Maxun: eine Open-Source-Plattform ohne Code, die automatisch Webdaten durchsucht und sie in APIs oder Tabellenkalkulationen umwandelt

Allgemeine Einführung
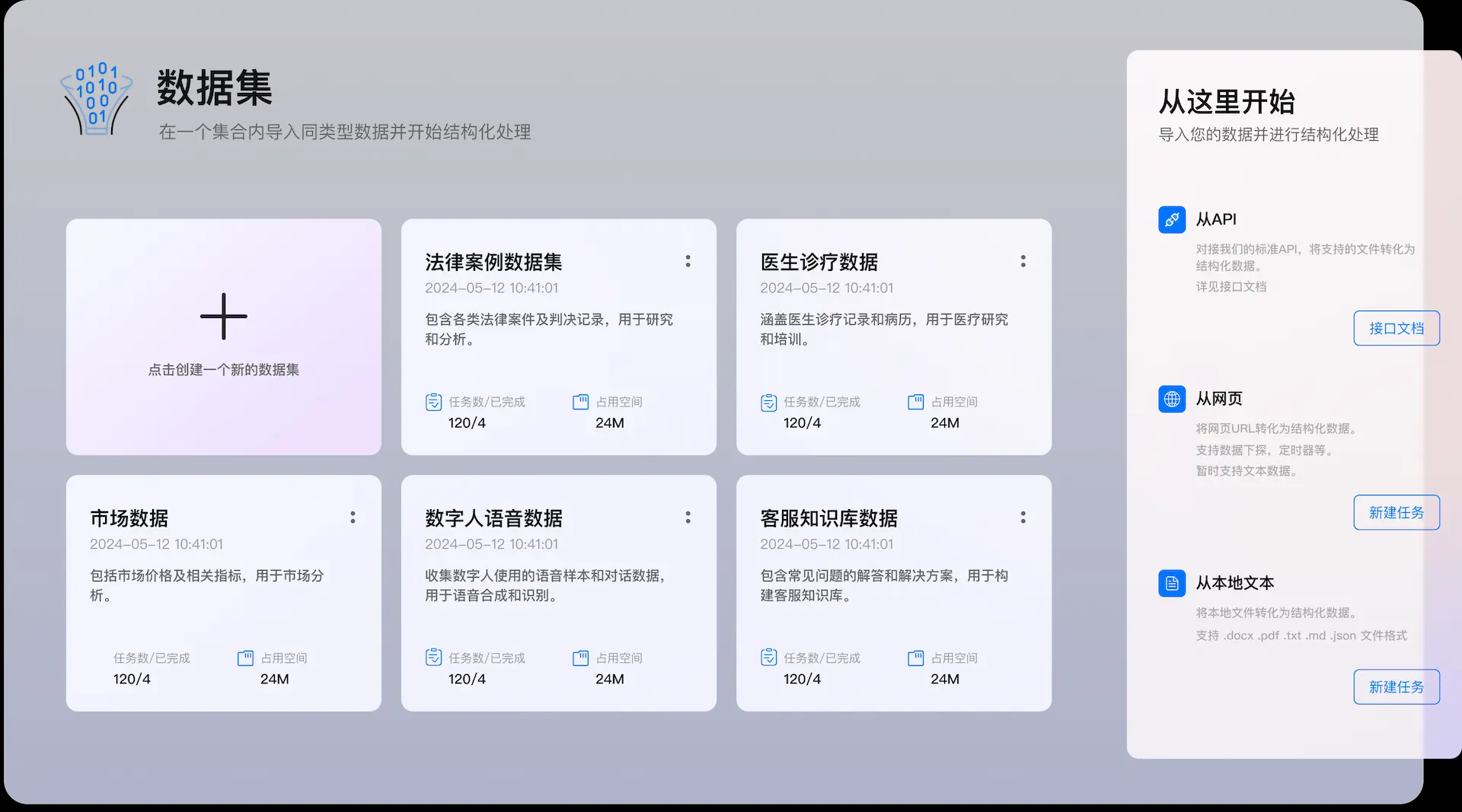
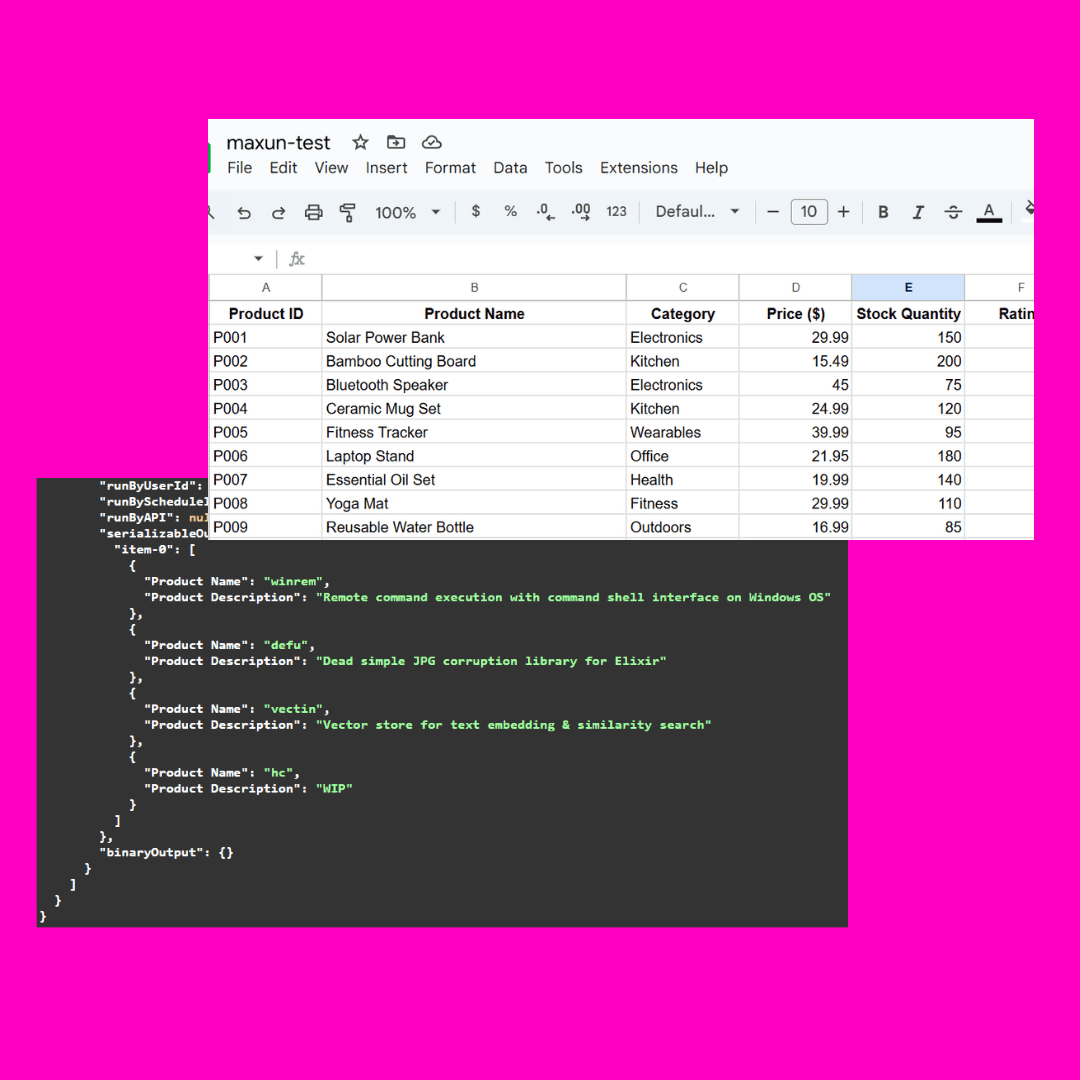
Maxun ist eine Open-Source-Plattform für die Extraktion von Webdaten ohne Code, mit der Benutzer in wenigen Minuten Roboter trainieren können, um Webdaten automatisch zu crawlen und in APIs oder Tabellenkalkulationen zu konvertieren. Die Plattform unterstützt Paging und Scrolling, kann sich an Änderungen im Website-Layout anpassen und bietet leistungsstarke Daten-Crawling-Funktionen für eine Vielzahl von Datenextraktionsanforderungen.

