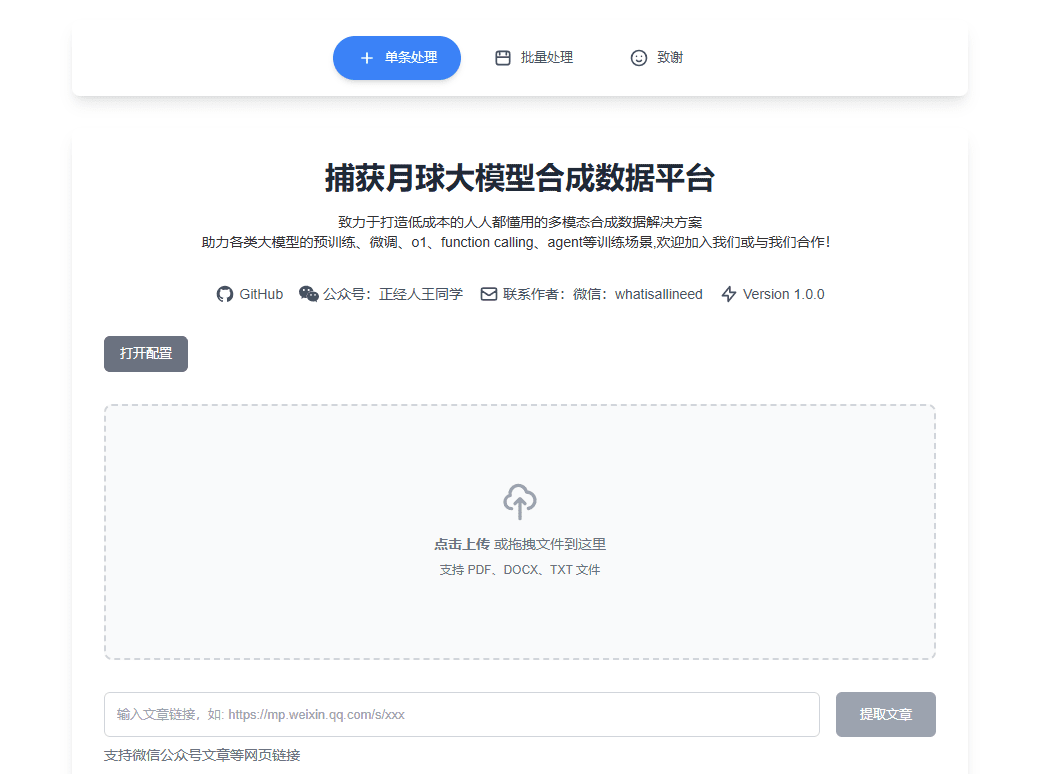
FunASR: Open Source Spracherkennungs-Toolkit, Sprechertrennung / Mehr-Personen-Dialog-Spracherkennung

Allgemeine Einführung
FunASR ist ein Open-Source-Spracherkennungs-Toolkit, das vom Dharma Institute von Alibaba entwickelt wurde, um akademische Forschung und industrielle Anwendungen zu verbinden. Es unterstützt eine breite Palette von Spracherkennungsfunktionen, einschließlich Spracherkennung (ASR), Voice Endpoint Detection (VAD), Interpunktionswiederherstellung, Sprachmodellierung, Sprecherverifizierung, Sprechertrennung und Spracherkennung für Dialoge mit mehreren Personen.FunASR bietet praktische Skripte und Tutorials zur Unterstützung der Inferenz und Feinabstimmung von vortrainierten Modellen, die Benutzern helfen, schnell effiziente Spracherkennungsdienste zu erstellen.
Unterstützt eine Vielzahl von Audio- und Videoformaten, kann Dutzende von Stunden langer Audio- und Videodateien in Text mit Interpunktion umwandeln, unterstützt Hunderte von Anfragen zur gleichzeitigen Transkription Unterstützt Chinesisch, Englisch, Japanisch, Kantonesisch und Koreanisch.
Online-Erfahrung: https://www.funasr.com/


Das FunASR-Softwarepaket für die Offline-Transkription von Dateien bietet einen leistungsstarken Offline-Dienst für die Transkription von Sprachdateien. Mit einer vollständigen Spracherkennungsverbindung, die Sprachendpunkt-Erkennung, Spracherkennung, Interpunktion und andere Modelle kombiniert, kann es Dutzende von Stunden langer Audio- und Videodateien als interpunktierten Text erkennen und unterstützt Hunderte von Anfragen zur gleichzeitigen Transkription. Die Ausgabe erfolgt als interpunktierter Text mit Zeitstempeln auf Wortebene und unterstützt ITN und benutzerdefinierte Hot Words. Server-seitige Integration mit ffmpeg, Unterstützung für eine Vielzahl von Audio- und Videoformaten. Das Paket bietet html, python, c++, java und c# und andere Programmiersprachen Client, kann der Benutzer direkt verwenden und Weiterentwicklung.

