
Wie werden große Modelle "schlauer"? Die Stanford University enthüllt den Schlüssel zur Selbstverbesserung: vier kognitive Verhaltensweisen

Der Bereich der künstlichen Intelligenz hat in den letzten Jahren beeindruckende Fortschritte gemacht, insbesondere im Bereich der Modellierung großer Sprachen (LLM). Viele Modelle, wie z.B. Qwen, haben eine erstaunliche Fähigkeit gezeigt, Antworten selbst zu überprüfen und Fehler zu korrigieren. Allerdings sind nicht alle Modelle gleichermaßen zur Selbstverbesserung fähig. Bei gleichen zusätzlichen Rechenressourcen und "Denk"-Zeiten sind einige Modelle in der Lage, diese Ressourcen optimal zu nutzen und ihre Leistung drastisch zu verbessern, während andere kaum Erfolg haben. Dieses Phänomen wirft die Frage auf: Welche Faktoren sind für diese Diskrepanz verantwortlich?
Genauso wie Menschen mehr Zeit damit verbringen, tiefgründig nachzudenken, wenn sie mit schwierigen Problemen konfrontiert werden, beginnen einige fortgeschrittene Modelle großer Sprachen ein ähnliches Denkverhalten an den Tag zu legen, wenn sie durch Verstärkungslernen auf Selbstverbesserung trainiert werden. Allerdings gibt es signifikante Unterschiede in der Selbstverbesserung zwischen Modellen, die mit demselben Verstärkungslernen trainiert wurden. Zum Beispiel ist Qwen-2.5-3B dem Llama-3.2-3B im Countdown-Spiel weit überlegen. Obwohl beide Modelle in der Anfangsphase relativ schwach sind, erreicht Qwen am Ende des Trainings mit verstärktem Lernen eine Genauigkeit von etwa 60%, während Llama nur etwa 30% erreicht. Welcher Mechanismus verbirgt sich hinter diesem signifikanten Unterschied?
Eine kürzlich in Stanford durchgeführte Studie hat die Mechanismen, die hinter der Fähigkeit großer Modelle zur Selbstverbesserung stehen, genauer untersucht und gezeigt, dass wichtige Sprachmodelle in den zugrunde liegenden kognitives Verhalten Die Bedeutung der KI. Diese Forschung bietet neue Perspektiven für das Verständnis und die Verbesserung der Selbstverbesserungsfähigkeiten von KI-Systemen.
Die Studie wurde nach ihrer Veröffentlichung breit diskutiert. Der CEO von Synth Labs beispielsweise hält die Entdeckung für spannend, weil sie verspricht, in jedes Modell integriert zu werden, um dessen Leistung zu verbessern.

Vier wichtige kognitive Verhaltensweisen
Um die Gründe für die Unterschiede in der Selbstverbesserung zu untersuchen, konzentrierten sich die Forscher auf zwei Basismodelle, Qwen-2.5-3B und Llama-3.2-3B. Indem sie diese mit Verstärkungslernen im Spiel Countdown trainierten, stellten die Forscher signifikante Unterschiede fest: Qwens Problemlösungsfähigkeit verbesserte sich deutlich, während Llama-3 während desselben Trainingsprozesses relativ geringe Verbesserungen zeigte. Welche Modelleigenschaften sind also für diesen Unterschied verantwortlich?

Um diese Frage systematisch zu untersuchen, entwickelte das Forschungsteam einen Rahmen für die Analyse der kognitiven Verhaltensweisen, die für die Problemlösung entscheidend sind. Der Rahmen beschreibt vier wichtige kognitive Verhaltensweisen:
- Überprüfung:: Systematische Fehlerprüfung.
- Backtracking:: Gescheiterte Ansätze aufgeben und neue Wege ausprobieren.
- Teilzielsetzung:: Zerlegen Sie komplexe Probleme in überschaubare Schritte.
