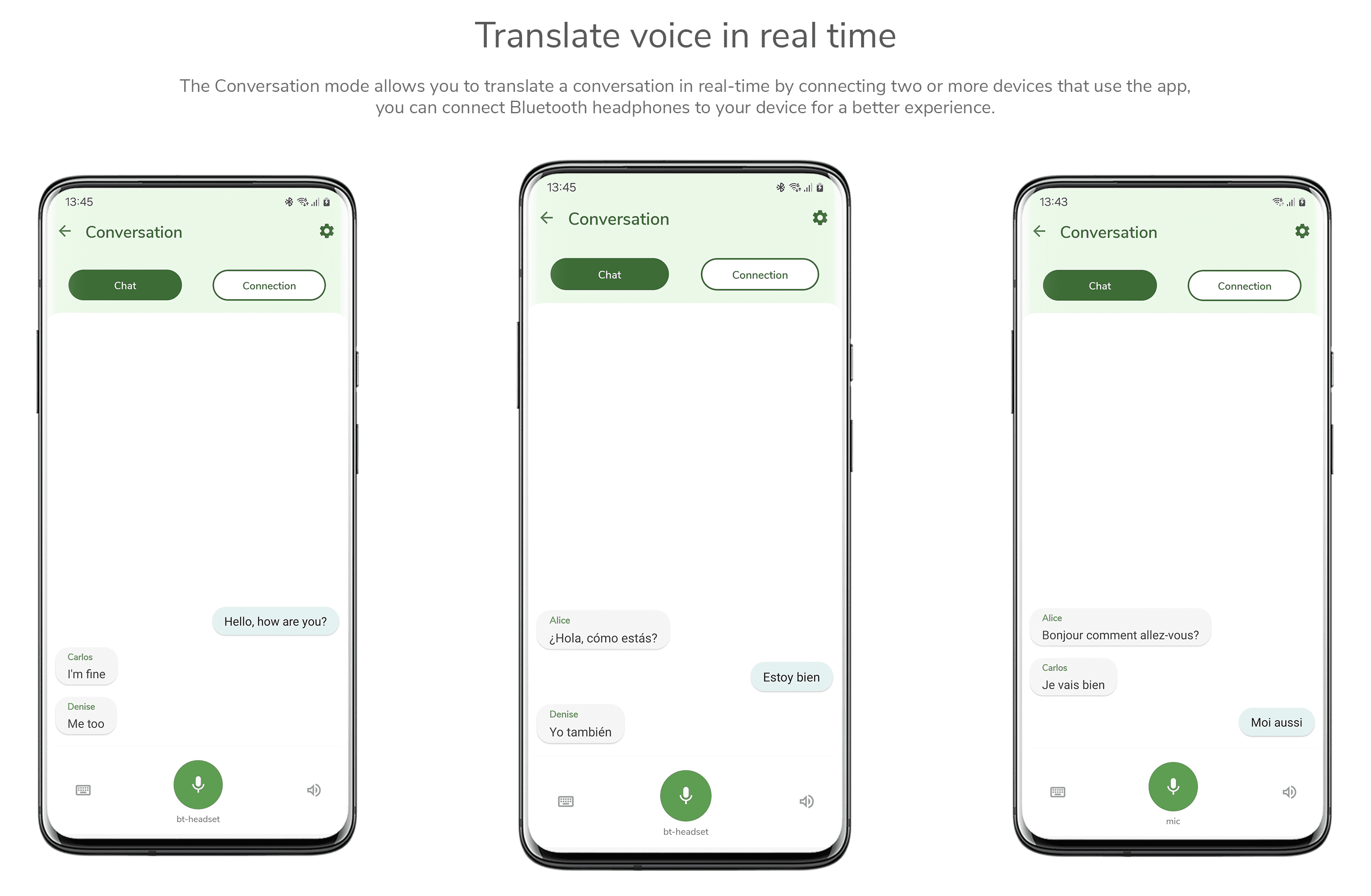
PengChengStarling: Kleineres und schnelleres mehrsprachiges Speech-to-Text-Tool als Whisper-Large v3

Allgemeine Einführung
PengChengStarling (PengCheng Labs) ist ein mehrsprachiges automatisches Spracherkennungswerkzeug (ASR), das Sprache in verschiedenen Sprachen in entsprechenden Text umwandeln kann. Dieses Toolkit wurde auf der Grundlage des icefall-Projekts entwickelt und bietet einen kompletten Spracherkennungsprozess einschließlich Datenverarbeitung, Modelltraining, Inferenz, Feinabstimmung und Bereitstellung. pengChengStarling unterstützt Streaming-Spracherkennung in acht Sprachen, darunter Chinesisch, Englisch, Russisch, Vietnamesisch, Japanisch, Thailändisch, Indonesisch und Arabisch. Zu den wichtigsten Anwendungsszenarien gehören Sprachassistenten, Übersetzungstools, Untertitelerstellung und Sprachsuche. Die Modellgröße beträgt 20% von Whisper-Large v3, und die Inferenzgeschwindigkeit ist 7 Mal schneller als bei Whisper-Large v3.
Es kann mehrsprachige Spracheingaben in einem einheitlichen Rahmen verarbeiten, unterstützt Spracherkennung in Echtzeit, Erkennung beim Sprechen, kann als internationale Konferenzaufzeichnung in Text verwendet werden, mehrsprachige Videos erzeugen automatisch Untertitel, sprachübergreifendes Kundendienstsystem.

Funktionsliste
- Datenverarbeitung: Unterstützt die Vorverarbeitung mehrerer Datensätze, um das erforderliche Eingabeformat zu erzeugen.
- Modelltraining: bietet flexible Trainingskonfigurationen zur Unterstützung mehrsprachiger Spracherkennungsaufgaben.
- Inferenz: effiziente Inferenzgeschwindigkeit mit Unterstützung für Streaming-Spracherkennung.
