Zusammenfassungen.
In diesem Beitrag wird ein neuer Satz von Basismodellen mit dem Namen Llama 3 vorgestellt. Llama 3 ist eine Gemeinschaft von Sprachmodellen, die Mehrsprachigkeit, das Schreiben von Code, logisches Denken und die Verwendung von Werkzeugen unterstützt. Unser größtes Modell ist ein dichter Transformer mit 405 Milliarden Parametern und einem Kontextfenster von bis zu 128.000 Token.Dieses Papier führt eine umfangreiche Reihe von empirischen Bewertungen von Llama 3 durch. Die Ergebnisse zeigen, dass Llama 3 bei vielen Aufgaben eine Qualität erreicht, die mit führenden Sprachmodellen wie GPT-4 vergleichbar ist. Wir stellen Llama 3 öffentlich zur Verfügung, einschließlich vor- und nachtrainierter Sprachmodelle mit 405 Milliarden Parametern sowie des Llama Guard 3 Modells für Input-Output-Sicherheit. In diesem Papier werden auch experimentelle Ergebnisse zur Integration von Bild-, Video- und Sprachmerkmalen in Llama 3 durch einen kombinatorischen Ansatz vorgestellt. Wir stellen fest, dass dieser Ansatz mit den modernsten Ansätzen für Bild-, Video- und Spracherkennungsaufgaben konkurrieren kann. Da sich diese Modelle noch in der Entwicklungsphase befinden, sind sie noch nicht allgemein veröffentlicht worden.
Volltext herunterladen pdf:

1 Einleitung
Grundmodellsind allgemeine Modelle der Sprache, des Sehens, der Sprache und anderer Modalitäten, die zur Unterstützung einer breiten Palette von KI-Aufgaben entwickelt wurden. Sie bilden die Grundlage für viele moderne KI-Systeme.
Die Entwicklung eines modernen Basismodells gliedert sich in zwei Hauptphasen:
(1) Vorschulungsphase. Die Modelle werden anhand großer Datenmengen trainiert, wobei einfache Aufgaben wie die Vorhersage von Wörtern oder die Erstellung von Diagrammkommentaren verwendet werden;
(2) Nachbereitungsphase. Modelle werden fein abgestimmt, um Anweisungen zu befolgen, sich an menschlichen Vorlieben zu orientieren und bestimmte Fähigkeiten zu verbessern (z. B. Codierung und logisches Denken).
In diesem Beitrag wird eine neue Reihe von Sprachbasismodellen mit dem Namen Llama 3 vorgestellt. Die Llama 3 Herd-Familie von Modellen unterstützt von Haus aus Mehrsprachigkeit, Kodierung, Argumentation und Werkzeugnutzung. Unser größtes Modell ist ein dichter Transformer mit 405B Parametern, der Informationen in Kontextfenstern von bis zu 128K Token verarbeiten kann.
In Tabelle 1 sind die einzelnen Mitglieder der Herde aufgeführt. Alle in diesem Dokument vorgestellten Ergebnisse basieren auf dem Modell Llama 3.1 (kurz Llama 3).
Wir sind der Meinung, dass die drei wichtigsten Instrumente für die Entwicklung qualitativ hochwertiger Basismodelle Daten, Maßstab und Komplexitätsmanagement sind. Wir werden uns bemühen, diese drei Bereiche während unseres Entwicklungsprozesses zu optimieren:
- Daten. Sowohl die Quantität als auch die Qualität der Daten, die wir für das Pre- und Post-Training verwendet haben, wurden im Vergleich zu früheren Versionen von Llama verbessert (Touvron et al., 2023a, b). Zu diesen Verbesserungen gehören die Entwicklung sorgfältigerer Vorverarbeitungs- und Kuratierungspipelines für die Pre-Trainingsdaten sowie die Entwicklung einer strengeren Qualitätssicherung und Filterung. Entwicklung sorgfältigerer Vorverarbeitungs- und Kuratierungspipelines für Pre-Training-Daten und Entwicklung strengerer Qualitätssicherungs- und Filterverfahren Llama 3 wurde auf einem Korpus von etwa 15T mehrsprachigen Token vortrainiert, während Llama 2 auf 1,8T Token vortrainiert wurde.
- Umfang. Wir haben ein größeres Modell als das vorherige Llama-Modell trainiert: Unser Flaggschiff-Sprachmodell verwendet 3,8 × 1025 FLOPs für das Pre-Training, fast 50 Mal mehr als die größte Version von Llama 2. Konkret haben wir ein Vorzeigemodell mit 405B trainierbaren Parametern auf 15,6T Text-Token vortrainiert. Wie erwartet, ist die

- Komplexität bewältigen. Die von uns getroffenen Designentscheidungen zielten darauf ab, die Skalierbarkeit des Modellentwicklungsprozesses zu maximieren. So haben wir zum Beispiel einen dichten Standard Transformator Modellarchitektur (Vaswani et al., 2017) mit einigen geringfügigen Anpassungen, anstatt ein Experten-Mischmodell (Shazeer et al., 2017) zu verwenden, um die Trainingsstabilität zu maximieren. In ähnlicher Weise haben wir einen relativ einfachen Postprozessor verwendet, der auf überwachtem Fine-Tuning (SFT), Rejection Sampling (RS) und direkter Präferenzoptimierung (DPO; Rafailov et al. (2023)) basiert, anstatt komplexere Reinforcement-Learning-Algorithmen (Ouyang et al., 2022; Schulman et al., 2017) zu verwenden, die oft weniger stabil und schwierig zu skalieren sind.
Das Ergebnis unserer Arbeit ist Llama 3: eine dreisprachige Mehrsprachigkeit mit 8B, 70B und 405B Parametern.1Population von Sprachmodellen. Wir haben die Leistung von Llama 3 anhand einer großen Anzahl von Benchmark-Datensätzen bewertet, die ein breites Spektrum von Sprachverstehensaufgaben abdecken. Darüber hinaus haben wir umfangreiche manuelle Evaluierungen durchgeführt, bei denen wir Llama 3 mit konkurrierenden Modellen verglichen haben. Tabelle 2 zeigt einen Überblick über die Leistung des Flaggschiffs Llama 3 in den wichtigsten Benchmark-Tests. Unsere experimentellen Auswertungen zeigen, dass unser Flaggschiffmodell mit führenden Sprachmodellen wie GPT-4 (OpenAI, 2023a) mithalten kann und bei einer Vielzahl von Aufgaben nahe am Stand der Technik ist. Unser kleineres Modell ist Klassenbester und übertrifft andere Modelle mit einer ähnlichen Anzahl von Parametern (Bai et al., 2023; Jiang et al., 2023).Llama 3 schafft auch ein besseres Gleichgewicht zwischen Hilfsbereitschaft und Unbedenklichkeit als sein Vorgänger (Touvron et al., 2023b). Wir analysieren die Sicherheit von Llama 3 im Detail in Abschnitt 5.4.
Wir veröffentlichen alle drei Llama-3-Modelle unter einer aktualisierten Version der Llama-3-Community-Lizenz; siehe https://llama.meta.com. Dazu gehören vortrainierte und nachbearbeitete Versionen unseres parametrischen Sprachmodells 405B sowie eine neue Version des Llama-Guard-Modells (Inan et al., 2023) zur Eingabe- und Ausgabesicherheit. und Ausgabesicherheit. Wir hoffen, dass die Veröffentlichung eines Vorzeigemodells eine Innovationswelle in der Forschungsgemeinschaft auslösen und den Fortschritt auf dem Weg zu einer verantwortungsvollen Entwicklung der künstlichen Intelligenz (AGI) beschleunigen wird.
Mehrsprachig: Dies bezieht sich auf die Fähigkeit des Modells, Text in mehreren Sprachen zu verstehen und zu erzeugen.
Während der Entwicklung von Llama 3 haben wir auch multimodale Erweiterungen des Modells entwickelt, um Bilderkennung, Videoerkennung und Sprachverständnis zu ermöglichen. Diese Modelle befinden sich noch in der aktiven Entwicklung und sind noch nicht zur Veröffentlichung bereit. Zusätzlich zu den Ergebnissen unserer Sprachmodellierung werden in diesem Papier die Ergebnisse unserer ersten Experimente mit diesen multimodalen Modellen vorgestellt.
Llama 3 8B und 70B wurden mit mehrsprachigen Daten trainiert, wurden aber zu diesem Zeitpunkt hauptsächlich für Englisch verwendet.

2 Allgemeines
Die Architektur des Llama 3-Modells ist in Abbildung 1 dargestellt. Die Entwicklung unseres Llama 3-Sprachmodells ist in zwei Hauptphasen unterteilt:
- Vortraining des Sprachmodells.Wir konvertieren zunächst ein großes mehrsprachiges Textkorpus in diskrete Token und trainieren ein Large Language Model (LLM) auf den resultierenden Daten für die nächste Token-Vorhersage vor. In der LLM-Pre-Trainingsphase lernt das Modell die Struktur der Sprache und erwirbt eine große Menge an Wissen über die Welt aus dem Text, den es "liest". Um dies effizient zu tun, wird das Pre-Training in großem Maßstab durchgeführt: Wir haben ein Modell mit 405B Parametern auf einem Modell mit 15,6T Token vortrainiert, wobei ein Kontextfenster von 8K Token verwendet wurde. Auf diese Standard-Pre-Trainingsphase folgt eine weitere Pre-Trainingsphase, in der das unterstützte Kontextfenster auf 128K Token erhöht wird. Siehe Abschnitt 3 für weitere Informationen.
- Ausbildung nach der Modellierung.Das vortrainierte Sprachmodell verfügt über ein umfassendes Verständnis der Sprache, hat aber noch nicht die Anweisungen befolgt oder sich wie der Assistent verhalten, den wir von ihm erwarten. Wir haben das Modell durch menschliches Feedback in mehreren Runden kalibriert, wobei jede Runde eine überwachte Feinabstimmung (SFT) und eine direkte Präferenzoptimierung (DPO; Rafailov et al., 2024) auf anweisungsabgestimmten Daten beinhaltete. In dieser Nachtrainings-Phase haben wir auch neue Merkmale, wie die Verwendung von Werkzeugen, integriert und deutliche Verbesserungen in Bereichen wie Codierung und Inferenz beobachtet. Weitere Informationen finden Sie in Abschnitt 4. Schließlich wurden in der Nachtrainings-Phase auch Sicherheitsabschwächungen in das Modell integriert, deren Einzelheiten in Abschnitt 5.4 beschrieben werden. Die generierten Modelle sind sehr funktionsreich. Sie sind in der Lage, Fragen in mindestens acht Sprachen zu beantworten, qualitativ hochwertigen Code zu schreiben, komplexe Inferenzprobleme zu lösen und Tools out-of-the-box oder stichprobenfrei zu verwenden.
Wir führen auch Experimente durch, um Llama 3 durch einen kombinierten Ansatz um Bild-, Video- und Sprachfunktionen zu erweitern. Der von uns untersuchte Ansatz besteht aus drei zusätzlichen Phasen, die in Abbildung 28 dargestellt sind:

- Multimodales Encoder-Vortraining.Wir trainieren separate Kodierer für Bild und Sprache. Wir trainieren den Bildkodierer mit einer großen Anzahl von Bild-Text-Paaren. Dadurch lernt das Modell die Beziehung zwischen dem visuellen Inhalt und seiner natürlichsprachlichen Beschreibung. Unser Sprachcodierer verwendet eine selbstüberwachte Methode, die einen Teil der Spracheingabe maskiert und versucht, den maskierten Teil durch eine diskrete Markerrepräsentation zu rekonstruieren. Auf diese Weise erlernt das Modell die Struktur des Sprachsignals. Weitere Informationen zu Bildkodierern finden Sie in Abschnitt 7 und zu Sprachkodierern in Abschnitt 8.
- Ausbildung zum visuellen Adapter.Wir trainieren einen Adapter, der einen vortrainierten Bildkodierer mit einem vortrainierten Sprachmodell verbindet. Der Adapter besteht aus einer Reihe von Cross-Attention-Schichten, die die Darstellung des Bildkodierers in das Sprachmodell einspeisen. Der Adapter wird auf Text-Bild-Paare trainiert, wodurch die Bildrepräsentation mit der Sprachrepräsentation in Einklang gebracht wird. Während des Trainings des Adapters aktualisieren wir auch die Parameter des Bild-Encoders, nicht aber die Parameter des Sprachmodells. Wir trainieren auch einen Videoadapter zusätzlich zum Bildadapter, indem wir gepaarte Video-Text-Daten verwenden. Dadurch kann das Modell Informationen über mehrere Bilder hinweg zusammenfassen. Für weitere Informationen siehe Abschnitt 7.
- Schließlich integrieren wir den Sprachkodierer über einen Adapter in das Modell, der die Sprachkodierung in eine tokenisierte Repräsentation umwandelt, die direkt in das feinabgestimmte Sprachmodell eingespeist werden kann. Während der überwachten Feinabstimmungsphase werden die Parameter des Adapters und des Encoders gemeinsam aktualisiert, um ein hochwertiges Sprachverständnis zu erreichen. Das Sprachmodell wird während des Trainings des Sprachadapters nicht verändert. Wir integrieren auch ein Text-to-Speech-System. Siehe Abschnitt 8 für weitere Einzelheiten.
Unsere multimodalen Experimente haben zu Modellen geführt, die den Inhalt von Bildern und Videos erkennen und die Interaktion über eine Sprachschnittstelle unterstützen. Diese Modelle befinden sich noch in der Entwicklung und sind noch nicht zur Veröffentlichung bereit.
3 Vorschulung
Das Vortraining von Sprachmodellen umfasst die folgenden Aspekte:
(1) Sammeln und Filtern großer Trainingskorpora;
(2) Entwicklung von Modellarchitekturen und entsprechenden Skalierungsgesetzen zur Bestimmung der Modellgröße;
(3) Entwicklung von Techniken für effizientes Pre-Training in großem Maßstab;
(4) Entwicklung eines Vorschulungsprogramms. Jede dieser Komponenten wird im Folgenden beschrieben.
3.1 Daten vor dem Training
Wir haben aus verschiedenen Datenquellen Datensätze für das Vortraining von Sprachmodellen erstellt, die Wissen bis Ende 2023 enthalten. Für jede Datenquelle haben wir mehrere Deduplizierungsmethoden und Datenbereinigungsmechanismen angewandt, um eine hochwertige Kennzeichnung zu erhalten. Wir haben Domänen mit großen Mengen an personenbezogenen Daten sowie Domänen mit bekanntermaßen nicht jugendfreien Inhalten entfernt.
3.11 Bereinigung von Webdaten
Die meisten der von uns verwendeten Daten stammen aus dem Internet, und wir beschreiben im Folgenden unseren Bereinigungsprozess.
PII und Sicherheitsfilterung. Neben anderen Maßnahmen haben wir Filter implementiert, die Daten von Websites entfernen, die möglicherweise unsichere Inhalte oder große Mengen personenbezogener Daten enthalten, von Domains, die nach verschiedenen Meta-Sicherheitsstandards als schädlich eingestuft sind, und von Domains, die bekanntermaßen nicht jugendfreie Inhalte enthalten.
Extraktion und Bereinigung von Text. Wir verarbeiten rohe HTML-Inhalte, um hochwertigen, vielfältigen Text zu extrahieren, und verwenden zu diesem Zweck nicht abgeschnittene Webdokumente. Zu diesem Zweck haben wir einen benutzerdefinierten Parser entwickelt, der HTML-Inhalte extrahiert und die Genauigkeit der Vorlagenentfernung sowie die Wiedererkennung von Inhalten optimiert. Wir haben die Qualität des Parsers durch eine manuelle Bewertung beurteilt und ihn mit populären HTML-Parsern von Drittanbietern verglichen, die für den Inhalt ähnlicher Artikel optimiert sind, und festgestellt, dass er gut funktioniert. Bei HTML-Seiten, die Mathematik- und Codeinhalte enthalten, achten wir darauf, dass die Struktur dieser Inhalte erhalten bleibt. Wir behalten den Text des Alt-Attributs für Bilder bei, da mathematische Inhalte in der Regel als vorgerendertes Bild dargestellt werden, bei dem die Mathematik ebenfalls im Alt-Attribut enthalten ist.
Wir haben festgestellt, dass Markdown die Leistung des Modells, das hauptsächlich auf Webdaten trainiert wurde, im Vergleich zu reinem Text beeinträchtigt, daher haben wir alle Markdown-Tags entfernt.
Betonung abbauen. Wir führen mehrere Deduplizierungsrunden auf URL-, Dokument- und Zeilenebene durch:
- De-Duplizierung auf URL-Ebene. Wir führen eine Deduplizierung auf URL-Ebene für den gesamten Datensatz durch. Für jede Seite, die einer URL entspricht, behalten wir die letzte Version.
- De-Duplizierung auf Dokumentenebene. Wir führen eine globale MinHash-Deduplizierung (Broder, 1997) für den gesamten Datensatz durch, um nahezu doppelte Dokumente zu entfernen.
- De-Duplizierung auf Zeilenebene. Wir führen eine radikale Deduplizierung ähnlich wie bei ccNet (Wenzek et al., 2019) durch. Wir entfernen Zeilen, die mehr als 6 Mal in jeder Gruppe mit 30 Millionen Dokumenten vorkommen.
Obwohl unsere manuellen qualitativen Analysen darauf hindeuten, dass die De-Duplizierung auf Zeilenebene nicht nur den restlichen Standardinhalt einer Vielzahl von Websites (z. B. Navigationsmenüs, Cookie-Warnungen), sondern auch häufigen hochwertigen Text entfernt, zeigen unsere empirischen Auswertungen deutliche Verbesserungen.
Heuristische Filterung. Es wurden Heuristiken entwickelt, um zusätzliche minderwertige Dokumente, Ausreißer und Dokumente mit zu vielen Wiederholungen zu entfernen. Einige Beispiele für Heuristiken sind:
- Wir verwenden Duplicate n-tuple coverage (Rae et al., 2021), um Zeilen mit doppeltem Inhalt (z. B. Protokolle oder Fehlermeldungen) zu entfernen. Diese Zeilen können sehr lang und eindeutig sein und können daher nicht durch Zeilenduplizierung herausgefiltert werden.
- Wir verwenden eine Zählung von "schmutzigen Wörtern" (Raffel et al., 2020), um Seiten mit nicht jugendfreien Inhalten herauszufiltern, die nicht von der Domain-Blacklist erfasst sind.
- Wir verwenden die Kullback-Leibler-Streuung der Token-Verteilung, um Dokumente herauszufiltern, die im Vergleich zur Verteilung im Trainingskorpus zu viele anomale Token enthalten.
Modellgestützte Qualitätsfilterung.
Darüber hinaus haben wir versucht, verschiedene modellbasierte Qualitätsklassifikatoren für die Auswahl hochwertiger Etiketten zu verwenden. Zu diesen Methoden gehören:
- Verwendung schneller Klassifikatoren wie fasttext (Joulin et al., 2017), die darauf trainiert sind, zu erkennen, ob ein bestimmter Text in Wikipedia zitiert wird (Touvron et al., 2023a).
- Es wurde ein rechenintensiverer Klassifikator nach dem Roberta-Modell (Liu et al., 2019a) verwendet, der anhand der Vorhersagen von Llama 2 trainiert wurde.
Um den auf Llama 2 basierenden Qualitätsklassifikator zu trainieren, haben wir eine Reihe von bereinigten Webdokumenten erstellt, die die Qualitätsanforderungen beschreiben, und das Chat-Modell von Llama 2 angewiesen, zu bestimmen, ob die Dokumente diese Anforderungen erfüllen. Um die Effizienz zu steigern, verwenden wir DistilRoberta (Sanh et al., 2019), um Qualitätsbewertungen für jedes Dokument zu erstellen. Wir werden die Wirksamkeit verschiedener Qualitätsfilterkonfigurationen experimentell bewerten.
Code und Inferenzdaten.
Ähnlich wie DeepSeek-AI et al. (2024) haben wir domänenspezifische Pipelines entwickelt, um Webseiten zu extrahieren, die Code und Mathematik enthalten. Sowohl die Code- als auch die Inferenz-Klassifikatoren sind DistilledRoberta-Modelle, die mit Llama 2 annotierten Webdaten trainiert wurden. Im Gegensatz zu den oben erwähnten generischen Qualitätsklassifikatoren führen wir ein Cue-Tuning durch, um Webseiten mit mathematischen Schlussfolgerungen, Schlussfolgerungen in MINT-Bereichen und in natürliche Sprache eingebetteten Code zu finden. Da sich die Token-Verteilungen von Code und Mathematik stark von denen der natürlichen Sprache unterscheiden, implementieren diese Pipelines eine domänenspezifische HTML-Extraktion, benutzerdefinierte Textmerkmale und Heuristiken für die Filterung.
Mehrsprachige Daten.
Ähnlich wie die oben beschriebene englische Verarbeitungspipeline implementieren wir Filter, um Websitedaten zu entfernen, die möglicherweise personenbezogene Daten oder unsichere Inhalte enthalten. Unsere mehrsprachige Textverarbeitungspipeline weist die folgenden einzigartigen Merkmale auf:
- Wir verwenden ein schnelles textbasiertes Spracherkennungsmodell, um Dokumente in 176 Sprachen zu klassifizieren.
- Wir führen die Datendeduplizierung auf Dokumentenebene und auf Zeilenebene für jede Sprache durch.
- Wir wenden sprachspezifische Heuristiken und modellbasierte Filter an, um minderwertige Dokumente zu entfernen.
Darüber hinaus verwenden wir einen mehrsprachigen Klassifikator auf der Grundlage von Llama 2, um die Qualität mehrsprachiger Dokumente zu bewerten und sicherzustellen, dass hochwertige Inhalte bevorzugt behandelt werden. Die Anzahl der mehrsprachigen Token, die wir im Pre-Training verwenden, wird experimentell bestimmt, und die Modellleistung wird in englischen und mehrsprachigen Benchmark-Tests ausgeglichen.
3.12 Bestimmung des Datenmixes
为了获得高质量语言模型,必须谨慎确定预训练数据混合中不同数据源的比例。我们主要利用知识分类和尺度定律实验来确定这一数据混合。
知识分类。我们开发了一个分类器,用于对网页数据中包含的信息类型进行分类,以便更有效地确定数据组合。我们使用这个分类器对网页上过度代表的数据类别(例如艺术和娱乐)进行下采样。
为了确定最佳数据混合方案。我们进行规模定律实验,其中我们将多个小型模型训练于特定数据混合集上,并利用其预测大型模型在该混合集上的性能(参见第 3.2.1 节)。我们多次重复此过程,针对不同的数据混合集选择新的候选数据混合集。随后,我们在该候选数据混合集上训练一个更大的模型,并在多个关键基准测试上评估该模型的性能。
数据混合摘要。我们的最终数据混合包含大约 50% 的通用知识标记、25% 的数学和推理标记、17% 的代码标记以及 8% 的多语言标记。
3.13 Glühdaten
Empirische Ergebnisse zeigen, dass das Annealing auf einer kleinen Menge hochwertiger Code- und Mathematikdaten (siehe Abschnitt 3.4.3) die Leistung von vortrainierten Modellen in wichtigen Benchmark-Tests verbessern kann. Ähnlich wie in der Studie von Li et al. (2024b) führen wir das Annealing mit einem gemischten Datensatz durch, der hochwertige Daten aus ausgewählten Bereichen enthält. Unsere geglätteten Daten enthalten keine Trainingsdatensätze aus häufig verwendeten Vergleichstests. Dies ermöglicht es uns, die tatsächliche Lernfähigkeit von Llama 3 für wenige Stichproben und die Generalisierung außerhalb der Domäne zu bewerten.
In Anlehnung an OpenAI (2023a) haben wir die Auswirkung von Annealing auf die Trainingssätze GSM8k (Cobbe et al., 2021) und MATH (Hendrycks et al., 2021b) untersucht. Wir stellen fest, dass Annealing die Leistung des vortrainierten Llama 3 8B-Modells um 24,0% bzw. 6,4% auf den GSM8k- und MATH-Validierungssätzen verbessert, während die Verbesserung für das 405B-Modell vernachlässigbar ist, was darauf hindeutet, dass unser Vorzeigemodell über starke kontextuelle Lern- und Schlussfolgerungsfähigkeiten verfügt und dass es keine domänenspezifischen Trainingsmuster benötigt, um eine robuste Leistung zu erzielen.
Bewerten Sie die Datenqualität durch Glühen.Wie Blakeney et al. (2024) stellen wir fest, dass wir mit Hilfe von Annealing den Wert kleiner domänenspezifischer Datensätze beurteilen können. Wir messen den Wert dieser Datensätze, indem wir die Lernrate des Llama 3 8B-Modells, das mit 50% trainiert wurde, über 40 Milliarden Token linear auf 0 annealen. In diesen Experimenten weisen wir dem neuen Datensatz 30%-Gewichte zu und die restlichen 70%-Gewichte dem Standarddatenmix. Es ist effizienter, neue Datenquellen durch Annealing zu evaluieren, als Skalierungsexperimente mit jedem kleinen Datensatz durchzuführen.
3.2 Modellarchitektur
Llama 3 verwendet die standardmäßige dichte Transformer-Architektur (Vaswani et al., 2017). Die Modellarchitektur unterscheidet sich nicht wesentlich von Llama und Llama 2 (Touvron et al., 2023a, b); unsere Leistungssteigerungen sind in erster Linie auf Verbesserungen bei der Datenqualität und -vielfalt sowie auf die Vergrößerung der Trainingsgröße zurückzuführen.
Wir haben ein paar kleine Änderungen vorgenommen:
- Wir verwenden Grouped Query Attention (GQA; Ainslie et al. (2023)), bei der 8 Key-Value-Header verwendet werden, um die Inferenzgeschwindigkeit zu erhöhen und die Größe des Key-Value-Cache während der Dekodierung zu reduzieren.
- Wir verwenden eine Aufmerksamkeitsmaske, um Mechanismen der Selbstaufmerksamkeit zwischen verschiedenen Dokumenten in der Sequenz zu verhindern. Wir stellen fest, dass diese Änderung beim Standard-Pre-Training nur begrenzte Auswirkungen hat, beim kontinuierlichen Pre-Training von sehr langen Sequenzen jedoch wichtig ist.
- Wir verwenden ein Vokabular von 128K Token. Unser tokenisiertes Vokabular kombiniert die 100K Token des tiktoken3-Vokabulars mit 28K zusätzlichen Token, um nicht-englische Sprachen besser zu unterstützen. Im Vergleich zum Vokabular von Llama 2 verbessert unser neues Vokabular die Komprimierung von englischen Datenproben von 3,17 auf 3,94 Zeichen/Token. Dadurch kann das Modell bei gleichem Trainingsaufwand mehr Text "lesen". Wir haben auch festgestellt, dass das Hinzufügen von 28K Token aus bestimmten nicht-englischen Sprachen die Kompression und die nachgelagerte Leistung verbessert, während es keine Auswirkungen auf die englische Tokenisierung hat.
- Wir erhöhen den RoPE-Basisfrequenz-Hyperparameter auf 500.000. Damit können wir längere Kontexte besser unterstützen; Xiong et al. (2023) zeigen, dass dieser Wert für Kontextlängen bis zu 32.768 gültig ist.

Das Llama 3 405B verwendet eine Architektur mit 126 Schichten, 16.384 Marker-Repräsentationsdimensionen und 128 Aufmerksamkeitsköpfen; weitere Informationen finden Sie in Tabelle 3. Dies führt zu einer Modellgröße, die auf der Grundlage unserer Daten und eines Trainingsbudgets von 3,8 × 10^25 FLOPs annähernd rechnerisch optimal ist.
3.2.1 Gesetz der Skala
Wir haben die Skalierungsgesetze (Hoffmann et al., 2022; Kaplan et al., 2020) verwendet, um die optimale Größe des Flaggschiffmodells unter Berücksichtigung unseres Rechenbudgets vor dem Training zu bestimmen. Neben der Bestimmung der optimalen Modellgröße stellt die Vorhersage der Leistung des Flaggschiffmodells bei nachgelagerten Benchmark-Aufgaben aus den folgenden Gründen eine große Herausforderung dar:
- Bestehende Skalierungsgesetze sagen in der Regel nur den Verlust der nächsten Markierungsvorhersage voraus, nicht aber eine bestimmte Benchmarking-Leistung.
- Skalierungsgesetze können verrauscht und unzuverlässig sein, da sie auf der Grundlage von Vortrainingsläufen mit einem geringen Rechenbudget entwickelt werden (Wei et al., 2022b).
Um diese Herausforderungen zu bewältigen, haben wir einen zweistufigen Ansatz zur Entwicklung von Skalierungsgesetzen entwickelt, die eine genaue Vorhersage der Downstream-Benchmarking-Leistung ermöglichen:
- Wir stellen zunächst die Korrelation zwischen den FLOPs vor dem Training und der Berechnung der negativen Log-Likelihood des besten Modells für die nachgelagerte Aufgabe fest.
- Als Nächstes korrelieren wir die negative Log-Wahrscheinlichkeit bei der nachgelagerten Aufgabe mit der Aufgabengenauigkeit unter Verwendung des Modells der Skalierungsgesetze und eines älteren Modells, das zuvor mit einer höheren Rechenleistung (FLOPs) trainiert wurde. In diesem Schritt verwenden wir ausschließlich die Llama-2-Modellfamilie.
Mit diesem Ansatz können wir die nachgelagerte Aufgabenleistung (für rechnerisch optimale Modelle) auf der Grundlage einer bestimmten Anzahl von vortrainierten FLOPs vorhersagen. Wir verwenden einen ähnlichen Ansatz, um unsere Kombination von Vortrainingsdaten auszuwählen (siehe Abschnitt 3.4).
Skalierung Rechtsexperiment.Konkret haben wir Skalierungsgesetze konstruiert, indem wir Modelle mit Rechenbudgets zwischen 6 × 10^18 FLOPs und 10^22 FLOPs vortrainiert haben. Bei jedem Rechenbudget haben wir Modelle mit Größen zwischen 40M und 16B Parametern vortrainiert und einen Bruchteil der Modellgröße bei jedem Rechenbudget verwendet. Bei diesen Trainingsläufen verwenden wir eine kosinusförmige Lernratenplanung und ein lineares Warm-up innerhalb von 2.000 Trainingsschritten. Die Spitzenlernrate wurde je nach Modellgröße zwischen 2 × 10^-4 und 4 × 10^-4 festgelegt. Der Cosinus-Abfall wurde auf das 0,1-fache des Spitzenwertes festgelegt. Der Gewichtsabfall für jeden Schritt wurde auf das 0,1-fache der Lernrate für diesen Schritt festgelegt. Für jede Berechnungsgröße wurde eine feste Stapelgröße verwendet, die von 250K bis 4M reichte.

Diese Experimente ergaben die IsoFLOPs-Kurven in Abbildung 2. Die Verluste in diesen Kurven wurden an separaten Validierungssätzen gemessen. Wir passen die gemessenen Verlustwerte mit einem Polynom zweiter Ordnung an und bestimmen den Minimalwert jeder Parabel. Wir bezeichnen das Minimum der Parabel als das rechnerisch optimale Modell unter dem entsprechenden vortrainierten Berechnungsbudget.
Wir verwenden die auf diese Weise ermittelten rechnerisch optimalen Modelle, um die optimale Anzahl von Trainings-Token für ein gegebenes Rechenbudget vorherzusagen. Zu diesem Zweck nehmen wir eine Potenzgesetz-Beziehung zwischen dem Berechnungsbudget C und der optimalen Anzahl von Trainingstoken N (C) an:
N (C) = AC α .
Wir passen A und α anhand der Daten in Abb. 2 an. Wir finden (α, A) = (0,53, 0,29); die entsprechende Anpassung ist in Abb. 3 dargestellt. Die Extrapolation des resultierenden Skalierungsgesetzes auf 3,8 × 10 25 FLOPs legt nahe, ein Modell mit 402B Parametern zu trainieren und 16,55T Token zu verwenden.
Eine wichtige Beobachtung ist, dass die IsoFLOPs-Kurve um das Minimum herum flacher wird, wenn das Berechnungsbudget steigt. Dies bedeutet, dass die Leistung des Flaggschiffmodells relativ stabil ist, wenn der Kompromiss zwischen Modellgröße und Trainingsmarkern geringfügig variiert. Auf der Grundlage dieser Beobachtung haben wir schließlich beschlossen, ein Flaggschiffmodell zu trainieren, das den Parameter 405B enthält.
Vorhersage der Leistung bei nachgelagerten Aufgaben.Wir verwenden das generierte rechnerisch optimale Modell, um die Leistung des Vorzeigemodells Llama 3 auf dem Benchmark-Datensatz vorherzusagen. Zunächst setzen wir die (normierte) negative logarithmische Wahrscheinlichkeit der richtigen Antwort im Benchmark in linearen Zusammenhang mit den Trainings-FLOPs. Für diese Analyse haben wir nur das Skalierungsgesetz-Modell verwendet, das auf 10^22 FLOPs auf der oben genannten Datenmischung trainiert wurde. Als Nächstes haben wir eine S-förmige Beziehung zwischen der Log-Likelihood und der Genauigkeit unter Verwendung des Scaling-Law-Modells und des Llama-2-Modells ermittelt, das mit dem Llama-2-Datenmix und dem Tagger trainiert wurde. (Die Ergebnisse dieses Experiments mit dem ARC-Challenge-Benchmark sind in Abbildung 4 dargestellt). Wir stellen fest, dass diese zweistufige Vorhersage nach dem Skalierungsgesetz (extrapoliert über vier Größenordnungen) recht genau ist: Sie unterschätzt die endgültige Leistung des Vorzeigemodells Llama 3 nur leicht.
3.3 Infrastruktur, Ausbau und Effizienz
Wir beschreiben die Hardware und die Infrastruktur, die das Llama 3 405B Pre-Training unterstützen und diskutieren verschiedene Optimierungen, die die Trainingseffizienz verbessern.
3.3.1 Ausbildungsinfrastruktur
Die Modelle Llama 1 und Llama 2 wurden auf dem KI-Forschungs-Supercluster von Meta trainiert (Lee und Sengupta, 2022). Im Zuge der weiteren Skalierung wurde das Training von Llama 3 auf den Produktionscluster von Meta verlagert (Lee et al., 2024). Dieses Setup optimiert die Zuverlässigkeit auf Produktionsebene, was bei der Ausweitung des Trainings entscheidend ist.