- Umkehrung des DenkensUmgekehrte Ableitung vom gewünschten Ergebnis zur ursprünglichen Eingabe.
Diese Verhaltensmuster ähneln stark der Art und Weise, wie erfahrene Problemlöser an komplexe Aufgaben herangehen. So führen Mathematiker beispielsweise Beweise durch, indem sie jeden Schritt der Ableitung sorgfältig überprüfen, bei Widersprüchen zurückgehen, um frühere Schritte zu überprüfen, und komplexe Theoreme in einfachere Lemmata für schrittweise Beweise zerlegen.

Vorläufige Analysen deuten darauf hin, dass das Qwen-Modell dieses Inferenzverhalten von Natur aus aufweist, insbesondere in den Bereichen Validierung und Backtracking, während das Llama-3-Modell diese Verhaltensweisen auffallend wenig aufweist. Auf der Grundlage dieser Beobachtungen formulierten die Forscher die Kernhypothese: Bestimmte logische Verhaltensweisen in der anfänglichen Strategie sind entscheidend dafür, dass das Modell die längere Testzeit effektiv nutzen kann. Mit anderen Worten: Wenn ein KI-Modell "schlauer" werden will, wenn es mehr Zeit zum "Denken" hat, muss es zunächst über einige grundlegende Denkfähigkeiten verfügen, wie z. B. die Gewohnheit, nach Fehlern zu suchen und die Ergebnisse zu überprüfen. Wenn dem Modell diese grundlegenden Denkfähigkeiten von Anfang an fehlen, wird es nicht in der Lage sein, seine Leistung effektiv zu verbessern, selbst wenn es mehr Denkzeit und Rechenressourcen erhält. Dies ist dem menschlichen Lernprozess sehr ähnlich - wenn es den Schülern an grundlegenden Fähigkeiten zur Selbstkontrolle und Fehlerkorrektur mangelt, ist es unwahrscheinlich, dass sie ihre Leistungen durch längere Prüfungen wesentlich verbessern können.
Experimentelle Validierung: die Bedeutung des kognitiven Verhaltens
Um die oben genannte Hypothese zu testen, führten die Forscher eine Reihe von cleveren Interventionsexperimenten durch.
Zunächst versuchten sie, das Llama-3-Modell mit synthetischen Inferenz-Trajektorien, die bestimmte kognitive Verhaltensweisen (insbesondere Retrospektion) enthalten, zu booten. Die Ergebnisse zeigen, dass das so geführte Llama-3-Modell signifikante Verbesserungen beim Verstärkungslernen zeigt, mit Leistungsgewinnen, die sogar mit Qwen-2.5-3B vergleichbar sind.
Zweitens konnte das Llama-3-Modell auch dann noch Fortschritte machen, wenn die für das Bootstrapping verwendeten Argumentationsbahnen falsche Antworten enthielten, solange diese Bahnen korrekte Argumentationsmuster aufwiesen. Dieses Ergebnis legt nahe, dass das Der Schlüsselfaktor, der die Selbstverbesserung des Modells wirklich vorantreibt, ist das Vorhandensein eines schlussfolgernden Verhaltens, nicht die Korrektheit der Antwort selbst.
Schließlich filterten die Forscher den OpenWebMath-Datensatz, um diese Schlussfolgerungen hervorzuheben, und verwendeten diese Daten für das Vortraining des Llama-3-Modells. Die experimentellen Ergebnisse zeigen, dass diese gezielte Anpassung der Vortrainingsdaten wirksam ist, um das für eine effiziente Nutzung der Rechenressourcen durch das Modell erforderliche Schlussfolgerungsverhalten zu induzieren. Der Verlauf der Leistungsverbesserung des getunten, vortrainierten Llama-3-Modells ist überraschenderweise konsistent mit dem des Qwen-2.5-3B-Modells.
