Kürzlich entdeckte ich ein aufsehenerregendes einheimisches Open-Source-KI-Wissensbasis-Framework: KAG (Knowledge Augmented Generation).
KAG Sie wurde gemeinsam von der Ant Group, der Zhejiang University und vielen anderen Organisationen ins Leben gerufen und konzentriert sich auf den Aufbau von Wissensgrundlagen in vertikalen Bereichen. Die Daten des Papiers zeigen, dass die KAG im Bereich E-Government die 91.6%s beeindruckende Trefferquoteeignet sich auch hervorragend für Szenarien wie Fragen und Antworten im Bereich der elektronischen Gesundheitsfürsorge.
Dieser Artikel gibt Ihnen einen detaillierten Einblick in KAG Prinzip, Anwendungsszenarien, Vergleich RAG Der Artikel enthält außerdem lokale Installationsanleitungen und Demos, die Ihnen einen umfassenden Eindruck vom KAG-Framework vermitteln, das von Ant als Open Source bereitgestellt wird. Wenn Sie planen, KI für den Aufbau Ihrer eigenen Wissensdatenbank zu nutzen, sollten Sie sich diesen Artikel nicht entgehen lassen!
Was ist KAG? Kernkonzepte für eine neue Generation von Wissensbasis-Rahmenwerken
KAG (Knowledge Augmented Generation) ist ein inferentielles Frage- und Antwortsystem, das auf der OpenSPG-Engine und Large Language Models (LLMs) basiert. Seine Kernkonzepte sindDurch die Kombination der doppelten Vorteile von Wissensgraphen und Vektor-Retrieval sollen den Nutzern genauere Entscheidungshilfen und präzisere Informationsabrufe geboten werden.
KAG ermöglicht eine tiefgreifende Fusion und Verbesserung von LLM und Knowledge Graph durch die folgenden vier Schlüsseltechnologien:
- Kenntnis der LLM-freundlichen VertretungOptimieren Sie die Struktur von Wissensgraphen, um sie für große Sprachmodelle leichter verständlich und nutzbar zu machen.
- Querindizierung zwischen Wissensgraphen und ursprünglichen TextfragmentenErstellung von bidirektionalen Verknüpfungen zwischen Entitäten und Beziehungen im Wissensgraphen und den ursprünglichen Textfragmenten, um die Effizienz und Genauigkeit der Suche zu verbessern.
- Logische formgeleitete hybride SchlussfolgerungsmaschineKombinieren Sie die logische Denkleistung des Knowledge Graph mit der semantischen Verstehensleistung des LLM, um komplexere Denkquizze zu erhalten.
- Wissensabgleich mit Semantic ReasoningDie Wissensgraphen müssen mit dem semantischen Raum des Sprachmodells abgeglichen werden, um die Effektivität der Wissensnutzung zu erhöhen.
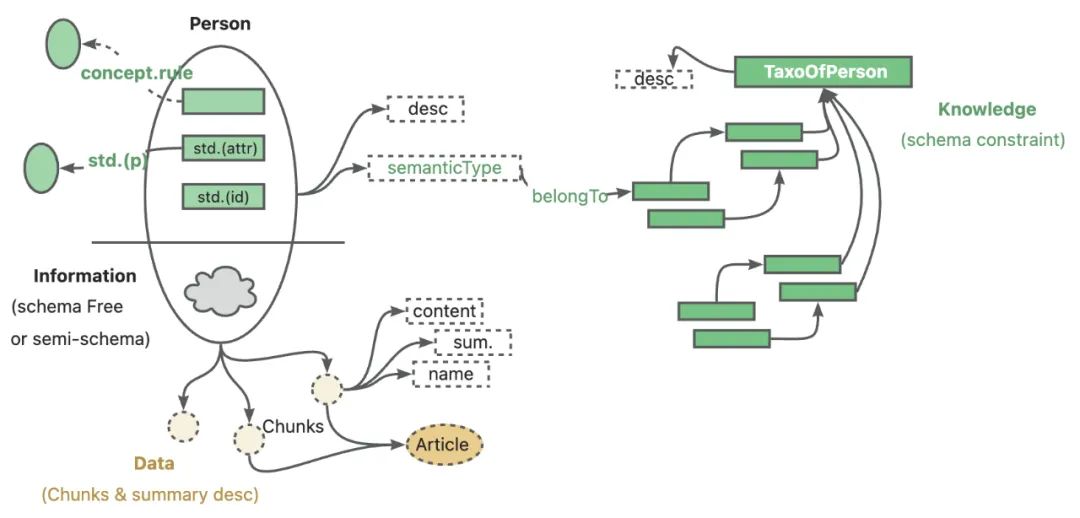
Kurz gesagt, KAG kombiniert auf innovative Weise die Vorteile von Knowledge Graph und Vector Retrieval, um eine leistungsstarke Wissensbasis zu schaffen. Es kann nicht nur die logischen Schlussfolgerungen des LLM nutzen, sondern diese auch mit dem Wissensgraphen kombinieren, um komplexe Aufgaben der Informationsbeschaffung zu lösen. Wenn die Informationen des Wissensgraphen unzureichend sind, kann KAG auch die Vektor-Retrieval-Technologie nutzen, um relevante Textfragmente zu ergänzen und so die Vollständigkeit und Genauigkeit der Antworten zu gewährleisten.
Überblick über die Gesamtarchitektur der KAG
Der KAG-Rahmen besteht aus zwei Kernmodulen: Wissensaufbau (kg-builder) und Problemlösung (kg-solver).
- kg-builder Das Modul konzentriert sich auf die effiziente Konstruktion von Wissen, die Optimierung der Wissensrepräsentation für LLM und die Unterstützung flexibler Wissensmodellierung und bidirektionaler Indexierung.
- kg-löser Das Modul ist dann für die effiziente Problemlösung zuständig, die durch eine hybride Logik-Engine erreicht wird, die mehrere Fähigkeiten wie Abfragen, grafische Logik, linguistische Logik und numerische Berechnungen integriert, um komplexe Probleme zu lösen.
- Das dritte Modul, kag-model, wird als Open Source zur weiteren Verbesserung des KAG-Rahmens zur Verfügung gestellt.
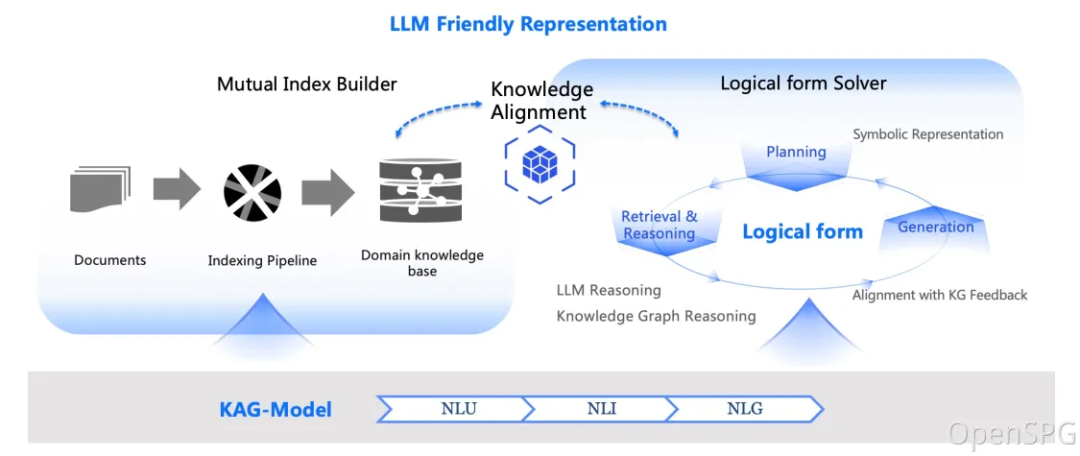
KAG vs. traditionelle RAG: Unterschiede und Vorteile erklärt
RAG (Retrieval-Augmented Generation) ist eine weit verbreitete Technologie für Wissensdatenbanken. Was sind nun die Unterschiede und Vorteile von KAG gegenüber RAG? Wir vergleichen und analysieren sie anhand der folgenden Dimensionen:
1. die Darstellung von Wissen:
- RAG. Es stützt sich hauptsächlich auf Vektorähnlichkeit für die Suche, und die Wissensrepräsentation ist relativ einfach, was es schwierig macht, komplexe Probleme zu behandeln, die Multi-Hop-Reasoning erfordern.