Funktionsliste
- Datenextraktion ohne Code: Es muss kein Code geschrieben werden, um die Webseitendaten zu crawlen
- Automatisiertes Crawlen von Daten: Roboter automatisieren das Crawlen von Daten
- API-Generierung: Konvertiert gecrawlte Daten in eine API
- Tabellenkalkulation: Export der erfassten Daten in eine Tabellenkalkulation
- Unterstützung für Paging und Scrolling: Verarbeitung mehrseitiger Daten und langer Seiten
- Anpassung an Änderungen des Website-Layouts: automatische Anpassung an Änderungen des Seitenlayouts
- Unterstützung von Login und Zwei-Faktor-Authentifizierung: Crawling von Daten aus Websites, die ein Login erfordern (in Kürze)
- Google Sheets-Integration: Daten direkt in Google Sheets importieren
- Proxy-Unterstützung: Verwendung externer Proxys zur Umgehung des Anti-Bot-Schutzes
Hilfe verwenden
Einbauverfahren
Installieren mit Docker Compose
- Klonen des Projektlagers:
git clone https://github.com/getmaxun/maxun
- Rufen Sie den Projektkatalog auf:
cd maxun
- Erstellen und starten Sie den Dienst mit Docker Compose:
docker-compose up -d --build
manuelle Installation
- Stellen Sie sicher, dass Node.js, PostgreSQL, MinIO und Redis auf Ihrem System installiert sind.
- Klonen des Projektlagers:
git clone https://github.com/getmaxun/maxun
- Wechseln Sie in das Projektverzeichnis und installieren Sie die Abhängigkeiten:
cd maxun
npm install
cd maxun-core
npm install
- Starten Sie Front-End- und Back-End-Dienste:
npm run start
- Der Front-End-Dienst wird auf http://localhost:5173/ und der Back-End-Dienst auf http://localhost:8080/ ausgeführt.
Leitlinien für die Verwendung
- Erstellen von Robotern::
- Nachdem Sie sich bei der Plattform angemeldet haben, klicken Sie auf die Schaltfläche "Bot erstellen".
- Wählen Sie die Art der zu erfassenden Daten (Liste, Text oder Bildschirmfoto).
- Konfigurieren Sie Crawling-Regeln, z. B. Ziel-URL, Crawling-Häufigkeit usw.
- Speichern Sie und starten Sie den Roboter, der dann automatisch die Datenerfassung durchführt.
- Datenexport::
- Nachdem die Bot-Mission abgeschlossen ist, rufen Sie die Seite mit den Missionsdetails auf.
- Wählen Sie das Exportformat (API oder Tabellenkalkulation).
- Klicken Sie auf die Schaltfläche "Exportieren", um die Daten herunterzuladen oder den API-Link zu erhalten.
- Handhabung von Paging und Scrolling::
- Konfigurieren Sie beim Erstellen eines Bots die Optionen zum Blättern und Scrollen.
- Der Roboter verarbeitet automatisch mehrseitige Daten und lange Seitendaten, um die Datenintegrität zu gewährleisten.
- Anpassung an Änderungen des Website-Layouts::
- Die Plattform verfügt über integrierte intelligente Algorithmen, die sich automatisch an Änderungen im Seitenlayout anpassen.
- Die Crawling-Regeln müssen nicht manuell angepasst werden, der Roboter passt sich automatisch an die Änderungen an.
- Integration mit Google Sheets::
- Konfigurieren Sie in den Plattformeinstellungen die Integration von Google Sheets.
- Die vom Roboter erfassten Daten werden automatisch in das angegebene Google Sheets-Formular importiert.
- Verwendung von Proxys::
- In den Plattformeinstellungen konfigurieren Sie den externen Agenten.
- Der Roboter führt die Greifaufgabe über einen Proxy aus und umgeht so den Roboterschutz.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...