Die Ergebnisse dieser Experimente lassen einen engen Zusammenhang zwischen dem anfänglichen Denkverhalten eines Modells und seiner Fähigkeit, sich selbst zu verbessern, erkennen. Dieser Zusammenhang hilft zu erklären, warum einige Sprachmodelle in der Lage sind, zusätzliche Rechenressourcen effizient zu nutzen, während andere stagnieren. Ein tieferes Verständnis dieser Dynamik ist für die Entwicklung von KI-Systemen, die das Lösen von Problemen erheblich verbessern können, von wesentlicher Bedeutung.
Countdown-Spiel mit Modellauswahl
Die Studie beginnt mit einer überraschenden Beobachtung: Sprachmodelle ähnlicher Größe, die zu verschiedenen Modellfamilien gehören, zeigen sehr unterschiedliche Leistungsverbesserungen, wenn sie mit Verstärkungslernen trainiert werden. Um dieses Phänomen eingehend zu untersuchen, wählten die Forscher das Spiel Countdown als primäre Testumgebung.
Bei Countdown handelt es sich um ein Mathematikrätsel, bei dem der Spieler eine vorgegebene Zahlenreihe mit den vier Grundrechenarten Addition, Subtraktion, Multiplikation und Division kombinieren muss, um eine Zielzahl zu erreichen. Wenn zum Beispiel die Zahlen 25, 30, 3, 4 und die Zielzahl 32 gegeben sind, muss der Spieler durch eine Reihe von Operationen genau die Zahl 32 erhalten, z. B. (30 - 25 + 3) × 4 = 32.
Das Countdown-Spiel wurde für diese Studie ausgewählt, weil es die Fähigkeiten des mathematischen Denkens, der Planung und der Suchstrategie des Modells untersucht und gleichzeitig einen relativ begrenzten Suchraum bietet, der dem Forscher die Durchführung tiefgreifender Analysen ermöglicht. Im Vergleich zu komplexeren Domänen reduziert das Countdown-Spiel den Schwierigkeitsgrad der Analyse und untersucht dennoch effektiv das komplexe Denkvermögen. Außerdem hängt der Erfolg von Countdown mehr von den Problemlösungsfähigkeiten als von anderen mathematischen Aufgaben ab und weniger von reinem mathematischem Wissen.
Die Forscher wählten zwei Basismodelle, Qwen-2.5-3B und Llama-3.2-3B, um die Lernunterschiede zwischen den verschiedenen Modellfamilien zu vergleichen. Die Experimente zum Verstärkungslernen basieren auf der VERL-Bibliothek und wurden mit TinyZero implementiert. Sie verwendeten den PPO-Algorithmus (Proximal Policy Optimization), um das Modell für 250 Schritte zu trainieren, wobei 4 Trajektorien pro Cue gesampelt wurden. Der Grund für die Wahl des PPO-Algorithmus ist, dass er im Vergleich zum GRPO und anderen Reinforcement-Learning-Algorithmen wie REINFORCE zeigt PPO eine bessere Stabilität bei verschiedenen Hyperparametereinstellungen, obwohl der Leistungsunterschied zwischen den Algorithmen insgesamt nicht signifikant ist. (Anmerkung des Herausgebers: Es wird vermutet, dass das ursprüngliche "GRPO" ein Schreibfehler ist und PPO heißen sollte.)
Die experimentellen Ergebnisse zeigen sehr unterschiedliche Lernkurven für die beiden Modelle. Obwohl beide zu Beginn der Aufgabe mit niedrigen Werten ähnlich abschneiden, zeigt Qwen-2.5-3B um den 30. Trainingsschritt herum einen "qualitativen Sprung", der sich in deutlich längeren Antworten des Modells und einer signifikanten Steigerung der Genauigkeit äußert. Am Ende des Trainings erreicht Qwen-2.5-3B eine Genauigkeit von ca. 601 TP3T, was deutlich höher ist als die 301 TP3T von Llama-3.2-3B.