- KAG. Annahme einer Wissensdarstellung, die LLM-freundlicher ist, mit schemafreiem und schemagebundenem Wissen kompatibel ist, eine interindizierte Struktur von graphenstrukturiertem Wissen und textuellem Wissen unterstützt und eine reichhaltigere und strukturiertere Wissensdarstellung bietet.
2. die Fähigkeit zum logischen Denken:
- RAG. Unempfindlichkeit gegenüber den logischen Zusammenhängen des Wissens und mangelnde Fähigkeit zum logischen Denken, um Probleme in Fachbereichen zu bewältigen, die komplexes Denken erfordern.
- KAG. Einführung einer logisch-symbolgesteuerten hybriden Argumentationsmaschine mit leistungsstarken logischen Schlussfolgerungen und Multi-Hop-Faktenquiz-Fähigkeiten zur Bewältigung komplexerer beruflicher Probleme.
3. die Leistung:
- RAG. Schlechte Leistungen bei Multi-Hop-Aufgaben und passagenübergreifenden Aufgaben, wobei der Text relativ wenig kohärent und logisch ist.
- KAG. Es zeigt gute Leistungen bei Multi-Hop- und Cross-Passage-Aufgaben, verbessert die Genauigkeit der Schlussfolgerungen und die Informationsabdeckung erheblich und erzeugt genauere und umfassendere Antworten.
4. anwendbare Szenarien:
- RAG. Es eignet sich besser für allgemeine Aufgaben der Texterstellung und -suche, ist aber in Fachgebieten wie Recht, Medizin und Wissenschaft, in denen komplexe Schlussfolgerungen erforderlich sind, nur begrenzt leistungsfähig.
- KAG. Besonders geeignet für Anwendungen, die komplexes logisches Denken erfordern, und für Faktenquizze mit mehreren Stationen. Bereich der ExpertiseDas Unternehmen ist in der Lage, professionellere und genauere Wissensdienste anzubieten, z. B. in den Bereichen Finanzen, Medizin, Recht und Behörden.
Alles in allem zeigt KAG durch die Verschmelzung von Knowledge Graph und Vector Retrieval und die tiefgreifende Optimierung der Wissensrepräsentation und der Schlussfolgerungsfähigkeiten das Potenzial, die traditionelle RAG-Technologie bei der Bewältigung komplexer Probleme und der Abfrage von domänenspezifischem Wissen zu übertreffen.
Lokaler Einsatz von "Feed-Level"-Tutorials: KAG-Installation, Nutzung, Wirkung der Demo
Theoretische Analysen brauchen schließlich praktische Tests! Als Nächstes zeige ich Ihnen, wie Sie KAG installieren, einsetzen und lokal von Hand verwenden können.
KAG-bezogene Ressourcen:
- Github-Adresse.https://github.com/OpenSPG/KAG
- Offizielle Website.https://spg.openkg.cn/
Empfehlungen für die Hardware-Konfiguration:
- CPU ≥ 8 Kerne
- Speicher RAM ≥ 32 GB
- Festplatte ≥ 100 GB
Die offiziell empfohlene Konfiguration ist hoch, aber nach meinem aktuellen Test kann es im Grunde problemlos auf einem Windows-PC mit 16 GB RAM laufen. Daher wird dieses Tutorial die Installation und Verwendung von KAG in einer Windows-Umgebung demonstrieren.
Schritt 1: Docker Desktop installieren
Die Installation und Bereitstellung von KAG basiert auf einer Docker-Umgebung. Stellen Sie daher sicher, dass Sie Docker Desktop auf Ihrem Computer installiert haben.
Schritt 2: Erstellen Sie die Datei docker-compose.yml
- Erstellen Sie einen Ordner namens KAG im Stammverzeichnis Ihres Laufwerks D (oder eines anderen Datenträgers).
- Erstellen Sie im KAG-Ordner eine neue Datei namens docker-compose.yml.
- Kopieren Sie den folgenden YAML-Code, fügen Sie ihn in die Datei docker-compose.yml ein und speichern Sie sie.
Version: "3.7"
Dienste.
Server.
Neustart: immer
Bild: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-server:latest
container_name: freigabe-openspg-server
ports.
- "8887:8887"
depends_on.
- mysql
- neo4j
- minio
#-Volumes.
# - /etc/localtime:/etc/localtime:ro
Umgebung: /etc/localtime:/etc/localtime:ro
TZ: Asien/Schanghai
LANG: C.UTF-8
Befehl: [
"java",
"-Dfile.encoding=UTF-8",
"-Xms2048m",
"-Xmx8192m",
"-jar".
"arks-sofaboot-0.0.1-SNAPSHOT-executable.jar",
'---server.repository.impl.jdbc.host=mysql',
'--server.repository.impl.jdbc.password=openspg',
'---builder.model.execute.num=5',
'--cloudext.graphstore.url=neo4j://release-openspg-neo4j:7687?user=neo4j&password=neo4j@openspg&database=neo4j', '--cloudext.graphstore.url=neo4j://release-openspg-neo4j:7687?
' --cloudext.searchengine.url=neo4j://release-openspg-neo4j:7687?user=neo4j&password=neo4j@openspg&database=neo4j'
]
mysql.
Neustart: immer
Bild: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-mysql:latest
container_name: freigabe-openspg-mysql
Datenträger: mysql_data:release-openspg-mysql:latest
- mysql_data:/var/lib/mysql
Umgebung: mysql_data:/var/lib/mysql
TZ: Asien/Schanghai
LANG: C.UTF-8
MYSQL_ROOT_PASSWORD. openspg
MYSQL_DATENBANK: openspg
Ports.
- "3306:3306"
Befehl: [
--character-set-server=utf8mb4',
'--collation-server=utf8mb4_general_ci'
]
neo4j.
Neustart: immer
Bild: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-neo4j:latest
container_name: freigabe-openspg-neo4j
ports.
- "7474:7474"
- "7687:7687"
Umgebung.
- TZ=Asien/Schanghai
- NEO4J_AUTH=neo4j/neo4j@openspg
- NEO4J_PLUGINS=["apoc"]
- NEO4J_server_memory_heap_initial__size=1G
- NEO4J_server_speicher_heap_max__size=4G
- NEO4J_server_speicher_pagecache_größe=1G
- NEO4J_apoc_export_file_enabled=true
- NEO4J_apoc_import_file_enabled=true
- NEO4J_dbms_security_procedures_unrestricted=*
- NEO4J_dbms_security_procedures_allowlist=*
NEO4J_dbms_security_procedures_unrestricted
- neo4j_logs:/logs
- neo4j_data:/data
minio.
Bild: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-minio:latest
container_name: freigabe-openspg-minio
Befehl: server --Konsole-Adresse ":9001" /data
Neustart: immer
Umgebung: MINIO_ACCESS_KNOWLEDGE
MINIO_ACCESS_KEY: minio
MINIO_SECRET_KEY: minio@openspg
TZ: Asien/Schanghai
TZ: Asien/Schanghai
- 9000:9000
- 9001:9001
Datenträger: minio_data:/data
- minio_data:/data
Datenträger: minio_data:/data
mysql_data.
neo4j_logs.
minio_data: minio_data:/data Volumes: mysql_data.
minio_data.
Schritt 3: Starten Sie den KAG-Dienst
- Öffnen Sie eine Eingabeaufforderung und wechseln Sie in das Verzeichnis des KAG-Ordners (geben Sie cmd in das Adressfeld des KAG-Ordners ein und bestätigen Sie).
