
MiMo-VL - das quelloffene multimodale Modell von Xiaomi

Was ist MiMo-VL
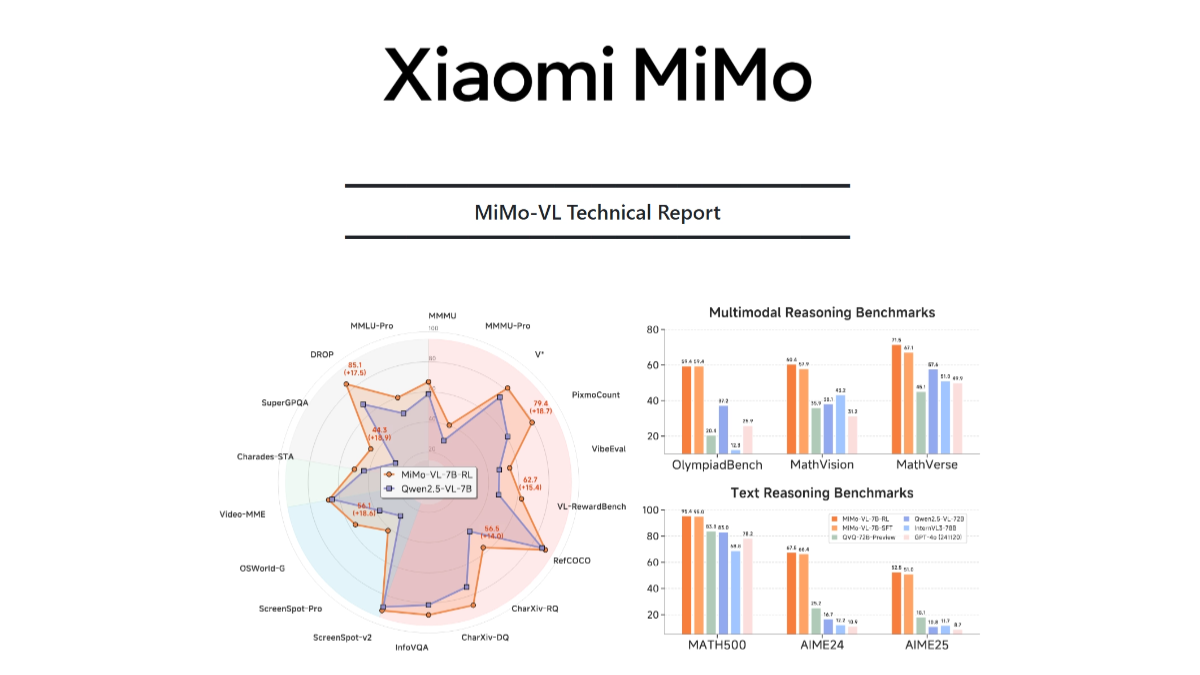
MiMo-VL ist Xiaomis quelloffenes multimodales Großmodell, das aus einem visuellen Kodierer, einer cross-modalen Projektionsschicht und einem Sprachmodell besteht. Der visuelle Kodierer basiert auf Qwen2.5-ViT, der Eingaben in nativer Auflösung unterstützt und mehr Details bewahrt; das Sprachmodell ist Xiaomis selbstentwickeltes MiMo-7B, das für komplexe Schlussfolgerungen optimiert ist. Das Modell basiert auf einer mehrstufigen Pre-Training-Strategie, die mit 2,4T Token multimodaler Daten trainiert wurde und Datentypen wie Bild-Text-Paare, Video-Text-Paare und GUI-Bedienungssequenzen umfasst. Basierend auf dem hybriden Online Reinforcement Learning (MORL)-Algorithmus werden die Inferenz, die Wahrnehmungsleistung und die Benutzererfahrung des Modells in allen Aspekten verbessert.MiMo-VL zeigt gute Leistungen bei der Inferenz komplexer Bilder, der GUI-Interaktion, dem Videoverständnis und dem Parsen langer Dokumente, z.B. erreicht es 66,7% auf MMMU-val und übertrifft damit Gemma 3 27B; 59,4% auf OlympiadBench 59,4% bei OlympiadBench, womit er das 72B-Modell übertrifft.
Hauptmerkmale von MiMo-VL
- Komplexes Bildverstehen und QuizGenaues Verständnis des Inhalts komplexer Bilder mit angemessenen Erklärungen und Antworten.