- Feinabstimmung: Unterstützt die Feinabstimmung von Modellen zur Anpassung an spezifische Aufgabenanforderungen.
- Bereitstellung: stellt Modelle in den Formaten PyTorch und ONNX für eine einfache Bereitstellung bereit.
Hilfe verwenden
Einbauverfahren
- Klonen des Projektlagers:
git clone https://github.com/yangb05/PengChengStarling
cd PengChengStarling
- Installieren Sie die Abhängigkeit:
pip install -r requirements.txt
export PYTHONPATH=/tmp/PengChengStarling:$PYTHONPATH
Vorbereitung der Daten
Bevor mit dem Trainingsprozess begonnen werden kann, müssen die Rohdaten zunächst in das gewünschte Eingabeformat umgewandelt werden. Dazu gehört in der Regel die Anpassung derzipformer/prepare.pyden Nagel auf den Kopf treffenmake_*_listMethode zur Erzeugung derdata.listDatei. Nach Fertigstellung generiert das Skript die entsprechenden Schnitte und fbank-Merkmale für jeden Datensatz, die als Eingabedaten für PengChengStarling verwendet werden.
Modellschulung
- Konfigurieren Sie die Trainingsparameter: im Fenster
config_trainum die für das Training erforderlichen Parameter zu konfigurieren. - Ausbildung einleiten:
./train.sh
Inferenz
- Aufbereitung der Inferenzdaten: Vorverarbeitung der Daten in das gewünschte Format.
- Argumentation einleiten:
./eval.sh
Feintuning
- Feinabstimmung der Daten: Die Daten werden in das gewünschte Format vorverarbeitet.
- Initiieren Sie die Feinabstimmung:
./train.sh --finetune
Einsätze
PengChengStarling bietet Modelle in zwei Formaten: PyTorch-Zustandswörterbuch und ONNX-Format. Sie können das geeignete Format für den Einsatz je nach Ihren Bedürfnissen wählen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...