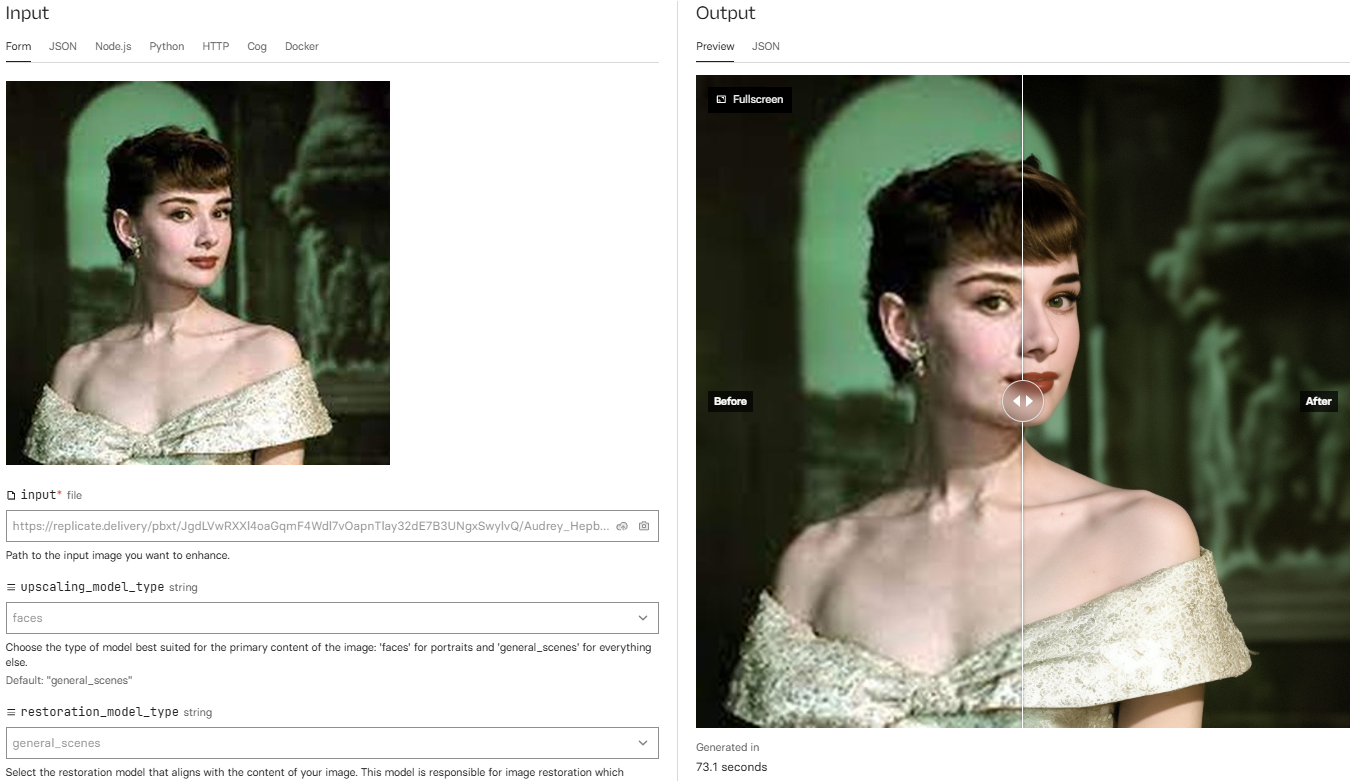
dots.vlm1 - Kleines rotes Buch hi lab open source multimodales großes Modell

Was ist dots.vlm1?
dots.vlm1 ist das erste multimodale Makromodell, das vom Little Red Book hi lab freigegeben wurde. Es basiert auf dem visuellen Codierer NaViT mit 1,2 Milliarden Parametern, der von Null an trainiert wurde, und dem DeepSeek V3 Large Language Model (LLM) mit starken Fähigkeiten zur visuellen Wahrnehmung und zum Textverständnis. Das Modell erbringt gute Leistungen bei visuellen Verständnis- und Schlussfolgerungsaufgaben, die sich dem Niveau von SOTA-Modellen nähern, und bleibt bei Textaufgaben konkurrenzfähig. Der visuelle Codierer von dots.vlm1, NaViT, wurde von Grund auf neu trainiert, unterstützt nativ die dynamische Auflösung und fügt der textuellen Überwachung eine rein visuelle Überwachung hinzu, um die Wahrnehmungsfähigkeiten zu verbessern. Die Trainingsdaten enthalten eine Vielzahl von synthetischen Daten, um verschiedene Bildtypen und deren Beschreibungen abzudecken und die Datenqualität zu verbessern.

Hauptfunktionen von dots.vlm1
- Starkes visuelles VerständnisErkennen und Verstehen von Bildinhalten, einschließlich komplexer Diagramme, Tabellen, Dokumente, Grafiken usw., und Unterstützung der dynamischen Auflösung für eine Vielzahl von visuellen Aufgaben.
- Effiziente Textgenerierung und ReasoningBasierend auf DeepSeek V3 LLM generiert es qualitativ hochwertige Textbeschreibungen und zeigt gute Leistungen bei textuellen Schlussfolgerungen wie Mathematik und Code.
- Multimodale DatenverarbeitungEs unterstützt die Datenverarbeitung mit grafischer und textueller Verflechtung und kann visuelle und textuelle Informationen für integrierte Schlussfolgerungen kombinieren, was für multimodale Anwendungsszenarien geeignet ist.
