dots.ocr - ein quelloffenes Modell zur Analyse mehrsprachiger Dokumente vom Little Red Book hi lab

Was ist dots.ocr
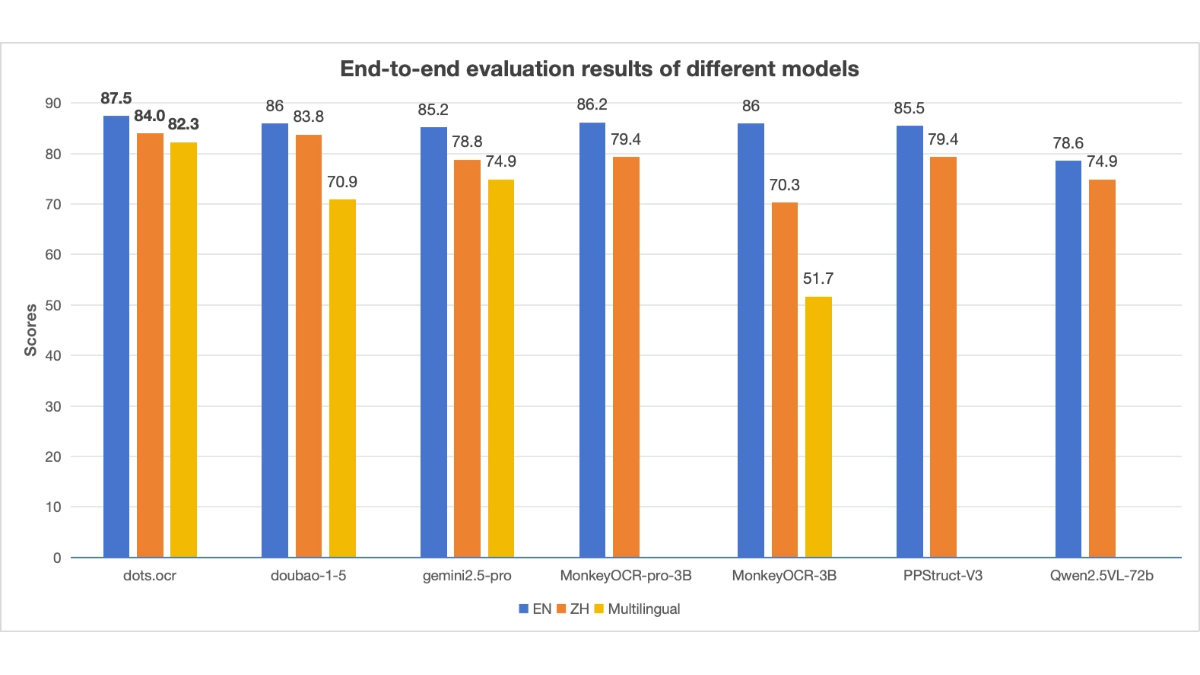
dots.ocr ist ein mehrsprachiges Parsing-Modell für Dokumente, das vom Little Red Book hi lab als Open Source zur Verfügung gestellt wird. Es basiert auf einem visuellen Sprachmodell (VLM) mit 1,7 Milliarden Parametern, das effizient das Layout und den Inhalt von Dokumenten erkennen kann und dabei eine gute Lesereihenfolge beibehält. dots.ocr unterstützt mehrere Sprachen, analysiert Text, Tabellen, Formeln und Bilder und hat eine hohe Inferenzgeschwindigkeit und eine branchenführende Leistung! . Das Modell kann flexibel auf unterschiedliche Parsing-Aufgaben reagieren, indem es einfach zwischen Eingabeaufforderungen und Ausgaben in einer Vielzahl von Formaten, einschließlich JSON und Markdown, umschaltet. dots.ocr zeichnet sich durch das Parsen kleinerer Sprachen und die Erkennung von Formeln aus und eignet sich für eine Vielzahl von Szenarien, wie z. B. akademische Forschung, Verarbeitung von Finanzdokumenten und Parsing von Lehrmaterial.
Hauptfunktionen von dots.ocr
- Mehrsprachige Unterstützung und vielfältige Inhaltsanalysedots.ocr kann Dokumente in mehreren Sprachen verarbeiten und Text, Tabellen, Formeln, Bilder und andere Elemente genau analysieren, um die Anforderungen an die Inhaltsextraktion in verschiedenen Szenarien zu erfüllen.
- Einheitliches Layout und Handhabung von InhaltenDas Modell integriert die Erkennung des Layouts und des Inhalts von Dokumenten in einem, wodurch verschiedene Regionen automatisch identifiziert und eine sinnvolle Lesereihenfolge beibehalten werden kann, wodurch das Problem der Trennung von Layout und Inhalt bei herkömmlichen Methoden vermieden wird.
- Effiziente Argumentation und umfangreiche VerarbeitungsmöglichkeitenDas visuelle Sprachmodell basiert auf 1,7 Milliarden Parametern, mit schneller Modellinferenz, geeignet für die Verarbeitung großer Dokumente und in der Lage, die Parsing-Anforderungen einer großen Anzahl von Dokumenten effektiv zu erfüllen.