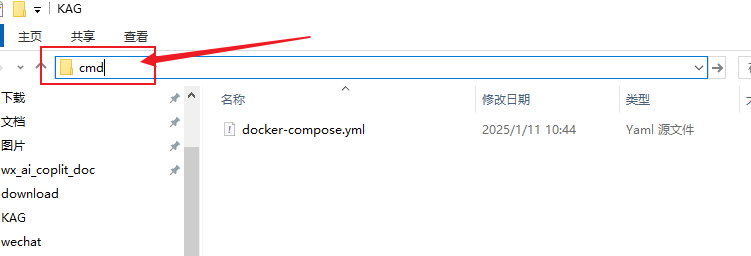
- Geben Sie docker-compose up -d in die Befehlszeile ein und bestätigen Sie, um die automatische Installation und Bereitstellung von KAG zu starten.
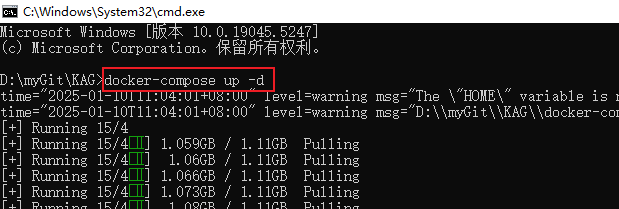
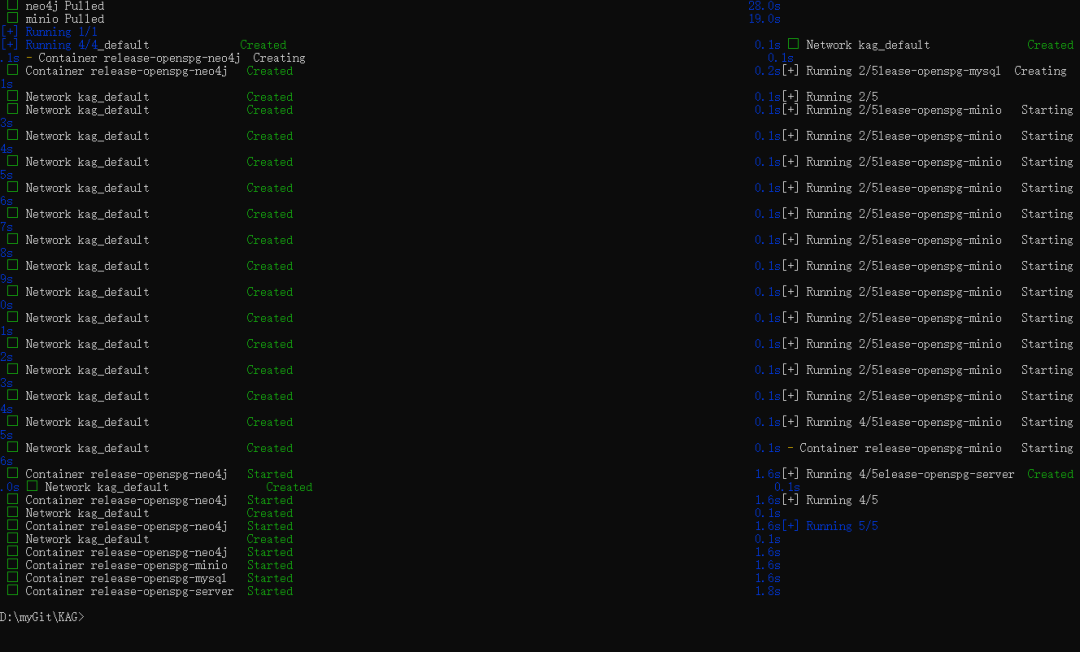
- Warten Sie einige Zeit. Wenn Sie sehen, dass die vier Dienste mysql, neo4j, openspg-server und minio den Status Created oder Started haben, bedeutet dies, dass der KAG-Dienst erfolgreich gestartet wurde.
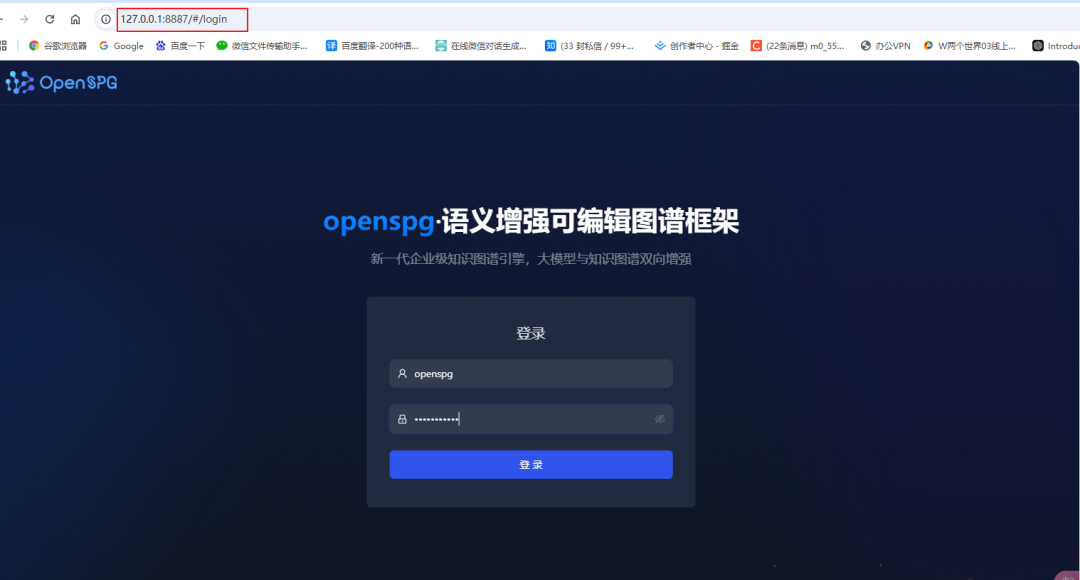
Schritt 4: Besuchen Sie die KAG-Backend-Administrationsseite
- Öffnen Sie Ihren Browser und geben Sie die Adresse 127.0.0.1:8887 ein, um die KAG-Hintergrundbetriebsseite aufzurufen.
- Melden Sie sich mit dem Standardbenutzernamen openspg und dem Standardkennwort openspg@kag am System an.
Schritt 5: Konfigurieren Sie das KAG-System
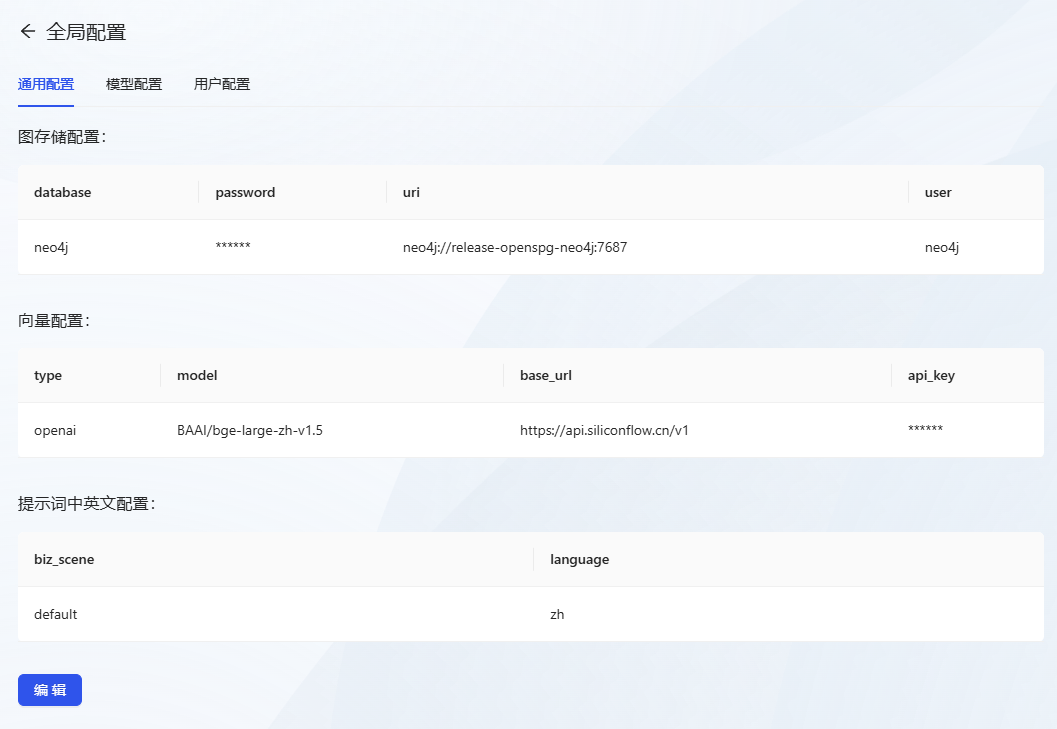
- Klicken Sie nach dem Einloggen zunächst auf das Menü Globale Konfiguration.