Das FunASR-Echtzeit-Sprachdiktat-Softwarepaket integriert Echtzeitversionen von Modellen zur Erkennung von Sprachendpunkten, Spracherkennung, Stimmerkennung, Modellen zur Vorhersage von Zeichensetzung usw. Durch die Nutzung der Synergie mehrerer Modelle kann es nicht nur Sprache-zu-Text in Echtzeit durchführen, sondern auch die Ausgabe mit hochpräzisem Transkriptionstext am Ende des Satzes, den Ausgabetext mit Interpunktion korrigieren und Unterstützung für mehrere Anfragen bieten. Entsprechend den verschiedenen Benutzerszenarien unterstützt es drei Servicemodi: Echtzeit-Sprachdiktatdienst (online), Satztranskription in Nicht-Echtzeit (offline) und integrierte Zusammenarbeit in Echtzeit und Nicht-Echtzeit (2pass). Das Softwarepaket bietet eine Vielzahl von Programmiersprachen wie html, python, c++, java und c#-Client, die Benutzer direkt verwenden und weiterentwickeln können.
Funktionsliste
- Spracherkennung (ASR): unterstützt Offline- und Echtzeit-Spracherkennung.
- Voice Endpoint Detection (VAD): erkennt den Anfang und das Ende des Sprachsignals.
- Interpunktionswiederherstellung: Fügen Sie automatisch Interpunktion hinzu, um die Lesbarkeit des Textes zu verbessern.
- Sprachmodelle: Unterstützt die Integration von mehreren Sprachmodellen.
- Sprecherverifizierung: Verifiziert die Identität des Sprechers.
- Sprechertrennung: Unterscheidung der Sprache von verschiedenen Sprechern.
- Spracherkennung für mehrere Gespräche: unterstützt die Spracherkennung für mehrere gleichzeitige Gespräche.
- Modellinferenz und Feinabstimmung: bietet Inferenz- und Feinabstimmungsfunktionen für vorab trainierte Modelle.
Hilfe verwenden
Einbauverfahren
- Vorbereitung der Umwelt::
- Stellen Sie sicher, dass Python 3.7 oder höher installiert ist.
- Installieren Sie die erforderlichen Abhängigkeits-Bibliotheken:
pip install -r requirements.txt
- Modelle herunterladen::
- Laden Sie bereits trainierte Modelle von ModelScope oder HuggingFace herunter:
git clone https://github.com/modelscope/FunASR.git cd FunASR
- Laden Sie bereits trainierte Modelle von ModelScope oder HuggingFace herunter:
- Konfiguration der Umgebung::
- Konfigurieren Sie die Umgebungsvariablen:
export MODEL_DIR=/path/to/your/model
- Konfigurieren Sie die Umgebungsvariablen:
Verwendungsprozess
- Spracherkennung::
- Verwenden Sie die Befehlszeile für die Spracherkennung:
python recognize.py --model paraformer --input your_audio.wav - Spracherkennung mit Python-Code:
from funasr import AutoModel model = AutoModel.from_pretrained("paraformer") result = model.recognize("your_audio.wav") print(result)
- Verwenden Sie die Befehlszeile für die Spracherkennung:
- Erkennung von Sprachendpunkten::
- Verwenden Sie die Befehlszeile für die Erkennung von Sprachendpunkten:
python vad.py --model fsmn-vad --input your_audio.wav - Erkennung von Sprachendpunkten mit Python-Code:
from funasr import AutoModel vad_model = AutoModel.from_pretrained("fsmn-vad") vad_result = vad_model.detect("your_audio.wav") print(vad_result)
- Verwenden Sie die Befehlszeile für die Erkennung von Sprachendpunkten:
- Wiederherstellung der Zeichensetzung::
- Verwenden Sie die Befehlszeile zur Wiederherstellung der Interpunktion:
python punctuate.py --model ct-punc --input your_text.txt - Wiederherstellung der Interpunktion mit Python-Code:
from funasr import AutoModel punc_model = AutoModel.from_pretrained("ct-punc") punc_result = punc_model.punctuate("your_text.txt") print(punc_result)
- Verwenden Sie die Befehlszeile zur Wiederherstellung der Interpunktion:
- Überprüfung des Sprechers::
- Verwenden Sie die Befehlszeile für die Lautsprecherüberprüfung:
python verify.py --model speaker-verification --input your_audio.wav - Sprecherverifizierung mit Python-Code:
from funasr import AutoModel verify_model = AutoModel.from_pretrained("speaker-verification") verify_result = verify_model.verify("your_audio.wav") print(verify_result)
- Verwenden Sie die Befehlszeile für die Lautsprecherüberprüfung:
- Multi-Talk-Spracherkennung::
- Spracherkennung für Multiplayer-Dialoge über die Kommandozeile:
python multi_asr.py --model multi-talker-asr --input your_audio.wav - Spracherkennung für Unterhaltungen mit mehreren Personen mit Python-Code:
from funasr import AutoModel multi_asr_model = AutoModel.from_pretrained("multi-talker-asr") multi_asr_result = multi_asr_model.recognize("your_audio.wav") print(multi_asr_result)
- Spracherkennung für Multiplayer-Dialoge über die Kommandozeile:
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...