Kostenloses PDF von Grundlagen großer Modelle der Universität Zhejiang - mit Download-Link

Fundamentals of Large Models bietet eine eingehende Analyse der Kerntechnologien und der praktischen Wege zu großen Sprachmodellen (LLMs). Ausgehend von der grundlegenden Theorie der Sprachmodellierung werden systematisch die Prinzipien des Modelldesigns auf der Grundlage statistischer, rekurrenter neuronaler Netze (RNN) und Transformer-Architekturen erläutert, wobei der Schwerpunkt auf den drei wichtigsten Architekturen großer Sprachmodelle (nur Encoder, Encoder-Decoder, nur Decoder) und repräsentativen Modellen (z. B. BERT, T5, GPT-Reihe). Das Buch erklärt Schlüsseltechnologien wie Prompt-Engineering, effiziente Feinabstimmung von Parametern, Modellbearbeitung und Generierung von Retrieval-Erweiterungen. In Kombination mit umfangreichen Fallstudien demonstriert das Buch Anwendungspraktiken in verschiedenen Szenarien und bietet dem Leser umfassende und tiefgehende Lern- und Praxisanleitungen, die ihm helfen, die Anwendung und Optimierung großer Sprachmodellierungstechnologien zu meistern.

Grundlagen der Sprachmodellierung
- Sprachmodellierung auf der Grundlage statistischer MethodenEine eingehende Analyse von n-Gramm-Modellen und der ihnen zugrunde liegenden Statistiken, einschließlich Markov-Annahmen und großer Wahrscheinlichkeitsschätzungen.
- RNN-basierte SprachmodellierungEine ausführliche Erläuterung der strukturellen Merkmale rekurrenter neuronaler Netze (RNN), gängige Probleme mit dem Verschwinden von Gradienten und Explosionen beim Training sowie praktische Anwendungen bei der Sprachmodellierung.
- Transformatorgestützte SprachmodellierungEine umfassende Analyse der Kernkomponenten der Transformer-Architektur, wie z.B. des Selbstbeobachtungsmechanismus, der Feed-Forward Neural Networks (FFNs), der Schichtnormalisierung und der Restkonnektivität, sowie deren effiziente Anwendung auf die Sprachmodellierung.
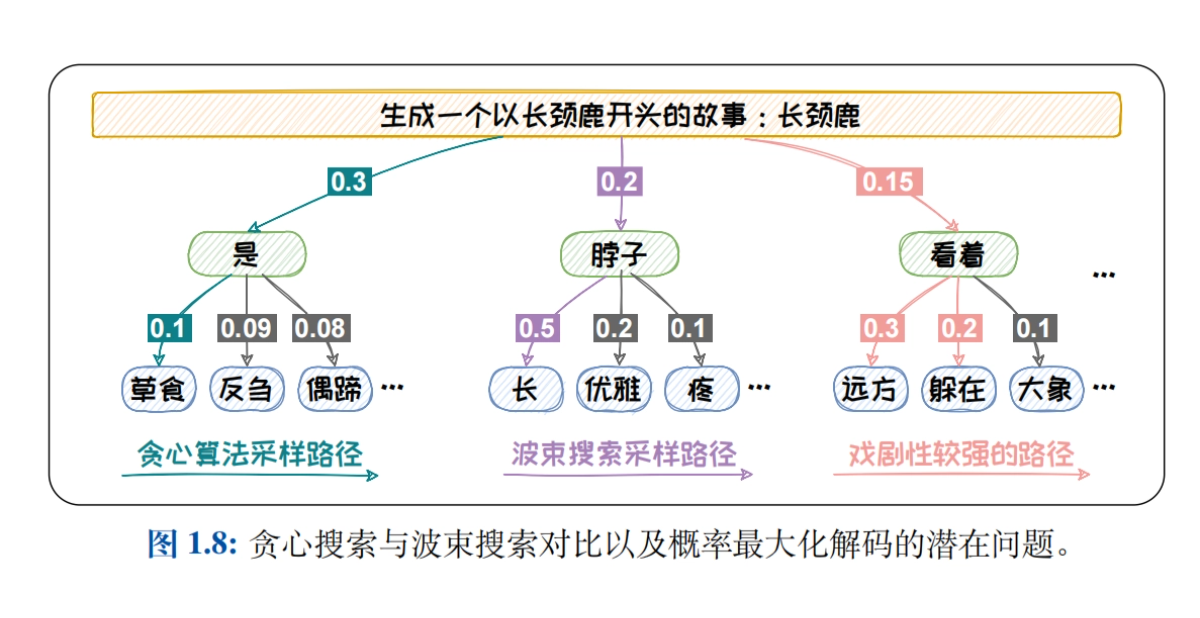
- Stichprobenverfahren für die SprachmodellierungDekodierungsstrategien wie Greedy Search, Beam Search, Top-K Sampling, Top-P Sampling und Temperaturmechanismus werden systematisch eingeführt, um die Auswirkungen der verschiedenen Strategien auf die Qualität des generierten Textes zu untersuchen.
