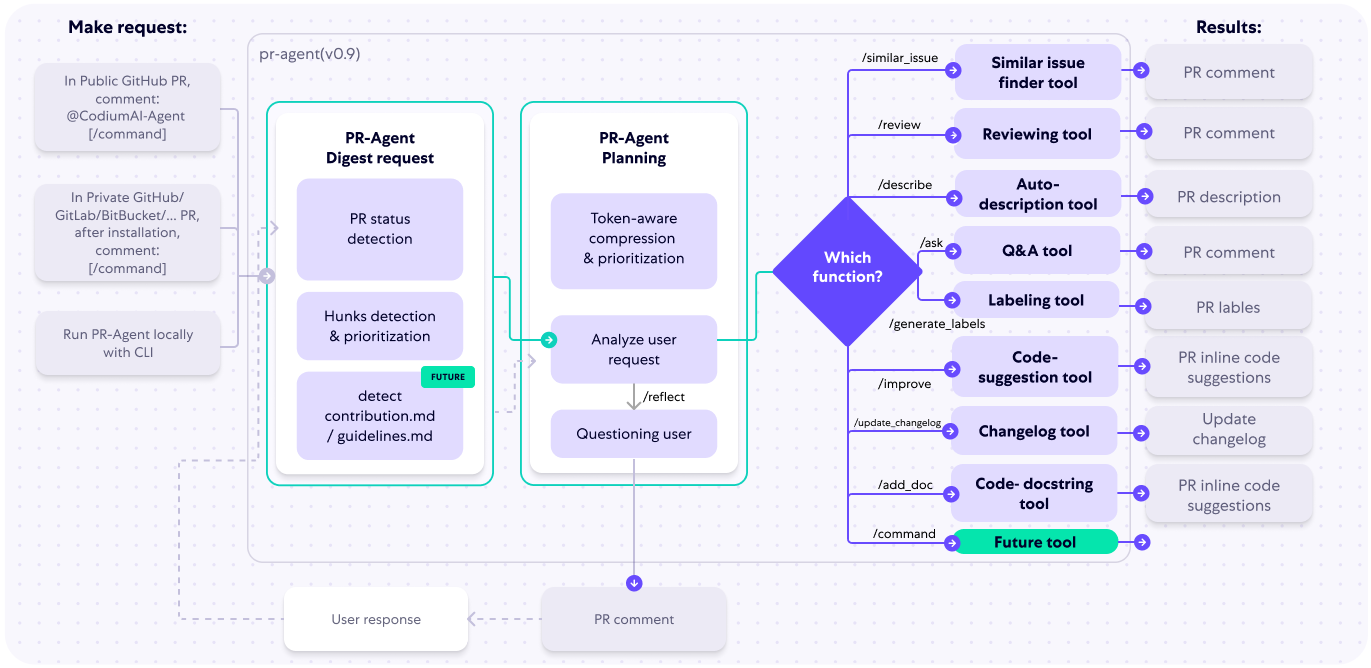
LettuceDetect: ein effizientes Werkzeug zur Erkennung von Halluzinationen im RAG-System

Allgemeine Einführung
LettuceDetect ist ein von KRLabsOrg entwickeltes, leichtgewichtiges Open-Source-Tool, das speziell für die Erkennung von illusorischen Inhalten in Retrieval Augmented Generation (RAG)-Systemen entwickelt wurde. Es hilft Entwicklern, den Kontext zu verbessern, indem es den Kontext, die Frage und die Antwort vergleicht und die Teile der Antwort identifiziert, die nicht durch den Kontext unterstützt werden. RAG Systemgenauigkeit. Das Tool basiert auf der ModernBERT-Technologie und unterstützt 4096 Token LettuceDetect wurde entwickelt, um eine lange Kontextverarbeitung zu ermöglichen, die effizienter als herkömmliche Encoder-Modelle und weitaus weniger rechenintensiv als Large Language Models (LLMs) ist. LettuceDetect schneidet im RAGTruth-Datensatz gut ab, mit einem F1-Score von 79,22% für die Large-Model-Version, und übertrifft damit eine Reihe bestehender Lösungen. Das Projekt ist unter der MIT-Lizenz veröffentlicht, und der Code und das Modell sind frei und offen für Benutzer, die die Zuverlässigkeit von KI-generierten Inhalten optimieren müssen.

