Dolphin - Wordpress Open-Source-leichte Dokument-Parsing großes Modell

Was ist ein Delphin?
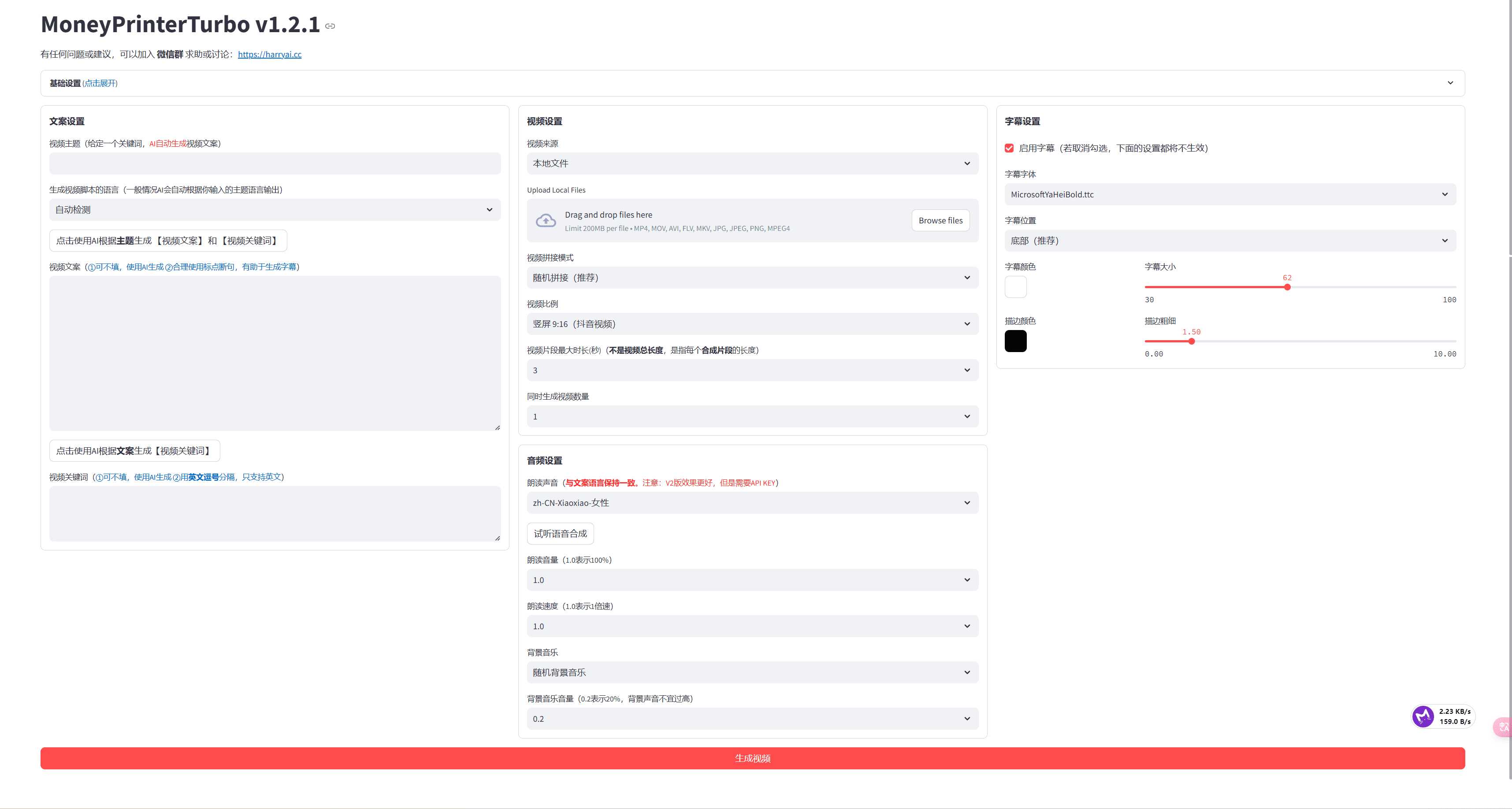
Dolphin ist ein Byte-Sprung Open-Source-leichte Dokumenten-Parsing großes Modell, mit 322M Parameter, geringe Größe und schnelle Laufgeschwindigkeit. Das Modell basiert auf einem zweistufigen Parsing-Ansatz, basierend auf Seiten-Level-Layout-Analyse, um die Elemente des Dokuments (wie Titel, Tabellen, Formeln, etc.) zu identifizieren, und dann jedes Element des Inhalts der Analyse, unterstützt das Modell die Extraktion von Text, Formeln, Tabellen und andere Elemente, Unterstützung für die Ausgabe von JSON, Markdown, HTML-Format, etc. Dolphin gilt für die akademische Forschung, kommerzielle Büro, Bildung, Technologie-Entwicklung und andere Dolphin eignet sich für den Einsatz in der akademischen Forschung, im kaufmännischen Bereich, im Bildungswesen, in der technologischen Entwicklung usw. Dolphin kann akademische Arbeiten, Geschäftsberichte, technische Dokumente usw. effizient verarbeiten, bei der Digitalisierung von Dokumenten und der Extraktion von Informationen helfen und die Effizienz im Büro verbessern.

Die wichtigsten Merkmale von Dolphin
- Layout-AnalyseIdentifiziert Titel, Diagramme, Tabellen, Fußnoten und andere Elemente in einem Dokument genau und erzeugt eine klare Reihenfolge der Elemente auf der Grundlage der natürlichen Lesereihenfolge, die die Grundlage für die anschließende Analyse des Inhalts bildet.
- InhaltsextraktionParsen von Dokumentseiten in ein strukturiertes JSON- oder Markdown-Format zur Weiterverarbeitung und Präsentation.
- Text-ParsingGenaue Extraktion von Textinhalten aus Dokumenten, die Chinesisch, Englisch und viele andere Sprachen umfassen.