- Gemeinsame KonfigurationKonfiguration: Führen Sie die folgende Konfiguration durch
- Abbildung Speicherkonfiguration
- Datenbank:neo4j
- Kennwort: neo4j@openspg
- uri:neo4j://release-openspg-neo4j:7687
- benutzer:neo4j
- Stichwörter auf Englisch und Chinesisch
- biz_scene: Standard
- Sprache: zh
- Vektorielle Konfiguration (Rechnen) (unter Verwendung der kostenlosen Vektormodellierungs-API)
- Typ: openai
- Modell: BAAI/bge-large-zh-v1.5
- base_url:https://api.siliconflow.cn/v1
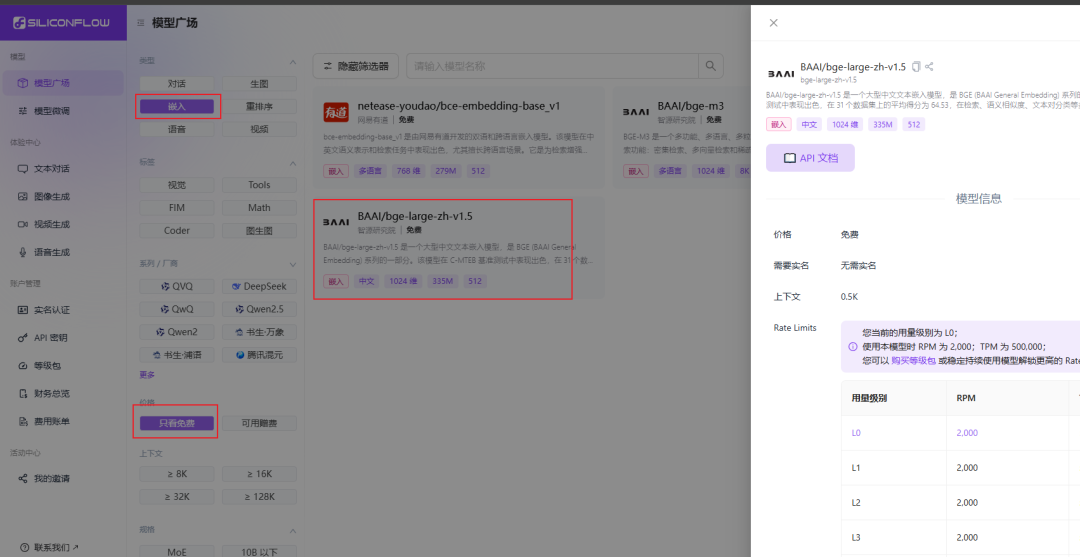
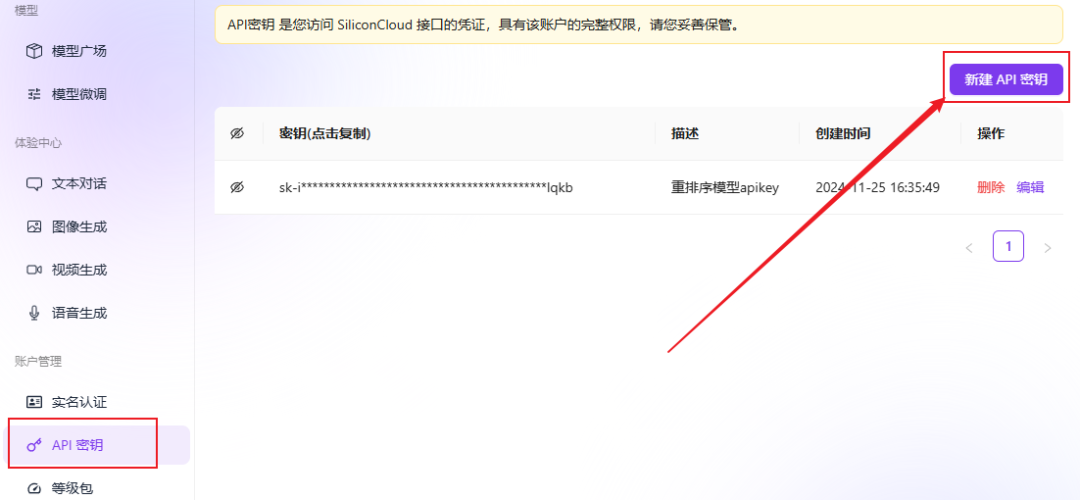
- api_key: weiter zu Durchfluss auf Siliziumbasis Plattform, um einen kostenlosen API-Schlüssel zu erhalten.
- Durchfluss auf Siliziumbasis Nach der Registrierung und Anmeldung bei der Plattform können Sie das kostenlose Vektormodell finden und einen API-Schlüssel erstellen, indem Sie die Richtlinien in der Abbildung unten befolgen.
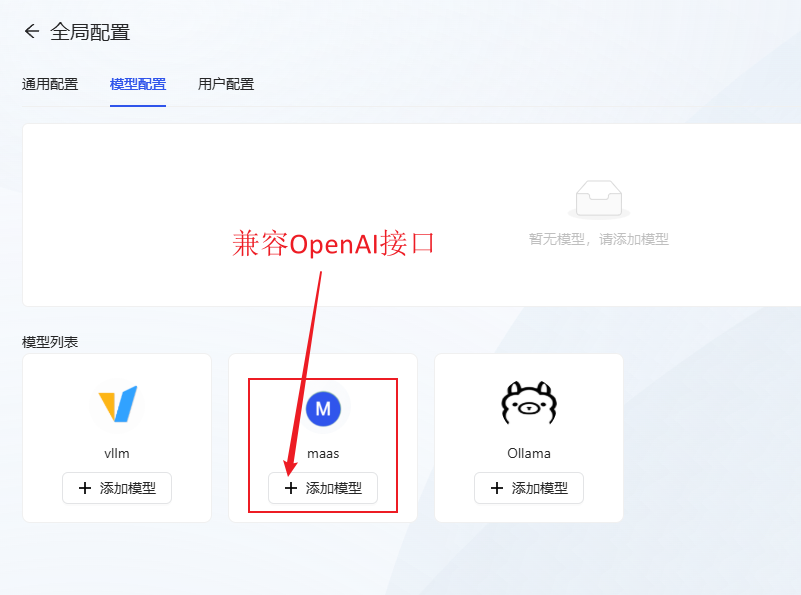
- Modell Konfiguration: Klick Hinzufügen des maas-Modells (kompatibel mit der openai-Schnittstelle)konfigurieren Sie das große Sprachmodell, das Sie verwenden möchten.
- Nehmen Sie gpt-4o als Beispiel, geben Sie die Modellinformationen ein und klicken Sie zum Speichern auf OK.