- Überprüfung von SprachmodellenDetaillierte Beschreibungen intrinsischer Rubriken (z.B. Perplexität) und extrinsischer Rubriken (z.B. BLEU, ROUGE, BERTScore, G-EVAL) werden vorgestellt, um die Stärken und Grenzen der einzelnen Rubriken bei der Bewertung der Leistung von Sprachmodellen zu analysieren.
Architektur des großen Sprachmodells
- Große Daten + große Modelle → Neue IntelligenzEs folgt eine eingehende Analyse der Auswirkungen von Modell- und Datengröße auf die Modellfähigkeit, eine ausführliche Erläuterung der Skalierungsgesetze (wie das Kaplan-McCandlish-Gesetz und das Chinchilla-Gesetz) und eine Diskussion darüber, wie die Modellleistung durch Optimierung von Modell- und Datengröße verbessert werden kann.
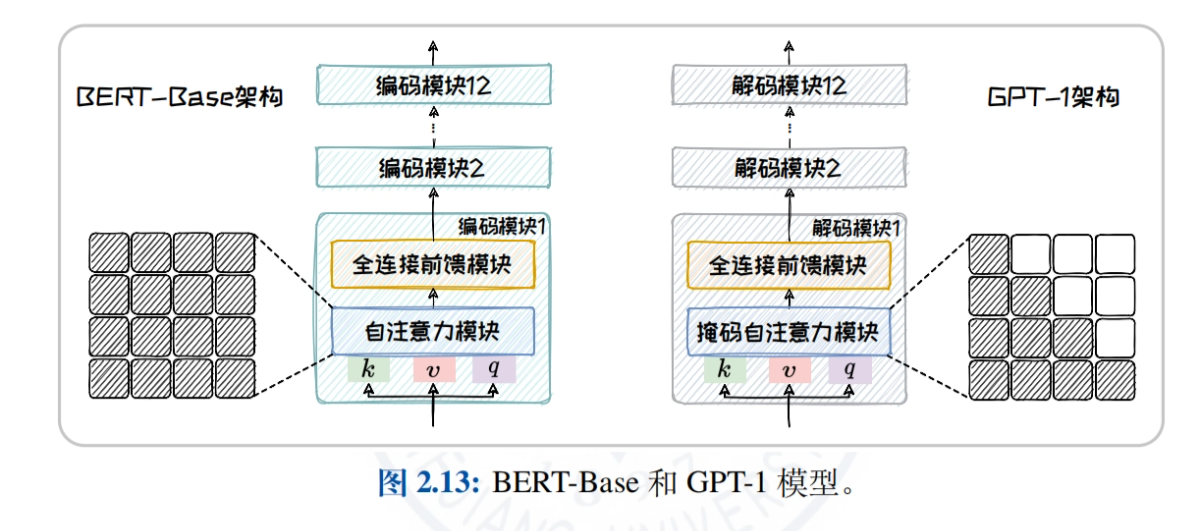
- Überblick über die Architektur des Big Language ModelVergleich und Analyse der Aufmerksamkeitsmechanismen und der anwendbaren Aufgaben von drei Mainstream-Architekturen, Encoder-only, Encoder-Decoder und Decoder-only, um dem Leser zu helfen, die Eigenschaften und Vorteile der verschiedenen Architekturen zu verstehen.
