Allgemeine Einführung
Marker ist ein auf Deep Learning basierendes Werkzeug zur Dokumentenverarbeitung, das PDF-Dateien schnell und präzise in das Markdown-Format konvertiert. Marker kann redundante Inhalte wie Kopf- und Fußzeilen entfernen, Tabellen und Codeblöcke formatieren und Bilder extrahieren und speichern. Er konvertiert auch die meisten Formeln in das LaTeX-Format und unterstützt die Ausführung auf GPU, CPU oder MPS.

Funktionsliste
- PDF-Dateien in das Markdown-Format konvertieren
- Unterstützung für mehrere Dokumenttypen, einschließlich Bücher und wissenschaftliche Arbeiten
- Überflüssige Inhalte wie Kopf- und Fußzeilen entfernen
- Formatierung von Tabellen und Codeblöcken
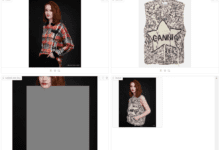
- Bilder extrahieren und speichern
- Konvertierung der meisten Gleichungen in das LaTeX-Format
- Unterstützt GPU-, CPU- und MPS-Betrieb
Hilfe verwenden
Ablauf der Installation
- Installation von AbhängigkeitenStellen Sie sicher, dass Python 3.6 und höher installiert ist und dass die folgenden Abhängigkeiten installiert sind:
pip install marker-pdf - laufendes Beispiel::
marker_single /pfad/zur/datei.pdf /pfad/zur/ausgabe/ordner --batch_multiplier 2 --max_pages 10
Richtlinien für die Verwendung
Konvertierung einzelner Dateien
marker_single /pfad/zur/datei.pdf /pfad/zur/ausgabe/ordner --batch_multiplier 2 --max_pages 10
---batch_multiplierist ein Vielfaches der Standard-Stapelgröße, wenn Sie über zusätzlichen VRAM verfügen. Höhere Zahlen verbrauchen mehr VRAM, sind aber schneller zu verarbeiten. Die Standardeinstellung ist 2. Die Standard-Stapelgröße erfordert etwa 3 GB VRAM.--max_pagesist die maximale Anzahl der zu verarbeitenden Seiten. Wird dieser Punkt weggelassen, wird das gesamte Dokument konvertiert.--Langsist eine optionale, durch Kommata getrennte Liste von Dokumentsprachen, die für die OCR verwendet werden sollen. ist standardmäßig optional und muss angegeben werden, wenn Tesseract verwendet wird.--ocr_all_pagesist ein optionaler Parameter, um OCR für alle Seiten des PDF zu erzwingen. Wenn dieser Parameter oder die Umgebungsvariable `OCR_ALL_PAGES` wahr ist, wird OCR erzwungen.
Eine Liste der unterstützten Surya OCR-Sprachen finden Sie unter [hier sind] gefunden. Wenn Sie mehr Sprachen benötigen, können Sie jede der unterstützten Sprachen verwenden, setzen Sie einfach die OCR_ENGINE eingestellt auf ocrmypdf. Wenn keine OCR erforderlich ist, kann der Marker jede Sprache unterstützen.
Mehrere Dateien konvertieren
Markierung /pfad/zur/eingabe/ordner /pfad/zur/ausgabe/ordner --workers 4 --max 10 --min_length 10000
--Arbeiterist die Anzahl der gleichzeitig konvertierten PDFs. Die Standardeinstellung ist 1, aber Sie können diesen Wert erhöhen, um den Durchsatz auf Kosten einer erhöhten CPU/GPU-Auslastung zu steigern. Jeder Arbeitsprozess verbraucht in der Spitze 5 GB VRAM und im Durchschnitt 3,5 GB.--Maxist die maximale Anzahl der zu konvertierenden PDFs. Wenn Sie diesen Punkt weglassen, werden alle PDFs im Ordner konvertiert.--min_lengthist der Mindestwert für die Anzahl der zu extrahierenden Zeichen in einer PDF-Datei; nur PDF-Dateien, die diesen Wert überschreiten, werden für die Verarbeitung berücksichtigt. Wenn Sie viele PDFs verarbeiten, empfiehlt es sich, diesen Wert festzulegen, um die OCR von PDFs zu vermeiden, die hauptsächlich aus Bildern bestehen (was die Verarbeitung verlangsamt).---metadata_fileist ein optionaler JSON-Dateipfad mit Metadaten über die PDF-Datei. Falls angegeben, wird diese Datei verwendet, um die Sprache für jede PDF-Datei festzulegen. Die Einstellung der Sprache ist für Surya optional (Standard), für Tesseract jedoch erforderlich. Das Format ist wie folgt:
{
"pdf1.pdf": {"Sprachen": ["Englisch"]}, {
"pdf2.pdf": {"Sprachen": ["Spanisch", "Russisch"]}, ...
...
}
Sie können entweder den Namen der Sprache oder den Code verwenden. Der genaue Code hängt von der OCR-Engine ab. Eine vollständige Liste der Surya-Codes finden Sie unter [hier sind], für Tesseract siehe [hier sind]
Konfigurieren von Marker-Umgebungsvariablen in FastGPT
Um den benutzerdefinierten Auflösungsdienst zu aktivieren, müssen Sie die folgenden Umgebungsvariablen in FastGPT konfigurieren:
CUSTOM_READ_FILE_URL=http://xxxx.com/v1/parse/file
CUSTOM_READ_FILE_EXTENSION=pdf
- CUSTOM_READ_FILE_URL - die Zugangsadresse des benutzerdefinierten Auflösungsdienstes, Sie müssen den Host in die Adresse des von Ihnen eingesetzten Auflösungsdienstes ändern, und der Pfad bleibt unverändert
- CUSTOM_READ_FILE_EXTENSION - Gibt die Dateitypsuffixe an, die für die Analyse unterstützt werden; mehrere Dateitypen werden durch Kommas getrennt
Überprüfen Sie den Parsing-Effekt
Nachdem Sie die Konfiguration abgeschlossen haben, können Sie den Parsing-Effekt anhand der folgenden Schritte überprüfen:
- Laden Sie eine PDF-Datei in der Wissensdatenbank hoch und bestätigen Sie den Upload
- Sehen Sie sich das Systemprotokoll an (Sie müssen LOG_LEVEL auf info oder debug level setzen).
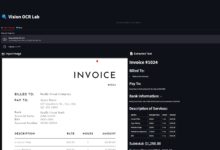
- Sie werden feststellen, dass die von Marker analysierte PDF-Datei vollständige Bildverknüpfungen enthält, was auf eine erfolgreiche Analyse hindeutet.