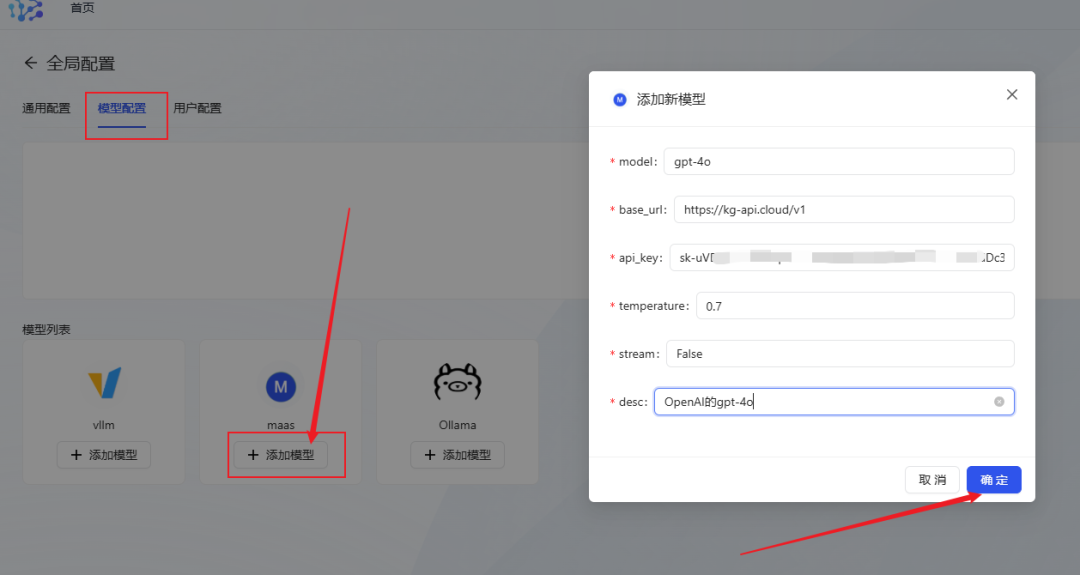
- Modell der API-Relaisstation EmpfehlungWenn Sie eine Vielzahl von API-Aufrufen für große Modelle benötigen, können Sie den API-Transitservice in Betracht ziehen, der mit der OpenAI-Schnittstelle kompatibel ist, den Wechsel zwischen inländischen und ausländischen Mainstream-Großmodellen mit einem Klick unterstützt und MJ-, SD- und Suno und andere Schnittstellen zum Zeichnen und Musikmachen. Auch der Preis ist günstiger.
Schritt 6: Erstellen einer Wissensdatenbank und Importieren von Dokumenten
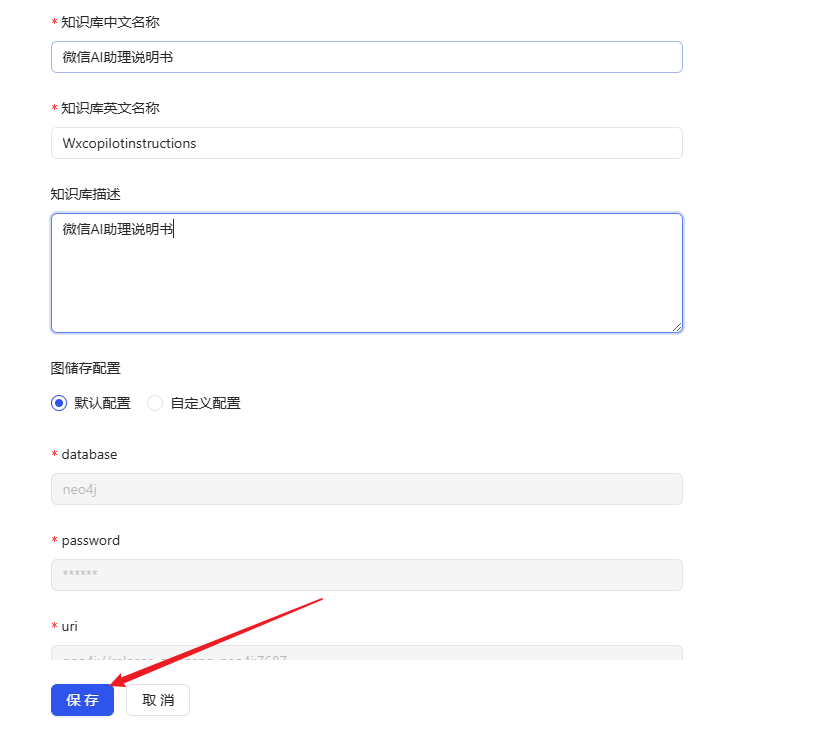
- Kehren Sie zur Startseite zurück und klicken Sie auf Wissensdatenbank erstellen.

- Benennen Sie die Wissensdatenbank und klicken Sie auf Speichern.
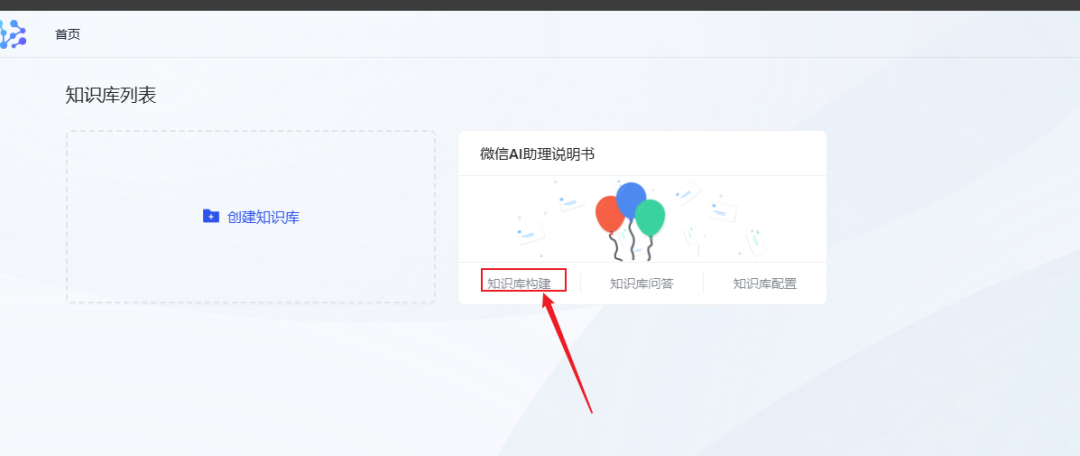
- Nach erfolgreicher Erstellung finden Sie die neu erstellte Wissensbasis auf der Startseite und klicken auf Wissensbasis erstellen.
- Klicken Sie auf Aufgabe erstellen, um mit dem Import von Dokumenten zu beginnen.
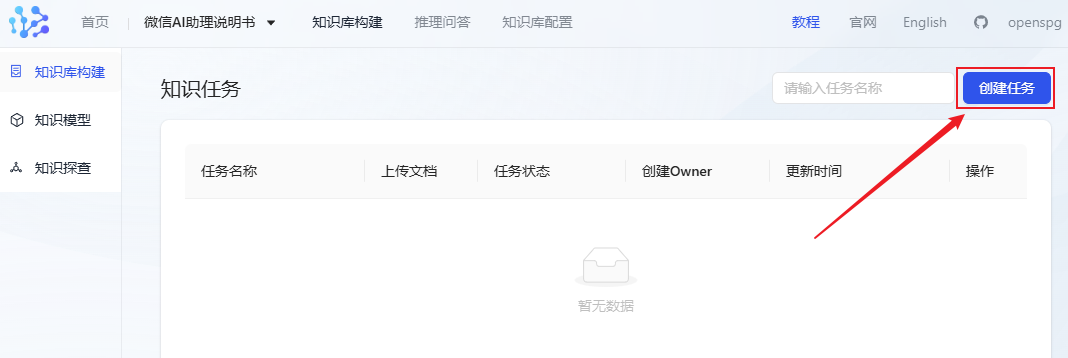
- Laden Sie Ihre Knowledge-Base-Dokumente hoch (derzeit unterstützt KAG nur das Hochladen eines Dokuments auf einmal, wenn Sie mehrere Dokumente haben, müssen Sie diese in Stapeln hochladen). Hier habe ich Dokumente hochgeladen, die sich auf mein neuestes Produkt, den WeChat AI Assistant, beziehen.
- Aufruf zur gemeinsamen Nutzung von File Merge ToolsWenn Sie ein gutes kostenloses Tool zur Dateifusion kennen, teilen Sie es bitte im Kommentarbereich mit, um die Stapelverarbeitung von Dokumenten zu erleichtern.