- Reine Encoder-ArchitekturBERT: Am Beispiel von BERT werden die Modellstruktur, die Pre-Training-Aufgaben (z.B. MLM, NSP) und die abgeleiteten Modelle (z.B. RoBERTa, ALBERT, ELECTRA) eingehend erläutert, um die Anwendung des Modells bei Aufgaben zum Verstehen natürlicher Sprache zu untersuchen.
- Encoder-Decoder-ArchitekturT5 und BART werden als Beispiele verwendet, um den einheitlichen Texterzeugungsrahmen und verschiedene Pre-Training-Aufgaben vorzustellen und die Leistung der Modelle bei Aufgaben wie der maschinellen Übersetzung und der Textzusammenfassung zu analysieren.
- Reine Decoder-ArchitekturDie Entwicklungsgeschichte und die Eigenschaften der GPT-Familie (von GPT-1 bis GPT-4) und der LLaMA-Familie (LLaMA1/2/3) werden detailliert beschrieben, wobei die Vorteile der Modelle für Aufgaben der offenen Texterzeugung untersucht werden.
- Nicht-Transformator-ArchitekturEinführung von State Space Models (SSMs) wie RWKV, Mamba und dem Training While Testing (TTT) Paradigma, um das Potential von nicht-mainstream Architekturen in spezifischen Szenarien zu erforschen.
Schnelles Engineering
- Einführung in Prompt ProjectDefinition von Prompt und Prompt-Engineering, ausführliche Erläuterung des Disambiguierungs- und Vektorisierungsprozesses (Tokenisierung, Einbettung) und Erkundung, wie qualitativ hochwertiger Text durch ein gut konzipiertes Prompt-Bootstrap-Modell erzeugt werden kann.
- Kontextbezogenes Lernen (ICL)Einführung in die Konzepte des Null-Stichproben-, Ein-Stichproben- und Wenig-Stichproben-Lernens, Erforschung von Strategien zur Auswahl von Beispielen (z. B. Ähnlichkeit und Vielfalt) und Analyse, wie kontextuelles Lernen zur Verbesserung der Anpassungsfähigkeit von Modellen an die Aufgabe eingesetzt werden kann.
- Gedankenkette (CoT)Erläutern Sie die drei Modi des CoT: Schritt-für-Schritt (z.B. CoT, Zero-Shot CoT, Auto-CoT), Think-Through (z.B. ToT, GoT) und Brainstorming (z.B. Self-Consistency), und untersuchen Sie, wie Sie die Argumentation von Modellen durch die Gedankenkette verbessern können.
- Prompt-TippsEs werden Techniken vorgestellt, wie z. B. die Standardisierung des Prompt-Schreibens, die rationelle Zusammenfassung von Fragen, der Einsatz von CoTs zum richtigen Zeitpunkt und die gute Nutzung psychologischer Hinweise (z. B. Rollenspiele, situative Substitution), um den Lesern zu helfen, ihre Prompt-Gestaltung zu verbessern.
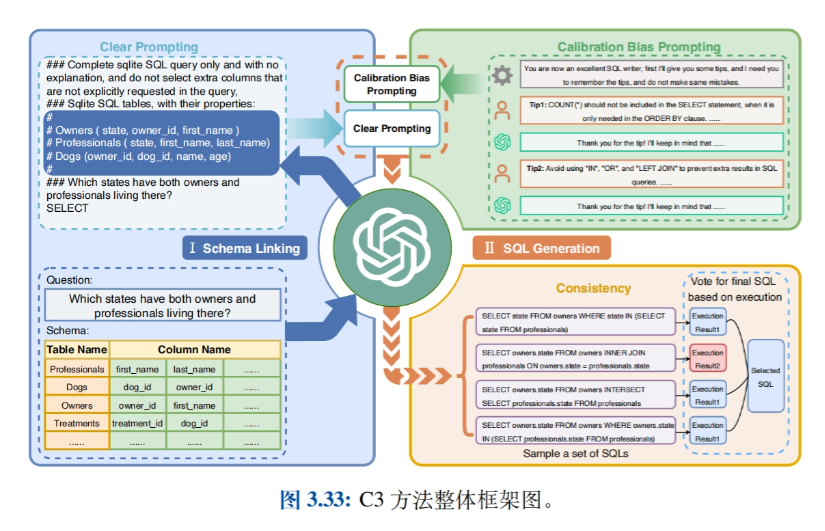
- Verwandte AnwendungenEinführung von Anwendungen wie Big Model-based Intelligentsia (Agents), Data Synthesis, Text-to-SQL, GPTS, etc. und Erkundung praktischer Anwendungsfälle von Prompt Engineering in verschiedenen Bereichen.