- FormelerkennungUnterstützt die Erkennung komplexer Formeln auf Zeilen- und Blockebene und gibt sie im LaTeX-Format aus, um die Bearbeitung akademischer und technischer Dokumente zu erleichtern.
- TabellenanalyseUnterstützung für das Parsen komplexer Tabellenstrukturen und das Extrahieren von Zelleninhalten, um HTML-formatierte Tabellen zu erzeugen, die den Anforderungen einer Vielzahl von Anwendungsszenarien gerecht werden.
- Leichte ArchitekturDas Modell hat die Referenznummer 322M, ist klein und schnell und eignet sich für den Einsatz in Geräten oder Umgebungen mit eingeschränkten Ressourcen.
- Mehrere Eingänge und AusgängeEs unterstützt verschiedene Eingaben von Dokumentenbildern wie akademische Arbeiten, Geschäftsberichte, technische Dokumente usw. Die Parsing-Ergebnisse können in JSON, Markdown, HTML und anderen Formaten ausgegeben werden, was die Integration in verschiedene Systeme erleichtert.
Offizielle Website-Adresse von Dolphin
- GitHub-Repository::https://github.com/bytedance/Dolphin
- HuggingFace-Modellbibliothek::https://huggingface.co/ByteDance/Dolphin
- arXiv Technisches Papier::https://arxiv.org/pdf/2505.14059
- Online-Erlebnis-Demo::http://115.190.42.15:8888/dolphin/
Wie man Dolphin benutzt
- Online-Erlebnis-DemoBesuchen Sie die Dolphin-Online-Demoadresse, und der Benutzer lädt direkt Dokumentbilder zur Analyse hoch, ohne eine Umgebung installieren oder konfigurieren zu müssen.
- GitHub-Repository-Bereitstellung::
- Klon-Lager::
git clone https://github.com/bytedance/Dolphin.git
cd Dolphin- Installation von Abhängigkeiten::
pip install -r requirements.txt- Herunterladen des vortrainierten ModellsDownloaden und entpacken Sie die vortrainierten Modelldateien gemäß den Anweisungen im GitHub-Repository.