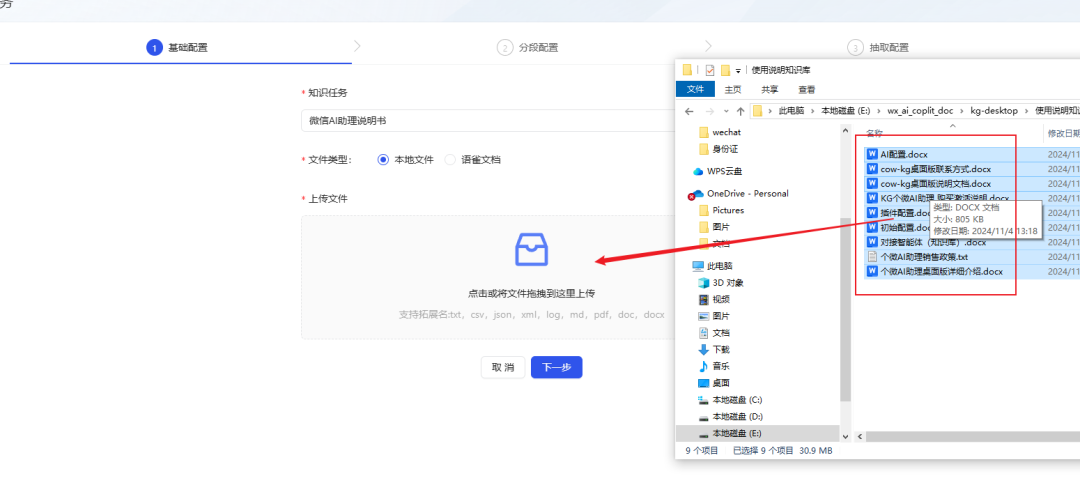
- Im nächsten Schritt der Einrichtung wird empfohlen, das Kontrollkästchen Absätze nach der Semantik des Dokuments aufteilen zu aktivieren, um die kontextuelle Kohärenz der Absätze zu erhalten.
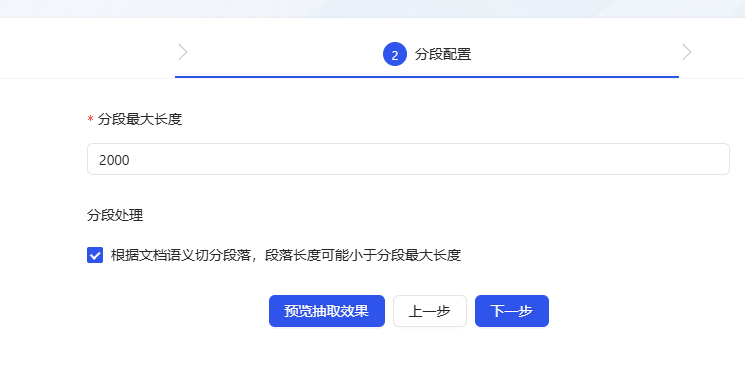
- Extraktionsmodell Option Standard (die Standardkonfiguration ist in Ordnung). Hinweis Sie kann nach Bedarf angepasst werden, hier habe ich sie einfach auf "Q&A Split" eingestellt (das Verständnis ist nicht immer genau, Sie können mich gerne korrigieren).
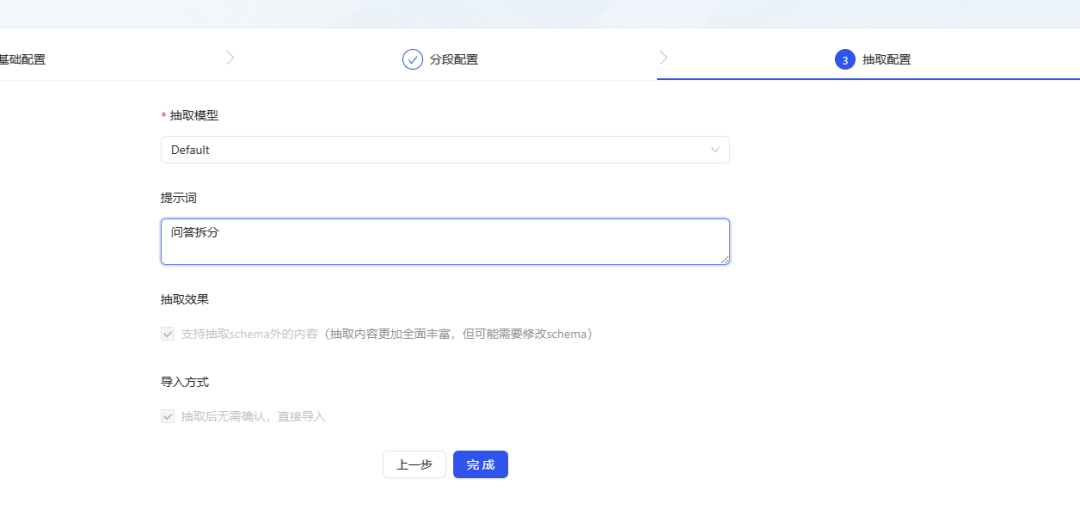
- Klicken Sie auf Fertig stellen und das KAG beginnt mit dem Extrahieren und Parsen der Dokumente, was einige Zeit dauern kann.
- Der Prozess des Parsens von Dokumenten ist in 6 Schritte unterteilt, wie in der folgenden Abbildung dargestellt:
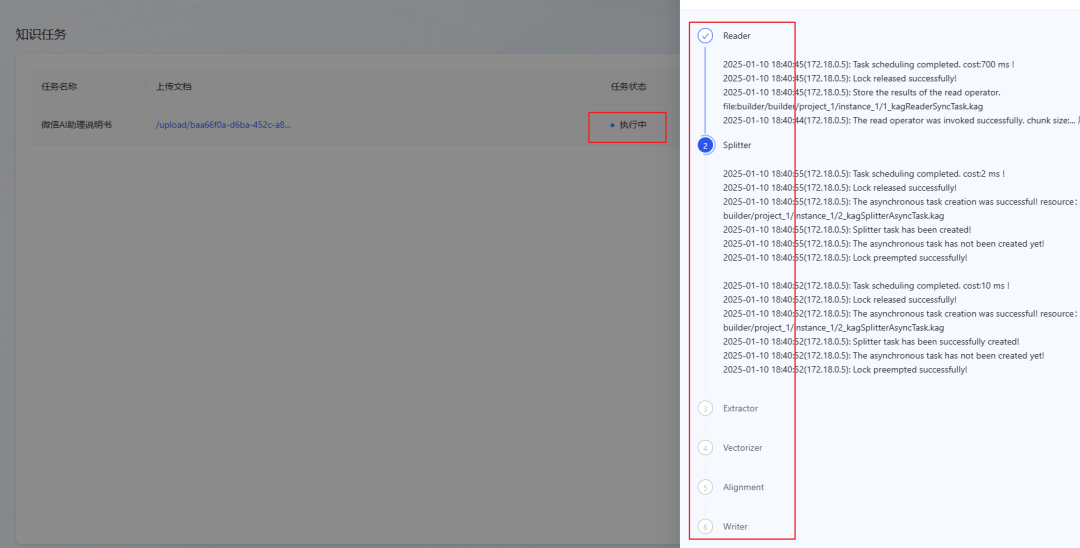
- Warten Sie, bis der Status der Aufgabe auf Erledigt wechselt, was bedeutet, dass das Dokument erfolgreich in die Wissensdatenbank importiert wurde. (Wenn der Status lange Zeit nicht aktualisiert wurde, versuchen Sie, die Seite zu aktualisieren).