- Flexibler AufgabenwechselEinfache Umschaltung zwischen verschiedenen Aufgaben, wie Layout-Erkennung, Inhaltserkennung, Formelparsing usw., auf der Grundlage einfacher Eingabeaufforderungen ohne komplexe Modellabstimmung.
- Vielseitige AusgabeformateEs unterstützt verschiedene Ausgabeformate wie JSON, Markdown usw. Es bietet Bilder zur Visualisierung des Layouts, was für die Benutzer bequem ist, um ihren Bedürfnissen entsprechend zu folgen.
- Vorteile der Small Language AnalysisDas Modell erbringt gute Leistungen beim Parsen kleinsprachiger Dokumente und kann kleinsprachige Inhalte genau verarbeiten, um den Anforderungen des Parsens von Dokumenten in einer mehrsprachigen Umgebung gerecht zu werden.
Die offizielle Website für dots.ocr befindet sich unter
- GitHub-Repository:: https://github.com/rednote-hilab/dots.ocr
- HuggingFace-Modellbibliothek:: https://huggingface.co/rednote-hilab/dots.ocr
- Online-Erlebnis-Demo:: https://dotsocr.xiaohongshu.com/
Wie man dots.ocr verwendet
- Besuchen Sie das Online-ErlebnisBesuchen Sie dots.ocr für die Adresse der Demo Experience.
- Ein Dokument hochladenKlicken Sie auf die Schaltfläche "Datei hochladen" und wählen Sie die PDF- oder Bilddatei aus, die Sie analysieren möchten.
- Wählen Sie eine AufgabeAuswahl von Aufgaben je nach Bedarf, z. B. Layout-Erkennung, Inhaltserkennung, Formelparsing oder Tabellenextraktion.
- Start des ParsingKlicken Sie auf die Schaltfläche "Start Parsing" und das Modell wird das Dokument automatisch verarbeiten.
- Ergebnisse anzeigenNach Abschluss des Parsings wählen Sie ein anderes Ausgabeformat.
- Herunterladen oder Kopieren der ErgebnisseKlicken Sie auf die Schaltfläche "Herunterladen" oder "Kopieren", um die Ergebnisse zu speichern oder zu verwenden.
Die wichtigsten Vorteile von dots.ocr
- Hohe Leistung und kleiner ModellvorteilDie Anzahl der Modellparameter beträgt nur 1,7 Milliarden, mit branchenführender Leistung, schneller Inferenzgeschwindigkeit und geringem Ressourcenverbrauch.
- Kompetenz in Mehrsprachigkeit und kleinen SprachenUnterstützung für viele gängige Sprachen und hervorragende Leistung beim Parsen von Dokumenten in kleinen Sprachen, mit einem breiten Spektrum von Anwendungen.
- Flexible Anpassbarkeit der AufgabenUmschalten zwischen verschiedenen Aufgaben durch einfaches Eintippen des Stichworts ist ohne Umlernen oder Anpassung der Modellarchitektur möglich.
- Einheitliches Layout und einheitliche Handhabung der Inhalte:Durch die Integration von Layout-Erkennung und Inhaltserkennung in ein einziges Modell wird das Problem der Trennung von Layout und Inhalt bei herkömmlichen Methoden vermieden und die Kohärenz der Parsing-Ergebnisse sichergestellt.
- Vielfältige Ausgabe und VisualisierungUnterstützt mehrere Ausgabeformate und bietet Layout-Visualisierungsbilder zum einfachen visuellen Verständnis und zur Weiterverarbeitung.
- Open Source und Unterstützung durch die GemeinschaftOffener Quellcode und ausführliche Dokumentation für Entwickler zur Erleichterung der Sekundärentwicklung und Anpassung, mit einer aktiven Community.
Personen, für die dots.ocr bestimmt ist
- Forscher und Akademikerdots.ocr analysiert Formeln und Diagramme in der akademischen Literatur und hilft Forschern, effizient auf wichtige Informationen zuzugreifen und die akademische Forschung zu beschleunigen.
- Praktiker der FinanzindustrieFinanzanalysten und Compliance-Beauftragte automatisieren die Extraktion von Daten und Tabellen aus Finanzberichten und verbessern so die Effizienz von Finanzdatenanalysen und Compliance-Prüfungen.
- Lehrkräfte und StudentenLehrer und Schüler nutzen dots.ocr, um Lehrbücher und Prüfungsunterlagen zu analysieren, um das Lehren und Lernen zu unterstützen und um die Informationstechnologie im Bildungswesen zu fördern.
- Interne DokumentenmanagerGeschäftsleitung und Projektmanager bearbeiten Besprechungsprotokolle und Projektberichte, extrahieren wichtige Informationen und optimieren die Prozesse der Dokumentenverwaltung.
- Entwickler und technische MissionenTeam: Die Entwickler integrieren das Modell in die Anwendung, um die Funktionalität des Dokumentenparsing zu erreichen und verschiedene Entwicklungsanforderungen zu erfüllen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...