EDV-Ressourcen: Der Llama 3 405B trainiert bis zu 16.000 H100-GPUs, die jeweils mit 700 W TDP und 80 GB HBM3 laufen, unter Verwendung der Grand Teton AI-Serverplattform von Meta (Matt Bowman, 2022). Jeder Server ist mit acht GPUs und zwei CPUs ausgestattet; innerhalb des Servers sind die acht GPUs über NVLink verbunden. Die Trainingsaufträge werden mit MAST (Choudhury et al., 2024), dem globalen Trainingsplaner von Meta, geplant.
Lagerung: Tectonic (Pan et al., 2021), das verteilte Allzweck-Dateisystem von Meta, wurde zum Aufbau der Speicherarchitektur für das Vortraining von Llama 3 (Battey und Gupta, 2024) verwendet. Es bietet 240 Petabyte Speicherplatz und besteht aus 7.500 mit SSDs ausgestatteten Servern, die einen nachhaltigen Durchsatz von 2 TB/s und einen Spitzendurchsatz von 7 TB/s unterstützen. Eine große Herausforderung ist die Unterstützung von Checkpoint-Schreibvorgängen, die die Speicherstruktur in kurzer Zeit sättigen. Checkpoints speichern den Modellstatus pro GPU, der von 1 MB bis 4 GB pro GPU reicht, zur Wiederherstellung und Fehlersuche. Unser Ziel ist es, die GPU-Pausenzeit während des Checkpointing zu minimieren und die Häufigkeit des Checkpointing zu erhöhen, um die Menge der nach der Wiederherstellung verlorenen Arbeit zu reduzieren.
Vernetzung: Der Llama 3 405B verwendet eine RDMA over Converged Ethernet (RoCE)-Architektur, die auf den Rack-Switches Arista 7800 und Minipack2 des Open Compute Project (OCP) basiert. Kleinere Modelle der Llama 3-Serie wurden mit dem Nvidia Quantum2 Infiniband-Netzwerk trainiert. Sowohl die RoCE- als auch die Infiniband-Cluster nutzen eine 400-Gbit/s-Verbindung zwischen den GPUs. Trotz der Unterschiede in der zugrundeliegenden Netzwerktechnologie dieser Cluster haben wir beide so abgestimmt, dass sie eine gleichwertige Leistung bieten, um diese großen Trainingslasten zu bewältigen. Wir werden unser RoCE-Netzwerk weiter ausbauen, sobald wir die volle Verantwortung für sein Design übernommen haben.
- Netzwerktopologie: Unser RoCE-basierter KI-Cluster umfasst 24.000 Grafikprozessoren (Fußnote 5), die über ein dreistufiges Clos-Netzwerk verbunden sind (Lee et al., 2024). Auf der untersten Ebene beherbergt jedes Rack 16 GPUs, die zwei Servern zugeordnet und über einen einzigen Minipack2-Top-of-Rack-Switch (ToR) verbunden sind. Auf der mittleren Ebene sind 192 dieser Racks über Cluster-Switches verbunden, um einen Pod mit 3 072 GPUs mit voller bidirektionaler Bandbreite zu bilden, so dass eine Überzeichnung ausgeschlossen ist. Auf der obersten Ebene werden acht solcher Pods innerhalb desselben Rechenzentrumsgebäudes über Aggregations-Switches zu einem Cluster mit 24.000 GPUs verbunden. Anstatt jedoch die volle bidirektionale Bandbreite aufrechtzuerhalten, haben die Netzwerkverbindungen auf der Aggregationsschicht eine Überbelegungsrate von 1:7. Sowohl unser modellparalleler Ansatz (siehe Abschnitt 3.3.2) als auch der Scheduler für die Trainingsaufgaben (Choudhury et al., 2024) sind so optimiert, dass sie die Netzwerktopologie berücksichtigen, um die Netzwerkkommunikation zwischen den Pods zu minimieren.
- Lastausgleich: Das Training großer Sprachmodelle erzeugt einen hohen Netzwerkverkehr, der mit herkömmlichen Methoden wie dem Equal Cost Multipath (ECMP) Routing nur schwer auf alle verfügbaren Netzwerkpfade verteilt werden kann. Um diese Herausforderung zu bewältigen, setzen wir zwei Techniken ein. Erstens erzeugt unsere Aggregatbibliothek 16 Netzwerkflüsse zwischen zwei GPUs anstelle von einem, wodurch der Datenverkehr pro Fluss reduziert wird und mehr Flüsse für den Lastausgleich zur Verfügung stehen. Zweitens gleicht unser Enhanced ECMP (E-ECMP)-Protokoll diese 16 Ströme effektiv über verschiedene Netzwerkpfade aus, indem es andere Felder im RoCE-Header-Paket hasht.

- Staukontrolle: Wir verwenden Deep-Buffer-Switches (Gangidi et al., 2024) im Backbone-Netz, um vorübergehende Überlastungen und Pufferungen, die durch aggregierte Kommunikationsmuster verursacht werden, auszugleichen. Dies trägt dazu bei, die Auswirkungen anhaltender Überlastungen und des durch langsame Server verursachten Netzrückstaus zu begrenzen, was bei Schulungen häufig der Fall ist. Schließlich verringert eine bessere Lastverteilung durch E-ECMP die Wahrscheinlichkeit von Überlastungen erheblich. Mit diesen Optimierungen konnten wir einen Cluster mit 24.000 GPUs erfolgreich betreiben, ohne dass herkömmliche Staukontrollmethoden wie die Data Center Quantified Congestion Notification (DCQCN) erforderlich waren.
3.3.2 Parallelität bei der Modellskalierung
Um das Training unseres größten Modells zu skalieren, haben wir das Modell mit 4D-Parallelität gesplittet - ein Schema, das vier verschiedene parallele Ansätze kombiniert. Dieser Ansatz verteilt die Berechnungen effektiv auf viele GPUs und stellt sicher, dass die Modellparameter, Optimierungszustände, Gradienten und Aktivierungswerte jeder GPU in ihren HBM passen. Unsere parallele 4D-Implementierung (wie in et al. (2020); Ren et al. (2021); Zhao et al. (2023b) gezeigt) unterteilt das Modell, den Optimierer und den Gradienten und implementiert gleichzeitig Datenparallelität, die die Daten parallel auf mehreren GPUs verarbeitet und sie nach jedem Trainingsschritt synchronisiert. Wir verwenden FSDP, um den Zustand des Optimierers und den Gradienten für Llama 3 zu slicen, aber für das Modell-Slicing schneiden wir nach der Vorwärtsberechnung nicht erneut, um zusätzliche Full-Collection-Kommunikation während des Reverse-Passes zu vermeiden.
GPU-Nutzung.Durch sorgfältige Abstimmung der parallelen Konfiguration, der Hardware und der Software erreichen wir eine BF16-Modell-FLOPs-Auslastung (MFU; Chowdhery et al. (2023)) von 38-43%. Die in Tabelle 4 dargestellten Konfigurationen zeigen, dass im Vergleich zu 43% auf 8K-GPUs und DP=64 der Rückgang der MFU auf 41% auf 16K-GPUs und DP=128 auf die Notwendigkeit zurückzuführen ist, die Stapelgröße jeder DP-Gruppe zu reduzieren, um die Anzahl der globalen Marker während des Trainings konstant zu halten. 41% ist auf die Notwendigkeit zurückzuführen, die Stapelgröße jeder DP-Gruppe zu reduzieren, um die Anzahl der globalen Token während des Trainings konstant zu halten.
Rationalisierung paralleler Verbesserungen.Bei unserer bisherigen Umsetzung sind wir auf mehrere Herausforderungen gestoßen:
- Beschränkungen der Chargengröße.Aktuelle Implementierungen begrenzen die pro GPU unterstützte Stapelgröße, die durch die Anzahl der Pipelinestufen teilbar sein muss. Für das Beispiel in Abb. 6 erfordert die Pipeline-Parallelität für das Depth-First-Scheduling (DFS) (Narayanan et al. (2021)) N = PP = 4, während das Breadth-First-Scheduling (BFS; Lamy-Poirier (2023)) N = M erfordert, wobei M die Gesamtzahl der Mikrobatches und N die Anzahl der aufeinanderfolgenden Mikrobatches in derselben Stufe in Vorwärts- oder Rückwärtsrichtung ist. Die Vorschulung erfordert jedoch in der Regel Flexibilität bei der Chargengrößenbestimmung.
- Ungleichgewicht im Gedächtnis.Bestehende parallele Implementierungen mit Pipelines führen zu einem unausgewogenen Ressourcenverbrauch. Die erste Stufe verbraucht aufgrund der Einbettung und Erwärmung von Mikrobatches mehr Speicher.
- Die Berechnungen sind nicht ausgeglichen. Nach der letzten Schicht des Modells müssen wir die Ausgänge und Verluste berechnen, was diese Phase zu einem Engpass in Bezug auf die Ausführungslatenz macht. wobei Di der Index der i-ten parallelen Dimension ist. In diesem Beispiel sind GPU0[TP0, CP0, PP0, DP0] und GPU1[TP1, CP0, PP0, DP0] in derselben TP-Gruppe, GPU0 und GPU2 in derselben CP-Gruppe, GPU0 und GPU4 in derselben PP-Gruppe und GPU0 und GPU8 in derselben DP-Gruppe.

Um diese Probleme zu lösen, haben wir den in Abbildung 6 dargestellten Ansatz der Pipeline-Planung geändert, der eine flexible Einstellung von N - in diesem Fall N = 5 - ermöglicht, so dass in jeder Charge eine beliebige Anzahl von Mikrochargen ausgeführt werden kann. Dies ermöglicht es uns:
(1) Wenn es eine Chargengrößenbegrenzung gibt, werden weniger Mikrochargen als die Anzahl der Stufen ausgeführt; oder
(2) Führen Sie mehr Mikrostapel aus, um die Peer-to-Peer-Kommunikation zu verbergen und die beste Kommunikations- und Speichereffizienz zwischen Depth-First Scheduling (DFS) und Breadth-First Scheduling (BFS) zu finden. Um die Pipeline auszubalancieren, reduzieren wir jeweils eine Transformer-Schicht in der ersten und letzten Stufe. Das bedeutet, dass der erste Modellblock auf der ersten Stufe nur die Einbettungsschicht enthält, während der letzte Modellblock auf der letzten Stufe nur die Ausgangsprojektion und die Verlustberechnung enthält.
Um Pipeline-Blasen zu reduzieren, verwenden wir einen Ansatz zur verschachtelten Planung (Narayanan et al., 2021) in einer Pipeline-Hierarchie mit V Pipeline-Stufen. Das gesamte Pipeline-Blasenverhältnis ist PP-1 V * M . Darüber hinaus verwenden wir asynchrone Peer-to-Peer-Kommunikation, die das Training erheblich beschleunigt, insbesondere in Fällen, in denen Dokumentenmasken zusätzliche rechnerische Ungleichgewichte verursachen. Wir aktivieren TORCH_NCCL_AVOID_RECORD_STREAMS, um die Speichernutzung durch asynchrone Peer-to-Peer-Kommunikation zu reduzieren. Um schließlich die Speicherkosten zu senken, geben wir auf der Grundlage einer detaillierten Analyse der Speicherzuweisung proaktiv Tensoren frei, die nicht für zukünftige Berechnungen verwendet werden, einschließlich Eingabe- und Ausgabetensoren für jede Pipelinestufe. ** Mit diesen Optimierungen sind wir in der Lage, die 8K-Tensoren ohne Aktivierungsprüfpunkte auszuführen, ohne Aktivierungsprüfpunkte. Token Sequenzen für die Llama 3-Vorschulung.
Die Kontextparallelisierung wird für lange Sequenzen verwendet. Wir nutzen die Kontextparallelisierung (CP), um die Speichereffizienz bei der Skalierung der Llama-3-Kontextlängen zu verbessern und das Training auf sehr langen Sequenzen mit bis zu 128K Länge zu ermöglichen. Bei CP partitionieren wir über die Sequenzdimensionen hinweg, d. h. wir teilen die Eingabesequenz in 2 × CP-Blöcke auf, so dass jede CP-Ebene zwei Blöcke erhält, um eine bessere Lastverteilung zu erreichen. Die i-te CP-Ebene erhält den i-ten und (2 × CP -1 -i) Blöcke.
Im Gegensatz zu bestehenden CP-Implementierungen, bei denen sich Kommunikation und Berechnung in einer Ringstruktur überschneiden (Liu et al., 2023a), verwendet unsere CP-Implementierung einen All-Gather-basierten Ansatz, bei dem zunächst Schlüssel-Wert-Tensoren (K, V) global aggregiert werden und dann die Aufmerksamkeitsausgaben eines Blocks lokaler Abfragetensoren (Q) berechnet werden. Obwohl die All-Gather-Kommunikationslatenz auf dem kritischen Pfad liegt, wählen wir diesen Ansatz aus zwei Hauptgründen:
(1) Es ist einfacher und flexibler, verschiedene Arten von Aufmerksamkeitsmasken, wie z. B. Dokumentenmasken, in der allumfassenden CP-Aufmerksamkeit zu unterstützen;
(2) Die exponierte All-Gather-Latenzzeit ist klein, weil der K- und V-Tensor der Kommunikation aufgrund der Verwendung von GQA viel kleiner ist als der Q-Tensor (Ainslie et al., 2023). Infolgedessen ist die Zeitkomplexität der Aufmerksamkeitsberechnung um eine Größenordnung größer als die von All-Gather (O(S²) gegenüber O(S), wobei S die Länge der Sequenz in der vollständigen Kausalmaske bezeichnet), wodurch der All-Gather-Overhead vernachlässigbar ist.

Netzwerkfähige, parallelisierte Konfiguration.Die Reihenfolge der Parallelisierungsdimensionen [TP, CP, PP, DP] ist für die Netzkommunikation optimiert. Die innerste Schicht der Parallelisierung erfordert die höchste Netzbandbreite und die geringste Latenz und ist daher in der Regel auf denselben Server beschränkt. Die äußerste Parallelisierungsschicht kann sich über Multi-Hop-Netze erstrecken und sollte eine höhere Netzlatenz tolerieren können. Daher ordnen wir die Parallelisierungsdimensionen auf der Grundlage der Anforderungen an die Netzwerkbandbreite und -latenz in der Reihenfolge [TP, CP, PP, DP] ein. DP (d. h. FSDP) ist die äußerste Parallelisierungsschicht, da sie eine längere Netzwerklatenz tolerieren kann, indem sie die Gewichte des Slicing-Modells asynchron vorab abruft und den Gradienten reduziert. Die Bestimmung der optimalen Parallelisierungskonfiguration mit minimalem Kommunikations-Overhead bei gleichzeitiger Vermeidung eines GPU-Speicherüberlaufs ist eine Herausforderung. Wir haben einen Schätzer für den Speicherverbrauch und ein Tool zur Leistungsprojektion entwickelt, mit dem wir verschiedene Parallelisierungskonfigurationen untersuchen, die Gesamttrainingsleistung vorhersagen und Speicherlücken effizient identifizieren konnten.
Numerische Stabilität.Durch den Vergleich der Trainingsverluste zwischen verschiedenen parallelen Einstellungen beheben wir einige numerische Probleme, die die Trainingsstabilität beeinträchtigen. Um die Trainingskonvergenz zu gewährleisten, verwenden wir FP32-Gradientenakkumulation während der Rückwärtsberechnung mehrerer Mikrostapel und reduzieren die Streuung der Gradienten mit FP32 zwischen datenparallelen Arbeitern in FSDP. Für Zwischentensoren, die mehrfach in Vorwärtsberechnungen verwendet werden, wie z. B. visuelle Codierausgaben, wird der Rückwärtsgradient ebenfalls in FP32 akkumuliert.
3.3.3 Kollektive Kommunikation
Die kollektive Kommunikationsbibliothek von Llama 3 basiert auf einem Zweig von Nvidias NCCL-Bibliothek namens NCCLX. NCCLX verbessert die Leistung von NCCL erheblich, insbesondere für Netzwerke mit hoher Latenz. Die Reihenfolge der parallelen Dimensionen ist [TP, CP, PP, DP], wobei DP dem FSDP entspricht, und die äußersten parallelen Dimensionen, PP und DP, können über ein Multi-Hop-Netzwerk mit Latenzen im Bereich von zehn Mikrosekunden kommunizieren. Die kollektiven Kommunikationsoperationen "all-gather" und "reduce-scatter" der ursprünglichen NCCL werden in FSDP verwendet, während für PP eine Punkt-zu-Punkt-Kommunikation verwendet wird, die Daten-Chunking und stufenweise Datenreplikation erfordert. Dieser Ansatz führt zu einigen der folgenden Ineffizienzen:
- Zur Erleichterung der Datenübertragung muss eine große Anzahl kleiner Kontrollmeldungen über das Netz ausgetauscht werden;
- Zusätzliche Speicherkopiervorgänge;
- Verwenden Sie zusätzliche GPU-Zyklen für die Kommunikation.
Für das Llama 3-Training beheben wir einige dieser Ineffizienzen, indem wir das Chunking und die Datenübertragungen an unsere Netzwerklatenz anpassen, die in großen Clustern bis zu zehn Mikrosekunden betragen kann. Außerdem lassen wir zu, dass kleine Kontrollnachrichten unser Netzwerk mit höherer Priorität durchlaufen, um insbesondere Head-of-Queue-Blockierungen in tief gepufferten Core-Switches zu vermeiden.
Unsere laufenden Arbeiten für zukünftige Versionen von Llama beinhalten tiefgreifende Änderungen an NCCLX, um alle oben genannten Probleme vollständig zu lösen.

3.3.4 Zuverlässigkeit und betriebliche Herausforderungen
Die Komplexität und die möglichen Fehlerszenarien des 16K-GPU-Trainings übersteigen die der größeren CPU-Cluster, mit denen wir gearbeitet haben. Außerdem ist das Training aufgrund seiner synchronen Natur weniger fehlertolerant - ein einziger GPU-Ausfall kann einen Neustart des gesamten Auftrags erfordern. Trotz dieser Herausforderungen erreichten wir für Llama 3 effektive Trainingszeiten von mehr als 90% und unterstützten gleichzeitig die automatische Clusterwartung (z. B. Firmware- und Linux-Kernel-Upgrades (Vigraham und Leonhardi, 2024)), was zu mindestens einem Trainingsausfall pro Tag führte.
Die effektive Schulungszeit ist die Zeit, die während der verstrichenen Zeit für die effektive Schulung aufgewendet wurde. Während der 54-tägigen Momentaufnahme vor dem Training gab es insgesamt 466 Betriebsausfälle. Davon waren 47 geplante Unterbrechungen aufgrund automatischer Wartungsarbeiten (z. B. Firmware-Upgrades oder vom Bediener initiierte Arbeiten wie Konfigurations- oder Datensatzaktualisierungen). Die restlichen 419 waren unvorhergesehene Ausfälle, die in Tabelle 5 kategorisiert sind. Etwa 78% der unvorhergesehenen Ausfälle waren auf festgestellte Hardwareprobleme zurückzuführen, wie z. B. Ausfälle von GPU- oder Host-Komponenten, oder auf vermutete hardwarebezogene Probleme, wie z. B. stille Datenverfälschungen und ungeplante individuelle Host-Wartungsereignisse.GPU-Probleme stellten mit 58,7% aller unvorhergesehenen Probleme die größte Kategorie dar.Trotz der großen Anzahl von Ausfällen waren in diesem Zeitraum nur drei größere manuelle Trotz der großen Anzahl von Ausfällen waren in diesem Zeitraum nur drei größere manuelle Eingriffe erforderlich, und die übrigen Probleme wurden durch Automatisierung gelöst.
Um die effektive Trainingszeit zu verbessern, haben wir die Zeit für das Starten von Jobs und das Checkpointing reduziert und Werkzeuge für eine schnelle Diagnose und Problemlösung entwickelt. Wir nutzten ausgiebig den in PyTorch eingebauten NCCL Flight Recorder (Ansel et al., 2024) - eine Funktion, die kollektive Metadaten und Stack Traces in einem Ringpuffer aufzeichnet, was uns eine schnelle Diagnose von Hängern und Leistungsproblemen im großen Maßstab ermöglicht, insbesondere im Fall von NCCLX-Aspekten. Mit dieser Funktion können wir Kommunikationsereignisse und -dauer für jede kollektive Operation effizient protokollieren und im Falle eines NCCLX-Watchdog- oder Heartbeat-Timeouts automatisch Tracedaten ausgeben. Mit Online-Konfigurationsänderungen (Tang et al., 2015) können wir selektiv rechenintensivere Trace-Operationen und die Sammlung von Metadaten aktivieren, ohne dass der Code freigegeben oder der Job neu gestartet werden muss. Das Debuggen von Problemen in großen Trainings wird durch die Mischung aus NVLink und RoCE in unserem Netzwerk erschwert. Datenübertragungen werden typischerweise über NVLink mittels Load/Store-Operationen durchgeführt, die vom CUDA-Kernel ausgegeben werden, und der Ausfall einer entfernten GPU oder NVLink-Verbindung manifestiert sich oft als blockierte Load/Store-Operation im CUDA-Kernel, ohne dass ein expliziter Fehlercode zurückgegeben wird.NCCLX verbessert die Geschwindigkeit und Genauigkeit der Fehlererkennung und -lokalisierung, indem es eng mit PyTorch zusammenarbeitet, so dass PyTorch kann auf den internen Zustand von NCCLX zugreifen und relevante Informationen verfolgen. Es ist zwar nicht möglich, einen Stillstand aufgrund von NVLink-Fehlern vollständig zu verhindern, aber unser System überwacht den Zustand der Kommunikationsbibliotheken und schaltet automatisch ab, wenn ein solcher Stillstand erkannt wird. Darüber hinaus verfolgt NCCLX die Kernel- und Netzwerkaktivitäten jeder NCCLX-Kommunikation und liefert eine Momentaufnahme des internen Zustands des fehlerhaften NCCLX-Kollektivs, einschließlich abgeschlossener und nicht abgeschlossener Datenübertragungen zwischen allen Ranks. Wir analysieren diese Daten, um Probleme mit der NCCLX-Erweiterung zu beheben.
Manchmal können Hardwareprobleme zu noch laufenden, aber langsamen Nachzüglern führen, die schwer zu erkennen sind. Selbst wenn es nur einen Nachzügler gibt, kann er Tausende anderer GPUs verlangsamen, oft in Form von normalem Betrieb, aber langsamer Kommunikation. Wir haben Tools entwickelt, mit denen sich potenziell problematische Kommunikationen von ausgewählten Prozessgruppen priorisieren lassen. Indem wir nur einige wenige Hauptverdächtige untersuchen, können wir Nachzügler oft effektiv identifizieren.
Eine interessante Beobachtung ist der Einfluss von Umgebungsfaktoren auf die Trainingsleistung in großem Maßstab. Beim Llama 3 405B haben wir Durchsatzschwankungen von 1-2% in Abhängigkeit von der Zeit festgestellt. Diese Fluktuation wird durch höhere Mittagstemperaturen verursacht, die die dynamische Spannungs- und Frequenzskalierung der GPU beeinflussen. Während des Trainings können Zehntausende von GPUs gleichzeitig den Stromverbrauch erhöhen oder senken, z. B. weil alle GPUs darauf warten, dass ein Checkpoint oder eine kollektive Kommunikation beendet wird oder dass ein ganzer Trainingsjob beginnt oder beendet wird. Wenn dies geschieht, kann es zu vorübergehenden Schwankungen des Stromverbrauchs im Rechenzentrum in der Größenordnung von einigen zehn Megawatt kommen, was die Grenzen des Stromnetzes ausreizt. Dies ist eine ständige Herausforderung, da wir das Training für zukünftige und noch größere Llama-Modelle skalieren.
3.4 Ausbildungsprogramme
Das Vorschulungsrezept für Llama 3 405B enthält drei Hauptstufen:
(1) anfängliches Pre-Training, (2) Pre-Training mit langem Kontext und (3) Annealing. Jeder dieser drei Schritte wird im Folgenden beschrieben. Für das Pre-Training der 8B- und 70B-Modelle verwenden wir ähnliche Rezepte.
3.4.1 Erste Vorschulung
Wir haben das Modell Llama 3 405B mit einem Kosinus-Lernratenschema mit einer maximalen Lernrate von 8 × 10-⁵ vortrainiert, linear auf 8.000 Schritte aufgewärmt und nach 1.200.000 Trainingsschritten auf 8 × 10-⁷ abklingen lassen. Um die Stabilität des Trainings zu verbessern, verwenden wir zu Beginn des Trainings eine kleinere Losgröße und erhöhen anschließend die Losgröße, um die Effizienz zu verbessern. Konkret haben wir anfangs eine Stapelgröße von 4M Token und eine Sequenzlänge von 4.096. Nach dem Vortraining von 252M Token verdoppeln wir die Stapelgröße und die Sequenzlänge auf 8M Sequenzen bzw. 8.192 Token. Nach dem Vortraining von 2,87T Token verdoppeln wir erneut die Stapelgröße auf 16M. Wir haben festgestellt, dass Diese Trainingsmethode ist sehr stabil: Es treten nur sehr wenige Verlustspitzen auf, und es ist kein Eingreifen erforderlich, um Abweichungen beim Modelltraining zu korrigieren.
Anpassung der Datenkombinationen. Während des Trainings haben wir mehrere Anpassungen an der Datenkombination vor dem Training vorgenommen, um die Leistung des Modells bei bestimmten nachgelagerten Aufgaben zu verbessern. Insbesondere haben wir den Anteil der nicht-englischen Daten während des Vortrainings erhöht, um die mehrsprachige Leistung von Llama 3 zu verbessern. Außerdem haben wir den Anteil der mathematischen Daten erhöht, um das mathematische Denken des Modells zu verbessern, in den späteren Phasen des Vortrainings neuere Netzwerkdaten hinzugefügt, um die Wissensabgrenzungen des Modells zu aktualisieren, und den Anteil einer Teilmenge der Daten, die später als von geringerer Qualität identifiziert wurde, verringert.
3.4.2 Vorschulung im langen Kontext
In der letzten Phase des Vortrainings trainieren wir lange Sequenzen, um Kontextfenster von bis zu 128.000 Token zu unterstützen. Wir trainieren lange Sequenzen nicht früher, da die Berechnungen in der Selbstbeobachtungsschicht quadratisch mit der Sequenzlänge wachsen. Wir erhöhen schrittweise die unterstützte Kontextlänge und führen ein Pre-Training durch, nachdem sich das Modell erfolgreich an die erhöhte Kontextlänge angepasst hat. Wir bewerten die erfolgreiche Anpassung, indem wir beides messen:
(1) Ob die Leistung des Modells bei Kurzkontextbewertungen vollständig wiederhergestellt wurde;
(2) Ob das Modell die Aufgabe "Nadel im Heuhaufen" bis zu dieser Länge perfekt lösen kann. Beim Vortraining von Llama 3 405B haben wir die Länge des Kontextes in sechs Stufen schrittweise erhöht, beginnend mit einem anfänglichen Kontextfenster von 8.000 Token und schließlich bis zu einem Kontextfenster von 128.000 Token. In dieser langen Kontext-Vorübungsphase wurden ca. 800 Milliarden Trainings-Token verwendet.

