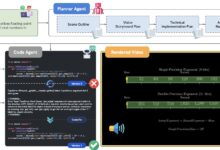
Allgemeine Einführung Basalt ist eine auf die Erstellung und Verwaltung von Cues ausgerichtete Plattform, die Teams bei der effizienten Erstellung hochwertiger KI-Cues und deren Anwendung auf ihre Produkte unterstützt. Sie bietet einen codefreien Editor, intelligente Optimierungsvorschläge und Versionierungsfunktionen, die es Produktmanagern, Ingenieuren und Fachexperten ermöglichen, schnell...
Allgemeine Einführung TheoremExplainAgent ist ein innovatives Projekt, das vom TIGER AI Lab entwickelt wurde, um komplexe mathematische und wissenschaftliche Theoreme mithilfe von Techniken der künstlichen Intelligenz in leicht verständliche Videoanimationen zu verwandeln. Das Tool basiert auf den Argumentationsfähigkeiten des Large Language Model (LLM), kombiniert mit Animationserzeugung und Sprachsynthese...
Aktivieren Sie Builder intelligenten Programmiermodus, unbegrenzte Nutzung von DeepSeek-R1 und DeepSeek-V3, reibungslosere Erfahrung als die Übersee-Version. Geben Sie einfach die chinesischen Befehle, keine Programmierkenntnisse können auch Null-Schwelle, um ihre eigenen Anwendungen zu schreiben.
Umfassende Einführung Cloudflare Workers MCP ist ein Open-Source-Projekt, das von Cloudflare entwickelt und auf GitHub gehostet wird, um Entwicklern zu helfen, schnell Cloudflare Workers-basierte MCP (Model Context Protocol)-Server zu erstellen und einzusetzen. Dieser Worker ...
Der bekannte KI-Gigant OpenAI hat vor kurzem die Veröffentlichung einer Forschungsvorschau seines neuesten Flaggschiff-Sprachmodells GPT-4.5 angekündigt, das wieder einmal viel Aufmerksamkeit in der Tech-Community auf sich gezogen hat. Das mit Spannung erwartete neue Modell wird zunächst Softwareentwicklern und ChatGPT Pro-Abonnenten zur Verfügung stehen und läutet damit eine neue Runde der...
Im Bereich der künstlichen Intelligenz hat das innovative Unternehmen Perplexity die nach eigenen Angaben "weltweit erste konversationelle KI-Suchmaschine" auf den Markt gebracht, eine Suchmaschine, die die umfangreichen Fähigkeiten der Google-Suchmaschine zum Abrufen von Informationen mit den interaktiven Konversationsfunktionen von ChatGPT kombiniert, was zweifelsohne die Übertragung...
Allgemeine Einführung 3FS (Fire-Flyer File System) ist ein vom DeepSeek-Team entwickeltes quelloffenes paralleles Dateisystem, das für moderne SSDs und RDMA-Netzwerke konzipiert wurde und darauf abzielt, die Effizienz des Datenzugriffs drastisch zu verbessern. Es erreicht einen aggregierten Lesedurchsatz von 6,6 TiB/s und 3,66 TiB/min in einem Cluster mit 180 Knoten...
Es ist schon lange her, dass ich ein AI-Schönheitsporträt geteilt habe. Ich habe zuvor fooocus verwendet, um Schönheitsporträts zu zeichnen, dieses Mal werde ich Starflow ausprobieren, ein kommerziell erhältliches AI-Bilderstellungstool, mit dem Sie alle grundlegenden Bildbearbeitungsarbeiten im Canvas durchführen können. Das StarFlow-Basismodell enthält zwei voreingestellte "Porträtfotografie"-Modelle, die beide...
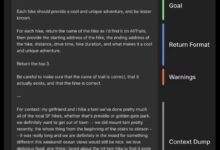
Das Schreiben effektiver Prompts (Eingabeaufforderungen) ist eine wichtige Fähigkeit im Zeitalter der KI. Ganz gleich, ob KI Texte oder Bilder generieren oder genaue Informationen einholen soll, ein guter Prompter kann die Qualität und Relevanz der KI-Ausgabe erheblich verbessern. Dieses Papier basiert auf "The Anatomy of an o1 Prompt...
Allgemeine Einführung DeepChat ist ein Open-Source-Projekt für intelligente Assistenten, das vom ThinkInAIXYZ-Team auf GitHub entwickelt wurde. Es zielt darauf ab, Benutzer mit der digitalen Welt durch leistungsstarke KI-Technologie zu verbinden und bietet eine effiziente und natürliche Chat-Erfahrung. Es unterstützt Windows, macOS, Linux und andere Multiplattform-Anwendungen, mit...