Funktionsliste
- Erkennung des TokenpegelsAnalysieren Sie die Antworten Wort für Wort und markieren Sie den Abschnitt mit den Halluzinationen genau.
- Erkennung des FüllstandsIdentifizieren Sie vollständige Phantomsegmente in einer Antwort, Ausgabeposition und Konfidenzniveau.
- lange KontextverarbeitungKontexte: Unterstützung von 4096 Token für komplexe Aufgaben.
- Effizientes ReasoningDas Modell ist als 150M- und 396M-Modell erhältlich und verarbeitet 30-60 Samples pro Sekunde auf einer einzigen GPU.
- Open-Source-IntegrationInstalliert über pip, bietet eine saubere Python-API und ist leicht in ein RAG-System einzubinden.
- Mehrere AusgabeformateUnterstützt Wahrscheinlichkeit auf Token-Ebene und Vorhersageergebnisse auf Spannebene zur einfachen Analyse.
- LeistungsmaßstabDetaillierte Bewertungsdaten sind im RAGTruth-Datensatz verfügbar, um Vergleiche zu erleichtern.
Hilfe verwenden
LettuceDetect ist ein leichtgewichtiges und effizientes Tool, das mit einer einfachen Installation schnell in Betrieb genommen werden kann. Im Folgenden finden Sie eine detaillierte Installations- und Nutzungsanleitung, die Ihnen hilft, die Funktionen von Grund auf zu beherrschen.
Einbauverfahren
- Vorbereiten der Python-Umgebung
Vergewissern Sie sich, dass Sie Python 3.8 oder höher installiert haben und dass Sie über das Dienstprogramm pip verfügen. Eine virtuelle Umgebung wird empfohlen:python -m venv venv source venv/bin/activate # Linux/Mac venv\Scripts\activate # Windows
- Installation von LettuceDetect
Installieren Sie die neueste Version von PyPI:pip install lettucedetectDer Installationsprozess lädt automatisch die wichtigsten Abhängigkeiten herunter, einschließlich des ModernBERT-Modells.
- Überprüfen der Installation
Überprüfen Sie den Erfolg, indem Sie den folgenden Code in einem Python-Terminal ausführen:from lettucedetect.models.inference import HallucinationDetector print("LettuceDetect 安装成功!")
Grundlegende Verwendung
LettuceDetect bietet eine saubere Python-API zur Erkennung von Halluzinationen mit nur wenigen Zeilen Code. Unten ist ein einfaches Beispiel:
Beispielcode (Rechnen)
from lettucedetect.models.inference import HallucinationDetector
# 初始化检测器
detector = HallucinationDetector(
method="transformer",
model_path="KRLabsOrg/lettucedect-base-modernbert-en-v1"
)
# 输入数据
contexts = ["France is a country in Europe. The capital of France is Paris. The population of France is 67 million."]
question = "What is the capital of France? What is the population of France?"
answer = "The capital of France is Paris. The population of France is 69 million."
# 执行 span 级检测
predictions = detector.predict(
context=contexts,
question=question,
answer=answer,
output_format="spans"
)
# 输出结果
print("检测结果:", predictions)
Beispielhafte Ausgabe::
检测结果: [{'start': 31, 'end': 71, 'confidence': 0.994, 'text': ' The population of France is 69 million.'}]
Die Ergebnisse zeigen, dass "die Bevölkerung beträgt 69 Millionen" als Illusion bezeichnet wird, weil der Kontext eine Bevölkerung von 67 Millionen nahelegt.
Hauptfunktionen
1. Initialisierung des Detektors
- Beschreibung der Parameter::
method: Derzeit wird nur "transformer" unterstützt.model_path: FakultativKRLabsOrg/lettucedect-base-modernbert-en-v1(150M) oderKRLabsOrg/lettucedect-large-modernbert-en-v1(396M).
- RiggDie Basisversion ist leicht und schnell, während die große Version genauer ist.
2. Vorbereiten auf den Eintritt
- KontextÜbergeben Sie eine Liste von Zeichenketten mit Hintergrundinformationen, die auf Englisch sein müssen.