3.4.3 Glühen
Während des Vortrainings der letzten 40 Mio. Token haben wir die Lernrate linear auf 0 geglättet und dabei eine Kontextlänge von 128K Token beibehalten. Während dieser Annealing-Phase passen wir auch den Datenmix an, um die Stichprobengröße der sehr hochwertigen Datenquellen zu erhöhen; siehe Abschnitt 3.1.3. Schließlich berechneten wir den Durchschnitt der Modellprüfpunkte (Polyak (1991) Durchschnitt) während des Annealings, um das endgültige vortrainierte Modell zu erstellen.
4 Nachschulung
Wir generieren und alignieren Llama-3-Modelle, indem wir mehrere Runden von Follow-up-Training durchführen. Diese Folgetrainings basieren auf vortrainierten Kontrollpunkten und beziehen menschliches Feedback für die Modellanpassung mit ein (Ouyang et al., 2022; Rafailov et al., 2024). Jede Runde des Folgetrainings bestand aus einer überwachten Feinabstimmung (SFT), gefolgt von einer direkten Präferenzoptimierung (DPO; Rafailov et al., 2024) unter Verwendung von Beispielen, die durch manuelle Annotation oder Synthese generiert wurden. In den Abschnitten 4.1 und 4.2 beschreiben wir unsere anschließende Trainingsmodellierung und unsere Datenmethoden. Darüber hinaus geben wir in Abschnitt 4.3 weitere Einzelheiten zu den Strategien für die kundenspezifische Datensammlung an, um das Modell in Bezug auf Inferenz, Programmierfähigkeiten, Faktorisierung, mehrsprachige Unterstützung, Werkzeugnutzung, lange Kontexte und genaue Einhaltung von Anweisungen zu verbessern.
4.1 Modellierung
Die Grundlage unserer Post-Training-Strategie bilden ein Belohnungsmodell und ein Sprachmodell. Zunächst trainieren wir ein Belohnungsmodell auf den Pre-Training-Kontrollpunkten mit von Menschen gelabelten Präferenzdaten (siehe Abschnitt 4.1.2). Anschließend erfolgt eine Feinabstimmung der Pre-Training-Checkpoints mit Supervised Fine-Tuning (SFT; siehe Abschnitt 4.1.3) und ein weiterer Abgleich mit den Checkpoints mit Hilfe von Direct Preference Optimization (DPO; siehe Abschnitt 4.1.4). Dieser Prozess ist in Abbildung 7 dargestellt. Sofern nicht anders angegeben, gilt unser Modellierungsprozess für Llama 3 405B, das wir der Einfachheit halber als Llama 3 405B bezeichnen.
4.1.1 Format des Chat-Dialogs
Um ein Large Language Model (LLM) für die Mensch-Computer-Interaktion anzupassen, müssen wir ein Chat-Dialogprotokoll definieren, das es dem Modell ermöglicht, menschliche Befehle zu verstehen und Dialogaufgaben auszuführen. Im Vergleich zu seinem Vorgänger hat Llama 3 neue Funktionen, wie z.B. die Verwendung von Werkzeugen (Abschnitt 4.3.5), die es erforderlich machen können, mehrere Nachrichten in einer einzigen Dialogrunde zu erzeugen und sie an verschiedene Stellen zu senden (z.B. Benutzer, ipython). Um dies zu unterstützen, haben wir ein neues Chat-Protokoll für mehrere Nachrichten entwickelt, das eine Reihe von speziellen Header- und Terminierungs-Tokens verwendet. Header-Token werden verwendet, um die Quelle und das Ziel jeder Nachricht in einem Dialog anzugeben. Ebenso zeigen Beendigungsmarkierungen an, wann der Mensch und die KI an der Reihe sind, abwechselnd zu sprechen.
4.1.2 Belohnungsmodellierung
Wir haben ein Belohnungsmodell (RM) trainiert, das verschiedene Fähigkeiten abdeckt, und es auf vortrainierten Kontrollpunkten aufgebaut. Das Trainingsziel ist das gleiche wie in Llama 2, aber wir entfernen den marginalen Term in der Verlustfunktion, da wir eine geringere Verbesserung mit zunehmender Datenmenge beobachten. Wie in Llama 2 verwenden wir alle Präferenzdaten für die Belohnungsmodellierung, nachdem wir Proben mit ähnlichen Antworten herausgefiltert haben.
Zusätzlich zu den Standard-Präferenzpaaren (ausgewählt, abgelehnt) wird bei einigen Stichwörtern eine dritte "bearbeitete Antwort" erstellt, bei der die aus dem Paar ausgewählte Antwort zur Verbesserung weiter bearbeitet wird (siehe Abschnitt 4.2.1). Somit gibt es in jeder Stichprobe für die Präferenzsortierung zwei oder drei Antworten, die eine klare Rangfolge aufweisen (bearbeitet > ausgewählt > abgelehnt). Während des Trainings haben wir die Stichwörter und Mehrfachantworten in einer Zeile zusammengefasst und die Antworten randomisiert. Dies ist eine Annäherung an das Standardszenario, bei dem die Antworten in separaten Zeilen angeordnet werden, aber in unseren Ablationsexperimenten verbessert dieser Ansatz die Trainingseffizienz ohne Präzisionsverlust.
4.1.3 Feinabstimmung der Überwachung
Menschlich markierte Hinweise werden zunächst mit Hilfe des Belohnungsmodells, dessen detaillierte Methodik in Abschnitt 4.2 beschrieben wird, für die Stichprobe zurückgewiesen. Wir kombinieren diese zurückgewiesenen Daten mit anderen Datenquellen (einschließlich synthetischer Daten), um das vortrainierte Sprachmodell mit Hilfe von Standard-Cross-Entropie-Verlusten zu verfeinern, mit dem Ziel, die Zielmarkierung vorherzusagen (und dabei die Verluste aus der markierten Markierung zu maskieren). Siehe Abschnitt 4.2 für weitere Details zum Data Blending. Obwohl viele der Trainingsziele durch das Modell generiert werden, bezeichnen wir diese Phase als überwachte Feinabstimmung (SFT; Wei et al. 2022a; Sanh et al. 2022; Wang et al. 2022b).
Unser maximales Modell wird mit einer Lernrate von 1e-5 innerhalb von 8,5K bis 9K Schritten feinabgestimmt. Wir haben festgestellt, dass diese Hyperparametereinstellungen für verschiedene Runden und Datenmischungen geeignet sind.
4.1.4 Direkte Präferenzoptimierung
Wir haben unsere SFT-Modelle für den Abgleich menschlicher Präferenzen mithilfe der direkten Präferenzoptimierung (DPO; Rafailov et al., 2024) weiter trainiert. Für das Training verwenden wir hauptsächlich die neuesten Präferenzdaten, die von den leistungsstärksten Modellen der vorherigen Abgleichsrunde gesammelt wurden. Dadurch stimmen unsere Trainingsdaten besser mit der Verteilung der optimierten Strategiemodelle in jeder Runde überein. Wir haben auch Strategiealgorithmen wie PPO (Schulman et al., 2017) untersucht, aber festgestellt, dass DPO weniger Berechnungen erfordert und bei großen Modellen besser abschneidet, insbesondere bei Benchmarks zur Befolgung von Anweisungen wie IFEval (Zhou et al., 2023).
Für Llama 3 verwendeten wir eine Lernrate von 1e-5 und setzten den Hyperparameter β auf 0,1. Zusätzlich haben wir die folgenden algorithmischen Änderungen an DPO vorgenommen:
- Maskierung von Formatierungsmarkierungen in DPO-Verlusten. Wir maskieren spezielle Formatmarker (einschließlich der in Abschnitt 4.1.1 beschriebenen Header- und Terminationsmarker) aus den ausgewählten und abgelehnten Antworten, um das DPO-Training zu stabilisieren. Wir stellen fest, dass die Einbeziehung dieser Marker in den Verlust zu unerwünschtem Modellverhalten führen kann, wie z. B. Schwanzverdopplung oder plötzliche Erzeugung von Terminationsmarkern. Wir stellen die Hypothese auf, dass dies auf die gegensätzliche Natur des DPO-Verlustes zurückzuführen ist - das Vorhandensein gemeinsamer Marker sowohl in ausgewählten als auch in abgelehnten Antworten kann zu widersprüchlichen Lernzielen führen, da das Modell die Wahrscheinlichkeit dieser Marker gleichzeitig erhöhen und verringern muss.
- Regularisierung mit NLL-Verlusten: die Ähnlich wie Pang et al. (2024) fügten wir den ausgewählten Sequenzen einen zusätzlichen Verlustterm der negativen Log-Likelihood (NLL) mit einem Skalierungsfaktor von 0,2 hinzu. Dies trägt zur weiteren Stabilisierung des DPO-Trainings bei, indem das für die Generierung erforderliche Format beibehalten wird und verhindert wird, dass die Log-Wahrscheinlichkeit der ausgewählten Antworten abnimmt (Pang et al., 2024; Pal et al., 2024).
4.1.5 Modell-Mittelwertbildung
Schließlich haben wir die Modelle aus Experimenten mit verschiedenen Datenversionen oder Hyperparametern in jeder RM-, SFT- oder DPO-Stufe gemittelt (Izmailov et al. 2019; Wortsman et al. 2022; Li et al. 2022). Wir präsentieren statistische Informationen zu den intern erhobenen menschlichen Präferenzdaten, die für die Konditionierung von Llama 3 verwendet wurden. Wir baten die Bewerter, sich in mehreren Dialogrunden mit dem Modell zu unterhalten, und verglichen die Antworten aus jeder Runde. Bei der Nachbearbeitung teilten wir jeden Dialog in mehrere Beispiele auf, die jeweils eine Aufforderung (einschließlich des vorherigen Dialogs, falls verfügbar) und eine Antwort (z. B. eine Antwort, die ausgewählt oder abgelehnt wurde) enthielten.

4.1.6 Iterationsrunden
In Anlehnung an Llama 2 haben wir die oben beschriebene Methodik in sechs Iterationsrunden angewandt. In jeder Runde haben wir neue Daten zur Präferenzkennzeichnung und Feinabstimmung (SFT) gesammelt und synthetische Daten aus dem letzten Modell entnommen.
4.2 Daten nach der Ausbildung
Die Zusammensetzung der Post-Training-Daten spielt eine entscheidende Rolle für den Nutzen und das Verhalten des Sprachmodells. In diesem Abschnitt werden unser Annotationsverfahren und die Erhebung von Präferenzdaten (Abschnitt 4.2.1), die Zusammensetzung der SFT-Daten (Abschnitt 4.2.2) und Methoden zur Datenqualitätskontrolle und -bereinigung (Abschnitt 4.2.3) erläutert.
4.2.1 Vorlieben
Unser Verfahren zur Kennzeichnung von Präferenzdaten ist ähnlich wie bei Llama 2. Nach jeder Runde setzen wir mehrere Modelle für die Annotation ein und nehmen zwei Antworten von verschiedenen Modellen für jeden Benutzerhinweis. Diese Modelle können mit verschiedenen Datenmischungs- und Ausrichtungsschemata trainiert werden, was zu unterschiedlichen Stärken (z. B. Code-Expertise) und einer größeren Datenvielfalt führt. Wir haben die Kommentatoren gebeten, ihre Präferenzbewertungen in eine von vier Stufen einzuordnen: deutlich besser, besser, etwas besser oder etwas besser.
Wir haben auch einen Bearbeitungsschritt nach der Präferenzordnung vorgesehen, um den Kommentator zu ermutigen, die bevorzugte Antwort weiter zu verfeinern. Der Kommentator kann entweder die ausgewählte Antwort direkt bearbeiten oder das Feedback-Cue-Modell verwenden, um seine eigene Antwort zu verfeinern. Infolgedessen haben einige Präferenzdaten drei sortierte Antworten (Bearbeiten > Auswählen > Ablehnen).
Die Präferenzstatistiken, die wir für das Training mit Llama 3 verwendet haben, sind in Tabelle 6 aufgeführt. Allgemeines Englisch umfasst mehrere Unterkategorien, wie z. B. wissensbasierte Fragen und Antworten oder präzises Befolgen von Anweisungen, die über den Rahmen der spezifischen Fähigkeiten hinausgehen. Im Vergleich zu Llama 2 beobachteten wir eine Zunahme der durchschnittlichen Länge von Prompts und Antworten, was darauf hindeutet, dass wir Llama 3 für komplexere Aufgaben trainieren. Darüber hinaus haben wir einen Qualitätsanalyse- und manuellen Evaluierungsprozess implementiert, um die gesammelten Daten kritisch zu bewerten, so dass wir die Prompts verfeinern und den Annotatoren systematisches, umsetzbares Feedback geben können. Wenn sich Llama 3 beispielsweise nach jeder Runde verbessert, werden wir die Komplexität der Hinweise entsprechend erhöhen, um Bereiche anzugehen, in denen das Modell hinterherhinkt.
In jeder späten Trainingsrunde verwenden wir für die Belohnungsmodellierung alle zu diesem Zeitpunkt verfügbaren Präferenzdaten und für das DPO-Training nur die jüngsten Chargen aus jeder Fähigkeit. Sowohl für die Belohnungsmodellierung als auch für den DPO trainieren wir mit Stichproben, die als "Auswahlreaktion deutlich besser oder besser" gekennzeichnet sind, und verwerfen Stichproben mit ähnlichen Antworten.
4.2.2 SFT-Daten
Unsere Daten für die Feinabstimmung stammen hauptsächlich aus den folgenden Quellen:
- Hinweise aus unserer manuell annotierten Sammlung und ihre Ablehnung von Stichprobenantworten
- Synthetische Daten für bestimmte Fähigkeiten (siehe Abschnitt 4.3 für Details)
- Geringe Menge an manuell beschrifteten Daten (siehe Abschnitt 4.3 für Details)
Im weiteren Verlauf unseres Post-Trainingszyklus entwickelten wir leistungsfähigere Varianten von Llama 3 und nutzten diese, um größere Datensätze zu sammeln, die ein breites Spektrum komplexer Fähigkeiten abdecken. In diesem Abschnitt werden die Details des Rejection Sampling-Prozesses und die Gesamtzusammensetzung der endgültigen SFT-Datenmischung erläutert.
Verweigerung der Probenahme.Beim Rejection Sampling (RS) werden für jeden Hinweis, den wir während der manuellen Annotation (Abschnitt 4.2.1) sammeln, K Ausgaben der letzten Chat-Modellierungsstrategie (typischerweise die besten Ausführungskontrollpunkte aus der letzten Post-Trainingsiteration oder die besten Ausführungskontrollpunkte für eine bestimmte Kompetenz) ausgewählt und unser Belohnungsmodell verwendet, um den besten Kandidaten auszuwählen, in Übereinstimmung mit Bai et al. (2022). In späteren Phasen des Nachtrainings führen wir Systemhinweise ein, um die Antworten der RS so zu lenken, dass sie einem gewünschten Ton, Stil oder Format entsprechen, das für verschiedene Fähigkeiten unterschiedlich sein kann.
Um die Effizienz des Rejection Sampling zu verbessern, setzen wir PagedAttention (Kwon et al., 2023) ein, das die Speichereffizienz durch dynamische Zuweisung von Schlüsselwerten im Cache verbessert. Es unterstützt beliebige Ausgabelängen durch dynamische Planung von Anforderungen auf der Grundlage der aktuellen Cache-Kapazität. Leider birgt dies das Risiko des Swapping, wenn der Speicher knapp wird. Um diesen Swapping-Overhead zu eliminieren, definieren wir eine maximale Ausgabelänge und führen Anfragen nur dann aus, wenn genügend Speicher für Ausgaben dieser Länge vorhanden ist. pagedAttention ermöglicht es uns auch, die angedeutete Schlüsselwert-Cache-Seite auf alle entsprechenden Ausgaben aufzuteilen. Insgesamt führte dies zu einer mehr als zweifachen Steigerung des Durchsatzes während der Ablehnungsproben.
Aggregierte Datenzusammensetzung.Tabelle 7 zeigt die Statistiken für jede der großen Datenkategorien in unserem "Nützlichkeits"-Mix. Obwohl die SFT- und Präferenzdaten sich überschneidende Bereiche enthalten, sind sie unterschiedlich kuratiert, was zu unterschiedlichen Zählstatistiken führt. In Abschnitt 4.2.3 werden die Techniken beschrieben, die zur Kategorisierung des Themas, der Komplexität und der Qualität unserer Datenproben verwendet werden. In jeder Runde des Post-Trainings stimmen wir unseren gesamten Datenmix sorgfältig ab, um die Leistung auf mehreren Achsen für eine breite Palette von Benchmarks anzupassen. Unsere endgültige Datenmischung wird für bestimmte hochwertige Quellen mehrfach wiederholt und für andere heruntergestuft.

4.2.3 Datenverarbeitung und Qualitätskontrolle
Da es sich bei den meisten unserer Trainingsdaten um modellgenerierte Daten handelt, ist eine sorgfältige Bereinigung und Qualitätskontrolle erforderlich.
Datenbereinigung: In der Anfangsphase stellten wir viele unerwünschte Muster in den Daten fest, wie etwa die übermäßige Verwendung von Emoticons oder Ausrufezeichen. Wir haben daher eine Reihe von regelbasierten Strategien zur Datenlöschung und -modifikation eingeführt, um problematische Daten zu filtern oder zu entfernen. Um z. B. das Problem der übermäßig entschuldigenden Intonation zu entschärfen, identifizierten wir übermäßig verwendete Phrasen (z. B. "Es tut mir leid" oder "Ich entschuldige mich") und glichen den Anteil solcher Muster im Datensatz sorgfältig aus.
Datenbeschneidung: Außerdem wenden wir eine Reihe von modellbasierten Techniken an, um minderwertige Trainingsmuster zu entfernen und die Gesamtleistung des Modells zu verbessern:
- Klassifizierung der Themen: Zunächst haben wir Llama 3 8B in einen Themenklassifikator umgewandelt und alle Daten in grobkörnige Kategorien ("Mathematisches Denken") und feinkörnige Kategorien ("Geometrie und Trigonometrie") eingeteilt.
- Bewertung der Qualität: Wir verwendeten das Reward-Modell und Llama-basierte Signale, um Qualitätsbewertungen für jede Probe zu erhalten. Für die RM-basierten Werte betrachteten wir Daten mit Werten im höchsten Quartil als hochqualitativ. Für die Llama-basierten Bewertungen haben wir die Llama-3-Kontrollpunkte dazu veranlasst, die allgemeinen englischen Daten auf drei Ebenen (Genauigkeit, Einhaltung der Anweisungen und Tonalität/Darstellung) und die Codedaten auf zwei Ebenen (Fehlererkennung und Benutzerabsicht) zu bewerten, und betrachteten die Proben, die die höchsten Punktzahlen erhielten, als hochwertige Daten. RM- und Llama-basierte Bewertungen haben hohe Konfliktraten, und wir fanden heraus, dass die Kombination dieser Signale die beste Wiedererkennung für die interne Testmenge ergab. Letztendlich wählen wir diejenigen Beispiele aus, die entweder von den RM- oder den Llama-basierten Filtern als hochwertig eingestuft werden.
- Schwierigkeitsgrad: Da wir auch daran interessiert waren, komplexere Modellbeispiele zu priorisieren, bewerteten wir die Daten anhand von zwei Schwierigkeitsmetriken: dem Instag (Lu et al., 2023) und dem Llama-basierten Scoring. Für Instag forderten wir Llama 3 70B auf, eine Absichtsmarkierung für SFT-Hinweise vorzunehmen, wobei mehr Absicht eine höhere Komplexität bedeutet. Außerdem forderten wir Llama 3 auf, den Schwierigkeitsgrad des Dialogs auf drei Ebenen zu messen (Liu et al., 2024c).
- Semantische Deemphasis: Schließlich führen wir eine semantische De-Duplizierung durch (Abbas et al., 2023; Liu et al., 2024c). Zunächst clustern wir vollständige Dialoge mithilfe von RoBERTa (Liu et al., 2019b) und sortieren sie in jedem Cluster nach Qualitäts- und Schwierigkeitsscore. Dann führen wir eine gierige Auswahl durch, indem wir über alle sortierten Beispiele iterieren und nur diejenigen behalten, deren maximale Cosinus-Ähnlichkeit zu den Beispielen in den bisherigen Clustern kleiner als ein Schwellenwert ist.
4.3 Kapazität
Insbesondere heben wir einige der Anstrengungen hervor, die unternommen wurden, um spezifische Kompetenzen zu fördern, wie die Handhabung von Codes (Abschnitt 4.3.1), Mehrsprachigkeit (Abschnitt 4.3.2), mathematische und logische Fähigkeiten (Abschnitt 4.3.3), lange Kontextualisierung (Abschnitt 4.3.4), Werkzeugnutzung (Abschnitt 4.3.5), Sachlichkeit (Abschnitt 4.3.6) und Kontrollierbarkeit (Abschnitt 4.3.7).
4.3.1 Code
seit (einer Zeit) Kopilot und Codex (Chen et al., 2021) veröffentlicht wurden, haben LLMs für Code viel Aufmerksamkeit erhalten. Entwickler nutzen diese Modelle nun ausgiebig, um Codeschnipsel zu generieren, zu debuggen, Aufgaben zu automatisieren und die Codequalität zu verbessern. Für Llama 3 ist es unser Ziel, die Fähigkeiten zur Codegenerierung, Dokumentation, Fehlersuche und Überprüfung für die folgenden vorrangigen Programmiersprachen zu verbessern und zu bewerten: Python, Java, JavaScript, C/C++, TypeScript, Rust, PHP, HTML/CSS, SQL und Bash/Shell. Hier stellen wir die Ergebnisse vor, die durch die Schulung von Code-Experten, die Erzeugung synthetischer Daten für SFT, die Umstellung auf verbesserte Formate über Systemaufforderungen und die Erstellung von Qualitätsfiltern zur Entfernung schlechter Beispiele aus den Trainingsdaten zur Verbesserung dieser Codierungsfunktionen erzielt wurden.
Spezialisierte Ausbildung.Wir haben einen Code-Experten trainiert und ihn in mehreren Runden des Post-Trainings eingesetzt, um qualitativ hochwertige menschliche Code-Annotationen zu sammeln. Dies wurde erreicht, indem wir den Haupt-Pre-Trainingslauf abzweigten und das Pre-Training mit einer Mischung aus 1T-Token fortsetzten, die hauptsächlich (>85%) Code-Daten waren. Es hat sich gezeigt, dass fortgesetztes Vortraining mit domänenspezifischen Daten die Leistung in bestimmten Domänen verbessert (Gururangan et al., 2020). Wir folgen einem ähnlichen Rezept wie CodeLlama (Rozière et al., 2023). In den letzten paar Tausend Trainingsschritten führen wir ein Long Context Fine-Tuning (LCFT) auf einer hochwertigen Mischung von Code-Daten auf Repository-Ebene durch und erweitern die Kontextlänge des Experten auf 16K Token. Schließlich folgen wir einem ähnlichen Rezept zur Modellierung nach dem Training, wie in Abschnitt 4.1 beschrieben, um das Modell abzugleichen, aber unter Verwendung einer Mischung aus SFT- und DPO-Daten, die in erster Linie codespezifisch sind. Das Modell wird auch für das Rejection Sampling von Coding Cues verwendet (Abschnitt 4.2.2).
Erzeugung synthetischer Daten.Während der Entwicklung haben wir wichtige Probleme bei der Codegenerierung festgestellt, darunter Schwierigkeiten beim Befolgen von Anweisungen, Syntaxfehler, falsche Codegenerierung und Schwierigkeiten bei der Fehlerbehebung. Während dichte menschliche Annotationen diese Probleme theoretisch lösen könnten, bietet die synthetische Datengenerierung einen ergänzenden Ansatz, der billiger ist, besser skaliert und nicht durch das Fachwissen der Annotatoren eingeschränkt ist.
Wir haben daher Llama 3 und Code Expert verwendet, um eine große Anzahl synthetischer SFT-Dialoge zu erzeugen. Wir beschreiben drei High-Level-Methoden zur Erzeugung synthetischer Codedaten. Insgesamt haben wir bei SFT über 2,7 Millionen synthetische Beispiele verwendet.
1. Synthetische Datengenerierung: Implementierung von Feedback.Die Modelle 8B und 70B zeigen deutliche Leistungsverbesserungen bei Trainingsdaten, die von größeren, kompetenteren Modellen erzeugt wurden. Unsere vorläufigen Experimente deuten jedoch darauf hin, dass das Training von Llama 3 405B nur auf den von ihm selbst generierten Daten nicht hilfreich ist (oder die Leistung sogar verschlechtert). Um diese Einschränkung zu beheben, führen wir das Ausführungsfeedback als eine Quelle der Wahrheit ein, die es dem Modell ermöglicht, aus seinen Fehlern zu lernen und auf Kurs zu bleiben. Insbesondere generieren wir einen Datensatz von etwa einer Million synthetischer Code-Dialoge mit dem folgenden Verfahren:
- Erstellung von Problembeschreibungen:Zunächst generierten wir eine große Menge an Beschreibungen von Programmierproblemen, die eine Vielzahl von Themen abdecken (einschließlich Long-Tail-Verteilungen). Um diese Vielfalt zu erreichen, haben wir nach dem Zufallsprinzip Codeschnipsel aus einer Vielzahl von Quellen ausgewählt und das Modell aufgefordert, auf der Grundlage dieser Beispiele Programmierprobleme zu generieren. Auf diese Weise konnten wir eine breite Palette von Themen nutzen und einen umfassenden Satz von Problembeschreibungen erstellen (Wei et al., 2024).
- Generierung von Lösungen:Anschließend forderten wir Llama 3 auf, jedes Problem in der vorgegebenen Programmiersprache zu lösen. Wir stellten fest, dass das Hinzufügen guter Programmierregeln zu den Aufforderungen die Qualität der generierten Lösungen verbesserte. Außerdem fanden wir es hilfreich, das Modell aufzufordern, seinen Denkprozess mit Kommentaren zu erklären.
- Analyse der Korrektheit: Nach der Generierung von Lösungen ist es wichtig zu erkennen, dass ihre Korrektheit nicht garantiert ist und dass die Aufnahme falscher Lösungen in den fein abgestimmten Datensatz die Qualität des Modells beeinträchtigen kann. Wir können zwar keine vollständige Korrektheit garantieren, aber wir haben Methoden entwickelt, um die Korrektheit zu approximieren. Zu diesem Zweck nehmen wir den extrahierten Quellcode der generierten Lösungen und wenden eine Kombination aus statischen und dynamischen Analysetechniken an, um ihre Korrektheit zu prüfen:
- Statische Analyse: Wir lassen den gesamten generierten Code durch einen Parser und Code-Prüfwerkzeuge laufen, um die syntaktische Korrektheit zu gewährleisten und Syntaxfehler, die Verwendung nicht initialisierter Variablen oder nicht importierter Funktionen, Code-Stilprobleme, Typfehler usw. zu erkennen.
- Erstellung und Ausführung von Einheitstests: Für jedes Problem und jede Lösung veranlassen wir das Modell, Unit-Tests zu generieren und sie mit der Lösung in einer containerisierten Umgebung auszuführen, wobei Laufzeitfehler und einige semantische Fehler abgefangen werden.
- Fehlerrückmeldung und iterative Selbstkorrektur: Wenn die Lösung in irgendeinem Schritt fehlschlägt, fordern wir das Modell auf, sie zu ändern. Die Aufforderung enthält die ursprüngliche Problembeschreibung, die falsche Lösung und das Feedback des Parsers/Code-Inspektionswerkzeugs/Testprogramms (Standardausgabe, Standardfehler und Rückgabewert). Nach einer fehlgeschlagenen Ausführung eines Unit-Tests kann das Modell entweder den Code so korrigieren, dass er die bestehenden Tests besteht, oder seine Unit-Tests an den generierten Code anpassen. Nur Dialoge, die alle Tests bestehen, werden in den endgültigen Datensatz für die überwachte Feinabstimmung (SFT) aufgenommen. Wir haben festgestellt, dass etwa 20% der Lösungen anfänglich falsch waren, sich aber selbst korrigiert haben, was darauf hindeutet, dass das Modell aus dem Feedback der Ausführung gelernt und seine Leistung verbessert hat.
- Feinabstimmung und iterative Verbesserung: Der Feinabstimmungsprozess erfolgt über mehrere Runden, wobei jede Runde auf der vorherigen Runde aufbaut. Nach jeder Feinabstimmungsrunde wird das Modell verbessert, um qualitativ hochwertigere synthetische Daten für die nächste Runde zu erzeugen. Dieser iterative Prozess ermöglicht eine schrittweise Verfeinerung und Verbesserung der Modellleistung.
2) Synthetische Datenerzeugung: Übersetzung der Programmiersprache. Wir beobachten einen Leistungsunterschied zwischen den großen Programmiersprachen (z. B. Python/C++) und weniger verbreiteten Programmiersprachen (z. B. Typescript/PHP). Dies ist nicht überraschend, da wir weniger Trainingsdaten für weniger verbreitete Programmiersprachen haben. Um dies abzumildern, werden wir die verfügbaren Daten durch die Übersetzung von Daten aus gängigen Programmiersprachen in weniger gängige Sprachen ergänzen (ähnlich wie Chen et al. (2023) im Bereich der Inferenz). Dies wird durch die Eingabeaufforderung von Llama 3 und die Gewährleistung der Qualität durch syntaktisches Parsing, Kompilierung und Ausführung erreicht. Abbildung 8 zeigt ein Beispiel für synthetischen PHP-Code, der aus Python übersetzt wurde. Dadurch wird die mit dem MultiPL-E (Cassano et al., 2023) Benchmark gemessene Leistung von weniger verbreiteten Sprachen erheblich verbessert.
3) Synthetische Datenerzeugung: Rückübersetzung. Zur Verbesserung bestimmter Kodierfähigkeiten (z. B. Dokumentation, Interpretation), bei denen die Menge an Informationen aus dem Ausführungsfeedback nicht ausreicht, um die Qualität zu bestimmen, verwenden wir einen anderen mehrstufigen Ansatz. Mit diesem Verfahren haben wir etwa 1,2 Millionen synthetische Dialoge zur Interpretation, Generierung, Dokumentation und Fehlersuche von Code erstellt. Wir beginnen mit Codeschnipseln in verschiedenen Sprachen aus den Pre-Training-Daten:


- Erzeugen: Wir haben Llama 3 aufgefordert, Daten zu generieren, die die Zielfähigkeiten repräsentieren (z. B. Kommentare und Dokumentationsstrings zu einem Codeschnipsel hinzuzufügen oder das Modell zu bitten, ein Stück Code zu interpretieren).
- Umgekehrte Übersetzung. Wir fordern das Modell auf, die synthetisch erzeugten Daten in den ursprünglichen Code zurück zu übersetzen (z. B. fordern wir das Modell auf, Code nur aus seinen Dokumenten zu erzeugen, oder wir bitten das Modell, Code nur aus seinen Erklärungen zu erzeugen).
- Filtrierung. Unter Verwendung des Originalcodes als Referenz fordern wir Llama 3 auf, die Qualität der Ausgabe zu bestimmen (z. B. fragen wir das Modell, wie getreu der rückübersetzte Code dem Originalcode entspricht). Wir verwenden dann das generierte Beispiel mit der höchsten Selbstvalidierungspunktzahl in SFT.
Systemführung für die Zurückweisung von Proben. Beim Rejection Sampling verwenden wir code-spezifische Systemhinweise, um die Lesbarkeit, Dokumentation, Vollständigkeit und Konkretheit des Codes zu verbessern. Wie in Abschnitt 7 beschrieben, werden diese Daten zur Feinabstimmung des Sprachmodells verwendet. Abbildung 9 zeigt ein Beispiel dafür, wie Systemhinweise dazu beitragen können, die Qualität des generierten Codes zu verbessern - es werden notwendige Kommentare hinzugefügt, informativere Variablennamen verwendet, Speicherplatz gespart usw.
Filtern von Trainingsdaten anhand von Ausführung und Modell als Rubrik. Wie in Abschnitt 4.2.3 beschrieben, sind wir gelegentlich auf Qualitätsprobleme in den zurückgewiesenen Stichprobendaten gestoßen, wie z. B. die Einbeziehung fehlerhafter Codeblöcke. Die Erkennung dieser Probleme in den abgelehnten Stichprobendaten ist nicht so einfach wie die Erkennung unserer synthetischen Codedaten, da die Antworten auf die abgelehnten Stichproben oft eine Mischung aus natürlicher Sprache und Code enthalten, der nicht immer ausführbar ist. (Zum Beispiel können Benutzeraufforderungen explizit nach Pseudocode oder Änderungen an nur sehr kleinen Teilen der ausführbaren Datei fragen.) Um dieses Problem zu lösen, verwenden wir einen "Modell als Richter"-Ansatz, bei dem frühere Versionen von Llama 3 bewertet werden und eine binäre (0/1) Punktzahl auf der Grundlage von zwei Kriterien erhalten: Korrektheit des Codes und Stil des Codes. Nur Beispiele mit einer perfekten Punktzahl von 2 wurden beibehalten. Anfänglich führte diese strenge Filterung zu einer Verschlechterung der nachgelagerten Benchmark-Leistung, vor allem weil dadurch unverhältnismäßig viele Beispiele mit schwierigen Hinweisen entfernt wurden. Um dem entgegenzuwirken, änderten wir strategisch einige der Antworten, die als die schwierigsten kodierten Daten eingestuft wurden, bis sie die Llama-basierten "Modell als Richter"-Kriterien erfüllten. Durch die Verbesserung dieser anspruchsvollen Fragen wurde bei den kodierten Daten ein Gleichgewicht zwischen Qualität und Schwierigkeit hergestellt, um eine optimale Downstream-Leistung zu erzielen.
4.3.2 Mehrsprachigkeit
In diesem Abschnitt wird beschrieben, wie wir die mehrsprachigen Fähigkeiten von Llama 3 verbessert haben, einschließlich: Training eines Expertenmodells, das auf mehrsprachige Daten spezialisiert ist; Beschaffung und Generierung hochwertiger, fein abgestimmter Daten mehrsprachiger Befehle für Deutsch, Französisch, Italienisch, Portugiesisch, Hindi, Spanisch und Thailändisch; und Lösung der besonderen Herausforderungen des mehrsprachigen Bootstrappings, um die Gesamtleistung unseres Modells zu verbessern.
Spezialisierte Ausbildung.Unser Llama 3 Pre-Training-Datenmix enthält weit mehr englische Token als nicht-englische Token. Um qualitativ hochwertigere nicht-englische menschliche Annotationen zu sammeln, trainieren wir ein mehrsprachiges Expertenmodell, indem wir die Pre-Trainingsläufe verzweigen und das Pre-Training mit einem Datenmix fortsetzen, der 90% mehrsprachige Token enthält. Anschließend wird dieses Expertenmodell wie in Abschnitt 4.1 beschrieben nachtrainiert. Dieses Expertenmodell wird dann verwendet, um qualitativ hochwertigere nicht-englische menschliche Annotationen zu sammeln, bis das Pre-Training vollständig abgeschlossen ist.
Mehrsprachige Datenerfassung.Unsere mehrsprachigen SFT-Daten stammen hauptsächlich aus den folgenden Quellen. Die Gesamtverteilung beträgt 2,4% menschliche Annotationen, 44,2% Daten aus anderen NLP-Aufgaben, 18,8% Rückweisungsstichproben und 34,6% Übersetzungsinferenzdaten.
- Manuelle Kommentierung:Wir sammeln qualitativ hochwertige, manuell annotierte Daten von Linguisten und Muttersprachlern. Diese Annotationen bestehen hauptsächlich aus offenen Hinweisen, die reale Anwendungsfälle darstellen.
- Daten aus anderen NLP-Aufgaben:Zur weiteren Verbesserung verwenden wir mehrsprachige Trainingsdaten aus anderen Aufgaben und schreiben sie in ein Dialogformat um. Zum Beispiel verwenden wir Daten aus exams-qa (Hardalov et al., 2020) und Conic10k (Wu et al., 2023). Um das Sprachalignment zu verbessern, verwenden wir auch Paralleltexte von GlobalVoices (Prokopidis et al., 2016) und Wikimedia (Tiedemann, 2012). Wir verwendeten LID-basierte Filterung und Blaser 2.0 (Seamless Communication et al., 2023), um Daten von geringer Qualität zu entfernen. Für die Paralleltextdaten verwendeten wir statt direkter Zweitextpaare eine von Wei et al. (2022a) inspirierte mehrsprachige Vorlage, um reale Dialoge in Übersetzungs- und Sprachlernszenarien besser zu simulieren.
- Stichprobendaten ablehnen:Wir wendeten Rejection Sampling auf von Menschen annotierte Stichwörter an, um qualitativ hochwertige Stichproben für die Feinabstimmung zu generieren, mit nur wenigen Änderungen im Vergleich zum Prozess für englische Daten:
- Generierung: Wir haben die zufällige Auswahl von Temperatur-Hyperparametern im Bereich von 0,2 - 1 in frühen Runden des Post-Trainings untersucht, um die Generierung zu diversifizieren. Bei hohen Temperaturen können Antworten auf mehrsprachige Hinweise kreativ und inspirierend sein, aber auch zu unnötigem oder unnatürlichem Code-Switching neigen. In den letzten Phasen des Post-Trainings haben wir einen konstanten Wert von 0,6 verwendet, um diesen Kompromiss auszugleichen. Darüber hinaus haben wir spezielle Systemhinweise verwendet, um die Formatierung, Struktur und allgemeine Lesbarkeit der Antworten zu verbessern.
- Auswahl: Vor der auf dem Belohnungsmodell basierenden Auswahl haben wir mehrsprachige Prüfungen durchgeführt, um eine hohe Rate an sprachlichen Übereinstimmungen zwischen Aufforderungen und Antworten zu gewährleisten (z. B. sollte man nicht erwarten, dass auf romanisierte Hindi-Aufforderungen mit Hindi-Sanskrit-Schriften geantwortet wird).
- Daten zur Übersetzung:Wir haben versucht, die Verwendung von maschinellen Übersetzungsdaten zur Feinabstimmung des Modells zu vermeiden, um das Auftreten von Translated English (Bizzoni et al., 2020; Muennighoff et al., 2023) oder möglicher Verzerrungen durch Namen (Wang et al., 2022a), Geschlecht (Savoldi et al., 2021) oder Kultur (Ji et al., 2023) zu verhindern. . Darüber hinaus wollten wir verhindern, dass das Modell nur Aufgaben aus dem englischsprachigen Kulturkreis erhält, die möglicherweise nicht repräsentativ für die sprachliche und kulturelle Vielfalt sind, die wir erfassen wollten. Wir machten eine Ausnahme und übersetzten die synthetisierten quantitativen Argumentationsdaten (siehe Abschnitt 4.3.3 für weitere Informationen) ins Nicht-Englische, um die quantitative Argumentationsleistung in nicht-englischen Sprachen zu verbessern. Aufgrund der einfachen Sprache dieser mathematischen Probleme wiesen die übersetzten Stichproben nur wenige Qualitätsprobleme auf. Wir stellten fest, dass die Zugabe dieser übersetzten Daten zum MGSM (Shi et al., 2022) zu erheblichen Verbesserungen führte.
4.3.3 Mathematik und logisches Denken
Wir definieren schlussfolgerndes Denken als die Fähigkeit, eine mehrstufige Berechnung durchzuführen und am Ende die richtige Antwort zu erhalten.
Wir haben uns bei der Ausbildung von Modellen, die sich durch mathematisches Denken auszeichnen, von mehreren Herausforderungen leiten lassen:
- Fehlen von Tipps. Mit zunehmender Problemkomplexität sinkt die Zahl der gültigen Hinweise oder Probleme für die überwachte Feinabstimmung (SFT). Diese Knappheit macht es schwierig, vielfältige und repräsentative Trainingsdatensätze zu erstellen, um Modellen verschiedene mathematische Fähigkeiten beizubringen (Yu et al. 2023; Yue et al. 2023; Luo et al. 2023; Mitra et al. 2024; Shao et al. 2024; Yue et al. 2024b).
- Fehlen echter Begründungsprozesse. Effektives logisches Denken erfordert schrittweise Lösungen, um den Denkprozess zu erleichtern (Wei et al., 2022c). Allerdings mangelt es oft an realistischen Denkprozessen, die für die Anleitung des Modells zur schrittweisen Zerlegung des Problems und zum Erreichen der endgültigen Antwort wichtig sind (Zelikman et al., 2022).
- Falscher Zwischenschritt. Bei der Verwendung von modellgenerierten Inferenzketten sind die Zwischenschritte möglicherweise nicht immer korrekt (Cobbe et al. 2021; Uesato et al. 2022; Lightman et al. 2023; Wang et al. 2023a). Diese Ungenauigkeit kann zu falschen endgültigen Antworten führen und muss behoben werden.
- Training des Modells mit externen Tools. Die Fähigkeit, Modelle so zu verbessern, dass sie externe Tools wie Code-Interpreter nutzen können, ermöglicht es ihnen, durch die Verflechtung von Code und Text zu argumentieren (Gao et al. 2023; Chen et al. 2022; Gou et al. 2023). Diese Fähigkeit kann ihre Problemlösungskompetenz erheblich verbessern.
- Unterschiede zwischen Ausbildung und Argumentation: die Die Art und Weise, wie Modelle während des Trainings feinabgestimmt werden, unterscheidet sich in der Regel von der Art und Weise, wie sie während der Argumentation verwendet werden. Während der Schlussfolgerungen kann das feinabgestimmte Modell mit Menschen oder anderen Modellen interagieren und Feedback benötigen, um seine Schlussfolgerungen zu verbessern. Die Gewährleistung der Konsistenz zwischen Training und realen Anwendungen ist entscheidend für die Aufrechterhaltung der Schlussfolgerungsleistung.
Um diese Herausforderungen zu bewältigen, wenden wir die folgende Methodik an:
- Behebung des Mangels an Hinweisen. Wir nehmen relevante Pre-Training-Daten aus mathematischen Kontexten und konvertieren sie in ein Frage-Antwort-Format, das zur überwachten Feinabstimmung verwendet werden kann. Darüber hinaus identifizieren wir mathematische Fähigkeiten, bei denen das Modell schlecht abschneidet, und sammeln aktiv Hinweise von Menschen, um dem Modell diese Fähigkeiten beizubringen. Zur Erleichterung dieses Prozesses erstellen wir eine Taxonomie der mathematischen Fähigkeiten (Didolkar et al., 2024) und bitten Menschen, die entsprechenden Aufforderungen/Fragen zu stellen.
- Anreicherung von Trainingsdaten mit schrittweisen Reasoning-Schritten. Wir verwenden Llama 3, um Schritt-für-Schritt-Lösungen für eine Reihe von Hinweisen zu generieren. Für jede Aufforderung erzeugt das Modell eine variable Anzahl von Ergebnissen. Diese generierten Ergebnisse werden dann auf der Grundlage der richtigen Antworten gefiltert (Li et al., 2024a). Wir führen auch eine Selbstvalidierung durch, bei der Llama 3 verwendet wird, um zu überprüfen, ob eine bestimmte Schritt-für-Schritt-Lösung für ein bestimmtes Problem gültig ist. Dieser Prozess verbessert die Qualität der feinabgestimmten Daten, indem er Fälle eliminiert, in denen das Modell keine gültigen Schlussfolgerungstrajektorien erzeugt.
- Filtern von fehlerhaften Argumentationsschritten. Wir trainieren Ergebnisse und schrittweise Belohnungsmodelle (Lightman et al., 2023; Wang et al., 2023a), um Trainingsdaten mit falschen Zwischeninferenzschritten zu filtern. Diese Reward-Modelle werden verwendet, um Daten mit ungültiger schrittweiser Inferenz zu eliminieren und sicherzustellen, dass die Feinabstimmung qualitativ hochwertige Daten liefert. Für anspruchsvollere Hinweise verwenden wir die Monte-Carlo-Baumsuche (MCTS) mit gelernten schrittweisen Belohnungsmodellen, um gültige Inferenztrajektorien zu generieren, was die Sammlung von qualitativ hochwertigen Inferenzdaten weiter verbessert (Xie et al., 2024).
- Verflechtung von Codes und textueller Argumentation. Wir schlagen vor, dass Llama 3 das Inferenzproblem durch eine Kombination aus textueller Inferenz und dem dazugehörigen Python-Code löst (Gou et al., 2023). Die Codeausführung wird als Feedbacksignal verwendet, um Fälle zu eliminieren, in denen die Inferenzkette ungültig ist, und um die Korrektheit des Inferenzprozesses sicherzustellen.
- Aus Feedback und Fehlern lernen. Um menschliches Feedback zu simulieren, verwenden wir falsche Generierungsergebnisse (d.h. Generierungsergebnisse, die zu falschen Inferenztrajektorien führen) und nehmen Fehlerkorrekturen vor, indem wir Llama 3 auffordern, korrekte Generierungsergebnisse zu erzeugen (An et al. 2023b; Welleck et al. 2022; Madaan et al. 2024a). Der selbst-iterative Prozess der Nutzung von Rückmeldungen aus fehlerhaften Versuchen und deren Korrektur trägt dazu bei, die Fähigkeit des Modells zu verbessern, genau zu folgern und aus seinen Fehlern zu lernen.
4.3.4 Langer Kontext
In der letzten Pre-Trainingsphase haben wir die Kontextlänge von Llama 3 von 8K auf 128K Token erweitert (siehe Abschnitt 3.4 für weitere Informationen dazu). Ähnlich wie beim Vortraining stellten wir fest, dass die Formulierung während der Feinabstimmung sorgfältig angepasst werden musste, um ein Gleichgewicht zwischen kurzen und langen Kontextfähigkeiten herzustellen.
SFT und Erzeugung synthetischer Daten. Die einfache Anwendung unserer bestehenden SFT-Formulierung, bei der nur Daten mit kurzem Kontext verwendet wurden, führte zu einem deutlichen Rückgang der Fähigkeit, lange Kontexte zu erkennen, was die Notwendigkeit unterstreicht, Daten mit langem Kontext in das SFT-Datenportfolio aufzunehmen. In der Praxis ist es jedoch unpraktisch, die meisten dieser Beispiele manuell zu kennzeichnen, da das Lesen langer Kontexte mühsam und zeitaufwändig ist. Daher verlassen wir uns stark auf synthetische Daten, um diese Lücke zu schließen. Wir haben eine frühere Version von Llama 3 verwendet, um synthetische Daten zu generieren, die auf den wichtigsten Anwendungsfällen für lange Kontexte basieren: (potenziell mehrere Runden von) Fragen und Antworten, lange Zusammenfassungen von Dokumenten und Überlegungen zur Codebasis, und beschreiben diese Anwendungsfälle im Folgenden ausführlicher.
- Q&A: Wir haben sorgfältig eine Reihe langer Dokumente aus dem Pre-Training-Datensatz ausgewählt. Wir haben diese Dokumente in 8K gelabelte Chunks aufgeteilt und eine frühere Version des Llama 3-Modells aufgefordert, QA-Paare auf zufällig ausgewählten Chunks zu erzeugen. Das gesamte Dokument wird beim Training als Kontext verwendet.
- Zusammenfassungen: Wir wenden die hierarchische Zusammenfassung langer Kontextdokumente an, indem wir zunächst unser stärkstes Llama 3 8K-Kontextmodell verwenden, um Blöcke von 8K Eingabelänge hierarchisch zusammenzufassen. Diese Zusammenfassungen werden dann aggregiert. Während des Trainings stellen wir das vollständige Dokument zur Verfügung und fordern das Modell auf, das Dokument unter Beibehaltung aller wichtigen Details zusammenzufassen. Wir generieren auch QA-Paare auf der Grundlage der Zusammenfassungen der Dokumente und fordern das Modell mit Fragen auf, die ein globales Verständnis des gesamten langen Dokuments erfordern.
- Langer Kontext Code Reasoning: Wir analysieren Python-Dateien, um Import-Anweisungen zu identifizieren und ihre Abhängigkeiten zu ermitteln. Von hier aus wählen wir die am häufigsten verwendeten Dateien aus, insbesondere diejenigen, die von mindestens fünf anderen Dateien referenziert werden. Wir entfernen eine dieser Schlüsseldateien aus dem Repository und fordern das Modell auf, die Abhängigkeiten zu den fehlenden Dateien zu ermitteln und den erforderlichen fehlenden Code zu generieren.
Wir klassifizieren diese synthetisch erzeugten Proben außerdem nach der Sequenzlänge (16K, 32K, 64K und 128K), um die Eingabelänge genauer zu lokalisieren.
Durch sorgfältige Ablationsexperimente konnten wir feststellen, dass das Mischen der synthetisch erzeugten langen Kontextdaten von 0,1% mit den ursprünglichen kurzen Kontextdaten die Leistung sowohl der kurzen als auch der langen Kontext-Benchmark-Tests optimiert.
DSB. Wir stellen fest, dass die Verwendung von Trainingsdaten mit kurzen Kontexten in DPO die Leistung bei langen Kontexten nicht negativ beeinflusst, solange das SFT-Modell bei Aufgaben mit langen Kontexten gut funktioniert. Wir vermuten, dass dies darauf zurückzuführen ist, dass unsere DPO-Formulierung weniger Optimierungsschritte enthält als SFT. In Anbetracht dieser Erkenntnis behalten wir die Standard-DPO-Formulierung für kurze Kontexte zusätzlich zu den SFT-Prüfpunkten für lange Kontexte bei.
4.3.5 Einsatz von Werkzeugen
Wenn man Large Language Models (LLMs) beibringt, Werkzeuge wie Suchmaschinen oder Code-Interpreter zu nutzen, kann man die Bandbreite der Aufgaben, die sie lösen können, erheblich erweitern und sie von reinen Gesprächsmodellen zu vielseitigeren Assistenten machen (Nakano et al. 2021; Thoppilan et al. 2022; Parisi et al. 2022; Gao et al. 2023 2022; Parisi et al. 2022; Gao et al. 2023; Mialon et al. 2023a; Schick et al. 2024). Wir trainierten Llama 3 für die Interaktion mit den folgenden Tools:
- Llama 3 wurde darauf trainiert, Brave Search7 zu nutzen, um Fragen zu aktuellen Ereignissen zu beantworten, die nach Ablauf der Wissensfrist gestellt wurden, oder um Anfragen zu beantworten, die das Abrufen bestimmter Informationen aus dem Internet erfordern.
- Llama 3 generiert und führt Code aus, um komplexe Berechnungen durchzuführen, liest vom Nutzer hochgeladene Dateien und löst Aufgaben, die auf diesen Dateien basieren, wie z. B. Quiz, Zusammenfassungen, Datenanalysen oder Visualisierungen.
- Llama 3 kann die Wolfram Alpha API8 nutzen, um mathematische und wissenschaftliche Probleme genauer zu lösen oder um genaue Informationen aus Wolframs Datenbanken abzurufen.
Das erstellte Modell ist in der Lage, diese Werkzeuge in einer Chat-Umgebung zu verwenden, um Benutzeranfragen zu lösen, einschließlich Dialogen mit mehreren Runden. Wenn die Anfrage mehrere Aufrufe der Werkzeuge erfordert, kann das Modell Schritt-für-Schritt-Pläne schreiben, die die Werkzeuge nacheinander aufrufen und nach jedem Werkzeugaufruf eine Begründung liefern.
Wir verbessern auch die Fähigkeiten von Llama 3 zur Nutzung von Werkzeugen bei Nullproben - bei potenziell unbekannten Werkzeugdefinitionen und Benutzeranfragen in einer kontextbezogenen Umgebung trainieren wir das Modell, um die richtigen Werkzeugaufrufe zu generieren.
Verwirklichung.Wir implementieren die wichtigsten Werkzeuge als Python-Objekte mit verschiedenen Methoden. Zero-Sample-Tools können als Python-Funktionen mit Beschreibungen und Dokumentation (d. h. Beispielen für ihre Verwendung) implementiert werden, und das Modell benötigt nur die Funktionssignatur und den Docstring als Kontext, um die entsprechenden Aufrufe zu generieren.
Wir konvertieren auch Funktionsdefinitionen und Aufrufe in das JSON-Format, z. B. für Web-API-Aufrufe. Alle Tool-Aufrufe werden vom Python-Interpreter ausgeführt, der an der Llama 3-Systemeingabeaufforderung aktiviert werden muss. Die Kernwerkzeuge können separat von der Systemsteuerung aus aktiviert oder deaktiviert werden.
Datenerhebung.Im Gegensatz zu Schick et al. (2024) stützen wir uns auf menschliche Annotationen und Präferenzen, um Llama 3 die Nutzung der Werkzeuge beizubringen. Dies unterscheidet sich von der Post-Training-Pipeline, die typischerweise in Llama 3 verwendet wird, in zwei wesentlichen Punkten:
- In Bezug auf Werkzeuge enthalten Dialoge oft mehr als eine Assistentenmeldung (z. B. Aufruf eines Werkzeugs und Argumentation über die Ausgabe des Werkzeugs). Daher führen wir eine Annotation auf Nachrichtenebene durch, um detailliertes Feedback zu sammeln: Der Annotator gibt Präferenzen für zwei Assistenznachrichten im selben Kontext an oder bearbeitet eine der Nachrichten, wenn es ein größeres Problem mit beiden gibt. Die ausgewählte oder geänderte Nachricht wird dann dem Kontext hinzugefügt und der Dialog wird fortgesetzt. Auf diese Weise erhält der Benutzer eine Rückmeldung über die Fähigkeit des Assistenten, das Tool aufzurufen und über die Ergebnisse des Tools nachzudenken. Der Kommentator kann die Ausgabe des Tools nicht bewerten oder bearbeiten.
- Wir haben keine Rückweisungsstichproben durchgeführt, da bei unserem Tool-Benchmarking keine Verbesserungen festgestellt wurden.
Um den Annotationsprozess zu beschleunigen, haben wir zunächst die grundlegenden Nutzungsmöglichkeiten des Tools durch eine Feinabstimmung der synthetischen Daten aus den vorherigen Llama 3-Checkpoints getestet. Auf diese Weise muss der Annotator weniger Bearbeitungsvorgänge durchführen. Da Llama 3 im Laufe der Entwicklung immer besser wird, verkomplizieren wir unser Protokoll für die menschliche Kommentierung zunehmend: Wir beginnen mit einer einzigen Runde der Kommentierung der Werkzeugnutzung, gehen dann zur Werkzeugnutzung im Dialog über und kommentieren schließlich die mehrstufige Werkzeugnutzung und Datenanalyse.
Tools-Datensatz.Um Daten für die Verwendung in Anwendungen zu erstellen, die Werkzeuge verwenden, gehen wir wie folgt vor.
- Verwendung des Werkzeugs in einem Schritt. Wir führen zunächst einen kleinen Teil der Beispielgenerierung durch, um Benutzeraufforderungen zu synthetisieren, die konstruktionsbedingt einen Aufruf eines unserer Kernwerkzeuge erfordern (z. B. eine Frage, die unsere Wissensfrist überschreitet). Dann generieren wir, immer noch auf der Grundlage eines kleinen Teils der Beispielgenerierung, geeignete Toolaufrufe für diese Hinweise, führen sie aus und fügen die Ausgabe dem Kontext des Modells hinzu. Schließlich fordern wir das Modell erneut auf, die endgültige Antwort auf die Benutzeranfrage auf der Grundlage der Tool-Ausgabe zu generieren. Am Ende erhalten wir Trajektorien in der folgenden Form: Systemhinweise, Benutzerhinweise, Toolaufrufe, Toolausgaben und endgültige Antworten. Wir haben auch etwa 30% des Datensatzes herausgefiltert, um nicht durchführbare Toolaufrufe oder andere Formatierungsprobleme zu entfernen.
- Einsatz eines mehrstufigen Werkzeugs. Wir folgen einem ähnlichen Protokoll, indem wir zunächst synthetische Daten erzeugen, um dem Modell grundlegende 다단계-Werkzeugnutzungsfähigkeiten beizubringen. Zu diesem Zweck fordern wir Llama 3 zunächst auf, Benutzerhinweise zu generieren, die mindestens zwei Werkzeugaufrufe erfordern (entweder vom selben Werkzeug oder von verschiedenen Werkzeugen aus unserem Kernsatz). Auf der Grundlage dieser Hinweise führen wir dann eine kleine Anzahl von Stichproben durch, in denen wir Llama 3 auffordern, eine Lösung zu generieren, die aus miteinander verwobenen Inferenzschritten und Werkzeugaufrufen besteht, ähnlich wie bei der ReAct (Yao et al., 2022). Siehe Abbildung 10 für ein Beispiel von Lama 3, das eine Aufgabe ausführt, die den Einsatz von Werkzeugen in mehreren Schritten erfordert.
- Hochladen von Dateien. Wir kommentieren die folgenden Dateitypen: .txt, .docx, .pdf, .pptx, .xlsx, .csv, .tsv, .py, .json, .jsonl, .html, .xml. Unsere Aufforderungen basieren auf den gelieferten Dateien und bitten darum, den Inhalt der Dateien zusammenzufassen, Fehler zu finden und zu beheben, die Codeschnipsel zu optimieren und Datenanalysen oder Visualisierungen durchzuführen. Abbildung 11 zeigt ein Beispiel für Llama 3, das eine Aufgabe ausführt, bei der Dateien hochgeladen werden.

Nach der Feinabstimmung dieser synthetischen Daten sammelten wir menschliche Anmerkungen zu einer Vielzahl von Szenarien, darunter mehrere Interaktionsrunden, die Verwendung von Werkzeugen über drei Schritte hinaus und Situationen, in denen Werkzeugaufrufe keine zufriedenstellenden Antworten ergaben. Wir ergänzten die synthetischen Daten mit verschiedenen Systemhinweisen, um dem Modell beizubringen, Werkzeuge nur dann zu verwenden, wenn sie aktiviert sind. Um das Modell darauf zu trainieren, Tool-Aufrufe für einfache Anfragen zu vermeiden, fügten wir auch Anfragen und deren Antworten aus einfach zu berechnenden oder Frage-und-Antwort-Datensätzen hinzu (Berant et al. 2013; Koncel-Kedziorski et al. 2016; Joshi et al. 2017; Amini et al. 2019), die das Tool nicht verwenden, bei denen die Systemhinweise das Tool aktiviert.
Zero Sample Tool Usage Data. Wir verbessern die Fähigkeit von Llama 3, Nullproben-Tools (auch bekannt als Funktionsaufrufe) zu verwenden, indem wir ein großes und vielfältiges Tupel von Teilkompositionen (Funktionsdefinitionen, Benutzerabfragen, entsprechende Aufrufe) feinabstimmen. Wir evaluieren unser Modell an einer Sammlung von unbekannten Werkzeugen.
- Einzelne, verschachtelte und parallele Funktionsaufrufe: Die Aufrufe können einfach, verschachtelt (d. h., wir übergeben Funktionsaufrufe als Argumente an eine andere Funktion) oder parallel (d. h., das Modell gibt eine Liste unabhängiger Funktionsaufrufe zurück) sein. Die Generierung einer Vielzahl von Funktionen, Abfragen und realen Ergebnissen kann eine Herausforderung sein (Mekala et al., 2024), und wir verlassen uns auf das Mining des Stacks (Kocetkov et al., 2022), um unsere synthetischen Benutzerabfragen auf reale Funktionen zu stützen. Genauer gesagt, extrahieren wir Funktionsaufrufe und ihre Definitionen, bereinigen und filtern sie (z. B. fehlende Dokumentzeichenfolgen oder nicht ausführbare Funktionen) und verwenden Llama 3, um natürlichsprachliche Abfragen zu generieren, die den Funktionsaufrufen entsprechen.
- Funktionsaufrufe über mehrere Runden: Wir generieren auch synthetische Daten für Mehrrunden-Dialoge, die Funktionsaufrufe enthalten, und folgen dabei einem Protokoll, das dem in Li et al. (2023b) vorgestellten ähnlich ist. Wir verwenden mehrere Agenten, um Domänen, APIs, Benutzeranfragen, API-Aufrufe und Antworten zu generieren, wobei wir sicherstellen, dass die generierten Daten eine Reihe verschiedener Domänen und realer APIs abdecken.
4.3.6 Sachlich
Unrealismus bleibt eine große Herausforderung für große Sprachmodelle. Modelle neigen dazu, selbst in Bereichen, in denen es ihnen an Wissen mangelt, übermäßig selbstbewusst zu sein. Trotz dieser Unzulänglichkeiten werden sie oft als Wissensbasis verwendet, was zu gefährlichen Ergebnissen wie der Verbreitung von Fehlinformationen führen kann. Wir erkennen zwar an, dass Wahrhaftigkeit über Illusion hinausgeht, verfolgen aber hier einen Ansatz, der die Illusion an die erste Stelle setzt.
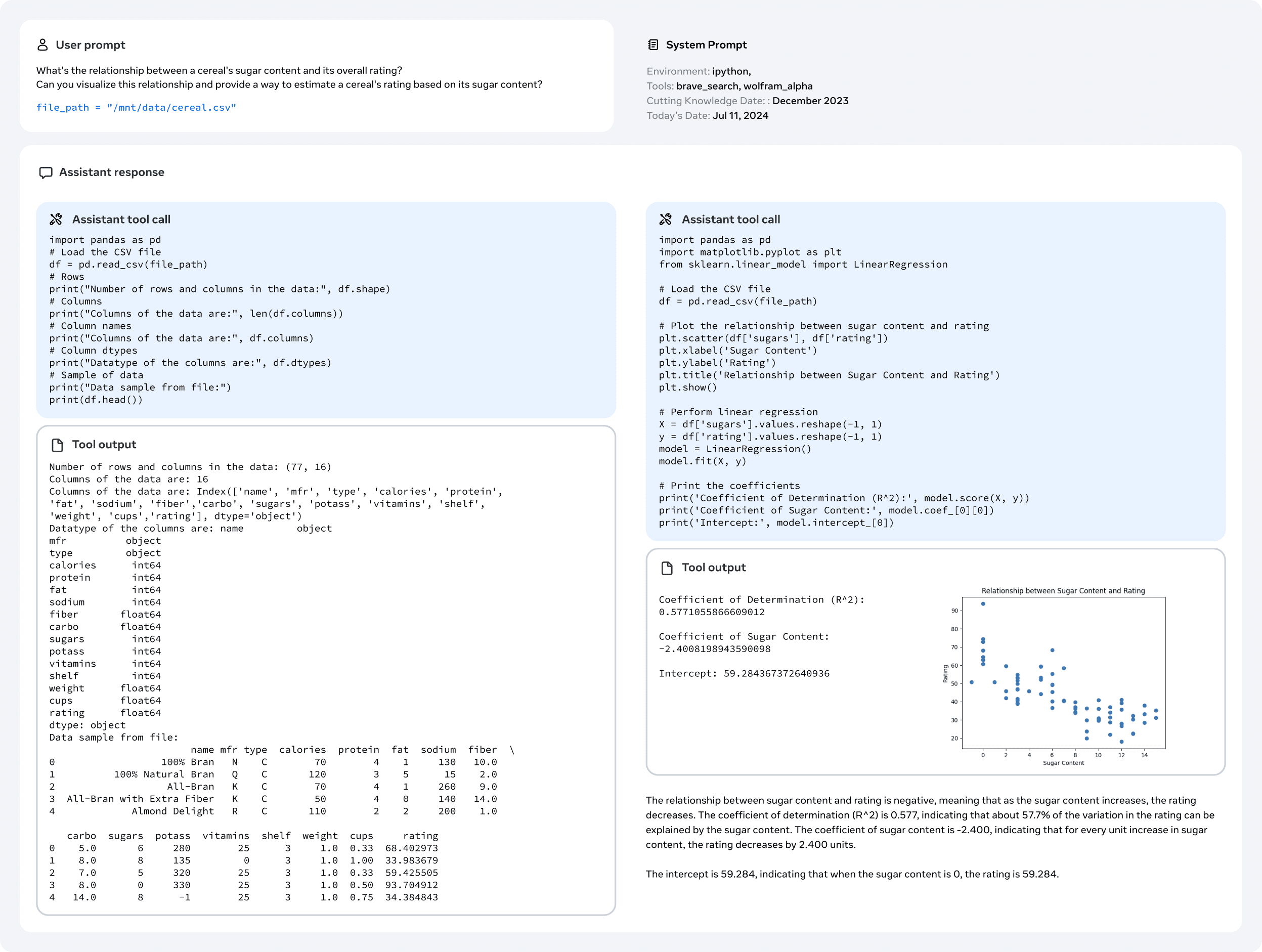
Abbildung 11 Datei-Upload-Verarbeitung. Das Beispiel zeigt, wie Llama 3 eine hochgeladene Datei analysiert und visualisiert.
Wir folgen dem Grundsatz, dass das Modell nach dem Training auf das "Wissen, was es weiß" ausgerichtet werden sollte, anstatt Wissen hinzuzufügen (Gekhman et al., 2024; Mielke et al., 2020). Unser Hauptansatz besteht darin, Daten zu generieren, die die Modellerstellung auf eine Teilmenge der in den Pre-Training-Daten vorhandenen realen Daten abstimmen. Zu diesem Zweck haben wir ein Verfahren zur Wissenserkennung entwickelt, das die kontextuellen Fähigkeiten von Llama 3 nutzt. Dieser Datengenerierungsprozess besteht aus den folgenden Schritten:
- Extrahieren Sie ein Datensegment aus den Pre-Training-Daten.
- Generieren Sie Sachfragen zu diesen Abschnitten (Kontexten), indem Sie Llama 3 auffordern.
- Beispielantworten zu dieser Frage von Llama 3.
- Der ursprüngliche Kontext diente als Referenz, und Llama 3 wurde als Richter eingesetzt, um die Korrektheit der Generierung zu bewerten.
- Verwenden Sie Llama 3 als Bewerter, um den erzeugten Reichtum zu bewerten.
- Generieren Sie Ablehnungsgründe für Antworten, die über mehrere Generationen hinweg konsistent informativ und falsch sind, und verwenden Sie Llama 3
Wir verwenden Daten, die aus Wissensabfragen generiert werden, um das Modell dazu anzuhalten, nur die Fragen zu beantworten, die es kennt, und Fragen abzulehnen, bei denen es sich nicht sicher ist. Darüber hinaus sind die Daten vor dem Training nicht immer sachlich konsistent oder korrekt. Daher haben wir auch einen begrenzten Satz von gekennzeichneten Wahrheitsdaten gesammelt, die sich mit sensiblen Themen befassten, bei denen es viele sachlich widersprüchliche oder falsche Aussagen gab.
4.3.7 Kontrollierbarkeit
Kontrollierbarkeit ist die Fähigkeit, das Verhalten und die Ergebnisse des Modells so zu steuern, dass es den Anforderungen von Entwicklern und Nutzern entspricht. Da es sich bei Llama 3 um ein generisches Basismodell handelt, sollte es einfach sein, es für verschiedene nachgelagerte Anwendungsfälle zu steuern. Um die Steuerbarkeit von Llama 3 zu verbessern, haben wir uns darauf konzentriert, die Steuerbarkeit durch Systemaufforderungen (unter Verwendung von Befehlen in natürlicher Sprache) zu verbessern, insbesondere im Hinblick auf die Länge der Antwort, die Formatierung, den Tonfall und die Rollen-/Charaktereinstellung.
Datenerhebung. Wir sammelten Präferenzbeispiele für die Beherrschbarkeit in der Kategorie Allgemeines Englisch, indem wir die Kommentatoren baten, verschiedene Systemaufforderungen für Llama 3 zu entwerfen. Der Kommentator ließ dann das Modell einen Dialog führen, um zu beurteilen, ob das Modell in der Lage war, die in den System-Prompts definierten Anweisungen während des gesamten Dialogs konsequent zu befolgen. Im Folgenden sind Beispiele für angepasste System-Prompts aufgeführt, die zur Verbesserung der Kontrollierbarkeit verwendet wurden:
"Du bist ein hilfsbereiter und energiegeladener KI-Chatbot, der vielbeschäftigten Familien bei der Essensplanung behilflich ist. Mahlzeiten für den Arbeitstag sollten schnell und einfach sein. Fertiggerichte wie Müsli, englische Muffins mit vorgekochtem Speck und andere schnell und einfach zuzubereitende Speisen sollten beim Frühstück und Mittagessen Vorrang haben. Diese Familie ist sehr beschäftigt. Erkundigen Sie sich, ob sie das Nötigste und ihre Lieblingsgetränke wie Kaffee oder Energydrinks vorrätig haben, damit sie nicht vergessen, sie zu kaufen. Wenn es sich nicht um einen besonderen Anlass handelt, denken Sie daran, Ihr Budget zu schonen.
Modellierung. Nach dem Sammeln von Präferenzdaten verwenden wir diese Daten für die Belohnungsmodellierung, das Rejection Sampling, die SFT (kontinuierliche Feinabstimmung) und die DPO (datengesteuerte Parameteroptimierung), um die Kontrollierbarkeit von Llama 3 zu verbessern.
5 Ergebnisse
Wir haben eine umfangreiche Reihe von Evaluierungen von Llama 3 durchgeführt und dabei die Leistung von (1) vortrainierten Sprachmodellen, (2) nachtrainierten Sprachmodellen und (3) den Sicherheitsfunktionen von Llama 3 untersucht. Wir stellen die Ergebnisse dieser Evaluierungen in separaten Unterabschnitten vor.
5.1 Vortraining von Sprachmodellen
In diesem Abschnitt berichten wir über die Bewertungsergebnisse des vortrainierten Llama 3 (Teil III) und vergleichen sie mit anderen Modellen vergleichbarer Größe. Wir werden die Ergebnisse konkurrierender Modelle so weit wie möglich reproduzieren. Für Modelle, die nicht von Llama stammen, werden wir die besten Ergebnisse aus öffentlich veröffentlichten oder (wenn möglich) von uns selbst reproduzierten Resultaten berichten. Spezifische Details dieser Auswertungen, einschließlich Konfigurationen wie Schusszahlen, Metriken und andere relevante Hyperparameter und Einstellungen, sind in unserem Github-Repository verfügbar: [Link hier einfügen]. Darüber hinaus werden wir auch Daten veröffentlichen, die im Rahmen der öffentlichen Benchmarking-Bewertungen generiert wurden, die hier zu finden sind: [Link hier einfügen].
Wir bewerten die Modellqualität anhand von Standard-Benchmarks (Abschnitt V 5.1.1), testen die Robustheit gegenüber Änderungen in Multiple-Choice-Einstellungen (Abschnitt V 5.1.2) und führen Bewertungen von Gegnern durch (Abschnitt V 5.1.3). Wir werden auch Kontaminationsanalysen durchführen, um abzuschätzen, inwieweit die Kontamination der Trainingsdaten unsere Bewertung beeinflusst (Abschnitt V 5.1.4).
5.1.1 Standard-Benchmarks
Um unser Modell mit dem aktuellen Stand der Technik zu vergleichen, haben wir Llama 3 in einer großen Anzahl von Standard-Benchmark-Tests evaluiert, die im Folgenden aufgeführt sind:
(1) gesunder Menschenverstand; (2) Wissen; (3) Leseverständnis; (4) Mathematik, logisches Denken und Problemlösung; (5) langer Kontext; (6) Code; (7) kontradiktorische Bewertung; und (8) Gesamtbewertung.