Am 26. Februar 2025 veröffentlichte SuperCLUE die erste Liste von Benchmarks für die Codegenerierung auf Projektebene (SuperCLUE-Project). Siehe: Project Level Code Generation Benchmark Release. Der Benchmark basiert auf der Zusammenarbeit einer "Jury" großer Modelle und bewertet die Leistung von 12 großen Modellen aus dem In- und Ausland bei der Codegenerierung auf Projektebene...
Allgemeine Einführung Dify Connect MCP ist ein Open-Source-Projekt, das auf GitHub gehostet wird. Es wurde entwickelt, um Nutzern der Dify-Plattform ein komfortables Tool zur nahtlosen Anbindung an Dify-Workflows über das Model Context Protocol (MCP) zu bieten. Das Projekt wurde von difybas entwickelt...
Umfassende Einführung Seconda ist ein innovatives No-Code-Entwicklungstool, das von Baidu Intelligent Cloud auf den Markt gebracht wurde, um Nutzern zu helfen, schnell Apps in natürlicher Sprache zu erstellen, ohne dass sie komplexe Programmierkenntnisse beherrschen müssen. Basierend auf der leistungsstarken KI-Technologie von Baidu und der Unterstützung großer Modelle ist die Plattform in der Lage, die kreativen Ideen der Nutzer in praktisch nutzbare...
Allgemeine Einführung DualPipe ist eine Open-Source-Technologie, die vom DeepSeek-AI-Team entwickelt wurde, um die Effizienz des Trainings von KI-Modellen in großem Maßstab zu verbessern. Es handelt sich um einen innovativen bidirektionalen parallelen Pipeline-Algorithmus, der in erster Linie verwendet wird, um eine vollständige Überlappung von Berechnung und Kommunikation beim DeepSeek-V3- und R1-Modelltraining zu erreichen, mit...
Allgemeine Einführung AutoDev ist ein Open-Source-Projekt, das vom Unit Mesh-Team entwickelt und auf GitHub gehostet wird. Es zielt darauf ab, die Programmiereffizienz von Entwicklern durch die Technologie der künstlichen Intelligenz zu verbessern. Es ist ein leistungsstarker Programmierassistent, der mehrere Programmiersprachen unterstützt, darunter Java, Kotlin, Python usw., und...
Sprachmodelle (LMs) sind zu einer zentralen Triebkraft für Innovationen in der KI-Technologie geworden. Vom Pre-Training bis hin zu realen Anwendungen sind Sprachmodelle auf Textdaten angewiesen, um zu funktionieren. Ob sie nun auf der Ebene von Billionen Token trainiert werden oder datenintensive KI unterstützen...
Im Zeitalter der Informationsexplosion ist das Wissensmanagement zum Schlüssel für die Verbesserung der persönlichen Wettbewerbsfähigkeit geworden. Unabhängig von der Branche, in der Sie tätig sind, müssen Sie sich jeden Tag mit einer riesigen Menge an Informationen, Dokumenten und Lernmaterialien auseinandersetzen. Wie Sie dieses Wissen effizient abrufen und nutzen können, ist zu einem dringenden Problem für alle geworden. Khoj, genau um dieses Problem zu lösen...
Allgemeine Einführung LLPlayer ist ein Open-Source-Medienplayer für Sprachschüler, der auf GitHub gehostet und vom Entwickler umlx5h erstellt wurde. Es integriert eine Vielzahl von nützlichen Funktionen, wie zweisprachige Untertitel-Anzeige, AI automatisch generierte Untertitel, Echtzeit-Übersetzung und Wortsuche, usw. Es wurde entwickelt, um Benutzern zu helfen, Videos zu sehen.
Abstrakt Gut entworfene Prompts sind wichtig, um die Argumentationsfähigkeiten von großen Sprachmodellen (LLMs) zu verbessern und gleichzeitig ihre Ergebnisse an die Aufgabenanforderungen verschiedener Domänen anzupassen. Das manuelle Entwerfen von Hints erfordert jedoch Fachwissen und iteratives Experimentieren. Bestehende Methoden zur Optimierung von Hinweisen zielen darauf ab, diesen Prozess zu automatisieren, aber sie ...
Angetrieben von der Welle der künstlichen Intelligenz hat die Sprachtechnologie nie dagewesene Entwicklungsmöglichkeiten eröffnet. ElevenLabs, ein Technologieunternehmen, das sich auf die KI-Sprachgenerierung konzentriert, hat mit seiner fortschrittlichen KI-Technologie erfolgreich Text in flüssige, natürliche und äußerst realistische Sprache umgewandelt. Darüber hinaus ist es erstaunlich...
Sie können keine AI-Tools finden? Versuchen Sie es hier!
Geben Sie einfach das Schlüsselwort Barrierefreiheit Bing-SucheDer Bereich KI-Tools auf dieser Website bietet eine schnelle und einfache Möglichkeit, alle KI-Tools auf dieser Website zu finden.