Effiziente Feinabstimmung der Parameter
- Einführung in die effiziente Feinabstimmung der ParameterDie Einführung der beiden vorherrschenden Ansätze für die nachgelagerte Aufgabenanpassung - Kontextlernen und Feinabstimmung von Anweisungen - führt zur Technik des Parameter Efficient Fine-Tuning (PEFT), wobei die erheblichen Vorteile in Bezug auf Kostenreduzierung und Effizienz ausführlich dargestellt werden.
- Methoden zum Anbringen von ParameternEine detaillierte Beschreibung von Methoden zur effizienten Feinabstimmung durch Anhängen neuer, kleinerer trainierbarer Module an die Modellstruktur, einschließlich der Implementierung und der Vorteile von Add-in-Eingaben (z.B. Prompt-Tuning), Add-in-Modellen (z.B. Prefix-Tuning und Adapter-Tuning) und Add-in-Ausgaben (z.B. Proxy-Tuning).
- Methode der ParameterauswahlEinführung von Methoden zur Feinabstimmung nur eines Teils der Modellparameter, unterteilt in regelbasierte Methoden (z.B. BitFit) und lernbasierte Methoden (z.B. Child-tuning), die untersuchen, wie man den Rechenaufwand reduzieren und die Leistung des Modells durch selektive Aktualisierung der Parameter verbessern kann.
- Niedrigrangige AnpassungsmethodenEine detaillierte Einführung in die effiziente Feinabstimmung durch Annäherung der ursprünglichen Gewichtsaktualisierungsmatrix durch eine Matrix mit niedrigem Rang, mit Schwerpunkt auf LoRA und seinen Varianten (z.B. ReLoRA, AdaLoRA und DoRA) sowie einer Diskussion der parametrischen Effizienz und der Aufgabengeneralisierungsfähigkeiten von LoRA.
- Praxis und AnwendungEinführung in die Verwendung des HF-PEFT-Frameworks und verwandter Techniken, Demonstration von Anwendungsfällen von PEFT-Techniken in der tabellarischen Datenabfrage und tabellarischen Datenanalyse und Nachweis der Wirksamkeit von PEFT bei der Verbesserung der Leistung großer modellspezifischer Aufgaben.
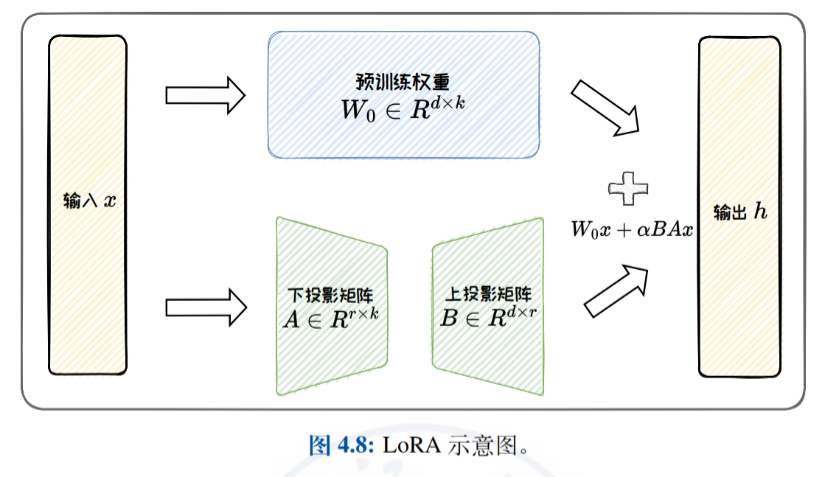
Modellbearbeitung
- Einführung in die ModellbearbeitungEine Einführung in die Idee, die Definition und die Natur des Modell-Editierens, wobei die Bedeutung des Modell-Editierens bei der Korrektur von Verzerrungen, Toxizität und Wissensfehlern in großen Sprachmodellen erläutert wird.