Versuchsaufbau.Für jeden Benchmark berechnen wir die Werte für Llama 3 sowie die Werte anderer vortrainierter Modelle mit vergleichbarer Größe. Wenn möglich, berechnen wir die Daten anderer Modelle mit unserer eigenen Pipeline neu. Um einen fairen Vergleich zu gewährleisten, wählen wir dann die beste Punktzahl, die wir zwischen den berechneten Daten und den von diesem Modell gemeldeten Zahlen haben (unter Verwendung der gleichen oder konservativerer Einstellungen). Nähere Informationen zu unseren Bewertungseinstellungen finden Sie hier. Für einige Modelle ist es nicht möglich, die Benchmark-Werte neu zu berechnen, z. B. aufgrund von unveröffentlichten vortrainierten Modellen oder weil die API keinen Zugang zur Log-Wahrscheinlichkeit bietet. Dies gilt insbesondere für alle mit Llama 3 405B vergleichbaren Modelle. Daher geben wir für Llama 3 405B keine Kategorie-Durchschnittswerte an, da hierfür alle Benchmarking-Zahlen verfügbar sein müssten.
Signifikanzwert.Bei der Berechnung von Benchmarking-Ergebnissen gibt es mehrere Varianzquellen, die zu ungenauen Schätzungen der Leistung des Modells führen können, das mit dem Benchmarking gemessen werden soll, z. B. eine kleine Anzahl von Demonstrationen, zufällige Seeds und Losgrößen. Dies macht es schwierig zu verstehen, ob ein Modell statistisch signifikant besser als ein anderes ist. Daher geben wir die Ergebnisse zusammen mit den 95%-Konfidenzintervallen (CIs) an, um die durch die Wahl der Benchmark-Daten verursachte Varianz zu berücksichtigen. Wir haben das 95%-Konfidenzintervall analytisch nach der Formel (Madaan et al., 2024b) berechnet:

CI_analytic(S) = 1,96 * sqrt(S * (1 - S) / N)
wobei S die bevorzugte Benchmark-Punktzahl und N der Stichprobenumfang der Benchmark ist. Wir weisen darauf hin, dass die Varianz in den Benchmark-Daten nicht die einzige Quelle der Varianz ist und dass diese 95%-KI untere Grenzen für die Varianz der tatsächlichen Kapazitätsschätzung darstellen. Für Indikatoren, die keine einfachen Durchschnittswerte sind, werden die KI weggelassen.
Ergebnisse der Modelle Llama 3 8B und 70B.Abbildung 12 zeigt die durchschnittliche Leistung von Llama 3 8B und 70B in den Tests "Common Sense Reasoning", "Knowledge", "Reading Comprehension", "Maths and Reasoning" und "Code Benchmark". Die Ergebnisse zeigen, dass Llama 3 8B die konkurrierenden Modelle in fast allen Kategorien übertrifft, sowohl in Bezug auf die Kategoriesiege als auch auf die durchschnittliche Leistung pro Kategorie. Wir stellen außerdem fest, dass Llama 3 70B die Leistung seines Vorgängers, Llama 2 70B, bei den meisten Benchmarks erheblich verbessert, mit Ausnahme der Common Sense Benchmarks, die möglicherweise gesättigt sind.Llama 3 70B übertrifft auch Mixtral 8x22B.
Ergebnisse der Modelle 8B und 70B.Abbildung 12 zeigt die durchschnittliche Leistung des Llama 3 8B und 70B in den Tests "Common Sense Reasoning", "Knowledge", "Reading Comprehension", "Maths & Reasoning" und "Code Benchmark". Die Ergebnisse zeigen, dass das Llama 3 8B die konkurrierenden Modelle in fast jeder Kategorie übertrifft, sowohl in Bezug auf die Gewinnrate pro Kategorie als auch auf die durchschnittliche Leistung pro Kategorie. Wir haben auch festgestellt, dass das Llama 3 70B in den meisten Benchmarks eine signifikante Verbesserung gegenüber seinem Vorgänger, dem Llama 2 70B, darstellt, mit Ausnahme des Common Sense Benchmarks, der möglicherweise eine Sättigung erreicht hat, und auch das Mixtral 8x22B übertrifft.
Detaillierte Ergebnisse für alle Modelle.Die Tabellen 9, 10, 11, 12, 13 und 14 zeigen die Leistung der vortrainierten Llama-3-Modelle 8B, 70B und 405B bei einer Aufgabe zum Leseverständnis, einer Codierungsaufgabe, einer Aufgabe zum Verständnis von Allgemeinwissen, einer Aufgabe zum mathematischen Denken und einer Routineaufgabe. In diesen Tabellen wird die Leistung von Llama 3 mit der von Modellen ähnlicher Größe verglichen. Die Ergebnisse zeigen, dass Llama 3 405B in seiner Kategorie konkurrenzfähig ist und insbesondere frühere Open-Source-Modelle weit übertrifft. Für Tests mit langen Kontexten liefern wir in Abschnitt 5.2 umfassendere Ergebnisse (einschließlich Erkennungsaufgaben wie needle-in-a-haystack).


5.1.2 Robustheit des Modells
Neben der Benchmarking-Leistung ist die Robustheit ein wichtiger Faktor für die Qualität von vortrainierten Sprachmodellen. Wir untersuchen die Robustheit von Designentscheidungen, die von vortrainierten Sprachmodellen in Multiple-Choice-Fragen (MCQ) getroffen werden. Frühere Studien haben gezeigt, dass die Modellleistung in solchen Situationen empfindlich auf scheinbar willkürliche Design-Entscheidungen reagieren kann, z.B. können sich die Modellwerte und sogar die Rangfolge mit der Reihenfolge und Beschriftung der Kontextbeispiele ändern (Lu et al. 2022; Zhao et al. 2021; Robinson und Wingate 2023; Liang et al. 2022; Gupta et al. 2024), das genaue Format der Aufforderungen (Weber et al., 2023b; Mishra et al., 2022) oder das Format und die Reihenfolge der Antwortmöglichkeiten (Alzahrani et al., 2024; Wang et al., 2024a; Zheng et al., 2023). In Anlehnung an diese Arbeit verwenden wir den MMLU-Benchmark, um die Robustheit des vortrainierten Modells gegenüber (1) der Verzerrung durch die Etikettierung von wenigen Schüssen, (2) Etikettierungsvarianten, (3) der Reihenfolge der Antworten und (4) dem Format der Hinweise zu bewerten:
- Einige Objektivbeschriftungen sind falsch. Nach Zheng et al. (2023), ... (experimentelle Details und Beschreibung der Ergebnisse hier weggelassen).
- Etikettenvarianten. Wir untersuchten auch die Reaktion des Modells auf verschiedene Sätze ausgewählter Token. Wir betrachteten zwei von Alzahrani et al. (2024) vorgeschlagene Tag-Sets: nämlich ein Set allgemeiner sprachunabhängiger Tags ($ & # @) und ein Set seltener Tags (oe § з ü), die keine implizite relative Reihenfolge haben. Wir betrachten auch zwei Versionen von kanonischen Tags (A. B. C. D. und A) B) C) D)) und eine Liste von Zahlen (1. 2. 3. 4.).
- Reihenfolge der Antworten. In Anlehnung an Wang et al. (2024a) berechnen wir die Stabilität der Ergebnisse unter verschiedenen Antwortreihenfolgen. Dazu ordnen wir alle Antworten im Datensatz entsprechend einer festen Permutation neu an. Zum Beispiel behalten bei der Permutation A B C D alle Antwortmöglichkeiten, die mit A und B gekennzeichnet sind, ihre Kennzeichnung, während alle Antwortmöglichkeiten, die mit C gekennzeichnet sind, die Kennzeichnung D erhalten, und umgekehrt.
- Cue-Format. Wir untersuchten die Leistungsunterschiede zwischen fünf Aufgabenhinweisen, die sich in der Menge der enthaltenen Informationen unterschieden: Ein Hinweis forderte das Modell lediglich auf, die Frage zu beantworten, während andere das Fachwissen des Modells beteuerten oder es aufforderten, die beste Antwort zu wählen.

Tabelle 11 Leistung des vortrainierten Modells bei der Aufgabe zum Verstehen von Allgemeinwissen. Die Ergebnisse enthalten 95%-Konfidenzintervalle.

Tabelle 12 Leistung der vortrainierten Modelle bei mathematischen und logischen Aufgaben. Die Ergebnisse enthalten 95%-Konfidenzintervalle. 11 Aufnahmen.

Tabelle 13 Leistung der vortrainierten Modelle bei allgemeinen Sprachaufgaben. Die Ergebnisse enthalten 95%-Konfidenzintervalle.

Abb. 13 Robustheit unseres vortrainierten Sprachmodells gegenüber verschiedenen Designentscheidungen im MMLU-Benchmarking. Linke Seite: Leistung bei verschiedenen Beschriftungsvarianten. Rechte Seite: Leistung bei Vorhandensein verschiedener Beschriftungen im Beispiel ohne Beispiel.

Abb. 14 Robustheit unseres vortrainierten Sprachmodells gegenüber verschiedenen Designentscheidungen im MMLU-Benchmarktest. Linke Seite: Leistung für verschiedene Antwortsequenzen. Rechte Seite: Leistung für verschiedene Prompt-Formate.
Abbildung 13 veranschaulicht die Ergebnisse unserer Experimente, in denen wir die Robustheit der Modellleistung bei Label-Varianten (links) und "few-shot label bias" (rechts) untersucht haben. Die Ergebnisse zeigen, dass unser vortrainiertes Sprachmodell sehr robust gegenüber MCQ-Etikettenvariationen sowie gegenüber der Struktur von "few-shot"-Etiketten ist. Diese Robustheit ist besonders deutlich für das parametrische Modell 405B.
Abbildung 14 veranschaulicht die Ergebnisse unserer Studien zur Robustheit der Antwortreihenfolge und des Cue-Formats. Diese Ergebnisse unterstreichen noch einmal die Robustheit der Leistung unserer vortrainierten Sprachmodelle, insbesondere die Robustheit von Llama 3 405B.

5.1.3 Adversarisches Benchmarking
Zusätzlich zu den oben erwähnten Benchmark-Tests haben wir mehrere gegnerische Benchmarks in drei Bereichen ausgewertet: Frage und Antwort, mathematisches Denken und Erkennung von Satzumschreibungen. Diese Tests wurden entwickelt, um die Fähigkeiten des Modells bei speziell anspruchsvollen Aufgaben zu testen und können Probleme bei der Überanpassung des Modells bei den Benchmark-Tests aufzeigen.
- Fragen und Antwortenverwendeten wir Adversarial SQuAD (Jia und Liang, 2017) und Dynabench SQuAD (Kiela et al., 2021).
- Mathematische ArgumentationWir verwendeten GSM-Plus (Li et al., 2024c).
- Testaspekte für das Umschreiben von Sätzenhaben wir PAWS (Zhang et al., 2019) verwendet.
Abbildung 15 zeigt die Ergebnisse von Llama 3 8B, 70B und 405B in den kontradiktorischen Benchmark-Tests in Abhängigkeit von ihrer Leistung in den nicht kontradiktorischen Benchmark-Tests. Die von uns verwendeten nicht-adversen Benchmark-Tests sind SQuAD für Frage und Antwort (Rajpurkar et al., 2016), GSM8K für mathematisches Denken und QQP für die Erkennung von Satzumstellungen (Wang et al., 2017). Jeder Datenpunkt steht für ein Paar aus gegnerischem und nicht-gegnerischem Datensatz (z. B. QQP gepaart mit PAWS), und wir zeigen alle möglichen Paarungen innerhalb der Kategorie. Die schwarze Linie auf der Diagonale zeigt die Parität zwischen adversen und nicht-adversen Datensätzen an - wobei die Linie anzeigt, dass das Modell unabhängig von adversen oder nicht-adversen Datensätzen eine ähnliche Leistung aufweist.
In Bezug auf die Erkennung von Satzprosodie scheinen weder die vor- noch die nachtrainierten Modelle durch die ungünstige Natur der PAWS-Konstrukte beeinträchtigt zu werden, was eine enorme Verbesserung gegenüber der vorherigen Generation von Modellen darstellt. Dieses Ergebnis bestätigt die Befunde von Weber et al. (2023a), die ebenfalls feststellten, dass große Sprachmodelle weniger empfindlich auf falsche Korrelationen in verschiedenen nachteiligen Datensätzen reagieren. Bei mathematischen Schlussfolgerungen und Fragen und Antworten ist die Leistung bei adversen Daten jedoch deutlich geringer als bei nicht-adversen Daten. Dieses Muster gilt sowohl für vor- als auch für nachtrainierte Modelle.
5.1.4 Analyse der Verschmutzung
Wir haben eine Kontaminationsanalyse durchgeführt, um abzuschätzen, inwieweit die Benchmark-Ergebnisse durch die Kontamination der Bewertungsdaten im Pre-Training-Korpus beeinflusst werden können. In einigen früheren Arbeiten wurde eine Vielzahl unterschiedlicher Kontaminationsmethoden und Hyperparameter verwendet - wir verweisen auf die Studie von Singh et al. (2024). Die Ergebnisse zeigen, dass unser vortrainiertes Sprachmodell sehr robust gegenüber Variationen in der Beschriftung von Multiple-Choice-Fragen sowie gegenüber Variationen in der Struktur von weniger stichprobenartigen Cued Labels ist (siehe 2024). Falsch-positive und falsch-negative Ergebnisse können bei jedem dieser Ansätze auftreten, und die Frage, wie Kontaminationsanalysen am besten durchgeführt werden können, ist noch ein offenes Forschungsgebiet. Hier folgen wir in erster Linie den Empfehlungen von Singh et al. (2024).


Methoden:Singh et al. (2024) schlagen insbesondere vor, eine Methode zur Erkennung von Verunreinigungen empirisch auszuwählen, die auf dem größten Unterschied zwischen dem "sauberen" Datensatz und dem gesamten Datensatz beruht, was sie als geschätzten Leistungsgewinn bezeichnen. Für alle Bewertungsdatensätze haben wir auf der Grundlage der 8-Gramm-Überlappung bewertet, die sich nach Singh et al. (2024) für viele Datensätze als genau erwiesen hat. Wir betrachten ein Beispiel des Datensatzes D als kontaminiert, wenn seine Kennzeichnung TD von denen ein Teil mindestens einmal im Pre-Training-Korpus erscheint. Wir wählen für jeden Datensatz einzeln TDje nachdem, welcher Wert den größten geschätzten Leistungsgewinn (über die drei Modellgrößen hinweg) aufweist.
Ergebnisse:Tabelle 15 zeigt den prozentualen Anteil der Bewertungsdaten für alle wichtigen Benchmarks, die für den maximalen geschätzten Leistungsgewinn, wie oben beschrieben, als kontaminiert gelten. Aus dieser Tabelle haben wir Benchmark-Daten ausgeschlossen, deren Ergebnisse nicht signifikant waren, z. B. aufgrund zu weniger sauberer oder kontaminierter Sammelproben, oder bei denen die beobachteten Schätzungen des Leistungsgewinns ein extrem erratisches Verhalten zeigten.
Aus Tabelle 15 geht hervor, dass die Kontamination bei einigen Datensätzen einen großen Einfluss hat, bei anderen hingegen nicht. Bei PiQA und HellaSwag beispielsweise sind sowohl die Kontaminationsschätzung als auch die Schätzung des Leistungsgewinns hoch. Andererseits scheint die geschätzte Kontamination von 52% bei Natürlichen Fragen fast keine Auswirkungen auf die Leistung zu haben. Bei SQuAD und MATH führen niedrige Schwellenwerte zu hohen Kontaminationswerten, aber zu keinem Leistungsgewinn. Dies deutet darauf hin, dass die Kontamination für diese Datensätze möglicherweise nicht hilfreich ist oder dass ein größeres n erforderlich ist, um bessere Schätzungen zu erhalten. Für MBPP, HumanEval, MMLU und MMLU-Pro schließlich sind möglicherweise andere Methoden zur Erkennung von Kontaminationen erforderlich: Selbst bei höheren Schwellenwerten ergibt die 8-Gramm-Überlappung so hohe Kontaminationswerte, dass keine guten Schätzungen des Leistungsgewinns erzielt werden können.
5.2 Feinabstimmung des Sprachmodells
Wir zeigen die Ergebnisse des Llama 3-Modells nach dem Training auf Benchmark-Tests mit unterschiedlichen Fähigkeiten. Ähnlich wie vor dem Training veröffentlichen wir die Daten, die im Rahmen unserer Evaluierung generiert wurden, in öffentlich zugänglichen Benchmarks, die auf Huggingface zu finden sind (Link hier einfügen). Ausführlichere Informationen zu unserem Evaluierungssetup finden Sie hier (Link hier einfügen).
Benchmarking und Indikatoren.In Tabelle 16 sind alle Vergleichstests nach Fähigkeiten geordnet zusammengefasst. Wir werden die Daten nach dem Training dekontaminieren, indem wir exakte Übereinstimmungen mit den Hinweisen in jedem Benchmark-Test herstellen. Zusätzlich zu den akademischen Standard-Benchmark-Tests haben wir auch eine umfangreiche manuelle Bewertung der verschiedenen Fähigkeiten durchgeführt. Siehe Abschnitt 5.3 für detaillierte Informationen.
Versuchsaufbau.Wir verwenden einen ähnlichen Versuchsaufbau wie in der Vorübungsphase und analysieren Llama 3 im Vergleich zu anderen Modellen mit vergleichbarer Größe und Fähigkeiten. Wenn möglich, werden wir die Leistung der anderen Modelle selbst bewerten und die Ergebnisse mit den gemeldeten Zahlen vergleichen, um das beste Ergebnis zu ermitteln. Ausführlichere Informationen über unseren Bewertungsaufbau finden Sie hier (Link hier eingefügt).

Tabelle 16 Post-Training-Benchmark-Tests nach Kategorie. Übersicht über alle Benchmark-Tests, die wir zur Bewertung des Llama-3-Modells nach dem Training verwendet haben, sortiert nach Fähigkeiten.
5.2.1 Benchmarking der allgemeinen Kenntnisse und der Einhaltung von Anweisungen
Wir haben die in Tabelle 2 aufgelisteten Benchmarks verwendet, um die Fähigkeiten von Llama 3 in Bezug auf das Allgemeinwissen und die Einhaltung der Anweisungen zu bewerten.
Allgemeinwissen: Wir verwenden MMLU (Hendrycks et al., 2021a) und MMLU-Pro (Wang et al., 2024b), um die Leistung von Llama 3 bei wissensbasierten Fragestellungen zu bewerten. MMLU-Pro ist eine erweiterte Version von MMLU, die anspruchsvollere, auf Schlussfolgerungen ausgerichtete Fragen enthält, verrauschte Fragen eliminiert und die Auswahlmöglichkeiten von vier auf zehn Optionen erweitert. Da der Schwerpunkt auf komplexem Schlussfolgern liegt, berichten wir über fünf Beispiel-CoTs für MMLU-Pro. Alle Aufgaben sind als generative Aufgaben formatiert, ähnlich wie simple-evals (OpenAI, 2024).
Wie aus Tabelle 2 hervorgeht, übertreffen unsere 8B- und 70B-Llama-3-Varianten andere Modelle ähnlicher Größe bei beiden Allgemeinwissensaufgaben. Unser 405B-Modell übertrifft GPT-4 und Nemotron 4 340B, und Claude 3.5 Sonnet führt bei den größeren Modellen.
Anweisungen zum Befolgen: Wir verwenden IFEval (Zhou et al., 2023), um die Fähigkeit von Llama 3 und anderen Modellen zu bewerten, natürlichsprachliche Anweisungen zu befolgen. IFEval besteht aus etwa 500 "überprüfbaren Anweisungen", wie z. B. "schreibe mehr als 400 Wörter", die mithilfe von Heuristiken überprüft werden können. IFEval besteht aus etwa 500 "überprüfbaren Anweisungen" wie z. B. "schreibe mehr als 400 Wörter", die mit Hilfe von Heuristiken überprüft werden können. In Tabelle 2 sind die durchschnittlichen Genauigkeiten auf Prompt- und Instruktionsebene unter strengen und lockeren Bedingungen angegeben. Man beachte, dass alle Llama 3-Varianten die vergleichbaren Modelle bei IFEval übertreffen.
5.2.2 Befähigungsprüfungen
Als Nächstes evaluieren wir unser Modell anhand einer Reihe von Eignungstests, die ursprünglich für die Prüfung von Menschen konzipiert wurden. Wir beziehen diese Prüfungen aus öffentlich zugänglichen offiziellen Quellen; für einige Prüfungen geben wir als Ergebnis jedes Eignungstests die durchschnittliche Punktzahl über die verschiedenen Prüfungsreihen hinweg an. Genauer gesagt, wir bilden den Durchschnitt:
- GRE: Die offiziellen GRE-Übungstests 1 und 2, die vom Educational Testing Service angeboten werden;
- LSAT: Offizieller Vortest 71, 73, 80 und 93;
- SAT: 8 Prüfungen aus The Official SAT Study Guide, 2018 Edition;
- AP: eine offizielle Übungsprüfung pro Fach;
- GMAT: Der offizielle GMAT-Online-Test.
Die Fragen in diesen Prüfungen enthalten Multiple-Choice- und generative Fragen. Wir schließen alle Fragen mit angehängten Bildern aus. Bei GRE-Fragen, die mehrere richtige Optionen enthalten, stufen wir die Ausgabe nur dann als richtig ein, wenn das Modell alle richtigen Optionen auswählt. In Fällen, in denen es mehr als ein Prüfungsset gibt, verwenden wir eine kleine Anzahl von Hinweisen für die Auswertung. Wir passen die Punktzahlen an den Bereich 130-170 (für GRE) an und geben die Genauigkeit für alle anderen Prüfungen an.

Unsere Ergebnisse sind in Tabelle 17 dargestellt. Wir stellen fest, dass unser Llama 3 405B Modell ähnlich gut abschneidet wie das Claude Der 3,5 Sonnet ist dem GPT-4 4o sehr ähnlich. Unser 70B-Modell hingegen zeigt eine noch beeindruckendere Leistung. Es ist deutlich besser als das GPT-3.5 Turbo und übertrifft das Nemotron 4 340B in vielen Tests.
5.2.3 Codierungs-Benchmarks
Wir evaluieren die Codegenerierungsfähigkeiten von Llama 3 anhand mehrerer beliebter Python- und mehrsprachiger Programmierbenchmarks. Um die Effektivität des Modells bei der Generierung von funktional korrektem Code zu messen, verwenden wir die pass@N-Metrik, die die Bestehensrate von Unit-Tests für einen Satz von N Generationen bewertet. Wir berichten die Ergebnisse für pass@1.


Generierung von Python-Code. HumanEval (Chen et al., 2021) und MBPP (Austin et al., 2021) sind beliebte Python-Benchmarks für die Codegenerierung, die sich auf relativ einfache, in sich geschlossene Funktionen konzentrieren.HumanEval+ (Liu et al., 2024a) ist eine verbesserte Version von HumanEval, bei der mehr Testfälle generiert werden, um falsch positive Ergebnisse zu vermeiden. Die MBPP-EvalPlus-Benchmark-Version (v0.2.0) ist eine Auswahl von 378 gut formatierten Fragen (Liu et al., 2024a) aus 974 ursprünglichen Fragen im ursprünglichen MBPP-Datensatz (Training und Test). Die Ergebnisse dieser Benchmark-Tests sind in Tabelle 18 dargestellt. Beim Benchmarking dieser Python-Varianten schnitten Llama 3 8B und 70B besser ab als Modelle derselben Größe, die ähnlich gut abschnitten. Bei den größten Modellen schneiden Llama 3 405B, Claude 3.5 Sonnet und GPT-4o ähnlich gut ab, wobei GPT-4o die besten Ergebnisse erzielt.
Modelle. Wir haben das Llama 3 mit anderen Modellen ähnlicher Größe verglichen. Bei dem größten Modell, Llama 3 405B, schneiden Claude 3.5 Sonnet und GPT-4o ähnlich ab, wobei GPT-4o die besten Ergebnisse erzielt.
Generierung von Code in mehreren Programmiersprachen: Um die Codegenerierungsfähigkeiten anderer Sprachen als Python zu bewerten, berichten wir die Ergebnisse des MultiPL-E (Cassano et al., 2023) Benchmarks, der auf Übersetzungen von HumanEval- und MBPP-Fragen basiert. Tabelle 19 zeigt die Ergebnisse für eine Auswahl an populären Programmiersprachen.
Es ist zu beachten, dass es im Vergleich zum Python-Pendant in Tabelle 18 zu einem deutlichen Leistungsabfall kommt.
5.2.4 Mehrsprachiges Benchmarking
Llama 3 unterstützt 8 Sprachen - Englisch, Deutsch, Französisch, Italienisch, Portugiesisch, Hindi, Spanisch und Thailändisch - obwohl das Basismodell mit einer größeren Anzahl von Sprachen trainiert wurde. In Tabelle 20 sind die Ergebnisse unserer Evaluierung von Llama 3 für die Benchmarks Multilingual MMLU (Hendrycks et al., 2021a) und Multilingual Primary Mathematics (MGSM) (Shi et al., 2022) dargestellt.
- Mehrsprachige MMLUWir haben Google Translate verwendet, um die MMLU-Fragen, Kurzbeispiele und Antworten in verschiedene Sprachen zu übersetzen. Wir haben die Aufgabenbeschreibungen auf Englisch belassen und sie in einer 5-Schuss-Einstellung bewertet.
- MGSM (Shi et al., 2022)Für unser Llama 3 Modell berichten wir 0-shot CoT Ergebnisse für MGSM. Multilingual MMLU ist ein interner Benchmark, der die Übersetzung von MMLU-Fragen und -Antworten (Hendrycks et al., 2021a) in 7 Sprachen beinhaltet - die 5-Shot-Ergebnisse, die wir berichten, sind ein Durchschnittswert über diese Sprachen.
Für MGSM (Shi et al., 2022) testeten wir unser Modell mit denselben muttersprachlichen Prompts wie in simple-evals (OpenAI, 2024) und platzierten es in einer 0-Shot CoT-Umgebung. In Tabelle 20 sind die durchschnittlichen Ergebnisse für alle im MGSM-Benchmark enthaltenen Sprachen aufgeführt.

Wir stellen fest, dass Llama 3 405B die meisten anderen Modelle beim MGSM übertrifft, mit einer durchschnittlichen Punktzahl von 91,61TP3 T. Beim MMLU liegt Llama 3 405B in Übereinstimmung mit den obigen englischen MMLU-Ergebnissen 21TP3 T hinter GPT-4o. Andererseits übertreffen sowohl die 70B- als auch die 8B-Modelle von Llama 3 die Konkurrenten und führen die Konkurrenz bei beiden Aufgaben mit großem Abstand an. bei beiden Aufgaben.
5.2.5 Mathematische und logische Benchmarks
Die Ergebnisse unserer mathematischen und Inferenz-Benchmarks sind in Tabelle 2 dargestellt: Das 8B-Modell von Llama 3 übertrifft andere Modelle der gleichen Größe bei GSM8K, MATH und GPQA. Unser 70B-Modell zeigt in allen Benchmark-Tests eine deutlich bessere Leistung als seine Gegenstücke. Schließlich ist das Modell Llama 3 405B das beste Modell in seiner Kategorie für GSM8K und ARC-C, während es bei MATH das zweitbeste Modell ist. Bei GPQA konkurriert es gut mit GPT-4 4o, während Claude 3.5 Sonnet die Liste mit deutlichem Abstand anführt.
5.2.6 Benchmarking im langen Kontext
Wir betrachten eine Reihe von Aufgaben aus verschiedenen Bereichen und Textsorten. In den nachstehenden Benchmarks konzentrieren wir uns auf Teilaufgaben, die ein unvoreingenommenes Bewertungsprotokoll verwenden, d. h. auf Genauigkeit basierende Metriken und nicht auf n-Gramm-Überschneidungsmetriken. Außerdem priorisieren wir die Aufgaben, bei denen eine geringere Varianz festgestellt wird.
- Die Nadel im Heuhaufen (Kamradt, 2023) Messen Sie die Fähigkeit des Modells, Informationen zu finden, die in zufälligen Teilen langer Dokumente versteckt sind. Unser Llama 3-Modell zeigt eine perfekte Leistung beim Abrufen von Nadeln, indem es 100% "Nadeln" in allen Dokumenttiefen und Kontextlängen erfolgreich abruft. Wir haben auch die Leistung von Multi-Nadel (Tabelle 21) gemessen, einer Variante von Needle-in-a-Haystack, bei der wir vier "Nadeln" in den Kontext eingefügt haben und getestet haben, ob das Modell zwei davon finden kann. Unser Llama-3-Modell erzielt nahezu perfekte Ergebnisse.
- ZeroSCROLLS (Shaham et al., 2023)ist ein Null-Stichproben-Benchmark-Test für das Verstehen von Langtexten in natürlicher Sprache. Da die wahren Antworten nicht öffentlich zugänglich sind, geben wir die Zahlen der Validierungsmenge an. Unsere Modelle Llama 3 405B und 70B sind den anderen Modellen bei einer Vielzahl von Aufgaben in diesem Benchmark-Test ebenbürtig oder überlegen.
- InfiniteBench (Zhang et al., 2024) Modelle sind erforderlich, um weitreichende Abhängigkeiten in Kontextfenstern zu verstehen. Wir evaluieren Llama 3 auf En.QA (Quiz zu Romanen) und En.MC (Multiple-Choice-Quiz zu Romanen), wo unser 405B-Modell alle anderen Modelle übertrifft. Der Gewinn ist besonders signifikant bei En.QA.

Tabelle 21 Langtext-Benchmarking. Für ZeroSCROLLS (Shaham et al., 2023) berichten wir die Ergebnisse für die Validierungsmenge. Für QuALITY berichten wir exakte Übereinstimmungen, für Qasper - f1, und für SQuALITY - rougeL. Wir berichten f1 für die InfiniteBench (Zhang et al., 2024) En.QA-Metriken und Genauigkeit für En.MC. Für Multi-Nadel (Kamradt, 2023) fügen wir 4 Nadeln in den Kontext ein und testen, ob das Modell in der Lage ist, 2 Nadeln mit unterschiedlichen Kontextlängen abzurufen, und wir berechnen den durchschnittlichen Recall für bis zu 128k von 10 Sequenzlängen.
5.2.7 Leistung der Werkzeuge
Wir haben unser Modell anhand einer Reihe von Nullproben-Benchmarks für die Werkzeugnutzung (d. h. Funktionsaufrufe) bewertet: Nexus (Srinivasan et al., 2023), API-Bank (Li et al., 2023b), Gorilla API-Bench (Patil et al., 2023) und Berkeley Function Call Leaderboard ( BFCL) (Yan et al., 2024). Die Ergebnisse sind in Tabelle 22 aufgeführt.
Bei Nexus schneidet unsere Llama-3-Variante am besten ab und übertrifft die anderen Modelle in ihrer Kategorie. Bei API-Bank übertreffen unsere Modelle Llama 3 8B und 70B die anderen Modelle in ihren jeweiligen Kategorien deutlich. Das Modell 405B liegt nur hinter Claude 3.5 Sonnet 0.6%. Schließlich schneiden unsere Modelle 405B und 70B bei BFCL am besten ab und belegen den zweiten Platz in ihrer jeweiligen Größenkategorie. Das Llama 3 8B war das beste Modell in seiner Kategorie.
Wir führten auch eine manuelle Bewertung durch, um die Fähigkeit des Modells zur Nutzung des Tools zu testen, wobei wir uns auf Aufgaben zur Codeausführung konzentrierten. Wir sammelten 2000 Benutzeraufforderungen, Zeichnungserstellung und Datei-Uploads im Zusammenhang mit der Codeausführung (ohne Zeichnungs- oder Datei-Uploads). Diese Eingabeaufforderungen stammen von LMSys Datensatz (Chiang et al., 2024), GAIA-Benchmarks (Mialon et al., 2023b), menschliche Annotatoren und synthetische Erzeugung. Wir verglichen Llama 3 405B mit GPT-4o unter Verwendung der Assistenten-API10 von OpenAI. Die Ergebnisse sind in Abbildung 16 dargestellt. Llama 3 405B übertrifft GPT-4o deutlich bei der Ausführung von reinem Textcode und bei der Zeichnungsgenerierung, bleibt aber im Anwendungsfall des Dateiuploads hinter GPT-4o zurück.