- FrageGeben Sie spezifische Fragen ein, die für den Kontext relevant sein müssen.
- AntwortRAG: Geben Sie die vom RAG-System generierten Antworten ein.
- zur Kenntnis nehmenSicherstellen, dass die Gesamtlänge des Kontextes 4096 Token nicht überschreitet.
3. Laufzeiterkennung
- eine Methode aufrufen: Verwendung
detector.predict(). - Ausgabeformat::
"spans"Start- und Endposition, Text und Vertrauensstufe des Halluzinationsclips."tokens"Rückgabe der illusorischen Wahrscheinlichkeit jedes Tokens.
- RiggWählen Sie das geeignete Ausgabeformat, die Spannebene für einen schnellen Überblick und die Token-Ebene für eine gründliche Analyse.
4. Analyse
- Span Level OutputUntersuchen Sie jedes halluzinatorische Fragment der
textim Gesang antwortenconfidenceDas Konfidenzniveau liegt nahe bei 1, was auf eine hohe Wahrscheinlichkeit von Halluzinationen hinweist. - Token-Level-Ausgang: Wort-für-Wort-Ansicht
probWerte, um bestimmte Fehlerpunkte zu ermitteln. - Nachbereitung der BehandlungOptimieren Sie das RAG-System oder protokollieren Sie Probleme auf der Grundlage der Ergebnisse.
Ausgewählte Funktionen
Erkennung des Tokenpegels
LettuceDetect unterstützt eine Wort-für-Wort-Analyse, um eine feinkörnige Erkennung von Halluzinationen zu ermöglichen:
predictions = detector.predict(
context=contexts,
question=question,
answer=answer,
output_format="tokens"
)
print(predictions)
Beispielhafte Ausgabe::
检测结果: [{'token': '69', 'pred': 1, 'prob': 0.95}, {'token': 'million', 'pred': 1, 'prob': 0.95}]
Dies deutet darauf hin, dass "69 Millionen" als eine Illusion bezeichnet wird, die für Szenarien geeignet ist, die eine genaue Abstimmung erfordern.
Lange Kontextunterstützung
Für lange Textaufgaben kann LettuceDetect 4096 Token verarbeiten:
contexts = ["A long context repeated many times..." * 50]
predictions = detector.predict(context=contexts, question="...", answer="...")
Achten Sie nur darauf, dass die Eingabe innerhalb der Grenzen liegt.
Streamlit-Demo
LettuceDetect bietet interaktive Präsentationen:
- Installieren Sie Streamlit:
pip install streamlit - Starten Sie die Demo:
streamlit run demo/streamlit_demo.py - Geben Sie Kontext, Fragen und Antworten in Ihren Browser ein, um die Testergebnisse in Echtzeit anzuzeigen.
Erweiterte Verwendung
Training benutzerdefinierter Modelle
- Laden Sie den RAGTruth-Datensatz herunter (Link (auf einer Website)), setzen Sie die
data/ragtruthMappe. - Vorverarbeitung der Daten:
python lettucedetect/preprocess/preprocess_ragtruth.py --input_dir data/ragtruth --output_dir data/ragtruth - Ausbildungsmodelle:
python scripts/train.py --data_path data/ragtruth/ragtruth_data.json --model_name answerdotai/ModernBERT-base --output_dir outputs/hallucination_detector --batch_size 4 --epochs 6 --learning_rate 1e-5
Leistungsoptimierung
- GPU-BeschleunigungInstallieren Sie die PyTorch CUDA-Version, um die Inferenzgeschwindigkeit zu erhöhen.
- Stapeldatei: Legen Sie mehrere Proben in den
contextsListe der einmaligen Tests.
caveat
- Die Eingabe muss in Englisch erfolgen, andere Sprachen werden derzeit nicht unterstützt.
- Stellen Sie sicher, dass das Netzwerk geöffnet ist, damit das Modell beim ersten Lauf heruntergeladen werden kann.
Mit den oben genannten Schritten können Benutzer LettuceDetect leicht verwenden, um Täuschungen des RAG-Systems zu erkennen und die Zuverlässigkeit der generierten Inhalte zu verbessern.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...