- GUI-Bedienung und -InteraktionUnterstützt bis zu 10+ Schritte von GUI-Operationen, um komplexe Anweisungen zu verstehen und auszuführen.
- Video und SprachverstehenVerstehen von Videoinhalten, Argumentation und Quizfragen in Verbindung mit Sprache.
- Parsing und Reasoning von langen DokumentenVerarbeitung langer Dokumente für komplexe Schlussfolgerungen und Informationsextraktion.
- Optimierung der BenutzerfreundlichkeitVerbesserung der Inferenz, der Wahrnehmungsleistung und der Benutzererfahrung auf der Grundlage von hybridem Online-Verstärkungslernen.
Offizielle Website-Adresse von MiMo-VL
- Github-Repositorien::https://github.com/XiaomiMiMo/MiMo-VL
- HuggingFace-Modellbibliothek::https://huggingface.co/collections/XiaomiMiMo/mimo-vl
- Technische Papiere::https://github.com/XiaomiMiMo/MiMo-VL/blob/main/MiMo-VL-Technical-Report
Wie verwende ich MiMo-VL?
- Umarmung Gesicht Plattform::
- Zugang zur Modellbibliothek Hugging FaceZugang zu MiMo-VL'sUmarmendes Gesicht ModellbibliothekSeite.
- Modelle laden: Verwenden Sie die Python-Bibliothek von Hugging Face, um das MiMo-VL-Modell zu laden. Beispiel:
from transformers import AutoModelForVision2Seq, AutoProcessor
model = AutoModelForVision2Seq.from_pretrained("XiaomiMiMo/mimo-vl")
processor = AutoProcessor.from_pretrained("XiaomiMiMo/mimo-vl")- Verarbeitung der EingangsdatenEingabedaten wie Bilder, Videos oder Text werden vom Prozessor vorverarbeitet.
- Ausgabe generierenEingabe der verarbeiteten Daten in das Modell und Erhalt der Ausgabe des Modells.
- GitHub-Repository::
- Klonen von GitHub-Repositorien: ZugangGitHub-Repositoryklonen Sie das Repository lokal.
git clone https://github.com/XiaomiMiMo/MiMo-VL.git- Installation von AbhängigkeitenInstallieren Sie die erforderlichen Python-Abhängigkeiten gemäß der Datei requirements.txt im Repository.
pip install -r requirements.txt- laufender CodeBefolgen Sie die Anweisungen im Repository, um Beispielcode auszuführen oder eine Anwendung zu öffnen.
Die wichtigsten Vorteile von MiMo-VL
- Starke multimodale FusionsfähigkeitVerarbeitung multimodaler Daten wie Bilder, Videos und Texte, um komplexe Szenarien zu verstehen.
- Ausgezeichnete InferenzleistungHervorragende Leistung in mehreren Benchmarks, z. B. 66,71 TP3T bei MMMU-val und 59,41 TP3T bei OlympiadBench.
- Optimierung der BenutzerfreundlichkeitBasierend auf Mixed Online Reinforcement Learning (MORL) wird das Verhalten des Modells dynamisch auf der Grundlage von Benutzerfeedback angepasst, um die Benutzererfahrung zu verbessern.
- Breite Palette von AnwendungsszenarienAnwendbar in einer Vielzahl von Bereichen wie intelligenter Kundendienst, intelligentes Zuhause und wissenschaftliche Forschung.
- Open Source und Unterstützung durch die GemeinschaftBereitstellung von Open-Source-Code und Community-Unterstützung zur Erleichterung der Forschung und Entwicklung von Entwicklern.
Für MiMo-VL in Frage kommende Personen
- KI-ForscherSchwerpunkt: Forschung in den Bereichen multimodale Fusion, komplexes logisches Denken, Sehen und Sprachverständnis.
- Entwickler und IngenieureDie Entwicklung intelligenter Anwendungen wie intelligenter Kundendienst, intelligentes Zuhause, intelligente Gesundheitsfürsorge usw. erfordert die Integration multimodaler Funktionen.
- DatenwissenschaftlerVerarbeitung und Analyse multimodaler Daten zur Verbesserung der Modellleistung und der Effizienz der Datenverarbeitung.
- Lehrkräfte und StudentenHilfsmittel für das Lehren und Lernen, z. B. für das Lösen mathematischer Probleme, das Erlernen von Programmen usw.
- Medizinische FachkräfteAssistenz bei der medizinischen Bildanalyse und dem Textverständnis zur Verbesserung der diagnostischen Effizienz und Genauigkeit.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...