5.3 Manuelle Bewertung
Zusätzlich zu den Bewertungen des Standard-Benchmark-Datensatzes haben wir eine Reihe von menschlichen Bewertungen durchgeführt. Diese Bewertungen ermöglichen es uns, subtilere Aspekte der Modellleistung zu messen und zu optimieren, z. B. den Ton des Modells, den Grad der Redundanz und das Verständnis von Nuancen und kulturellem Kontext. Sorgfältig konzipierte rengren-Evaluierungen stehen in engem Zusammenhang mit der Benutzererfahrung und geben Aufschluss darüber, wie das Modell in der realen Welt funktioniert.
https://platform.openai.com/docs/assistants/overview
Bei den menschlichen Bewertungen über mehrere Runden lag die Anzahl der Runden für jeden Hinweis zwischen 2 und 11. Wir bewerteten die Reaktion des Modells in der letzten Runde.
Tipp-Sammlung. Wir haben qualitativ hochwertige Aufforderungen gesammelt, die ein breites Spektrum an Kategorien und Schwierigkeiten abdecken. Zu diesem Zweck entwickelten wir zunächst eine Taxonomie mit Kategorien und Unterkategorien für möglichst viele Modellfähigkeiten. Auf der Grundlage dieser Taxonomie sammelten wir ca. 7.000 Prompts für sechs Ein-Runden-Fähigkeiten (Englisch, Reasoning, Coding, Hindi, Spanisch und Portugiesisch) und drei Mehr-Runden-Fähigkeiten11 (Englisch, Reasoning und Coding). Wir stellten sicher, dass innerhalb jeder Kategorie die Prompts gleichmäßig auf die Unterkategorien verteilt waren. Außerdem haben wir jeden Prompt in einen von drei Schwierigkeitsgraden eingeteilt und sichergestellt, dass unser Satz von Prompts etwa 10% leichte, 30% mittelschwere und 60% schwierige Prompts enthält. Alle menschlichen Bewertungen Abbildung 16 Menschliche Bewertungsergebnisse für Llama 3 405B vs. GPT-4o bei Codeausführungsaufgaben einschließlich Zeichnen und Hochladen von Dateien. Das Llama 3 405B übertrifft das GPT-4o bei der Codeausführung (ohne Zeichnen und Hochladen von Dateien) sowie bei der Erstellung von Plots, liegt aber beim Hochladen von Dateien zurück.
Die Cue-Sets wurden einem strengen Qualitätssicherungsprozess unterzogen. Das Modellierungsteam hat keinen Zugang zu unseren menschlichen Bewertungsstichwörtern, um eine versehentliche Verunreinigung oder Überanpassung des Testsatzes zu verhindern.
Bewertungsprozess. Um gepaarte menschliche Bewertungen der beiden Modelle durchzuführen, fragen wir menschliche Kommentatoren, welche der beiden Modellantworten (die von verschiedenen Modellen erzeugt wurden) sie bevorzugen. Die Kommentatoren verwenden eine 7-Punkte-Skala, auf der sie angeben können, ob eine Modellantwort viel besser, besser, etwas besser oder ungefähr gleich gut ist wie die andere. Wenn die Kommentatoren angeben, dass eine Modellantwort viel besser oder besser ist als die Antwort eines anderen Modells, betrachten wir dies als einen "Sieg" für dieses Modell. Wir werden die Modelle paarweise vergleichen und die Gewinnrate für jede Fähigkeit im Cue-Set angeben.
am Ende. Wir haben das Llama 3 405B mit dem GPT-4 (0125 API-Version), dem GPT-4o (API-Version) und dem Claude 3.5 Sonnet (API-Version) anhand eines menschlichen Bewertungsverfahrens verglichen. Die Ergebnisse dieser Bewertungen sind in Abbildung 17 dargestellt. Wir stellen fest, dass Llama 3 405B in etwa vergleichbar mit der 0125 API-Version von GPT-4 abschneidet, mit gemischten Ergebnissen (einige Gewinne und einige Verluste) im Vergleich zu GPT-4o und Claude 3.5 Sonnet. Bei fast allen Fähigkeiten gewinnen Llama 3 und GPT-4 innerhalb der Fehlermarge. Das Llama 3 405B übertrifft das GPT-4 bei den Mehrrunden-Aufgaben zum schlussfolgernden Denken und zum Kodieren, aber nicht bei den mehrsprachigen (Hindi, Spanisch und Portugiesisch) Aufforderungen. Das Llama 3 schneidet bei den englischen Aufforderungen genauso gut ab wie das GPT-4, ebenso wie das Claude 3.5 Sonnet bei den mehrsprachigen Aufforderungen und übertrifft sowohl die englischen Aufforderungen in einer Runde als auch in mehreren Runden. Qualitativ haben wir festgestellt, dass die Leistung des Modells in der menschlichen Bewertung stark von subtilen Faktoren wie Tonfall, Antwortstruktur und Redundanzgrad beeinflusst wird - alles Faktoren, die wir im Nachtrainingsverfahren optimieren. Faktoren, die optimiert werden. Insgesamt stimmen die Ergebnisse unserer menschlichen Bewertung mit denen der Standard-Benchmark-Evaluierungen überein: Das Llama 3 405B konkurriert sehr gut mit führenden Industriemodellen und ist damit das leistungsstärkste öffentlich verfügbare Modell.
Einschränkungen. Alle menschlichen Bewertungsergebnisse wurden einem strengen Verfahren zur Sicherung der Datenqualität unterzogen. Da es jedoch schwierig ist, objektive Kriterien für die Reaktion des Modells zu definieren, können die menschlichen Bewertungen immer noch von den persönlichen Vorlieben, Hintergründen und Präferenzen der menschlichen Kommentatoren beeinflusst werden, was zu uneinheitlichen oder unzuverlässigen Ergebnissen führen kann.

Abbildung 16 Ergebnisse der menschlichen Bewertung von Llama 3 405B und GPT-4o bei der Codeausführung (einschließlich Plotten und Datei-Upload). Das Llama 3 405B übertrifft das GPT-4o bei der Codeausführung (ohne Plotten und Datei-Upload) und bei der Plot-Erstellung, liegt aber beim Anwendungsfall Datei-Upload zurück.

Abb. 17 Ergebnisse der manuellen Bewertung des Modells Llama 3 405B. Links: Vergleich mit GPT-4. Mitte: Vergleich mit GPT-4o. Rechts: Vergleich mit Claude 3.5 Sonnet. Alle Ergebnisse enthalten 95%-Konfidenzintervalle und schließen Gleichstände aus.
5.4 Sicherheit
Der Sicherheitsteil enthält sensible Wörter, die übersprungen oder als PDF heruntergeladen werden können, vielen Dank!
6 Schlussfolgerung
Wir untersuchen zwei Haupttechniken zur Verbesserung der Inferenz-Effizienz des Llama 3 405B-Modells: (1) Pipeline-Parallelität und (2) FP8-Quantisierung. Wir haben eine Implementierung der FP8-Quantisierung öffentlich zugänglich gemacht.
6.1 Pipeline-Parallelität
Das Modell Llama 3 405B passt nicht in den GPU-Speicher einer einzelnen Maschine mit 8 Nvidia H100 GPUs, wenn BF16 zur Darstellung der Modellparameter verwendet wird. Um dieses Problem zu lösen, verwendeten wir die BF16-Präzision zur Parallelisierung der Modellinferenz auf 16 GPUs auf zwei Rechnern. Innerhalb jeder Maschine ermöglicht NVLink mit hoher Bandbreite die Nutzung von Tensor-Parallelität (Shoeybi et al., 2019). Knotenübergreifende Verbindungen haben jedoch eine geringere Bandbreite und eine höhere Latenz, weshalb wir Pipeline-Parallelität verwenden (Huang et al., 2019).
Blasen sind ein großes Effizienzproblem beim Training mit Pipeline-Parallelität (siehe Abschnitt 3.3). Bei der Inferenz stellen sie jedoch kein Problem dar, da die Inferenz keine Backpropagation beinhaltet, die eine Pipeline-Spülung erfordert. Daher verwenden wir Micro-Batching, um den Durchsatz der pipeline-parallelen Inferenz zu verbessern.
Wir evaluieren die Auswirkungen der Verwendung von zwei Mikrostapeln in einer Inferenz-Arbeitslast von 4.096 Eingabe-Token und 256 Ausgabe-Token für die Vorbelegungsphase des Key-Value-Cache bzw. die Dekodierungsphase der Inferenz. Wir stellen fest, dass Micro-Batching den Inferenzdurchsatz bei gleicher lokaler Batch-Größe verbessert (siehe Abbildung 24), da Micro-Batching die gleichzeitige Ausführung von Micro-Batches in beiden Phasen ermöglicht. Da das Micro-Batching zu zusätzlichen Synchronisationspunkten führt, erhöht sich auch die Latenzzeit, aber insgesamt führt das Micro-Batching immer noch zu einem besseren Kompromiss zwischen Durchsatz und Latenz.


6.2 RP8 Quantifizierung
Wir führten Experimente zur Inferenz mit geringer Genauigkeit durch, indem wir die FP8-Unterstützung der H100 GPU nutzten. Um eine Inferenz mit geringer Genauigkeit zu erreichen, haben wir FP8-Quantisierung auf die meisten Matrixmultiplikationen innerhalb des Modells angewendet. Insbesondere haben wir die überwiegende Mehrheit der Parameter und Aktivierungswerte in den Feedforward-Netzschichten des Modells quantisiert, die etwa 50% der Berechnungszeit für die Inferenz ausmachen, während wir die Parameter in der Selbstaufmerksamkeitsschicht des Modells nicht quantisiert haben. Wir verwenden einen dynamischen Skalierungsfaktor, um die Genauigkeit zu verbessern (Xiao et al., 2024b), und optimieren unseren CUDA-Kernel15 , um den Rechenaufwand für die Skalierung zu verringern.
Wir stellten fest, dass die Qualität von Llama 3 405B auf bestimmte Arten der Quantifizierung empfindlich reagierte, und nahmen einige zusätzliche Änderungen vor, um die Qualität der Modellausgabe zu verbessern:
- Ähnlich wie Zhang et al. (2021) haben wir die erste und letzte Transformer-Schicht nicht quantifiziert.
- Stark ausgerichtete Token (z. B. Datumsangaben) können zu großen Aktivierungswerten führen. Dies wiederum kann zu höheren dynamischen Skalierungsfaktoren in FP8 und einem nicht zu vernachlässigenden Betrag an Fließkomma-Unterlauf führen, was wiederum Dekodierungsfehler zur Folge hat. Abbildung 26 zeigt die Verteilung der Reward-Scores für Llama 3 405B unter Verwendung von BF16- und FP8-Inferenz. Unsere FP8-Quantifizierungsmethode hat kaum Auswirkungen auf die Modellreaktion.
Um dieses Problem zu lösen, setzen wir die Obergrenze des dynamischen Skalierungsfaktors auf 1200.
- Wir verwendeten die zeilenweise Quantisierung, um die Skalierungsfaktoren für die Parameter- und Aktivierungsmatrizen zeilenübergreifend zu berechnen (siehe Abbildung 25). Diese Methode funktionierte besser als die Quantisierung auf Tensorebene.
die Auswirkungen von Fehlern zu quantifizieren. Auswertungen von Standard-Benchmarks zeigen in der Regel, dass FP8-Schlussfolgerungen auch ohne diese Abschwächungen vergleichbare Leistungen wie BF16-Schlussfolgerungen erbringen. Wir stellen jedoch fest, dass solche Benchmarks die Auswirkungen der FP8-Quantifizierung nicht angemessen widerspiegeln. Wenn der Skalierungsfaktor nicht gekappt wird, produziert das Modell gelegentlich fehlerhafte Antworten, selbst wenn die Benchmark-Leistung stark ist.
Anstatt sich auf Benchmarks zu verlassen, um Veränderungen in der Verteilung aufgrund der Quantifizierung zu messen, ist es möglich, die Verteilung der Belohnungsmodell-Scores für die 100.000 Antworten, die mit BF16 und FP8 generiert wurden, zu analysieren. Abbildung 26 zeigt die Verteilung der Rewards, die durch unsere Quantifizierungsmethode erhalten wurden. Die Ergebnisse zeigen, dass unsere FP8-Quantifizierungsmethode nur einen sehr geringen Einfluss auf die Modellantworten hat.
experimentelle Bewertung der Effizienz. Abbildung 27 zeigt den Kompromiss zwischen Durchsatz und Latenz für die Durchführung der FP8-Inferenz in der Vorpopulations- und Dekodierungsphase unter Verwendung von 4.096 Eingabe-Token und 256 Ausgabe-Token mit dem Llama 3 405B. Die Abbildung vergleicht die Effizienz der FP8-Inferenz mit dem in Abschnitt 6.1 beschriebenen BF16-Inferenzansatz mit zwei Maschinen. Die Ergebnisse zeigen, dass die Verwendung von FP8-Inferenz den Durchsatz in der Vorpopulationsphase um bis zu 50% verbessert und den Kompromiss zwischen Durchsatz und Verzögerung während der Dekodierung erheblich verbessert.



7 Visuelle Experimente
Wir haben eine Reihe von Experimenten durchgeführt, um visuelle Erkennungsfunktionen in Llama 3 durch einen kombinierten Ansatz zu integrieren. Der Ansatz ist in zwei Hauptphasen unterteilt:
Erste Etappe. Wir kombinierten einen vortrainierten Bildkodierer (Xu et al., 2023) mit einem vortrainierten Sprachmodell und führten eine Reihe von Cross-Attention-Schichten (Alayrac et al., 2022) ein und trainierten sie an einer großen Anzahl von Bild-Text-Paaren. Das Ergebnis ist das in Abbildung 28 dargestellte Modell.
Zweite Etappe. Wir führen eine zeitliche Aggregationsschicht und zusätzliche Video-Cross-Attention-Schichten ein, die auf eine große Anzahl von Videotextpaaren einwirken, um das Modell zur Erkennung und Verarbeitung zeitlicher Informationen aus Videos zu erlernen.
Der kombinatorische Ansatz zur Erstellung des Basismodells hat mehrere Vorteile.
(1) Sie ermöglicht es uns, visuelle und sprachliche Modellierungsmerkmale parallel zu entwickeln;
(2) Es vermeidet die Komplexität, die mit dem gemeinsamen Vortraining von visuellen und verbalen Daten verbunden ist und die sich aus der Tokenisierung von visuellen Daten, den Unterschieden in der Hintergrund-Perplexität zwischen den Modalitäten und dem Wettbewerb zwischen den Modalitäten ergibt;
(3) Es wird sichergestellt, dass die Einführung von visuellen Erkennungsfunktionen die Leistung des Modells bei reinen Textaufgaben nicht beeinträchtigt;
(4) Die Cross-Attention-Architektur stellt sicher, dass wir keine Bilder in voller Auflösung an das ständig wachsende LLM-Backbone (insbesondere das Feed-Forward-Netzwerk in jeder Transformer-Schicht) weiterleiten müssen, was die Inferenz-Effizienz verbessert.
Bitte beachten Sie, dass sich unser multimodales Modell noch in der Entwicklung befindet und noch nicht zur Veröffentlichung bereit ist.
Bevor wir die experimentellen Ergebnisse in den Abschnitten 7.6 und 7.7 vorstellen, beschreiben wir die Daten, die zum Training der visuellen Erkennungsfähigkeiten verwendet wurden, die Modellarchitektur der visuellen Komponenten, wie wir das Training dieser Komponenten erweitert haben und unsere Rezepte für das Vor- und Nachtraining.
7.1 Daten
Wir beschreiben Bild- und Videodaten getrennt.
7.1.1 Bilddaten
Unsere Bildkodierer und -adapter werden auf Bild-Text-Paaren trainiert. Wir erstellen diesen Datensatz durch eine komplexe Datenverarbeitungspipeline, die aus vier Hauptstufen besteht:
(1) Qualitätsfilterung (2) Wahrnehmungsdeemphasis (3) Resampling (4) Optische Zeichenerkennung . Wir haben auch eine Reihe von Sicherheitsmaßnahmen ergriffen.
- Massenfiltration. Wir haben Qualitätsfilter implementiert, um nicht-englische Bildunterschriften und minderwertige Bildunterschriften durch Heuristiken wie die niedrigen Alignment-Scores von (Radford et al., 2021) zu entfernen. Konkret entfernen wir alle Bild-Text-Paare, die unter einen bestimmten CLIP-Score fallen.
- Betonung abbauen. Die Deduplizierung großer Trainingsdatensätze verbessert die Modellleistung, da sie die Trainingsberechnungen für redundante Daten reduziert (Esser et al. 2024; Lee et al. 2021; Abbas et al. 2023) und das Risiko der Modellspeicherung verringert (Carlini et al. 2023; Somepalli et al. 2023). Aus Gründen der Effizienz und des Datenschutzes werden die Trainingsdaten daher de-dupliziert. Zu diesem Zweck verwenden wir die neueste hauseigene Version des SSCD-Kopiererkennungsmodells (Pizzi et al., 2022), um die Bilder massiv zu de-duplizieren. Für alle Bilder berechnen wir zunächst eine 512-dimensionale Darstellung mit dem SSCD-Modell. Anschließend verwenden wir diese Einbettungen, um mit Hilfe einer Kosinus-Ähnlichkeitsmetrik eine Suche nach dem nächsten Nachbarn (NN) für alle Bilder des Datensatzes durchzuführen. Wir definieren Beispiele oberhalb eines bestimmten Ähnlichkeitsschwellenwerts als doppelte Begriffe. Wir gruppieren diese doppelten Begriffe mithilfe eines Algorithmus für zusammenhängende Komponenten und behalten nur ein einziges Bild-Text-Paar für jede zusammenhängende Komponente. Wir verbessern die Effizienz der Deduplizierungspipeline, indem wir (1) die Daten mithilfe von K-Mittelwert-Clustering vorclustern und (2) FAISS für die NN-Suche und das Clustering verwenden (Johnson et al., 2019).
- Neuabtastung. Wir stellen die Vielfalt der Bild-Text-Paare sicher, ähnlich wie Xu et al. (2023); Mahajan et al. (2018); Mikolov et al. (2013). Zunächst erstellen wir ein grammatikalisches n-Tupel-Glossar, indem wir hochwertige Textquellen parsen. Anschließend berechnen wir die Häufigkeit von n-Tupel-Grammatiken für jedes Glossar im Datensatz. Anschließend werden die Daten wie folgt neu ausgewählt: Wenn eine n-Tupel-Grammatik in einer Bildunterschrift weniger als T Mal im Glossar vorkommt, behalten wir das entsprechende Bild-Text-Paar bei. Andernfalls haben wir jede n-Tupel-Grammatik n i in der Überschrift mit der Wahrscheinlichkeit T / f i unabhängig voneinander abgetastet, wobei f i die Häufigkeit der n-Tupel-Grammatik n i bezeichnet; wenn eine n-Tupel-Grammatik abgetastet wurde, haben wir das Bild-Text-Paar behalten. Dieses Resampling trägt dazu bei, die Leistung von niederfrequenten Kategorien und feinkörnigen Erkennungsaufgaben zu verbessern.
- Optische Zeichenerkennung. Wir haben unsere Bildtextdaten weiter verbessert, indem wir den Text im Bild extrahiert und mit einer Bildunterschrift verknüpft haben. Der geschriebene Text wurde mithilfe einer proprietären OCR-Pipeline (Optical Character Recognition) extrahiert. Wir haben festgestellt, dass das Hinzufügen von OCR-Daten zu den Trainingsdaten die Leistung von Aufgaben, die OCR-Fähigkeiten erfordern, wie z. B. das Verstehen von Dokumenten, erheblich verbessern kann.
Um die Leistung des Modells beim Verstehen von Dokumenten zu verbessern, werden die Dokumentseiten als Bilder dargestellt und die Bilder mit dem entsprechenden Text verknüpft. Der Dokumententext wird entweder direkt aus der Quelle oder durch eine Dokumenten-Parsing-Pipeline gewonnen.
Sicherheit: Unser Hauptaugenmerk liegt darauf, sicherzustellen, dass die Trainingsdatensätze für die Bilderkennung keine unsicheren Inhalte, wie z. B. sexuell anstößiges Material (CSAM), enthalten (Thiel, 2023). Wir verwenden perzeptive Hashing-Methoden wie PhotoDNA (Farid, 2021) sowie firmeneigene Klassifikatoren, um alle Trainingsbilder auf CSAM zu scannen. Außerdem verwenden wir eine firmeneigene Pipeline zum Abrufen von Medienrisiken, um Bild-Text-Paare zu identifizieren und zu entfernen, die wir als NSFW betrachten, z. B. weil sie sexuelle oder gewalttätige Inhalte enthalten. Wir glauben, dass die Minimierung der Prävalenz solchen Materials im Trainingsdatensatz die Sicherheit und Nützlichkeit des endgültigen Modells verbessert, ohne seine Nützlichkeit zu beeinträchtigen. Schließlich führen wir bei allen Bildern des Trainingssatzes eine Gesichtsunschärfe durch. Wir haben das Modell anhand von menschlich erzeugten Hinweisen getestet, die sich auf zusätzliche Bilder beziehen.
Glühende Daten: Wir haben einen geglätteten Datensatz mit ca. 350 Millionen Beispielen erstellt, indem wir Bildunterschriftenpaare mit n-Grammen resamplen. Da n-Gramm-Resampling reichhaltigere Textbeschreibungen begünstigt, wird eine qualitativ hochwertigere Teilmenge der Daten ausgewählt. Außerdem haben wir die resultierenden Daten mit etwa 150 Millionen Beispielen aus fünf weiteren Quellen ergänzt:
-
- Visuelle Orientierung. Wir assoziieren Substantivphrasen im Text mit Begrenzungsrahmen oder Masken im Bild. Die Lokalisierungsinformationen (Begrenzungsrahmen und Masken) werden in den Bild-Text-Paaren auf zwei Arten angegeben:(1) Wir überlagern die Rahmen oder Masken auf dem Bild und verwenden Markierungen als Referenzen im Text, ähnlich wie bei einem Markerset (Yang et al., 2023a). (2) Wir fügen die normalisierten Koordinaten (x min, y min, x max, y max) direkt in den Text ein und trennen sie durch spezielle Marker.
- Screenshot-Analyse. Wir rendern Screenshots aus HTML-Code und lassen das Modell den Code vorhersagen, der bestimmte Screenshot-Elemente erzeugt, ähnlich wie Lee et al. (2023). Elemente von Interesse werden im Screenshot durch Begrenzungsrahmen angezeigt.
- Q&A mit. Wir beziehen Q&A-Paare ein, die es uns ermöglichen, große Mengen an Q&A-Daten zu verwenden, die zu groß sind, um sie für die Modellfeinabstimmung zu nutzen.
- Synthetischer Titel. Wir haben Bilder mit synthetischen Beschriftungen aufgenommen, die aus früheren Modellversionen generiert wurden. Im Vergleich zu den Originalbeschriftungen haben wir festgestellt, dass die synthetischen Beschriftungen eine umfassendere Beschreibung des Bildes liefern als die Originalbeschriftungen.
- Synthese von strukturierten Bildern. Wir bieten auch synthetisch erzeugte Bilder für verschiedene Bereiche wie Diagramme, Tabellen, Flussdiagramme, mathematische Formeln und Textdaten. Diese Bilder werden von entsprechenden strukturierten Darstellungen begleitet, z. B. der entsprechenden Markdown- oder LaTeX-Notation. Wir haben festgestellt, dass diese Daten nicht nur die Erkennungsfähigkeiten des Modells in diesen Bereichen verbessern, sondern auch nützlich sind, um Frage-Antwort-Paare für die Feinabstimmung durch textuelle Modellierung zu erzeugen.