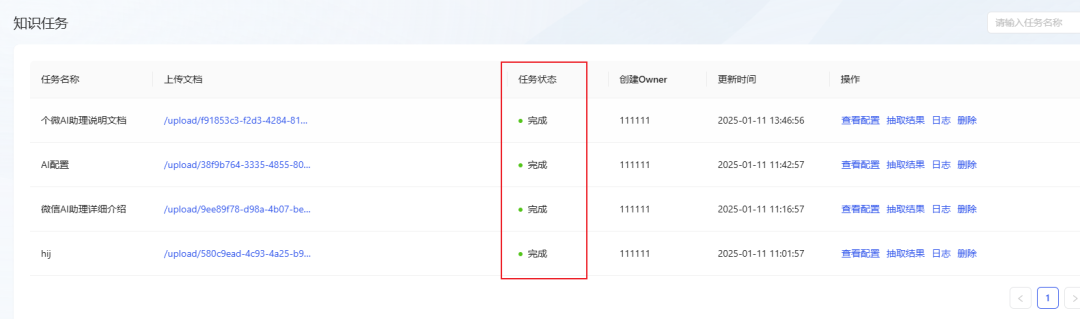
Schritt 7: Demonstration
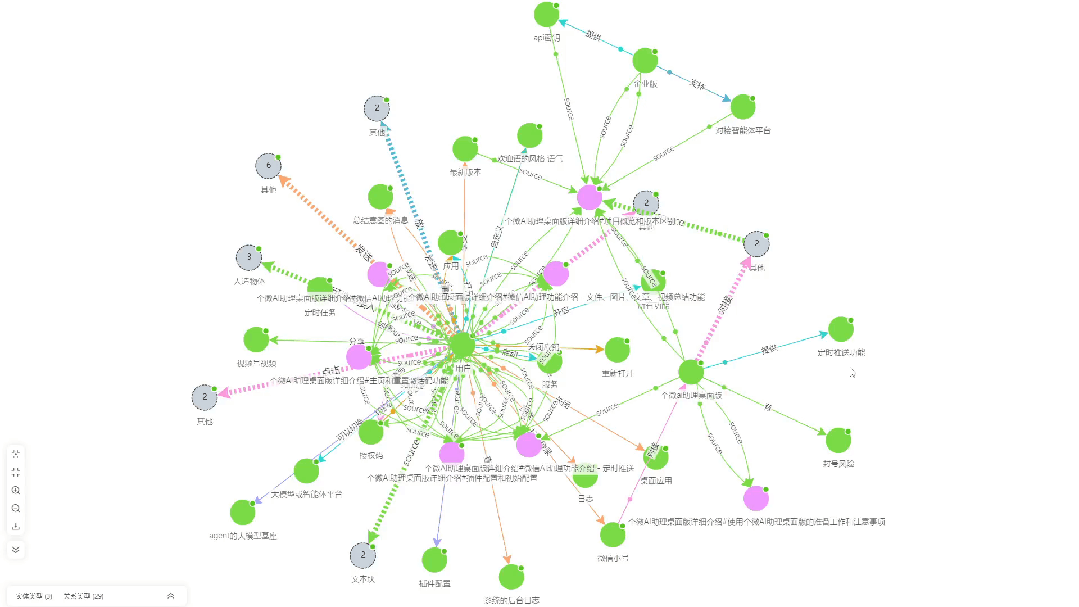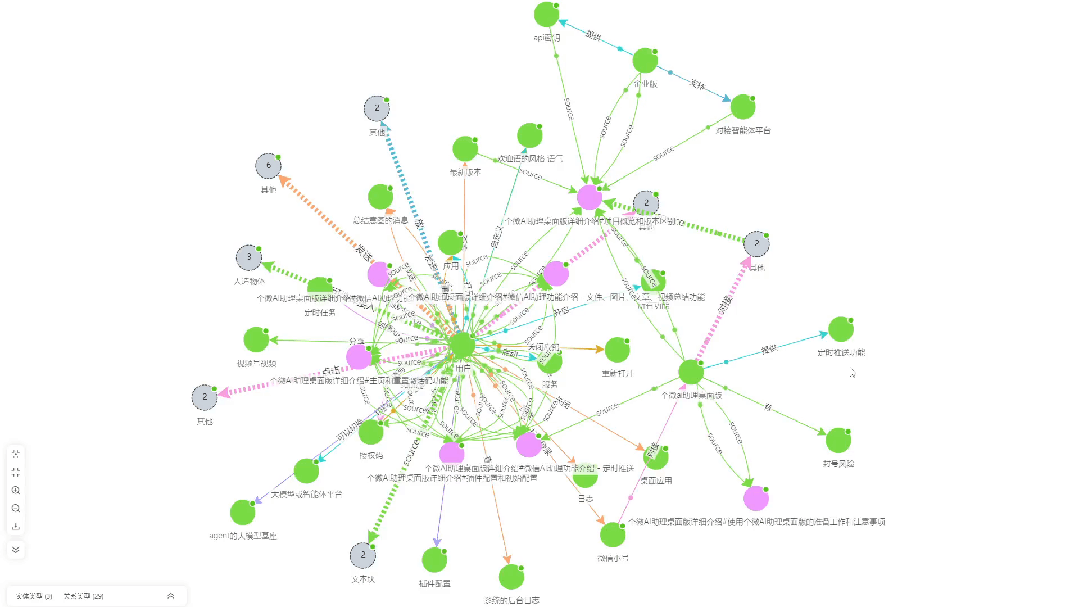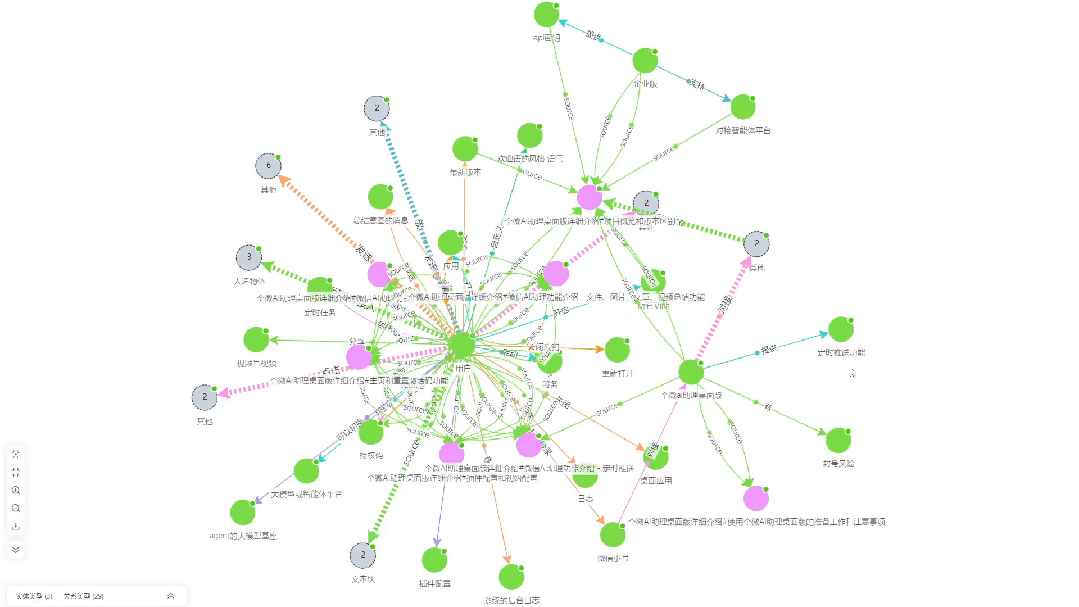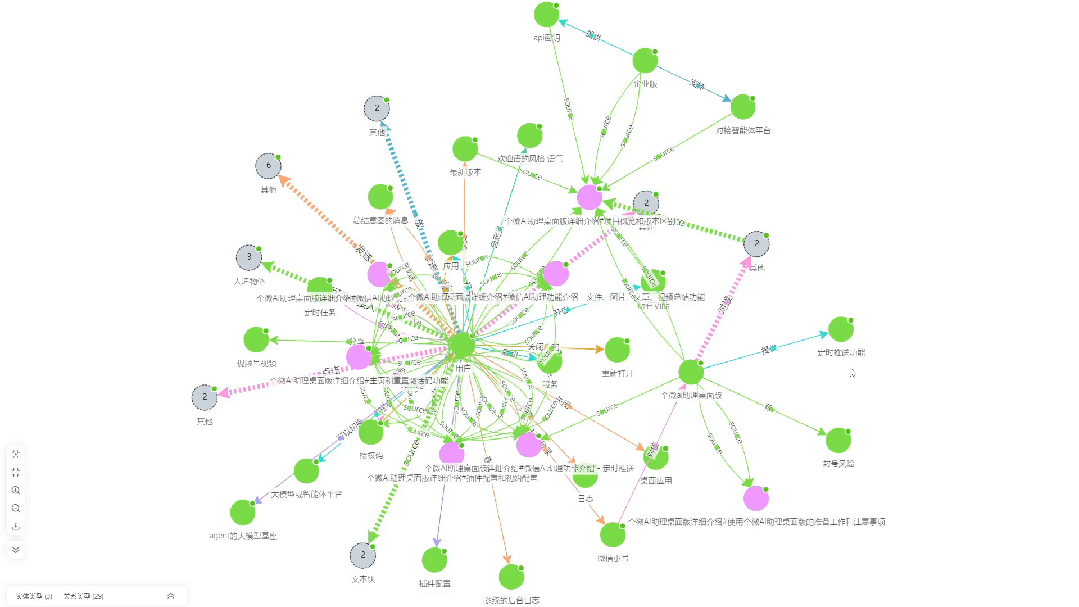
- Korrelationsdiagramm zur WissensextraktionDies ist eine Visualisierung der Wissensassoziationen, die von KAG aus dem Dokument extrahiert wurden.