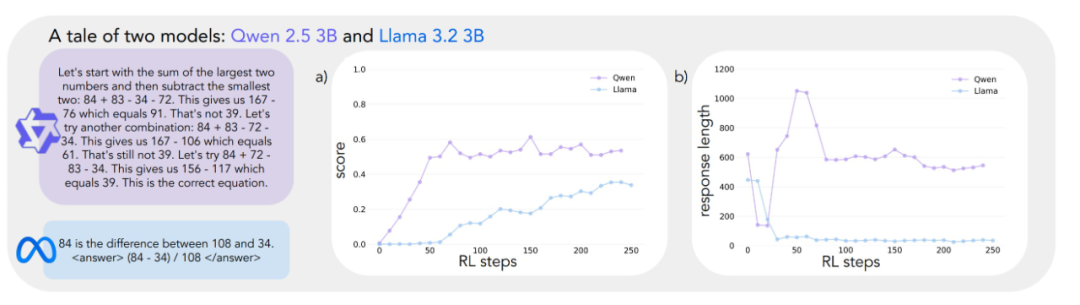
In späteren Phasen des Trainings beobachteten die Forscher eine interessante Veränderung im Verhalten von Qwen-2.5-3B: Das Modell ging allmählich von der Verwendung expliziter Validierungsaussagen (z. B. "8*35 ist 280, zu hoch") zur impliziten Lösungsüberprüfung über. Das Modell probiert последовательно (auf Russisch mit "последовательно land" oder "sequentiell" übersetzt) verschiedene Lösungen aus, bis es die richtige findet, und bewertet seine eigene Arbeit nicht mehr mit Worten. Der Kontrast ist frappierend. Dieser Kontrast führt zu einer zentralen Frage: Was sind die zugrundeliegenden Fähigkeiten, die es einem Modell ermöglichen, sich auf der Grundlage von Schlussfolgerungen erfolgreich selbst zu verbessern? Die Beantwortung dieser Frage erfordert einen systematischen Rahmen für die Analyse des kognitiven Verhaltens.
Rahmen der kognitiven Verhaltensanalyse (Cognitive Behavioural Analysis)
Um ein tieferes Verständnis der sehr unterschiedlichen Lernverläufe der beiden Modelle zu erlangen, entwickelten die Forscher einen Rahmen zur Identifizierung und Analyse der wichtigsten kognitiven Verhaltensweisen in den Modellergebnissen. Der Rahmen konzentriert sich auf vier grundlegende Verhaltensweisen:
- BacktrackingExplizite Änderung der Methode, wenn ein Fehler festgestellt wird (z. B. "Diese Methode funktioniert nicht, weil ..."). .").
- Überprüfung: Systematische Überprüfung von Zwischenergebnissen (z.B. "Let's validate this result by ... um dieses Ergebnis zu überprüfen").
- TeilzielsetzungKomplexe Probleme in überschaubare Schritte zerlegen (z. B. "Um dieses Problem zu lösen, müssen wir zuerst ..."). .
- Umkehrung des DenkensZielgerichtetes Denken: Beginnen Sie mit einem gewünschten Ergebnis und arbeiten Sie rückwärts, um einen Weg zur Lösung zu finden (z. B. "Um das Ziel 75 zu erreichen, brauchen wir eine Zahl, die ... teilbar ist durch ..."). .").
Diese Verhaltensweisen wurden ausgewählt, weil sie eine ganz andere Problemlösungsstrategie darstellen als die linearen, monotonen Denkmuster, die in Sprachmodellen üblich sind. Diese kognitiven Verhaltensweisen ermöglichen dynamischere, suchähnliche Gedankengänge, bei denen sich die Lösungen auf nichtlineare Weise entwickeln können. Obwohl diese Verhaltensweisen nicht vollständig sind, haben die Forscher sie ausgewählt, weil sie leicht zu identifizieren sind und natürlich zu den menschlichen Problemlösungsstrategien in Countdown-Spielen und in weiter gefassten mathematischen Denkaufgaben, wie der Konstruktion mathematischer Beweise, passen.