- Flexible Anpassung und ErweiterungDer MLP-Adapter verbindet den visuellen Encoder mit dem Sprachmodell und ermöglicht eine flexible Anpassung und Erweiterung für verschiedene Aufgaben.
- Open Source und OffenheitBereitstellung von vollständigem Open-Source-Code und Modellen zur Unterstützung von Entwicklern in ihrer Forschung und Anwendungsentwicklung und zur Förderung der Entwicklung multimodaler Technologien.
Projektadresse für dots.vlm1
- GitHub-Repository:: https://github.com/rednote-hilab/dots.vlm1
- Umarmendes Gesicht Modellbibliothek:: https://huggingface.co/rednote-hilab/dots.vlm1.inst
- Online-Erlebnis-Demo:: https://huggingface.co/spaces/rednote-hilab/dots-vlm1-demo
Technische Grundlagen von dots.vlm1
- NaViT visueller Kodiererdots.vlm1 verwendet NaViT, einen visuellen Codierer mit 1,2 Milliarden Parametern, der von Grund auf neu trainiert und nicht auf der Grundlage bestehender ausgereifter Modelle feinabgestimmt wurde. Native Unterstützung für dynamische Auflösung, die in der Lage ist, Bildeingaben mit unterschiedlichen Auflösungen zu verarbeiten, und rein visuelle Überwachung, die der textuellen Überwachung hinzugefügt wurde, um die Wahrnehmung von Bildern durch das Modell zu verbessern.
- Multimodale DatenausbildungDas Modell verwendet verschiedene multimodale Trainingsdaten, darunter gewöhnliche Bilder, komplexe Diagramme, Tabellen, Dokumente, Grafiken usw. und entsprechende Textbeschreibungen (z. B. Alt-Text, dichte Beschriftung, Erdung usw.). Synthetische Datenideen und mit Grafik und Text verschachtelte Daten wie Webseiten und PDFs werden eingeführt, um die Datenqualität durch Umschreiben und Bereinigen zu verbessern und die multimodale Verständnisfähigkeit des Modells zu erhöhen.
- Visuelle und sprachliche Modellfusiondots.vlm1 kombiniert einen visuellen Encoder mit dem DeepSeek V3 Large Language Model (LLM), das über einen leichtgewichtigen MLP-Adapter verbunden ist, um die effektive Fusion von visuellen und linguistischen Informationen zur Unterstützung der Verarbeitung multimodaler Aufgaben zu ermöglichen.
- Dreiphasiger AusbildungsprozessDas Training des Modells ist in drei Stufen unterteilt: Pre-Training des visuellen Codierers, Pre-Training des VLM und Post-Training des VLM. Die Generalisierungsfähigkeit und die Fähigkeit des Modells, multimodale Aufgaben zu verarbeiten, werden durch die schrittweise Erhöhung der Bildauflösung und die Einführung verschiedener Trainingsdaten verbessert.
Die wichtigsten Vorteile von dots.vlm1
- Von Grund auf geschulter visueller CodiererEin von Grund auf neu trainierter NaViT-Visual-Codierer mit nativer Unterstützung für dynamische Auflösungen und rein visueller Überwachung, um die Grenzen der visuellen Wahrnehmung zu erweitern.
- Multimodale DateninnovationDie Einführung einer Vielzahl von synthetischen Daten, die verschiedene Bildtypen und deren Beschreibungen abdecken, sowie das Umschreiben von Webseitendaten unter Verwendung eines multimodalen Makromodells verbessert die Qualität der Trainingsdaten erheblich.
- Nahezu SOTA-LeistungLeistung nahe an der Leistung von SOTA-Modellen mit geschlossenem Quellcode in visueller Wahrnehmung und Schlussfolgerung, wodurch eine neue Leistungsobergrenze für Open-Source-Modelle für visuelle Sprache gesetzt wird.
- Leistungsstarke TextfunktionenGute Leistungen bei Aufgaben zum logischen Denken in Texten, mit einigen mathematischen und kodierenden Fähigkeiten, während er bei reinen Textaufgaben wettbewerbsfähig bleibt.
- Flexible ArchitekturgestaltungDer MLP-Adapter verbindet den visuellen Encoder mit dem Sprachmodell und ermöglicht eine flexible Anpassung und Erweiterung für verschiedene Aufgaben.
Personen, für die dots.vlm1 bestimmt ist
- Forscher im Bereich der künstlichen IntelligenzInteresse an multimodaler Makromodellierung und Interesse an der Erforschung ihrer Anwendung und Verbesserung im Bereich der Seh- und Sprachverarbeitung.
- Entwickler und IngenieureDie Notwendigkeit, multimodale Funktionen wie Bilderkennung, Texterzeugung, Visual Reasoning usw. in Projekte zu integrieren.
- ErzieherinDas Modell kann zur Unterstützung des Unterrichts verwendet werden und hilft Schülern, komplexe Diagramme, Dokumente und andere Inhalte besser zu verstehen und zu analysieren.
- Ersteller von InhaltenDie Notwendigkeit, hochwertige grafische Inhalte zu erstellen oder Inhaltsempfehlungen und personalisierte Kreationen zu erstellen.
- GeschäftskundeIn Geschäftsszenarien, in denen multimodale Daten verarbeitet werden müssen, wie z. B. intelligenter Kundenservice, Inhaltsempfehlungen, Datenanalyse usw., können Modelle zur Verbesserung von Effizienz und Effektivität eingesetzt werden.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...