Abb. 28 Schematische Darstellung des kombinierten Ansatzes zur Erweiterung der multimodalen Fähigkeiten von Llama 3, der in dieser Arbeit untersucht wurde. Dieser Ansatz führt zu einem multimodalen Modell, das in fünf Stufen trainiert wird: Vorschulung des Sprachmodells, Vorschulung des multimodalen Encoders, Training des visuellen Adapters, Feinabstimmung des Modells und Training des Sprachadapters.
7.1.2 Videodaten
Für das Vortraining von Videos verwenden wir einen großen Datensatz von Video-Text-Paaren. Unser Datensatz wird in einem mehrstufigen Prozess zusammengestellt. Wir verwenden regelbasierte Heuristiken, um relevante Texte zu filtern und zu bereinigen, z. B. um eine Mindestlänge sicherzustellen und Großbuchstaben zu fixieren. Anschließend lassen wir Spracherkennungsmodelle laufen, um nicht-englischen Text herauszufiltern.
Wir haben das OCR-Erkennungsmodell laufen lassen, um Videos mit übermäßig überlagerndem Text herauszufiltern. Um einen angemessenen Abgleich zwischen Video-Text-Paaren sicherzustellen, verwenden wir Bild-Text- und Video-Text-Vergleichsmodelle im Stil von CLIP (Radford et al., 2021). Wir berechnen zunächst die Bild-Text-Ähnlichkeit anhand eines Einzelbildes aus dem Video und filtern Paare mit geringer Ähnlichkeit heraus. Einige unserer Daten enthielten unbewegte oder bewegungsarme Videos; diese filterten wir mit Hilfe der bewegungsscorebasierten Filterung (Girdhar et al., 2023). Wir haben keine Filter auf die visuelle Qualität der Videos angewandt, wie etwa ästhetische Bewertungen oder Auflösungsfilter.
Unser Datensatz enthält Videos mit einer mittleren Dauer von 16 Sekunden und einer durchschnittlichen Dauer von 21 Sekunden, wobei mehr als 99% der Videos weniger als eine Minute lang sind. Die räumliche Auflösung variiert stark zwischen 320p- und 4K-Videos, wobei mehr als 70% Videos kurze Kanten mit mehr als 720 Pixeln aufweisen. Die Videos haben unterschiedliche Seitenverhältnisse, wobei fast alle Videos ein Seitenverhältnis zwischen 1:2 und 2:1 haben, mit einem Median von 1:1.
7.2 Modellarchitektur
Unser visuelles Erkennungsmodell besteht aus drei Hauptkomponenten: (1) einem Bildkodierer, (2) einem Bildadapter und (3) einem Videoadapter.
Bild-Encoder.
Unser Bildkodierer ist ein Standard-Visual-Transformer (ViT; Dosovitskiy et al. (2020)), der darauf trainiert ist, Bilder und Text aneinander anzupassen (Xu et al., 2023). Wir haben die Version ViT-H/14 des Bild-Encoders verwendet, die 630 Millionen Parameter hat und fünf Epochen lang auf 2,5 Milliarden Bild-Text-Paaren trainiert wurde. Die Auflösung des Eingangsbildes des Bild-Encoders betrug 224 × 224; das Bild wurde in 16 × 16 gleich große Teile aufgeteilt (d. h. eine Blockgröße von 14 × 14 Pixeln). Wie in früheren Arbeiten, z. B. ViP-Llava (Cai et al., 2024), gezeigt wurde, haben wir festgestellt, dass Bildcodierer, die durch den Vergleich textausgerichteter Ziele trainiert wurden, keine feinkörnigen Lokalisierungsinformationen behalten. Um dieses Problem zu entschärfen, verwendeten wir einen mehrschichtigen Ansatz zur Merkmalsextraktion, der zusätzlich zur letzten Merkmalsebene Merkmale auf den Schichten 4, 8, 16, 24 und 31 lieferte.
Zusätzlich fügten wir vor dem Vortraining der Cross-Attention-Schichten 8 weitere Gated-Self-Attention-Schichten (insgesamt 40 Transformer-Blöcke) ein, um ausrichtungsspezifische Merkmale zu lernen. Das Ergebnis war, dass der Bildkodierer 850 Millionen Parameter und zusätzliche Schichten enthielt. Mit mehreren Schichten von Merkmalen erzeugt der Bildkodierer eine 7680-dimensionale Darstellung für jeden der erzeugten 16 × 16 = 256 Chunks. Wir frieren die Parameter des Bildkodierers in späteren Trainingsphasen nicht ein, da wir festgestellt haben, dass dies die Leistung verbessert, insbesondere in Bereichen wie der Texterkennung.
Bildadapter.
Wir führen eine Cross-Attention-Schicht zwischen der visuellen Marker-Repräsentation, die durch den Bild-Encoder erzeugt wird, und der Marker-Repräsentation, die durch das Sprachmodell erzeugt wird, ein (Alayrac et al., 2022). Die Cross-Attention-Schicht wird nach jeder vierten Self-Attention-Schicht des Kern-Sprachmodells eingesetzt. Wie das Sprachmodell selbst nutzt auch die Cross-Attention-Schicht die generalisierte Query Attention (GQA) zur Verbesserung der Effizienz.
Die Cross-Attention-Schicht führt eine große Anzahl von trainierbaren Parametern in das Modell ein: für Llama 3 405B hat die Cross-Attention-Schicht etwa 100 Milliarden Parameter. Wir haben die Bildadapter in zwei Stufen vortrainiert: (1) anfängliches Vortraining und (2) Annealing:* Erste Vorschulung. Wir haben unsere Bildadapter mit dem oben erwähnten Datensatz von etwa 6 Milliarden Bild-Text-Paaren vortrainiert. Um die Berechnungseffizienz zu verbessern, passen wir die Größe aller Bilder so an, dass sie in maximal vier Blöcke mit 336 × 336 Pixeln passen, wobei wir die Blöcke so anordnen, dass sie verschiedene Seitenverhältnisse unterstützen, z. B. 672 × 672, 672 × 336 und 1344 × 336. ● Die Bildadapter sind so konzipiert, dass sie in maximal vier Blöcke mit 336 × 336 Pixeln passen. Glühen. Wir trainieren den Bildadapter weiterhin mit etwa 500 Millionen Bildern aus dem oben beschriebenen Annealing-Datensatz. Während des Annealing-Prozesses erhöhen wir die Bildauflösung jedes Blocks, um die Leistung bei Aufgaben zu verbessern, die höher aufgelöste Bilder erfordern, wie z. B. das Verstehen von Infografiken.
Video-Adapter.
Unser Modell akzeptiert Eingaben von bis zu 64 Einzelbildern (gleichmäßig aus dem gesamten Video abgetastet), von denen jedes von einem Bildcodierer verarbeitet wird. Wir modellieren die zeitliche Struktur im Video mit Hilfe von zwei Komponenten: (i) die kodierten Videobilder werden mit Hilfe eines zeitlichen Aggregators, der 32 aufeinanderfolgende Bilder zu einem zusammenfasst, zu einem einzigen zusammengefügt; und (ii) zusätzliche Video-Cross-Attention-Schichten werden vor jeder vierten Bild-Cross-Attention-Schicht hinzugefügt. Zeitliche Aggregatoren sind als Perceptron-Resampler implementiert (Jaegle et al., 2021; Alayrac et al., 2022). Für das Pre-Training wurden 16 Einzelbilder pro Video (zusammengefasst zu einem Einzelbild) verwendet, während der überwachten Feinabstimmung wurde die Anzahl der Einzelbilder auf 64 erhöht. Der Video-Aggregator und die Cross-Attention-Schicht haben 0,6 bzw. 4,6 Milliarden Parameter in Llama 3 7B und 70B.
7.3 Modellgröße
Nach dem Hinzufügen der visuellen Erkennungskomponenten zu Llama 3 enthält das Modell eine Selbstaufmerksamkeitsschicht, eine Kreuzaufmerksamkeitsschicht und einen ViT-Bildkodierer. Wir haben festgestellt, dass Datenparallelität und Tensorparallelität die effizientesten Kombinationen beim Training von Adaptern für kleinere Modelle (8 und 70 Milliarden Parameter) sind. Bei diesen Größenordnungen wird die Modell- oder Pipeline-Parallelität die Effizienz nicht verbessern, da das Sammeln von Modellparametern die Berechnungen dominiert. Beim Training des Adapters für das 405-Milliarden-Parameter-Modell haben wir jedoch Pipeline-Parallelität (zusätzlich zur Daten- und Tensor-Parallelität) verwendet. Das Training in diesem Maßstab bringt drei neue Herausforderungen mit sich, zusätzlich zu den in Abschnitt 3.3 beschriebenen: Modellheterogenität, Datenheterogenität und numerische Instabilität.
Heterogenität der Modelle. Die Modellberechnungen sind heterogen, da einige Token mehr Berechnungen durchführen als andere. Insbesondere werden Bild-Token durch den Bild-Encoder und die Cross-Attention-Schicht verarbeitet, während Text-Token nur durch das linguistische Backbone-Netzwerk verarbeitet werden. Diese Heterogenität kann zu Engpässen bei der parallelen Planung der Pipeline führen. Wir gehen dieses Problem an, indem wir sicherstellen, dass jede Pipelinestufe fünf Schichten enthält: d. h. vier Self-Attention-Schichten und eine Cross-Attention-Schicht im linguistischen Backbone-Netzwerk. (Es sei daran erinnert, dass wir nach jeweils vier Self-Attention-Schichten eine Cross-Attention-Schicht eingeführt haben). Außerdem replizieren wir den Bildkodierer auf alle Pipelinestufen. Da wir auf gepaarten Bild-Text-Daten trainieren, ermöglicht uns dies einen Lastausgleich zwischen dem Bild- und dem Textteil der Berechnung.
Heterogenität der DatenDie Daten sind heterogen, weil Bilder im Durchschnitt mehr Token haben als der zugehörige Text: ein Bild hat 2308 Token, während der zugehörige Text nur 192 Token hat. Die Daten sind heterogen, weil Bilder im Durchschnitt mehr Token haben als der zugehörige Text: ein Bild hat 2308 Token, während der zugehörige Text im Durchschnitt nur 192 Token hat. Infolgedessen dauert die Berechnung der Cross-Attention-Schicht länger und erfordert mehr Speicherplatz als die Berechnung der Self-Attention-Schicht. Wir gehen dieses Problem an, indem wir Sequenzparallelität in den Bildkodierer einführen, so dass jede GPU ungefähr die gleiche Anzahl von Token verarbeitet. Außerdem verwenden wir aufgrund der relativ geringen durchschnittlichen Textgröße eine größere Mikrostapelgröße (8 statt 1).
Numerische Instabilität. Nachdem wir den Bildkodierer zum Modell hinzugefügt hatten, stellten wir fest, dass die Gradientenakkumulation mit bf16 zu instabilen Werten führte. Die wahrscheinlichste Erklärung dafür ist, dass die Bildmarker durch alle Cross-Attention-Schichten in das linguistische Backbone-Netzwerk eingeführt werden. Dies bedeutet, dass numerische Abweichungen in der mit Bildmarkierungen versehenen Repräsentation einen unverhältnismäßig großen Einfluss auf die Gesamtberechnung haben, da sich die Fehler addieren. Wir gehen dieses Problem an, indem wir eine Gradientenakkumulation mit FP32 durchführen.
7.4 Vorschulung
Bild-Vortraining. Wir beginnen die Initialisierung mit dem vortrainierten Textmodell und den Gewichten des visuellen Codierers. Der visuelle Kodierer wurde aufgetaut, während die Gewichte des Textmodells wie oben beschrieben eingefroren blieben. Zunächst wurde das Modell anhand von 6 Milliarden Bild-Text-Paaren trainiert, wobei jedes Bild so verkleinert wurde, dass es in vier 336 × 336 Pixel große Plots passte. Wir verwendeten eine globale Stapelgröße von 16.384 und ein Kosinus-Lernratenschema mit einer anfänglichen Lernrate von 10 × 10 -4 und einem Gewichtsabfall von 0,01. Die anfängliche Lernrate wurde anhand von Experimenten in kleinem Maßstab ermittelt. Diese Ergebnisse lassen sich jedoch nicht gut auf sehr lange Trainingspläne verallgemeinern, und wir reduzieren die Lernrate mehrmals während des Trainings, wenn die Verlustwerte stagnieren. Nach dem grundlegenden Vortraining erhöhen wir die Bildauflösung weiter und setzen das Training mit denselben Gewichten auf dem geglätteten Datensatz fort. Der Optimierer wird durch Aufwärmen auf eine Lernrate von 2 × 10 -5 reinitialisiert, wiederum nach dem Kosinus-Schema.
Video-Vorschulung. Für das Video-Pre-Training beginnen wir mit dem oben beschriebenen Bild-Pre-Training und den Annealing-Gewichten. Wir fügen Video-Aggregator- und Cross-Attention-Schichten wie in der Architektur beschrieben hinzu und initialisieren sie nach dem Zufallsprinzip. Wir frieren alle Parameter des Modells mit Ausnahme der videospezifischen (Aggregator und Video-Cross-Attention) ein und trainieren sie anhand der Videovortrainingsdaten. Wir verwenden die gleichen Trainingshyperparameter wie in der Image Annealing-Phase, mit leicht unterschiedlichen Lernraten. Wir nehmen gleichmäßig 16 Bilder aus dem gesamten Video und verwenden vier Blöcke der Größe 448 × 448 Pixel, um jedes Bild darzustellen. Wir verwenden einen Aggregationsfaktor von 16 im Videoaggregator, um ein gültiges Bild zu erhalten, auf das die Textmarker den Fokus legen. Wir trainieren mit einer globalen Stapelgröße von 4.096, einer Sequenzlänge von 190 Token und einer Lernrate von 10 -4.
7.5 Nachbereitung der Ausbildung
In diesem Abschnitt beschreiben wir die weiteren Trainingsschritte für den visuellen Adapter im Detail.
Nach dem Vortraining haben wir das Modell auf hochgradig ausgewählte multimodale Dialogdaten abgestimmt, um die Chat-Funktionalität zu ermöglichen.
Darüber hinaus setzen wir die direkte Präferenzoptimierung (DPO) ein, um die Leistung der manuellen Auswertung zu verbessern, und verwenden Rückweisungsstichproben, um die multimodale Inferenz zu verbessern.
Schließlich fügen wir eine Qualitätsoptimierungsphase hinzu, in der wir das Modell anhand eines sehr kleinen Datensatzes hochwertiger Dialoge weiter feinabstimmen, was die Ergebnisse der manuellen Bewertung weiter verbessert, während die Leistung des Benchmark-Tests erhalten bleibt.
Im Folgenden finden Sie detaillierte Informationen zu den einzelnen Schritten.
7.5.1 Überwachung von Feinabstimmungsdaten
Im Folgenden werden die Daten für die überwachte Feinabstimmung (SFT) für Bild- bzw. Videofunktionen beschrieben.
IMAGE. Wir verwenden eine Mischung aus verschiedenen Datensätzen für die überwachte Feinabstimmung.
- Akademische Datensätze: Wir konvertieren stark gefilterte bestehende akademische Datensätze in Q&A-Paare mit Hilfe von Vorlagen oder durch Umschreiben mittels Large Language Modelling (LLM), um die Daten mit verschiedenen Anweisungen zu ergänzen und die sprachliche Qualität der Antworten zu verbessern.
- Manuelle Annotation: Wir sammeln multimodale Dialogdaten für eine Vielzahl von Aufgaben (offene Fragen und Antworten, Untertitel, reale Anwendungsfälle usw.) und Domänen (z. B. natürliche und strukturierte Bilder) durch manuelle Annotatoren. Der Annotator erhält die Bilder und wird gebeten, den Dialog zu verfassen.
Um die Vielfalt zu gewährleisten, haben wir den großen Datensatz geclustert und die Bilder gleichmäßig auf die verschiedenen Cluster verteilt. Darüber hinaus erhalten wir zusätzliche Bilder für einige spezifische Bereiche, indem wir die Seeds mit Hilfe von k-nearest neighbours erweitern. Der Annotator erhält auch Zwischenkontrollpunkte bestehender Modelle, um die stilistische Annotation der Modelle in der Schleife zu erleichtern, so dass die Modellerzeugung als Ausgangspunkt für den Annotator verwendet werden kann, um zusätzliche menschliche Bearbeitungen vorzunehmen. Dabei handelt es sich um einen iterativen Prozess, bei dem die Modellprüfpunkte regelmäßig auf leistungsfähigere Versionen aktualisiert werden, die mit den neuesten Daten trainiert wurden. Dies erhöht den Umfang und die Effizienz der manuellen Annotation und verbessert gleichzeitig die Qualität.
- Synthetische Daten: Wir erforschen verschiedene Ansätze zur Erzeugung synthetischer multimodaler Daten durch die Verwendung textueller Darstellungen von Bildern und textueller Eingabe-LLMs. Die Grundidee besteht darin, die Inferenzfähigkeiten der Texteingabe-LLM zu nutzen, um Q&A-Paare im Textbereich zu generieren und die textuellen Repräsentationen durch ihre entsprechenden Bilder zu ersetzen, um synthetische multimodale Daten zu erzeugen. Beispiele hierfür sind die Darstellung von Text aus Q&A-Datensätzen als Bilder oder von tabellarischen Daten als synthetische Tabellen- und Diagrammbilder. Darüber hinaus nutzen wir die Beschriftung und OCR-Extraktion vorhandener Bilder, um allgemeine Dialog- oder Q&A-Daten in Verbindung mit den Bildern zu erzeugen.
Video. Ähnlich wie beim Bildadapter verwenden wir bereits vorhandene kommentierte akademische Datensätze für die Umwandlung in geeignete textliche Anweisungen und Zielantworten. Zielvorgaben werden je nach Bedarf in offene Antworten oder Multiple-Choice-Fragen umgewandelt. Wir haben menschliche Annotatoren gebeten, den Videos Fragen und entsprechende Antworten hinzuzufügen. Wir baten den Kommentator, sich auf Fragen zu konzentrieren, die nicht auf der Grundlage einzelner Frames beantwortet werden konnten, um den Kommentator auf Fragen zu lenken, deren Verständnis Zeit in Anspruch nehmen würde.
7.5.2 Überwachung der Feinsteuerungsprogramme
Wir stellen überwachte Feinabstimmungsprogramme (SFT) für Bild- und Videofähigkeiten vor:
IMAGE. Wir initialisieren das Modell mit den vortrainierten Bildadaptern, ersetzen aber die Gewichte des vortrainierten Sprachmodells durch die Gewichte des auf die Anweisungen abgestimmten Sprachmodells. Um die reine Textleistung beizubehalten, werden die Gewichte des Sprachmodells eingefroren, d. h. wir aktualisieren nur die Gewichte des visuellen Codierers und der Bildadapter.
Unser Ansatz für die Feinabstimmung ist ähnlich wie der von Wortsman et al. (2022). Zunächst führen wir Hyperparameterscans mit mehreren zufälligen Teilmengen von Daten, Lernraten und Gewichtungsabfallwerten durch. Anschließend werden die Modelle anhand ihrer Leistung bewertet. Der Wert von K wurde durch Auswertung des Durchschnittsmodells und Auswahl der leistungsstärksten Instanz ermittelt. Wir stellen fest, dass das Durchschnittsmodell durchweg bessere Ergebnisse liefert als das beste Einzelmodell, das durch die Rastersuche gefunden wurde. Darüber hinaus verringert diese Strategie die Empfindlichkeit gegenüber Hyperparametern.
Video. Für die Video-SFT initialisieren wir den Video-Aggregator und die Cross-Attention-Schicht mit vortrainierten Gewichten. Die übrigen Parameter des Modells (Bildgewichte und LLM) werden anhand des entsprechenden Modells initialisiert und durchlaufen die entsprechenden Feinabstimmungsphasen. Ähnlich wie beim Videotraining werden dann nur die Videoparameter auf den Video-SFT-Daten feinabgestimmt. In dieser Phase erhöhen wir die Videolänge auf 64 Bilder und verwenden einen Aggregationsfaktor von 32, um zwei gültige Bilder zu erhalten. Die Auflösung des aynı zamanda,-Blocks wird entsprechend erhöht, damit sie mit den entsprechenden Bildhyperparametern übereinstimmt.
7.5.3 Vorlieben
Zur Belohnungsmodellierung und direkten Präferenzoptimierung haben wir multimodale gepaarte Präferenzdatensätze erstellt.
- Manuelle Beschriftung. Die manuell kommentierten Präferenzdaten bestehen aus einem Vergleich der Ergebnisse von zwei verschiedenen Modellen, die mit "auswählen" und "ablehnen" gekennzeichnet sind und auf einer 7-Punkte-Skala bewertet werden. Die Modelle, die zur Generierung der Antworten verwendet werden, werden jede Woche nach dem Zufallsprinzip aus einem Pool der besten aktuellen Modelle ausgewählt, die jeweils unterschiedliche Merkmale aufweisen. Zusätzlich zu den Präferenz-Labels baten wir die Kommentatoren um eine optionale manuelle Bearbeitung, um Ungenauigkeiten in der Antwort "Auswählen" zu korrigieren, da die visuelle Aufgabe weniger tolerant gegenüber Ungenauigkeiten ist. Beachten Sie, dass die manuelle Bearbeitung ein optionaler Schritt ist, da es in der Praxis einen Kompromiss zwischen Quantität und Qualität gibt.
- Synthesedaten. Synthetische Präferenzpaare können auch durch die Verwendung von reinem Text-LLM-Editing und die absichtliche Einführung von Fehlern in den überwachten Feinabstimmungsdatensatz erzeugt werden. Wir haben Dialogdaten als Input genommen und LLM verwendet, um subtile, aber bedeutungsvolle Fehler einzufügen (z.B. das Ändern von Objekten, das Ändern von Attributen, das Hinzufügen von Rechenfehlern, usw.). Diese bearbeiteten Antworten werden als negative "Ablehnungsproben" verwendet und mit den "ausgewählten" ursprünglichen überwachten Feinabstimmungsdaten gepaart.
- Probenahme ablehnen. Um strategischere Negativstichproben zu erstellen, verwenden wir außerdem einen iterativen Prozess des Rejection Sampling, um zusätzliche Präferenzdaten zu sammeln. Wie Rejection Sampling eingesetzt wird, wird in den nächsten Abschnitten ausführlicher erläutert. Zusammenfassend lässt sich sagen, dass das Rejection Sampling dazu dient, iterativ hochwertige Ergebnisse aus dem Modell zu ziehen. Als Nebenprodukt können daher alle nicht ausgewählten generierten Ergebnisse als negative Rückweisungsstichproben und als zusätzliche Präferenzdatenpaare verwendet werden.
7.5.4 Belohnungsmodellierung
Wir haben ein visuelles Belohnungsmodell (RM) trainiert, das auf einem visuellen SFT-Modell und einem linguistischen RM basiert. Die visuellen Encoder- und Cross-Attention-Schichten wurden aus dem visuellen SFT-Modell initialisiert und während des Trainings aufgetaut, während die Self-Attention-Schicht aus dem linguistischen RM initialisiert und eingefroren wurde. Wir stellen fest, dass das Einfrieren des sprachlichen RM-Teils in der Regel zu einer besseren Genauigkeit führt, insbesondere bei Aufgaben, bei denen das RM auf der Grundlage seines Wissens oder seiner Sprachqualität Urteile fällen muss. Wir verwenden dasselbe Trainingsziel wie für das sprachliche RM, fügen aber einen gewichteten Regularisierungsterm hinzu, um die stapelgemittelten Belohnungslogits zu quadrieren, um eine Drift der Belohnungswerte zu verhindern.
Die menschlichen Präferenzannotationen in Abschnitt 7.5.3 wurden zum Trainieren der visuellen RMs verwendet. Wir verfolgten den gleichen Ansatz wie bei den linguistischen Präferenzdaten (Abschnitt 4.2.1), indem wir zwei oder drei Paare mit klaren Rangfolgen (bearbeitete Version > ausgewählte Version > abgelehnte Version) erstellten. Darüber hinaus haben wir negative Antworten synthetisch verstärkt, indem wir Wörter oder Phrasen (z. B. Zahlen oder visuellen Text), die mit den Bildinformationen verbunden sind, verschlüsselt haben. Auf diese Weise wird das visuelle RM dazu angeregt, seine Urteile auf der Grundlage des tatsächlichen Bildinhalts zu fällen.
7.5.5 Direkte Präferenzoptimierung
Ähnlich wie beim Sprachmodell (Abschnitt 4.1.4) haben wir die visuellen Adapter mit Hilfe der direkten Präferenzoptimierung (DPO; Rafailov et al. (2023)) mit den in Abschnitt 7.5.3 beschriebenen Präferenzdaten weiter trainiert. Um Verteilungsfehler während des Nachtrainings zu bekämpfen, behielten wir nur die jüngsten Chargen menschlicher Präferenzannotationen bei und verwarfen jene Chargen, die weit hinter der Strategie zurückblieben (z. B. wenn das zugrundeliegende Pre-Training-Modell geändert wurde). Wir haben herausgefunden, dass das Modell mehr aus den Daten lernt, wenn es alle k Schritte als exponentieller gleitender Durchschnitt (EMA) aktualisiert wird, anstatt das Referenzmodell die ganze Zeit einzufrieren, was zu einer besseren Leistung bei menschlichen Bewertungen führt. Insgesamt stellen wir fest, dass das visuelle DPO-Modell seinen SFT-Ausgangspunkt in menschlichen Bewertungen durchweg übertrifft und in jeder Feinabstimmungsiteration gute Leistungen erbringt.
7.5.6 Ablehnung der Probenahme
Die meisten vorhandenen Quizpaare enthalten nur die endgültigen Antworten und lassen die Erklärungen der Gedankenkette vermissen, die erforderlich sind, um auf Modelle zu schließen, die die Aufgabe gut verallgemeinern. Wir verwenden Rejection Sampling, um die fehlenden Erklärungen für diese Beispiele zu generieren und dadurch die Inferenz des Modells zu verbessern.
Bei einem Quizpaar generieren wir mehrere Antworten, indem wir das fein abgestimmte Modell mit verschiedenen Systemhinweisen oder Temperaturen abfragen. Anschließend vergleichen wir die generierten Antworten mit den wahren Antworten über Heuristiken oder LLM-Referenten. Schließlich trainieren wir das Modell neu, indem wir die richtigen Antworten zu den feinabgestimmten Daten hinzufügen. Es hat sich als nützlich erwiesen, mehrere richtige Antworten pro Frage zu speichern.
Um sicherzustellen, dass nur qualitativ hochwertige Beispiele in die Ausbildung aufgenommen werden, haben wir die folgenden zwei Sicherheitsmaßnahmen eingeführt:
- Wir haben festgestellt, dass einige Beispiele falsche Erklärungen enthielten, obwohl die endgültige Antwort richtig war. Wir stellen fest, dass dieses Muster häufiger bei Fragen vorkommt, bei denen nur ein kleiner Teil der generierten Antworten richtig ist. Daher haben wir Antworten auf Fragen verworfen, bei denen die Wahrscheinlichkeit einer richtigen Antwort unter einem bestimmten Schwellenwert lag.
- Prüfer bevorzugen bestimmte Antworten aufgrund von sprachlichen oder stilistischen Unterschieden. Wir verwenden ein Belohnungsmodell, um die K hochwertigsten Antworten auszuwählen und sie zum Training hinzuzufügen.
7.5.7 Qualitätsoptimierung
Wir haben sorgfältig einen kleinen, aber hochselektiven Feinabstimmungsdatensatz (SFT) kuratiert, bei dem alle Proben umgeschrieben und validiert wurden, um die höchsten Standards zu erfüllen, entweder manuell oder durch unsere besten Modelle. Wir verwenden diese Daten zum Trainieren von DPO-Modellen, um die Antwortqualität zu verbessern, und bezeichnen diesen Prozess als Quality Tuning (QT). Wir haben festgestellt, dass QT, wenn der QT-Datensatz ein breites Aufgabenspektrum abdeckt und geeignete frühe Stopps angewendet werden, die menschlichen Bewertungsergebnisse erheblich verbessern kann, ohne die allgemeine Leistung der Benchmark-Testvalidierung zu beeinträchtigen. In dieser Phase wählen wir Kontrollpunkte nur auf der Grundlage von Benchmark-Tests aus, um sicherzustellen, dass die Fähigkeiten erhalten bleiben oder verbessert werden.
7.6 Ergebnisse der Bilderkennung
Wir haben die Leistung der Llama 3 Bildverstehensfähigkeiten in einer Reihe von Aufgaben evaluiert, die natürliches Bildverstehen, Textverstehen, Diagrammverstehen und multimodales Schlussfolgern abdecken:
- MMMU (Yue et al., 2024a) ist ein anspruchsvoller Datensatz für multimodales schlussfolgerndes Denken, bei dem Modelle Bilder interpretieren und Probleme auf Universitätsniveau in 30 verschiedenen Disziplinen lösen müssen. Dazu gehören Multiple-Choice-Fragen und offene Fragen. Wir evaluieren das Modell anhand eines Validierungssatzes mit 900 Bildern, der mit anderen Arbeiten übereinstimmt.
- VQAv2 (Antol et al., 2015) testet die Fähigkeit des Modells, Bildverständnis, Sprachverständnis und Allgemeinwissen zu kombinieren, um allgemeine Fragen zu natürlichen Bildern zu beantworten.
- AI2 Diagram (Kembhavi et al., 2016) bewertet die Fähigkeit von Modellen, wissenschaftliche Diagramme zu analysieren und Fragen dazu zu beantworten. Wir haben das gleiche Modell verwendet wie Zwillinge Gleiches Bewertungsprotokoll wie x.ai und Verwendung von transparenten Bounding Boxes zur Angabe der Punktzahl.
- ChartQA (Masry et al., 2022) ist ein anspruchsvoller Benchmark-Test für das Verständnis von Diagrammen. Er verlangt von den Modellen, verschiedene Arten von Diagrammen visuell zu verstehen und Fragen zur Logik dieser Diagramme zu beantworten.
- TextVQA (Singh et al., 2019) ist ein beliebter Benchmark-Datensatz, bei dem Modelle Text in Bildern lesen und interpretieren müssen, um Anfragen zu beantworten. Damit wird die Fähigkeit des Modells getestet, OCR in natürlichen Bildern zu verstehen.
- DocVQA (Mathew et al., 2020) ist ein Benchmark-Datensatz, der sich auf die Analyse und Erkennung von Dokumenten konzentriert. Er enthält Bilder eines breiten Spektrums von Dokumenten und bewertet die Fähigkeit von OCR-Modellen, den Inhalt von Dokumenten zu verstehen und Schlussfolgerungen zu ziehen, um Fragen dazu zu beantworten.
Tabelle 29 zeigt die Ergebnisse unserer Experimente. Die Ergebnisse in der Tabelle zeigen, dass das an Llama 3 angeschlossene Bildverarbeitungsmodul bei verschiedenen Bilderkennungsbenchmarks mit unterschiedlichen Modellkapazitäten konkurrenzfähig ist. Mit dem resultierenden Llama 3-V 405B Modell übertreffen wir das GPT-4V in allen Benchmarks, liegen aber leicht unter dem Gemini 1.5 Pro und dem Claude 3.5 Sonnet. Das Llama 3 405B schneidet besonders gut bei der Aufgabe des Dokumentenverständnisses ab.

7.7 Ergebnisse der Videoerkennung
Wir haben die Grafikkarte des Llama 3 in drei Benchmarks getestet:
- PerceptionTest (Lin et al., 2023)Dieser Benchmark testet die Fähigkeit des Modells, kurze Videoclips zu verstehen und vorherzusagen. Er enthält verschiedene Arten von Problemen wie das Erkennen von Objekten, Aktionen, Szenen usw. Wir berichten über die Ergebnisse auf der Grundlage des offiziell bereitgestellten Codes und der Bewertungsmetriken (Genauigkeit).
- TVQA (Lei et al., 2018)Dieser Benchmark bewertet die Fähigkeit des Modells, zusammengesetzte Schlussfolgerungen zu ziehen, was die räumlich-zeitliche Lokalisierung, die Erkennung visueller Konzepte und die gemeinsame Schlussfolgerung mit untertitelten Dialogen beinhaltet. Da der Datensatz aus beliebten Fernsehsendungen stammt, wird auch die Fähigkeit des Modells getestet, externes Wissen über diese Fernsehsendungen zur Beantwortung von Fragen zu nutzen. Er enthält über 15.000 validierte QA-Paare, die jeweils einem Videoclip mit einer durchschnittlichen Länge von 76 Sekunden entsprechen. Es wird ein Multiple-Choice-Format mit fünf Optionen pro Frage verwendet, und wir berichten über die Leistung bei der Validierungsmenge auf der Grundlage früherer Arbeiten (OpenAI, 2023b).
- ActivityNet-QA (Yu et al., 2019)Dieser Benchmark bewertet die Fähigkeit des Modells, lange Videoclips zu verstehen, um Handlungen, räumliche und zeitliche Beziehungen, Zählungen und mehr zu erkennen. Er enthält 8.000 Test-QA-Paare aus 800 Videos mit einer durchschnittlichen Länge von jeweils 3 Minuten. Für die Bewertung folgen wir dem Protokoll früherer Arbeiten (Google, 2023; Lin et al., 2023; Maaz et al., 2024), bei denen das Modell kurze Wort- oder Satzantworten generiert und sie mit realen Antworten unter Verwendung der GPT-3.5 API vergleicht, um die Korrektheit der Ausgabe zu bewerten. Wir geben die durchschnittliche Genauigkeit an, die von der API berechnet wird.
Argumentationsprozess
Bei der Durchführung von Schlussfolgerungen werden aus dem gesamten Videoclip gleichmäßig Bilder ausgewählt und zusammen mit einer kurzen Textaufforderung an das Modell übergeben. Da die meisten Benchmarks die Beantwortung von Multiple-Choice-Fragen beinhalten, verwenden wir die folgenden Aufforderungen:
- Wählen Sie die richtige Antwort aus den folgenden Optionen:{Frage}. Antworten Sie nur mit dem richtigen Buchstaben der Option und schreiben Sie nichts anderes.
Für Benchmarks, die kurze Antworten generieren müssen (z. B. ActivityNet-QA und NExT-QA), verwenden wir die folgenden Hinweise:
- Beantworten Sie die Frage mit einem Wort oder einem Satz: {Frage}.
Da die Bewertungsmetriken (WUPS) bei NExT-QA empfindlich auf die Länge und die verwendeten Wörter reagieren, haben wir das Modell auch aufgefordert, spezifisch zu sein und auf die hervorstechendsten Antworten zu reagieren, z. B. bei der Frage nach dem Ort "Wohnzimmer" anzugeben anstatt einfach "Haus ". Bei Benchmarks, die Untertitel enthalten (z. B. TVQA), beziehen wir die entsprechenden Untertitel des Clips in den Hinweis während des Inferenzprozesses ein.
am Ende
Tabelle 30 zeigt die Leistung der Modelle Llama 3 8B und 70B. Wir vergleichen ihre Leistung mit der Leistung der beiden Gemini-Modelle und der beiden GPT-4-Modelle. Beachten Sie, dass es sich bei allen Ergebnissen um Nullstichproben handelt, da wir keinen Teil dieser Benchmarks in unsere Trainings- oder Feinabstimmungsdaten aufgenommen haben. Wir stellen fest, dass unser Llama-3-Modell beim Training von kleinen Videoadaptern während des Post-Processings sehr wettbewerbsfähig ist und in einigen Fällen sogar andere Modelle übertrifft, die die Vorteile der nativen multimodalen Verarbeitung vom Pre-Training an nutzen.Llama 3 schneidet besonders gut bei der Videoerkennung ab, da wir nur die 8B- und 70B-Parameter-Modelle evaluiert haben.Llama 3 erzielte die beste Leistung im PerceptionTest, was die starke Fähigkeit des Modells zeigt, komplexe zeitliche Schlussfolgerungen zu ziehen. Bei Aufgaben zum Verstehen von Aktivitäten in langen Clips wie ActivityNet-QA erzielt Llama 3 gute Ergebnisse, auch wenn es nur bis zu 64 Bilder verarbeitet (bei einem 3-minütigen Video verarbeitet das Modell nur ein Bild alle 3 Sekunden).