- Klassischer Ansatz zur ModellbearbeitungKlassifizierung von Modellbearbeitungsmethoden in externe Erweiterungsmethoden (z.B. Wissenscaching und zusätzliche Parametermethoden) und interne Modifizierungsmethoden (z.B. Meta-Learning und Positionsbearbeitungsmethoden) und Vorstellung repräsentativer Arbeiten zu jeder Art von Methode.
- Zusätzlicher Parameter Methode: T-PatcherT-Patcher: Die T-Patcher-Methode wird detailliert beschrieben, die eine präzise Kontrolle des Modelloutputs erreicht, indem bestimmte Parameter an das Modell angehängt werden. Sie eignet sich für Szenarien, die eine schnelle und präzise Korrektur bestimmter Wissenspunkte im Modell erfordern.
- Standortbearbeitungsmethode: ROMEEine ausführliche Einführung in die ROME-Methode, die eine präzise Steuerung der Modellleistung durch die Lokalisierung und Modifizierung bestimmter Schichten oder Neuronen innerhalb des Modells für Szenarien ermöglicht, die eine tiefgreifende Modifizierung der internen Wissensstruktur des Modells erfordern.
- Anwendungen zur ModellbearbeitungEinführung in die praktischen Anwendungen der Modellbearbeitung für die genaue Modellaktualisierung, den Schutz des Rechts auf Vergessenwerden und die Verbesserung der Modellsicherheit sowie Demonstration des Anwendungspotenzials der Modellbearbeitungstechnologie in verschiedenen Szenarien.
Suche Verbesserte Generation
- Abruferweiterung GenerierungsprofilStellt den Hintergrund und die Zusammensetzung von Retrieval-verstärkter Generierung vor und beschreibt die Bedeutung und die Anwendungsszenarien der Verbesserung der Modellleistung durch die Kombination von Retrieval und Generierung in Aufgaben der natürlichen Sprachverarbeitung.
- Abruf der Architektur der erweiterten GenerationEinführung in die Klassifizierung von RAG-Architekturen, Black-Box-Enhancement-Architekturen und White-Box-Enhancement-Architekturen, Vergleich und Analyse der Eigenschaften und Anwendungsszenarien der verschiedenen Architekturen und Unterstützung bei der Auswahl der geeigneten Architektur.
- WissensabfrageEine ausführliche Einführung in die Konstruktion von Wissensdatenbanken, die Verbesserung von Abfragen, Suchern und die Verbesserung der Abfrageeffizienz, wobei untersucht wird, wie die Abfrageeffektivität verbessert und der Wissensabfrageprozess durch die Neuordnung der Abfrageergebnisse optimiert werden kann.
- Generation EnhancementErläutert, wann, wo und mit welchen Methoden verbessert werden soll, diskutiert Strategien für die Anwendung generativer Erweiterungen für verschiedene Aufgaben und verbessert die Qualität und Effizienz des generierten Textes.
- Praxis und AnwendungFührt in die Schritte zum Aufbau eines einfachen RAG-Systems ein, zeigt Beispiele für RAG in typischen Anwendungen und hilft den Lesern, Retrieval-gestützte Generierungstechniken zu verstehen und anzuwenden, um die Leistung ihrer Modelle in realen Aufgaben zu verbessern.
Adresse zum Herunterladen von Ressourcenmaterial
Der Bericht Fundamentals of Large Modelling kann heruntergeladen werden unter: https://url23.ctfile.com/f/65258023-8434020435-605e6e?p=8894 (Zugangscode: 8894)
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Verwandte Beiträge


Keine Kommentare...