LocalPdfChatRAG: Intelligentes Chat-Tool zur Unterstützung lokaler Fragen zu PDF-Dokumenten mit mehreren Quellen

Allgemeine Einführung
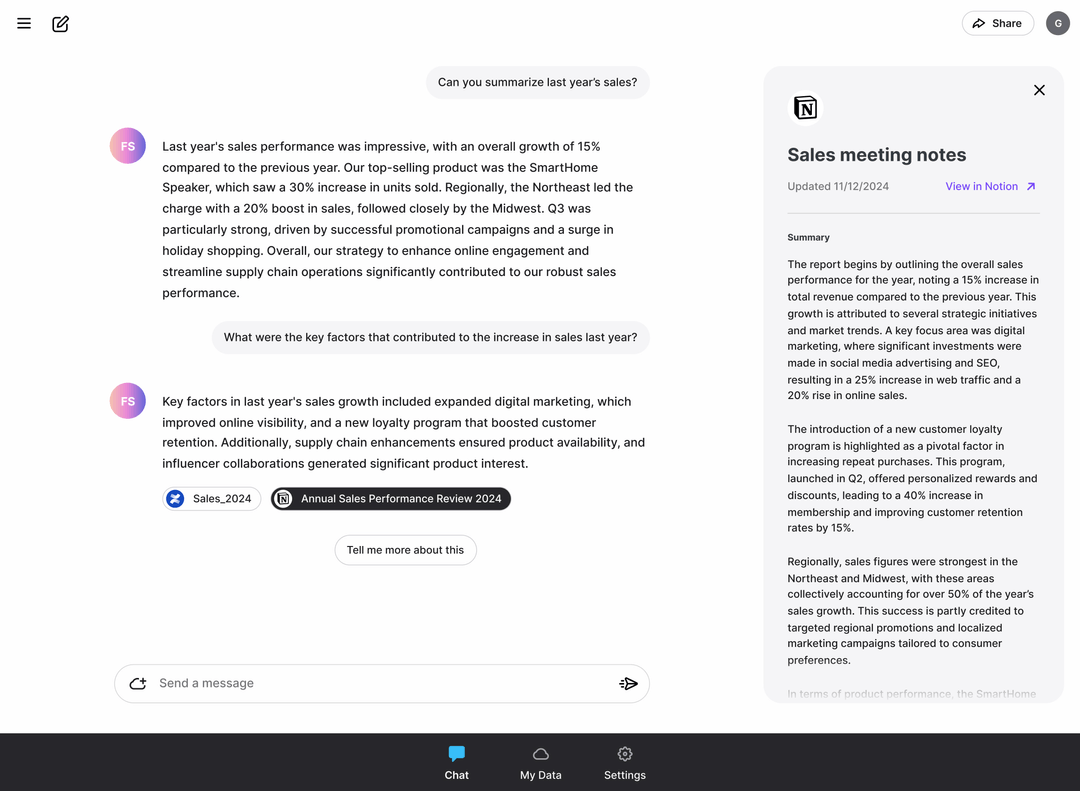
LokalesPdfChatRAG ist ein Open-Source-Projekt, das darauf abzielt, durch die Kombination von lokalen PDF-Dokumenten mit Retrieval Augmented Generation (RAG)-Modellen intelligente Chats zu ermöglichen. Das Projekt ermöglicht es Benutzern, PDF-Dokumente hochzuladen und durch natürlichsprachliche Fragen relevante Informationen aus dem Dokument zu erhalten. lokalPdfChatRAG nutzt fortschrittliche Technologien zur Verarbeitung natürlicher Sprache, um eine effiziente und genaue Suche nach Dokumenteninhalten und Frage- und Antwortservices für eine Vielzahl von Szenarien zu bieten, einschließlich akademischer Forschung und Dokumentenmanagement in Unternehmen.

Funktionsliste
- PDF-Dokument hochladenBenutzer können lokale PDF-Dokumente hochladen, das System analysiert und extrahiert den Textinhalt automatisch.
- Quiz zur natürlichen SpracheBenutzer können Fragen in natürlicher Sprache stellen, und das System wird die relevanten Informationen aus dem hochgeladenen PDF-Dokument abrufen und Antworten generieren.
- Integration von Informationen aus mehreren QuellenUnterstützung für die Kombination von lokalen PDF-Dokumenten und Web-Suchergebnissen, um umfassendere Antworten zu erhalten.
- VektorisierungVectorisation of text using embedding models to improve retrieval and Q&A accuracy.
- Konfiguration der UmgebungsvariablenUnterstützung der Konfiguration von API-Schlüsseln und anderen Parametern über .env-Dateien für benutzerdefinierte Einstellungen.
Hilfe verwenden
Einbauverfahren
- Klonprojekt: Führen Sie den folgenden Befehl im Terminal aus, um den Projektcode zu klonen:
git clone https://github.com/weiwill88/Local_Pdf_Chat_RAG.git
- Installation von Abhängigkeiten: Wechseln Sie in das Projektverzeichnis und installieren Sie die erforderlichen Abhängigkeiten:
cd Local_Pdf_Chat_RAG
pip install -r requirements.txt
- Umgebungsvariablen konfigurieren: Erstellen einer
.envDatei und fügen Sie Folgendes hinzu:
SERPAPI_KEY=your_serpapi_key
Oberbefehlshaber (Militär)your_serpapi_keyErsetzen Sie ihn durch Ihren SerpAPI-Schlüssel.
Verwendungsprozess
- Neue Dienste: Führen Sie den folgenden Befehl im Terminal aus, um den Dienst zu starten:
python rag_demo.py
- Hochladen von PDF-DokumentenÖffnen Sie Ihren Browser, um auf die lokale Serviceadresse zuzugreifen, und laden Sie das PDF-Dokument hoch, das Sie bearbeiten möchten.
- Fragen stellenGeben Sie Ihre Frage in das Eingabefeld ein und das System wird die relevanten Informationen aus dem hochgeladenen PDF-Dokument abrufen und eine Antwort generieren.
Detaillierte Funktionsweise
- PDF-Dokument hochladenKlicken Sie auf die Schaltfläche "Hochladen" und wählen Sie die lokale PDF-Datei aus. Das System wird den Inhalt des Dokuments automatisch analysieren und in der Datenbank speichern.
- Quiz zur natürlichen SpracheGeben Sie eine Frage in das Eingabefeld ein, z. B. "Was ist die wichtigste Schlussfolgerung dieser Arbeit?". Das System extrahiert die relevanten Absätze aus dem PDF-Dokument und generiert eine Antwort.
- Integration von Informationen aus mehreren QuellenDas System wird nicht nur Informationen aus lokalen PDF-Dokumenten abrufen, sondern auch Web-Suchen über SerpAPI durchführen, wobei mehrere Informationsquellen integriert werden, um umfassendere Antworten zu liefern.
- VektorisierungDas System verwendet das SentenceTransformer-Modell zur Vektorisierung von Text, um eine hohe Genauigkeit bei der Suche und bei Fragen und Antworten zu gewährleisten.
- Konfiguration der UmgebungsvariablenBenutzer können die Parameter in der .env-Datei ändern, um API-Schlüssel, Suchmaschinen usw. nach ihren Bedürfnissen zu konfigurieren.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...