8 Sprachexperiment
Wir haben Experimente durchgeführt, um einen kombinatorischen Ansatz für die Integration von Sprachfunktionen in Llama 3 zu untersuchen, der dem Schema ähnelt, das wir für die visuelle Erkennung verwendet haben. Am Eingang wurden Encoder und Adapter hinzugefügt, um das Sprachsignal zu verarbeiten. Wir verwenden Systemhinweise (in Form von Text), um Llama 3 in die Lage zu versetzen, verschiedene Arten des Sprachverständnisses zu unterstützen. Wenn keine Systemhinweise gegeben werden, fungiert das Modell als generisches Sprachdialogmodell, das auf die Sprache des Benutzers in einer Weise reagieren kann, die der reinen Textversion von Llama 3 entspricht. Die Einführung eines Dialogverlaufs als Präfix kann die Dialogerfahrung in mehreren Runden verbessern. Wir haben auch mit der Verwendung von System-Prompts für die automatische Spracherkennung (ASR) und die automatische Sprachübersetzung (AST) in Llama 3 experimentiert. Die Sprachschnittstelle von Llama 3 unterstützt bis zu 34 Sprachen.18 Sie ermöglicht auch die abwechselnde Eingabe von Text und Sprache, so dass das Modell fortgeschrittene Audioverstehensaufgaben lösen kann.
Wir haben auch mit einem Ansatz zur Spracherzeugung experimentiert, bei dem wir ein Streaming-Text-to-Speech-System (TTS) implementiert haben, das während der Dekodierung des Sprachmodells dynamisch Sprachwellenformen erzeugt. Wir entwickelten den Sprachgenerator von Llama 3 auf der Grundlage des proprietären TTS-Systems und nahmen keine Feinabstimmung des Sprachmodells für die Spracherzeugung vor. Stattdessen konzentrierten wir uns auf die Verbesserung der Latenzzeit, der Genauigkeit und der Natürlichkeit der Sprachsynthese durch die Verwendung von Llama 3-Worteinbettungen während der Inferenz. Die Sprachschnittstelle ist in den Abbildungen 28 und 29 dargestellt.
8.1 Daten
8.1.1 Sprachverständnis
Die Trainingsdaten können in zwei Kategorien unterteilt werden. Pre-Training-Daten bestehen aus großen Mengen unmarkierter Sprache, die zur Initialisierung des Sprachcodierers auf selbstüberwachte Weise verwendet werden. Zu den überwachten Feinabstimmungsdaten gehören Daten zur Spracherkennung, zur Sprachübersetzung und zu gesprochenen Dialogen; sie werden verwendet, um bei der Integration mit großen Sprachmodellen bestimmte Fähigkeiten freizusetzen.
Daten vor dem Training. Um den Sprachcodierer vorzutrainieren, haben wir einen Datensatz mit etwa 15 Millionen Stunden Sprachaufnahmen in mehreren Sprachen zusammengestellt. Wir filterten die Audiodaten mithilfe eines Modells zur Erkennung von Sprachaktivität (Voice Activity Detection, VAD) und wählten Audiobeispiele mit einem VAD-Schwellenwert von über 0,7 für das Vortraining aus. Bei den Sprachdaten für das Vortraining haben wir außerdem darauf geachtet, dass keine personenbezogenen Daten (PII) enthalten sind. Wir verwenden Presidio Analyzer, um solche PII zu identifizieren.
Spracherkennung und Übersetzungsdaten. Unsere ASR-Trainingsdaten enthalten 230.000 Stunden handschriftlich transkribierter Sprachaufnahmen in 34 Sprachen. Unsere AST-Trainingsdaten enthalten 90.000 Stunden bidirektionaler Übersetzung: von 33 Sprachen ins Englische und vom Englischen in 33 Sprachen. Diese Daten enthalten sowohl überwachte als auch synthetische Daten, die mit dem NLLB-Toolkit erzeugt wurden (NLLB Team et al., 2022). Die Verwendung von synthetischen AST-Daten verbessert die Qualität der Modelle für Sprachen mit geringen Ressourcen. Die maximale Länge der Sprachsegmente in unseren Daten beträgt 60 Sekunden.
Daten zum gesprochenen Dialog. Zur Feinabstimmung von Sprachadaptern für gesprochene Dialoge haben wir Antworten auf Sprachaufforderungen synthetisiert, indem wir das Sprachmodell gebeten haben, auf Transkriptionen dieser Aufforderungen zu antworten (Fathullah et al., 2024). Wir verwendeten eine Teilmenge des ASR-Datensatzes (mit 60.000 Stunden Sprache), um auf diese Weise synthetische Daten zu erzeugen.
Darüber hinaus haben wir 25.000 Stunden synthetischer Daten generiert, indem wir das Voicebox TTS-System (Le et al., 2024) auf einer Teilmenge der für die Feinabstimmung von Llama 3 verwendeten Daten laufen ließen. Wir verwendeten mehrere Heuristiken, um eine Teilmenge der feinabgestimmten Daten auszuwählen, die der Sprachverteilung entsprach. Diese Heuristiken konzentrierten sich auf relativ kurze und einfach strukturierte Cues und schlossen nicht-textuelle Symbole aus.
8.1.2 Spracherzeugung
语音生成数据集主要包括用于训练文本规范化(TN)模型和韵律模型(PM)的数据集。两种训练数据都通过添加 Llama 3 词嵌入作为额外的输入特征进行增强,以提供上下文信息。
文本规范化数据。我们的 TN 训练数据集包含 5.5 万个样本,涵盖了广泛的符号类别(例如,数字、日期、时间),这些类别需要非平凡的规范化。每个样本由书面形式文本和相应的规范化口语形式文本组成,并包含一个推断的手工制作的 TN 规则序列,用于执行规范化。
声韵模型数据。PM 训练数据包括从一个包含 50,000 小时的 TTS 数据集提取的语言和声韵特征,这些特征与专业配音演员在录音室环境中录制的文字稿件和音频配对。
Llama 3 嵌入。Llama 3 嵌入取自第 16 层解码器输出。我们仅使用 Llama 3 8B 模型,并提取给定文本的嵌入(即 TN 的书面输入文本或 PM 的音频转录),就像它们是由 Llama 3 模型在空用户提示下生成的。在一个样本中,每个 Llama 3 标记序列块都明确地与 TN 或 PM 本地输入序列中的相应块对齐,即 TN 特定的文本标记(由 Unicode 类别区分)或语音速率特征。这允许使用 Llama 3 标记和嵌入的流式输入训练 TN 和 PM 模块。
8.2 Modellarchitektur
8.2.1 Sprachverständnis
Auf der Eingabeseite besteht das Sprachmodul aus zwei aufeinanderfolgenden Modulen: einem Sprachcodierer und einem Adapter. Die Ausgabe des Sprachmoduls wird als Token-Repräsentation direkt in das Sprachmodell eingespeist, was eine direkte Interaktion zwischen Sprach- und Text-Token ermöglicht. Darüber hinaus führen wir zwei neue spezielle Token ein, die Sequenzen von Sprachrepräsentationen enthalten. Das Sprachmodul unterscheidet sich deutlich vom Sehmodul (siehe Abschnitt 7), das multimodale Informationen über die Cross-Attention-Schicht in das Sprachmodell einspeist. Im Gegensatz dazu können die vom Sprachmodul erzeugten Einbettungen nahtlos in die textuellen Token integriert werden, so dass die Sprachschnittstelle alle Funktionen des Llama 3-Sprachmodells nutzen kann.
Sprachcodierer:Unser Sprachcodierer ist ein Conformer-Modell mit 1 Milliarde Parametern (Gulati et al., 2020). Die Eingabe für das Modell besteht aus 80-dimensionalen Meier-Spektrogramm-Merkmalen, die zunächst durch eine gestapelte Schicht mit einer Schrittgröße von 4 verarbeitet und dann durch lineare Projektion auf eine Rahmenlänge von 40 Millisekunden reduziert werden. Die verarbeiteten Merkmale werden von einem Encoder mit 24 Conformer-Schichten verarbeitet. Jede Conformer-Schicht hat eine potenzielle Dimension von 1536 und umfasst zwei Macron-Netz-ähnliche Feedforward-Netze mit einer Dimension von 4096, ein Faltungsmodul mit einer Kernelgröße von 7 und ein Rotationsaufmerksamkeitsmodul mit 24 Aufmerksamkeitsköpfen (Su et al., 2024).
Sprachadapter:Der Sprachadapter enthält etwa 100 Millionen Parameter. Er besteht aus einer Faltungsschicht, einer rotierenden Transformatorschicht und einer linearen Schicht. Die Faltungsschicht hat eine Kernelgröße von 3 und eine Schrittgröße von 2 und ist so konzipiert, dass sie die Sprachrahmenlänge auf 80 ms reduziert. Die Transformationsschicht mit einer potenziellen Dimension von 3072 und das Feed-Forward-Netzwerk mit einer Dimension von 4096 verarbeiten die durch die Faltung heruntergetasteten Sprachinformationen weiter. Schließlich passt die lineare Schicht die Dimension der Ausgabe an die Einbettungsschicht des Sprachmodells an.
8.2.2 Spracherzeugung
Wir verwenden die Einbettung von Llama 3 8B in zwei Schlüsselkomponenten der Spracherzeugung: Textnormalisierung und metrische Modellierung. Das Modul Textnormalisierung (TN) sorgt für semantische Korrektheit, indem es geschriebenen Text kontextuell in gesprochene Form umwandelt. Das Modul Prosodische Modellierung (PM) verbessert die Natürlichkeit und Ausdruckskraft, indem es diese Einbettungen zur Vorhersage prosodischer Merkmale verwendet. Diese beiden Komponenten arbeiten zusammen, um eine genaue und natürliche Spracherzeugung zu erreichen.
**Textnormalisierung**: Als Determinante für die semantische Korrektheit der generierten Sprache führt das Modul Textnormalisierung (TN) eine kontextabhängige Transformation von geschriebenem Text in die entsprechende gesprochene Form durch, die schließlich von nachgeschalteten Komponenten verbalisiert wird. Beispielsweise kann die geschriebene Form "123" je nach semantischem Kontext als Basiszahl (einhundertdreiundzwanzig) gelesen oder ziffernweise buchstabiert werden (eins-zwei-drei).Das TN-System besteht aus einem LSTM-basierten Sequenzetikettierungsmodell, das die Anzahl der zu verwendenden Ziffern vorhersagt, um TN-Regelsequenzen von Eingabetext umwandelt (Kang et al., 2024). Das neuronale Modell empfängt auch Llama-3-Einbettungen über Cross-Attention, um die darin kodierten Kontextinformationen zu nutzen, was eine minimale Textetikettierung im Voraus und Streaming-Input/Output ermöglicht.
**Reim-Modellierung**: Um die Natürlichkeit und Ausdruckskraft der synthetischen Sprache zu verbessern, haben wir ein Reim-Modell (PM) (Radford et al., 2021) integriert, das nur die Transformer-Architektur dekodiert, die Llama 3-Einbettungen als zusätzlichen Input verwendet. Diese Integration macht sich die linguistischen Fähigkeiten von Llama 3 zunutze und verwendet dessen Textausgabe und Zwischeneinbettungen (Devlin et al. 2018; Dong et al. 2019; Raffel et al. 2020; Guo et al. 2023), um die Vorhersage von Reimmerkmalen zu verbessern und dadurch die vom Modell benötigte Vorausschau zu reduzieren. PM integriert mehrere Eingangskomponenten, um umfassende metrische Vorhersagen zu generieren: linguistische Merkmale, Token und Einbettungen, die aus dem oben beschriebenen Textnormalisierungs-Frontend abgeleitet werden. Drei wichtige metrische Merkmale werden von PM vorhergesagt: die logarithmische Dauer jedes Phonems, der logarithmische Mittelwert der Grundfrequenz (F0) und der logarithmische Mittelwert der Leistung über die Dauer des Phonems. Das Modell besteht aus einem unidirektionalen Transformator und sechs Aufmerksamkeitsblöcken. Jeder Block besteht aus einer Cross-Attention-Schicht und einer dualen, vollständig verbundenen Schicht mit 864 versteckten Dimensionen. Eine Besonderheit des PM ist sein dualer Cross-Attention-Mechanismus, bei dem eine Schicht dem sprachlichen Input und die andere der Llama-Einbettung gewidmet ist. Auf diese Weise können unterschiedliche Eingaben ohne expliziten Abgleich effektiv verarbeitet werden.
8.3 Ausbildungsprogramme
8.3.1 Sprachverstehen
Das Training des Sprachmoduls wurde in zwei Phasen durchgeführt. In der ersten Phase, dem Vortraining der Sprache, wird ein Sprachcodierer mit unmarkierten Daten trainiert, der starke Generalisierungsfähigkeiten in Bezug auf linguistische und akustische Bedingungen aufweist. In der zweiten Phase, der überwachten Feinabstimmung, werden der Adapter und der vortrainierte Encoder in das Sprachmodell integriert und gemeinsam mit ihm trainiert, während das LLM eingefroren bleibt. Dies ermöglicht es dem Modell, auf Spracheingaben zu reagieren. In dieser Phase werden gelabelte Daten verwendet, die den Sprachverstehensfähigkeiten entsprechen.
Mehrsprachige ASR- und AST-Modellierung führt oft zu Sprachverwirrung/interferenz, was die Leistung beeinträchtigt. Eine beliebte Abhilfemethode besteht darin, Informationen zur Sprachidentifikation (LID) sowohl in der Quelle als auch im Ziel einzubeziehen. Dies kann die Leistung in einer bestimmten Richtung verbessern, aber es kann auch zu einer Verschlechterung der Generalisierung führen. Wenn ein Übersetzungssystem beispielsweise erwartet, dass es sowohl in der Quelle als auch im Ziel LID-Informationen bereitstellt, ist es unwahrscheinlich, dass das Modell in Richtungen, die im Training nicht vorkommen, eine gute Leistung bei Nullproben aufweist. Die Herausforderung besteht also darin, ein System zu entwickeln, das ein gewisses Maß an LID-Informationen berücksichtigt und gleichzeitig das Modell allgemein genug für die Sprachübersetzung in ungesehene Richtungen hält. Um dieses Problem zu lösen, haben wir System-Cues entwickelt, die nur LID-Informationen für den auszugebenden Text (Zielseite) enthalten. Diese Cues enthalten keine LID-Informationen für die Spracheingabe (Quellenseite), was auch den Umgang mit code-switching Sprache ermöglichen kann. Für ASR verwenden wir die folgende Systemaufforderung: Wiederhole meine Worte in {Sprache}:, wobei {Sprache} für eine der 34 Sprachen steht (Englisch, Französisch, etc.). Für die Sprachübersetzung lautet die Systemaufforderung: "Übersetze den folgenden Satz in {Sprache}:". Dieses Design hat sich als effektiv erwiesen, um Sprachmodelle dazu zu veranlassen, in der gewünschten Sprache zu antworten. Wir verwenden denselben Systemprompt während des Trainings und der Inferenz.
Wir verwenden den selbstüberwachten BEST-RQ-Algorithmus (Chiu et al., 2022) zum Vortraining von Sprache.
编码器采用长度为 32 帧的掩码,对输入 mel 谱图的概率为 2.5%。如果语音话语超过 60 秒,我们将随机裁剪 6K 帧,对应 60 秒的语音。通过堆叠 4 个连续帧、将 320 维向量投影到 16 维空间,并在 8192 个向量的代码库内使用余弦相似度度量进行最近邻搜索,对 mel 谱图特征进行量化。为了稳定预训练,我们采用 16 个不同的代码库。投影矩阵和代码库随机初始化,在模型训练过程中不更新。多软最大损失仅用于掩码帧,以提高效率。编码器经过 50 万步训练,全局批处理大小为 2048 个语音。
监督微调。预训练语音编码器和随机初始化的适配器在监督微调阶段与 Llama 3 联合优化。语言模型在此过程中保持不变。训练数据是 ASR、AST 和对话数据的混合。Llama 3 8B 的语音模型经过 650K 次更新训练,使用全局批大小为 512 个话语和初始学习率为 10。Llama 3 70B 的语音模型经过 600K 次更新训练,使用全局批大小为 768 个话语和初始学习率为 4 × 10。
8.3.2 Spracherzeugung
Um die Echtzeitverarbeitung zu unterstützen, verwendet das Reimmodell einen Vorausschau-Mechanismus, der eine feste Anzahl zukünftiger phonemischer Positionen und eine variable Anzahl zukünftiger Token berücksichtigt. Dies gewährleistet eine konsistente Vorausschau bei der Verarbeitung des eingehenden Textes, was für Sprachsyntheseanwendungen mit geringer Latenzzeit entscheidend ist.
Ausbildung. Wir entwickeln eine dynamische Ausrichtungsstrategie, die kausale Masken verwendet, um das Streaming der Sprachsynthese zu erleichtern. Die Strategie kombiniert einen Vorausschau-Mechanismus im prosodischen Modell für eine feste Anzahl zukünftiger Phoneme und eine variable Anzahl zukünftiger Token, in Übereinstimmung mit dem Chunking-Prozess im Textnormalisierungsprozess (Abschnitt 8.1.2).
Für jedes Phonem besteht der Marker-Look-Ahead aus der maximalen Anzahl von Markern, die durch die Blockgröße definiert ist, was zu Llama-Einbettungen mit variablem Look-Ahead und Phonemen mit festem Look-Ahead führt.
Llama 3 Einbettungen aus dem Llama 3 8B Modell, die während des Trainings des Reim-Modells eingefroren wurden. Die Merkmale der Eingangsgesprächsrate umfassen linguistische und Sprecher-/Stilkontrollierungselemente. Das Modell wird mit einem AdamW-Optimierer mit einer Stapelgröße von 1.024 Tönen und einer Lernrate von 9 × 10 -4 trainiert. Das Modell wird über 1 Million Aktualisierungen trainiert, wobei die ersten 3.000 Aktualisierungen eine Aufwärmphase für die Lernrate durchführen und dann dem Cosinus-Scheduling folgen.
Begründungen. Während der Inferenz werden derselbe Vorausschau-Mechanismus und dieselbe kausale Maskierungsstrategie verwendet, um die Konsistenz zwischen Training und Echtzeitverarbeitung zu gewährleisten. PM verarbeitet den eingehenden Text in einer Streaming-Methode, wobei die Eingaben Telefon für Telefon-Raten-Merkmale und Block für gelabelte Raten-Merkmale aktualisiert werden. Neue Blockeingaben werden nur dann aktualisiert, wenn das erste Telefon des Blocks aktuell ist, wodurch die Ausrichtung und Vorausschau während des Trainings beibehalten wird.
Zur Vorhersage von Reimzielen verwendeten wir einen Ansatz mit verzögertem Modus (Kharitonov et al., 2021), der die Fähigkeit des Modells verbessert, weitreichende Reimabhängigkeiten zu erfassen und zu replizieren. Dieser Ansatz trägt zur Natürlichkeit und Ausdruckskraft der synthetisierten Sprache bei und gewährleistet eine niedrige Latenz und eine hohe Qualität der Ausgabe.
8.4 Ergebnisse des Sprachverständnisses
Wir haben die Sprachverstehensfähigkeiten der Llama 3-Sprachschnittstelle für drei Aufgaben evaluiert: (1) Automatische Spracherkennung (2) Sprachübersetzung (3) Sprachabfragen. Wir verglichen die Leistung der Sprachschnittstelle von Llama 3 mit drei hochmodernen Sprachverstehensmodellen: Whisper (Radford et al., 2023), SeamlessM4T (Barrault et al., 2023) und Gemini.In allen Evaluierungen verwendeten wir die Greedy-Suche zur Vorhersage der Token von Llama 3.
Erkennung von Sprache. Wir haben die ASR-Leistung auf Multilingual LibriSpeech (MLS; Pratap et al., 2020), LibriSpeech (Panayotov et al., 2015), VoxPopuli (Wang et al., 2021a) und einer Teilmenge des mehrsprachigen FLEURS-Datensatzes (Conneau et al. 2023) auf den englischen Datensatz, um die ASR-Leistung zu bewerten. Bei der Bewertung wurde die Verwendung von Flüstern Das Textnormalisierungsverfahren verarbeitet die Dekodierungsergebnisse nach, um die Konsistenz mit den Ergebnissen anderer Modelle zu gewährleisten. Bei allen Benchmarks messen wir die Wortfehlerrate der Llama 3-Sprachschnittstelle mit dem Standardtestsatz dieser Benchmarks, außer für Chinesisch, Japanisch, Koreanisch und Thailändisch, wo wir die Zeichenfehlerraten angeben.
Tabelle 31 zeigt die Ergebnisse der ASR-Evaluierung. Sie zeigt die starke Leistung von Llama 3 (und multimodalen Basismodellen im Allgemeinen) bei Spracherkennungsaufgaben: Unser Modell übertrifft sprachspezifische Modelle wie Whisper20 und SeamlessM4T in allen Benchmarks. Für MLS-Englisch schneidet Llama 3 ähnlich gut ab wie Gemini.
Sprachübersetzung. Wir haben auch die Leistung unseres Modells in einer Sprachübersetzungsaufgabe bewertet, bei der das Modell nicht-englische Sprache in englischen Text übersetzen sollte. Für diese Evaluierungen haben wir die Datensätze FLEURS und Covost 2 (Wang et al., 2021b) verwendet und die BLEU-Scores für die englische Übersetzung gemessen. Tabelle 32 zeigt die Ergebnisse dieser Experimente. Die Leistung unseres Modells bei der Sprachübersetzung unterstreicht die Vorteile von multimodalen Basismodellen bei Aufgaben wie der Sprachübersetzung.
Stimmen-Quiz. Die Sprachschnittstelle von Llama 3 beweist erstaunliche Fähigkeiten bei der Beantwortung von Fragen. Das Modell kann mühelos codierte Sprache verstehen, ohne dass es vorher mit solchen Daten in Berührung gekommen ist. Obwohl das Modell nur für eine einzige Dialogrunde trainiert wurde, ist es in der Lage, ausgedehnte und kohärente Dialogsitzungen mit mehreren Runden zu führen. Abbildung 30 zeigt einige Beispiele, die diese Mehrsprachen- und Mehrrundenfähigkeiten verdeutlichen.
Sicherheit. Wir haben die Sicherheitsleistung unseres Sprachmodells anhand von MuTox (Costa-jussà et al., 2023) bewertet, einem Datensatz für mehrsprachige audiobasierte Datensätze, der 20.000 englische und spanische Segmente und 4.000 Segmente in 19 anderen Sprachen enthält, die jeweils mit einem Toxizitätskennzeichen versehen sind. Die Audiodaten werden dem Modell als Eingabe übergeben, und die Ausgabe wird nach dem Entfernen einiger Sonderzeichen auf Toxizität geprüft. Wir haben den MuTox-Klassifikator (Costa-jussà et al., 2023) auf Gemini 1.5 Pro angewendet und die Ergebnisse verglichen. Wir bewerteten den Prozentsatz der hinzugefügten Toxizität (AT), wenn die Eingabe sicher und die Ausgabe giftig ist, und den Prozentsatz der verlorenen Toxizität (LT), wenn die Eingabe giftig und die Antwort sicher ist. Tabelle 33 zeigt die Ergebnisse für Englisch und unsere durchschnittlichen Ergebnisse für alle 21 Sprachen. Der Prozentsatz der hinzugefügten Toxizität ist sehr niedrig: Unser Sprachmodell hat den niedrigsten Prozentsatz an hinzugefügter Toxizität für Englisch, weniger als 11 TP3T. es entfernt viel mehr Toxizität als es hinzufügt.

8.5 Ergebnisse der Spracherzeugung
Im Kontext der Spracherzeugung konzentrieren wir uns auf die Bewertung der Qualität markerbasierter Streaming-Eingabemodelle, die Llama 3-Vektoren für Textnormalisierungs- und Reim-Modellierungsaufgaben verwenden. Die Bewertung konzentriert sich auf Vergleiche mit Modellen, die keine Llama-3-Vektoren als zusätzliche Eingabe verwenden.
Textnormalisierung. Um die Auswirkungen des Llama-3-Vektors zu messen, haben wir versucht, die Menge des vom Modell verwendeten Kontextes auf der rechten Seite zu variieren. Wir trainierten das Modell mit einem Kontext auf der rechten Seite von 3 Textnormalisierungs-Tokens (getrennt durch Unicode-Kategorien). Dieses Modell wurde mit Modellen verglichen, die den Llama-3-Vektor nicht verwendeten und entweder den mit drei Tags versehenen Kontext auf der rechten Seite oder den vollständigen bidirektionalen Kontext nutzten. Wie erwartet, zeigt Tabelle 34, dass die Verwendung des vollständigen Kontextes auf der rechten Seite die Leistung des Modells ohne Llama-3-Vektoren verbessert. Das Modell mit Llama-3-Vektoren übertrifft jedoch alle anderen Modelle, da es ein markiertes Input/Output-Streaming ermöglicht, ohne sich auf lange Kontexte in der Eingabe verlassen zu müssen. Wir vergleichen Modelle mit und ohne Llama 3 8B Vektoren und unter Verwendung verschiedener Kontextwerte auf der rechten Seite.
Rhythmische Modellierung. Um die Leistung unseres Reim-Modells (PM) mit Llama 3 8B zu bewerten, haben wir zwei Sätze menschlicher Bewertungen durchgeführt, in denen Modelle mit und ohne Llama 3-Vektoren verglichen wurden. Die Bewerter hörten sich Beispiele aus verschiedenen Modellen an und gaben ihre Präferenzen an.
Um die endgültige Sprachwellenform zu generieren, verwendeten wir ein Transformer-basiertes internes akustisches Modell (Wu et al., 2021), das spektrale Merkmale vorhersagt, und einen neuronalen WaveRNN-Vocoder (Kalchbrenner et al., 2018), um die endgültige Sprachwellenform zu erzeugen.
Im ersten Test wird ein direkter Vergleich mit dem Streaming-Benchmark-Modell ohne Verwendung von Llama-3-Vektoren vorgenommen. Im zweiten Test wurde das Llama 3 8B PM mit einem Nicht-Streaming-Benchmark-Modell verglichen, das keine Llama 3-Vektoren verwendet. Wie aus Tabelle 35 hervorgeht, wurde das Llama 3 8B PM für 60% der Zeit (im Vergleich zum Streaming-Benchmark) und für 63,6% der Zeit (im Vergleich zum Non-Streaming-Benchmark) bevorzugt, was auf eine signifikante Verbesserung der Wahrnehmungsqualität hindeutet. Der Hauptvorteil von Llama 3 8B PM ist seine markerbasierte Streaming-Fähigkeit (Abschnitt 8.2.2), die eine niedrige Latenzzeit während des Inferenzprozesses gewährleistet. Dies reduziert die Look-Ahead-Anforderungen des Modells und ermöglicht eine reaktionsschnellere Sprachsynthese in Echtzeit im Vergleich zum Benchmark-Modell ohne Streaming. Insgesamt übertrifft das Llama 3 8B Reim-Modell das Benchmark-Modell durchweg, was seine Effektivität bei der Verbesserung der Natürlichkeit und Ausdruckskraft der synthetisierten Sprache beweist.




9 Verwandte Arbeiten
Die Entwicklung von Llama 3 stützt sich auf eine Vielzahl früherer Forschungsarbeiten zu grundlegenden Modellen für Sprache, Bild, Video und Sprache. Der Umfang dieses Papiers umfasst keinen umfassenden Überblick über diese Arbeiten; wir verweisen den Leser auf Bordes et al. (2024); Madan et al. (2024); Zhao et al. (2023a) für einen solchen Überblick. Im Folgenden geben wir einen kurzen Überblick über die bahnbrechenden Arbeiten, die die Entwicklung von Llama 3 direkt beeinflusst haben.
9.1 Sprache
Umfang. Llama 3 folgt dem anhaltenden Trend der Anwendung einfacher Methoden auf immer größere Maßstäbe, die das Basismodell kennzeichnen. Die Verbesserungen sind auf eine Steigerung der Rechenleistung und der Datenqualität zurückzuführen, wobei das 405B-Modell fast das Fünfzigfache des Rechenbudgets vor dem Training von Llama 2 (70B) benötigt. Obwohl unser größtes Llama 3 405B Parameter enthält, hat es aufgrund eines besseren Verständnisses der Skalierungsgesetze (Kaplan et al., 2020; Hoffmann et al., 2022) tatsächlich weniger Parameter als frühere und leistungsschwächere Modelle wie PALM (Chowdhery et al., 2023). Andere Grenzmodelle sind in Größen wie Claude 3 oder GPT 4 (OpenAI, 2023a) verfügbar, mit begrenzten öffentlichen Informationen, aber mit vergleichbarer Gesamtleistung.
Modelle im kleinen Maßstab. Die Entwicklung von Modellen in kleinem Maßstab ging Hand in Hand mit der Entwicklung von Modellen in großem Maßstab. Modelle mit weniger Parametern können die Kosten für Schlussfolgerungen erheblich senken und den Einsatz vereinfachen (Mehta et al., 2024; Team et al., 2024). Das kleinere Llama-3-Modell erreicht dies, indem es die rechnerisch optimalen Trainingspunkte bei weitem übertrifft und so die Trainingsberechnung gegen die Inferenz-Effizienz tauscht. Ein anderer Weg ist die Aufteilung größerer Modelle in kleinere, wie z. B. Phi (Abdin et al., 2024).
Architektur. Im Vergleich zu Llama 2 weist Llama 3 nur minimale architektonische Änderungen auf, aber andere neuere Basismodelle haben alternative Designs erforscht. Vor allem hybride Expertenarchitekturen (Shazeer et al. 2017; Lewis et al. 2021; Fedus et al. 2022; Zhou et al. 2022) können zur effizienten Steigerung der Kapazität eines Modells verwendet werden, wie z. B. in Mixtral (Jiang et al. 2024) und Arctic (Snowflake 2024). Die Leistung von Llama 3 übertrifft diese Modelle, was darauf hindeutet, dass dichte Architekturen kein begrenzender Faktor sind, dass es aber immer noch viele Kompromisse in Bezug auf Training und Inferenz-Effizienz sowie die Modellstabilität auf großen Skalen gibt.
Offene Quelle. Open-Source-Basismodelle haben sich im vergangenen Jahr rasch weiterentwickelt, wobei Llama3-405B inzwischen mit dem aktuellen Stand der Technik bei geschlossenen Quellen vergleichbar ist. In letzter Zeit wurde eine Reihe von Modellfamilien entwickelt, darunter Mistral (Jiang et al., 2023), Falcon (Almazrouei et al., 2023), MPT (Databricks, 2024), Pythia (Biderman et al., 2023), Arctic (Snowflake, 2024), OpenELM (Mehta et al., 2024), OLMo (Groeneveld et al., 2024), StableLM (Bellagente et al., 2024), OpenLLaMA (Geng und Liu, 2023), Qwen (Bai et al., 2023), Gemma (Team et al., 2024), Grok (Biderman et al., 2023) und Gemma (Biderman et al., 2024). 2024), Grok (XAI, 2024) und Phi (Abdin et al., 2024).
Nach der Ausbildung. Das Post-Training für Llama 3 folgt einer etablierten Strategie zum Abgleich von Anweisungen (Chung et al., 2022; Ouyang et al., 2022), gefolgt von einem Abgleich mit menschlichem Feedback (Kaufmann et al., 2023). Während einige Studien unerwartete Ergebnisse mit leichtgewichtigen Abgleichverfahren gezeigt haben (Zhou et al., 2024), verwendet Llama 3 Millionen menschlicher Instruktionen und Präferenzurteile, um die vortrainierten Modelle zu verbessern, einschließlich Ablehnungsstichproben (Bai et al., 2022), überwachte Feinabstimmung (Sanh et al., 2022) und direkte Präferenzoptimierung (Rafailov et al., 2023). Um diese Anweisungs- und Präferenzbeispiele zu kuratieren, setzten wir frühere Versionen von Llama 3 zum Filtern (Liu et al., 2024c), Umschreiben (Pan et al., 2024) oder Generieren von Hinweisen und Antworten (Liu et al., 2024b) ein und wendeten diese Techniken in mehreren Runden des Post-Trainings an.
9.2 Multimodalität
Unsere Llama-3-Experimente zu multimodalen Fähigkeiten sind Teil einer Langzeitstudie zu grundlegenden Modellen für die gemeinsame Modellierung mehrerer Modalitäten. Unser Llama-3-Ansatz kombiniert Ideen aus einer Reihe von Arbeiten, um Ergebnisse zu erzielen, die mit Gemini 1.0 Ultra (Google, 2023) und GPT-4 Vision (OpenAI, 2023b) vergleichbar sind; siehe Abschnitt 7.6.
VideoTrotz der wachsenden Anzahl von Basismodellen, die Videoeingabe unterstützen (Google, 2023; OpenAI, 2023b), wurde bisher nicht viel Forschung zur gemeinsamen Modellierung von Video und Sprache betrieben. Ähnlich wie bei Llama 3 verwenden die meisten aktuellen Forschungsarbeiten Adaptermethoden, um Video- und Sprachrepräsentationen abzugleichen und Fragen und Antworten sowie Schlussfolgerungen über Video zu entschlüsseln (Lin et al. 2023; Li et al. 2023a; Maaz et al. 2024; Zhang et al. 2023; Zhao et al. 2022). Wir stellen fest, dass solche Methoden Ergebnisse liefern, die mit dem Stand der Technik konkurrieren können; siehe Abschnitt 7.7.
umgangssprachliche (und nicht literarische) Aussprache eines chinesischen SchriftzeichensUnsere Arbeit fügt sich auch in einen größeren Bestand an Arbeiten ein, die Sprach- und Sprachmodellierung kombinieren. Zu den frühen gemeinsamen Text- und Sprachmodellen gehören AudioPaLM (Rubenstein et al., 2023), VioLA (Wang et al., 2023b), VoxtLM Maiti et al. (2023), SUTLM (Chou et al., 2023) und Spirit-LM (Nguyen et al., 2024) . Unsere Arbeit baut auf früheren kompositorischen Ansätzen zur Kombination von Sprache und Sprache auf, wie z. B. Fathullah et al. (2024). Im Gegensatz zu den meisten dieser früheren Arbeiten haben wir auf eine Feinabstimmung des Sprachmodells für die Sprachaufgabe verzichtet, da dies zu einer Konkurrenz durch nichtsprachliche Aufgaben führen könnte. Wir haben festgestellt, dass auch ohne eine solche Feinabstimmung eine gute Leistung bei größeren Modellgrößen erzielt werden kann; siehe Abschnitt 8.4.
10 Schlussfolgerung
Die Entwicklung von qualitativ hochwertigen Basismodellen befindet sich noch in einem frühen Stadium. Unsere Erfahrungen bei der Entwicklung von Llama 3 deuten darauf hin, dass es noch viel Raum für zukünftige Verbesserungen dieser Modelle gibt. Bei der Entwicklung der Llama 3-Modellfamilie haben wir festgestellt, dass ein starker Fokus auf hochwertige Daten, Skalierung und Einfachheit durchweg zu den besten Ergebnissen führt. In ersten Experimenten haben wir komplexere Modellarchitekturen und Trainingsszenarien erprobt, konnten aber nicht feststellen, dass die Vorteile dieser Ansätze die zusätzliche Komplexität, die sie bei der Modellentwicklung mit sich bringen, aufwiegen.
Die Entwicklung eines Vorzeige-Basismodells wie Llama 3 erfordert nicht nur die Überwindung vieler tiefgreifender technischer Probleme, sondern auch fundierte organisatorische Entscheidungen. Um zum Beispiel sicherzustellen, dass Llama 3 nicht versehentlich zu stark an die gängigen Benchmark-Tests angepasst wird, werden unsere Pre-Training-Daten von einem unabhängigen Team beschafft und verarbeitet, das einen starken Anreiz hat, externe Benchmark-Tests nicht mit Pre-Training-Daten zu kontaminieren. Ein weiteres Beispiel ist, dass wir die Glaubwürdigkeit menschlicher Bewertungen sicherstellen, indem wir nur einer kleinen Gruppe von Forschern, die nicht an der Modellentwicklung beteiligt sind, erlauben, diese Bewertungen durchzuführen und darauf zuzugreifen. Diese organisatorischen Entscheidungen werden zwar selten in Fachzeitschriften erörtert, wir haben sie jedoch als entscheidend für die erfolgreiche Entwicklung der Llama 3-Modellfamilie angesehen.
Wir teilen Details unseres Entwicklungsprozesses, da wir glauben, dass dies der breiteren Forschungsgemeinschaft helfen wird, die Schlüsselelemente der Basismodellentwicklung zu verstehen und zu einer aufschlussreichen öffentlichen Diskussion über die zukünftige Entwicklung von Basismodellen beizutragen. Wir teilen auch erste experimentelle Ergebnisse der Integration multimodaler Funktionen in Llama 3. Diese Modelle befinden sich zwar noch in der aktiven Entwicklung und sind noch nicht zur Veröffentlichung bereit, aber wir hoffen, dass die frühzeitige Veröffentlichung unserer Ergebnisse die Forschung in dieser Richtung beschleunigen wird.
Angesichts der positiven Ergebnisse der in diesem Papier beschriebenen Sicherheitsanalysen veröffentlichen wir unser Sprachmodell Llama 3, um den Prozess der Entwicklung von KI-Systemen für ein breites Spektrum gesellschaftlich relevanter Anwendungsfälle zu beschleunigen und um der Forschungsgemeinschaft die Möglichkeit zu geben, unsere Modelle zu überprüfen und Wege zu finden, sie besser und sicherer zu machen. Wir glauben, dass die Veröffentlichung der zugrundeliegenden Modelle für die verantwortungsvolle Entwicklung solcher Modelle von entscheidender Bedeutung ist, und hoffen, dass die Veröffentlichung von Llama 3 die gesamte Branche dazu ermutigen wird, eine offene, verantwortungsvolle KI-Entwicklung anzustreben.