Jedes kognitive Verhalten lässt sich durch seine Rolle bei der Begründung der Token Backtracking wird beispielsweise durch die explizite Negierung und Ersetzung von Token-Sequenzen früherer Schritte dargestellt. Backtracking wird beispielsweise durch eine Abfolge von Token dargestellt, die explizit vorherige Schritte negieren und ersetzen; Validierung wird durch die Erzeugung von Token dargestellt, die Ergebnisse mit Lösungskriterien vergleichen; Backtracking wird durch Token dargestellt, die inkrementell einen Lösungspfad vom Ziel zum Ausgangszustand aufbauen; und Teilzielsetzung wird durch explizite Vorschläge für Zwischenschritte dargestellt, die auf dem Weg zum Endziel erreicht werden sollen. Die Forscher entwickelten eine Klassifizierungspipeline unter Verwendung des GPT-4o-mini-Modells, die diese Muster in der Modellausgabe zuverlässig identifiziert.
Die Auswirkungen des anfänglichen Verhaltens auf die Selbstverbesserung
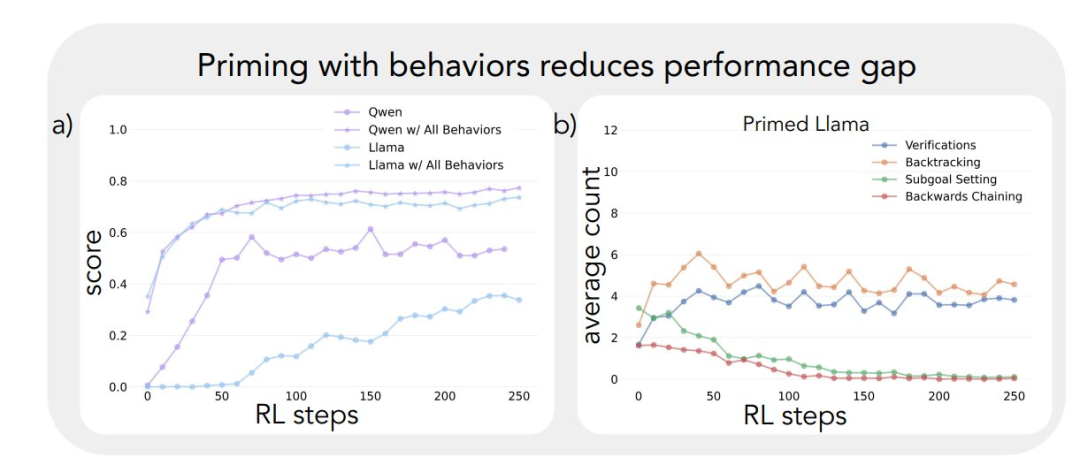
Die Anwendung des oben beschriebenen analytischen Rahmens auf die ersten Experimente führte zu einer wichtigen Erkenntnis: Die signifikante Verbesserung der Leistung des Qwen-2.5-3B-Modells geht einher mit dem Auftreten von kognitiven Verhaltensweisen, insbesondere von Verifikations- und Backtracking-Verhaltensweisen. Im Gegensatz dazu zeigte das Modell Llama-3.2-3B während des gesamten Trainings kaum Anzeichen für diese Verhaltensweisen.