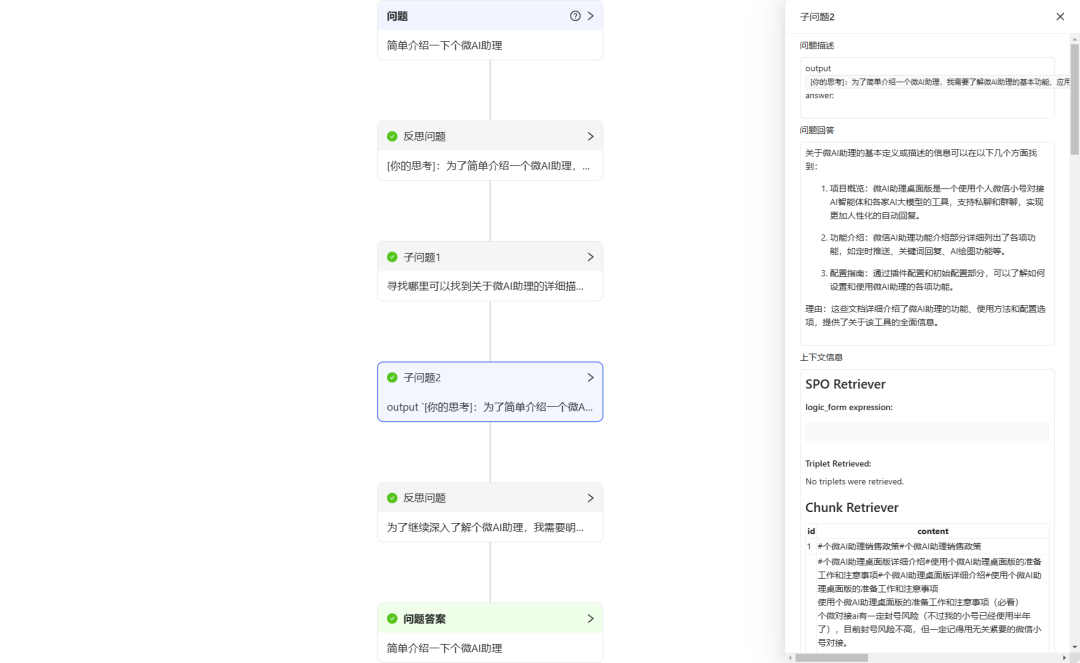
- Q&A Effektivitätstest::
- Frage 1: "Stellen Sie kurz den Personal Micro AI Assistant vor."
KAG führt einen Denk- und Überlegungsprozess durch, bevor es die Antwort abruft und gibt. Es ist zu erkennen, dass die von KAG gegebenen Antworten relativ genau und umfassend sind. Allerdings ist die Antwortzeit mit ca. 40 Sekunden langsam (daher ist KAG möglicherweise nicht für einfache Q&A-Szenarien geeignet).

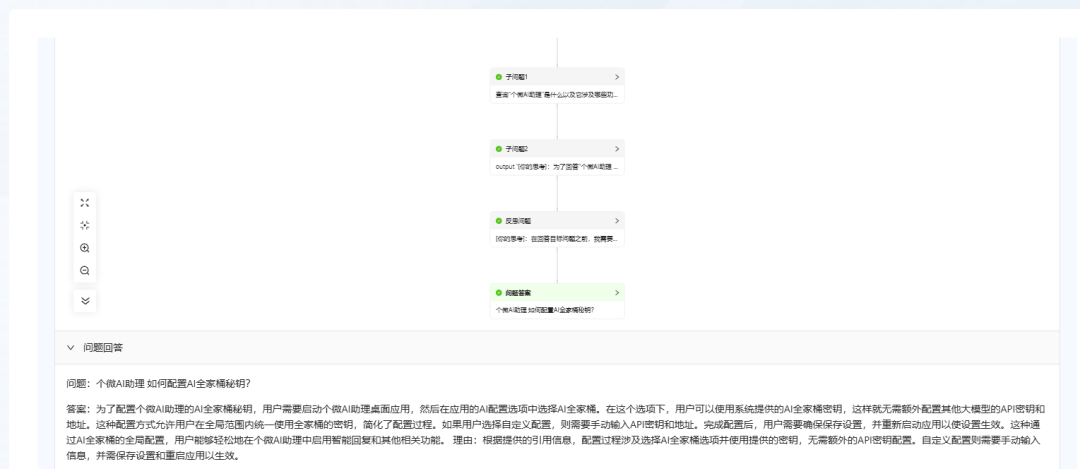
- Frage 2: "Wie konfiguriere ich den geheimen Schlüssel des AI Family Bucket für den Personal Micro AI Assistant?"
Auch die KAG ist in der Lage, eine Antwort zu geben, aber es dauert noch länger.
Zusammenfassung und Ausblick
Durch die oben genannten Erfahrungen, können wir sehen, dass die Ameise Open-Source-KAG Wissensbasis Rahmen ist immer noch in der schnellen Entwicklungsphase, einige Funktionen und Benutzerfreundlichkeit ist noch zu verbessern (wie Wissensbasis Parameter Anpassung, Wissensbasis Bearbeitung und Änderung der Funktion ist nicht perfekt, die Verwendung der Verwendung von einigen Bugs können auch angetroffen werden). Aus den Github-Update-Aufzeichnungen geht jedoch hervor, dass das KAG-Team aktiv an der Iteration des Codes und der funktionalen Optimierung arbeitet.
Die technische Richtung von KAG, die Knowledge Graph und Vector Retrieval vereint, ist sehr vielversprechend. Ebenso wie die RAG-Technologie qualitativ hochwertige Wissensdatenbanken, Modellerweiterungen und Parameterabstimmungen für optimale Ergebnisse erfordert, muss auch die Entwicklung von KAG kontinuierlich verbessert und optimiert werden.
Wie zu Beginn des Artikels erwähnt, ist KAG besser für spezialisierte Bereiche wie Gesundheitswesen, Finanzen, Recht, Verwaltung usw. geeignet, die eine komplexe Argumentation erfordern, als für einfache alltägliche Fragen und Antworten (bei denen die Reaktionsfähigkeit ein Manko ist).
Derzeit hat KAG die API noch nicht geöffnet, und es wird erwartet, dass sie nach der Öffnung der API in der Zukunft in die Agentenanwendung integriert werden kann, und durch den Problemidentifizierungsmechanismus können einfache und komplexe Probleme verschoben werden, um die Vorteile von KAG bei der Bearbeitung komplexer Probleme auszuspielen.
Alles in allem soll dieser Artikel Ihnen einen Vorgeschmack auf die Spitzentechnologie von KAG geben. Auch wenn KAG noch nicht perfekt ist, hat es als Open-Source-Wissensbasis-Framework großes Potenzial gezeigt. Wir glauben, dass KAG mit den gemeinsamen Anstrengungen der Community und der kontinuierlichen Weiterentwicklung der Technologie weitere Möglichkeiten für den Bereich der KI-Wissensdatenbanken bieten wird.