- laufender CodeStarten Sie Dolphin anhand des Beispielcodes aus dem Repository, zum Beispiel:
from dolphin import DolphinParser
parser = DolphinParser(model_path="path/to/model")
result = parser.parse(image_path="path/to/document.jpg")
print(result)- Umarmendes Gesicht Modellbibliothek::
- Installieren der Hugging Face Library::
pip install transformers- Modelle laden::
from transformers import AutoModelForDocumentParsing, AutoFeatureExtractor
model_name = "ByteDance/Dolphin"
model = AutoModelForDocumentParsing.from_pretrained(model_name)
feature_extractor = AutoFeatureExtractor.from_pretrained(model_name)
# 加载文档图像并进行预处理
image = feature_extractor(images="path/to/document.jpg", return_tensors="pt")
# 进行解析
outputs = model(**image)
# 处理输出结果- Verarbeitung der AusgabeergebnisseWeiterverarbeitung und Verwendung der Parsing-Ergebnisse auf der Grundlage des Ausgabeformats des Modells (z. B. JSON, HTML usw.).
Die Stärken von Dolphin
- Leicht & EffizientDolphin ist nur 322 MB groß, klein und schnell und eignet sich für ressourcenbeschränkte Umgebungen.
- Zweistufiger Parsing-AnsatzParsing des Layouts vor dem Inhalt, basierend auf paralleler Verarbeitung zur Verbesserung von Effizienz und Genauigkeit.
- Leistungsstarkes Document ParsingUnterstützt das Parsen von Text, Tabellen, Formeln, Diagrammen und anderen Elementen zur Abdeckung komplexer Dokumentstrukturen.
- Unterstützung mehrerer SprachenErkennen von chinesischem, englischem und anderem mehrsprachigem Text, um den Anforderungen der mehrsprachigen Dokumentenverarbeitung gerecht zu werden.
- Vielfältige Inputs und OutputsKompatibel mit einer Vielzahl von Dokumentformaten bei der Eingabe, Unterstützung für JSON, Markdown, HTML und andere Formate bei der Ausgabe, einfach zu integrieren.
- Open Source und BenutzerfreundlichkeitDer Code und die vortrainierten Modelle sind quelloffen und bieten Entwicklern reichhaltige Ressourcen, um schnell mit der Entwicklung beginnen und sie anpassen zu können.
- Hohe LeistungÜbertrifft Mainstream-Modelle wie GPT-4.1 und Mistral-OCR beim Parsen von Dokumenten und übertrifft sie bei der Erkennung von Tabellen und Formeln.
Für wen ist Dolphin gedacht?
- ForschungsmitarbeiterSchnelles Parsen von Text, Formeln und Diagrammen in akademischen Arbeiten, um die Literatur effizient zu organisieren und Schlüsselinformationen zu extrahieren und die wissenschaftliche Arbeit zu beschleunigen.
- Mitarbeiter der GeschäftsstelleGeschäftsleute extrahieren Schlüsselinformationen aus Verträgen, Berichten und anderen Geschäftsdokumenten, um die Überprüfung von Verträgen und die Erstellung von Berichten zu unterstützen und die Effizienz im Büro zu verbessern.
- ErzieherinLehrkräfte und Bildungseinrichtungen nutzen Dolphin, um Unterrichtsmaterialien und Prüfungsunterlagen zu digitalisieren, den Online-Unterricht und die Mehrsprachigkeit zu unterstützen und die Lehrmittel zu bereichern.
- Technologie-EntwicklerEntwickler analysieren die technische Dokumentation, um die Verwaltung des Codes und den technischen Austausch zu erleichtern, sowie die sekundäre Entwicklung und Anpassung auf der Grundlage von Open-Source-Code.
- Schülerinnen und SchülerDie Schüler können ihr Lernmaterial schnell ordnen und die wichtigsten Punkte herausziehen, um das Lernen und Wiederholen zu erleichtern.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...