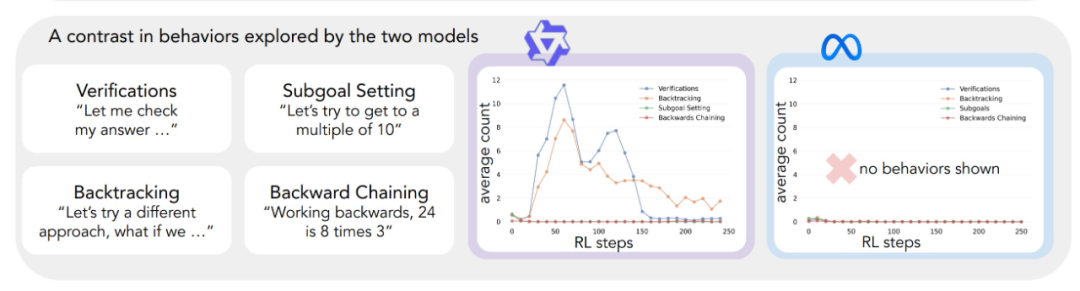
Um ein tieferes Verständnis dieses Unterschieds zu erlangen, analysierten die Forscher die grundlegenden Denkmuster der drei Modelle: Qwen-2.5-3B, Llama-3.2-3B und Llama-3.1-70B. Die Ergebnisse der Analysen zeigten, dass das Modell Qwen-2.5-3B höhere Anteile aller kognitiven Verhaltensweisen aufwies als die beiden Llama-Modellvarianten Llama-3.2-3B und Llama-3.1-70B. Das Modell Llama-2.5-3B ergab einen höheren Anteil aller kognitiven Verhaltensweisen. Obwohl das größere Modell Llama-3.1-70B diese Verhaltensweisen im Allgemeinen häufiger aktivierte als das Modell Llama-3.2-3B, war dieser Anstieg ungleichmäßig, insbesondere bei den retrospektiven Verhaltensweisen, die auch im größeren Modell begrenzt blieben.

Aus diesen Beobachtungen ergeben sich zwei wichtige Erkenntnisse:
- Das Vorhandensein bestimmter kognitiver Verhaltensweisen in der anfänglichen Strategie kann eine Voraussetzung dafür sein, dass das Modell die erhöhte Testzeitberechnung durch Erweiterung der Inferenzsequenz effektiv nutzen kann.
- Eine Erhöhung der Modellgröße kann die Häufigkeit der kontextuellen Aktivierung dieser kognitiven Verhaltensweisen bis zu einem gewissen Grad verbessern.
Dieses Modell ist von entscheidender Bedeutung, da Verstärkungslernen nur Verhaltensweisen verstärken kann, die bereits in erfolgreichen Bahnen vorhanden sind. Das bedeutet, dass die anfängliche Verfügbarkeit dieser kognitiven Verhaltensweisen eine Voraussetzung für effektives Lernen in diesem Modell ist.
Eingreifen in das anfängliche Verhalten: Steuerung des Modelllernens
Nachdem die Bedeutung der kognitiven Verhaltensweisen im Basismodell festgestellt wurde, lautet die nächste Frage: Können diese Verhaltensweisen im Modell durch gezielte Eingriffe künstlich hervorgerufen werden? Die Forscher stellten die Hypothese auf, dass durch die Schaffung von Varianten des Basismodells, die selektiv bestimmte kognitive Verhaltensweisen vor dem Training des Verstärkungslernens zeigen, ein tieferes Verständnis dafür erreicht werden könnte, welche Verhaltensmuster für effektives Lernen wesentlich sind.
Um diese Hypothese zu testen, entwarfen sie zunächst sieben verschiedene Einstiegsdatensätze mit dem Countdown-Spiel. Fünf dieser Datensätze betonten unterschiedliche Kombinationen von Verhaltensweisen: alle Strategiekombinationen, nur Backtracking, Backtracking und Validierung, Backtracking und Teilzielsetzung sowie Backtracking und Rückwärtsdenken. Zur Erstellung dieser Datensätze wurde das Claude-3.5-Sonnet-Modell verwendet, da Claude-3.5-Sonnet in der Lage ist, Inferenzkurven mit genau spezifizierten Verhaltensmerkmalen zu erzeugen.
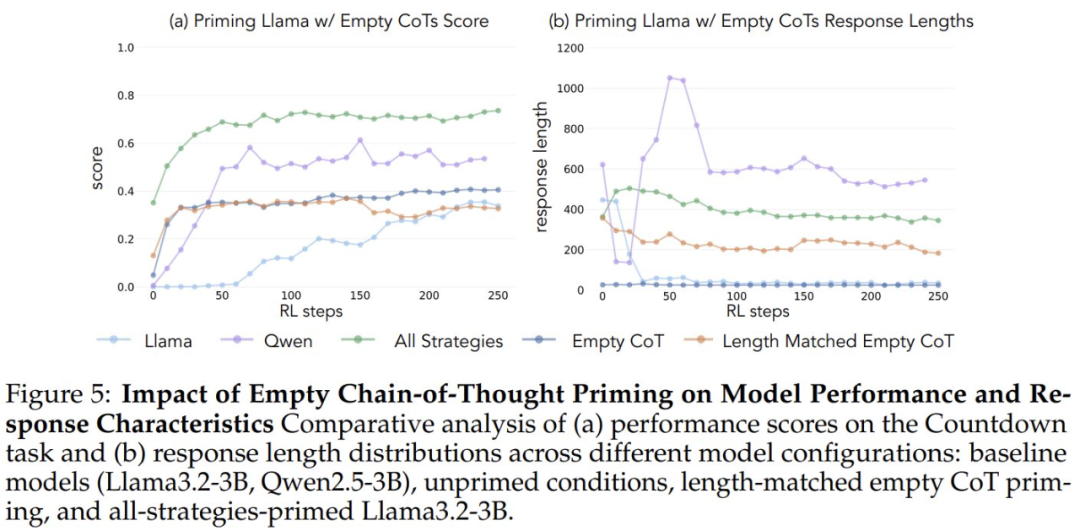
Um zu überprüfen, ob die Leistungssteigerungen auf spezifische kognitive Verhaltensweisen und nicht einfach auf einen Anstieg der Rechenzeit zurückzuführen sind, führten die Forscher auch zwei Kontrollbedingungen ein: eine leere Gedankenkette und eine Kontrollbedingung, bei der die Kette mit Platzhalter-Token gefüllt und die Länge der Datenpunkte an den Datensatz "alle Strategiekombinationen" angepasst wurde. Datensatz". Anhand dieser Kontrolldatensätze konnten die Forscher überprüfen, ob die beobachteten Leistungsverbesserungen tatsächlich auf bestimmte kognitive Verhaltensweisen zurückzuführen waren und nicht nur auf einen Anstieg der Rechenzeit.
Darüber hinaus haben die Forscher eine Variante des Datensatzes "Vollständige Strategiekombination" erstellt, die nur falsche Lösungen enthält, aber die erforderlichen Denkmuster beibehält. Der Zweck dieser Variante ist es, den Unterschied zwischen der Bedeutung des kognitiven Verhaltens und der Genauigkeit der Lösungen zu erkennen.
Experimentelle Ergebnisse zeigen, dass sowohl das Llama-3- als auch das Qwen-2.5-3B-Modell signifikante Leistungsverbesserungen durch Verstärkungslernen aufweisen, wenn sie mit einem Datensatz initialisiert werden, der retrospektives Verhalten enthält. Die Verhaltensanalyse zeigt außerdem, dass Beim Verstärkungslernen werden Verhaltensweisen, die sich empirisch als nützlich erwiesen haben, selektiv verstärkt, während andere Verhaltensweisen gehemmt werden. In der Bedingung "Vollständige Strategiekombination" beispielsweise behält das Modell retrospektive und validierende Verhaltensweisen bei und verstärkt sie, während es die Häufigkeit von Rückwärtsdenken und Unterzielsetzung reduziert. Wenn es jedoch nur mit retrospektiven Verhaltensweisen gepaart ist, bleiben unterdrückte Verhaltensweisen (z. B. Rückwärtsdenken und Teilzielsetzung) während des gesamten Trainings bestehen.
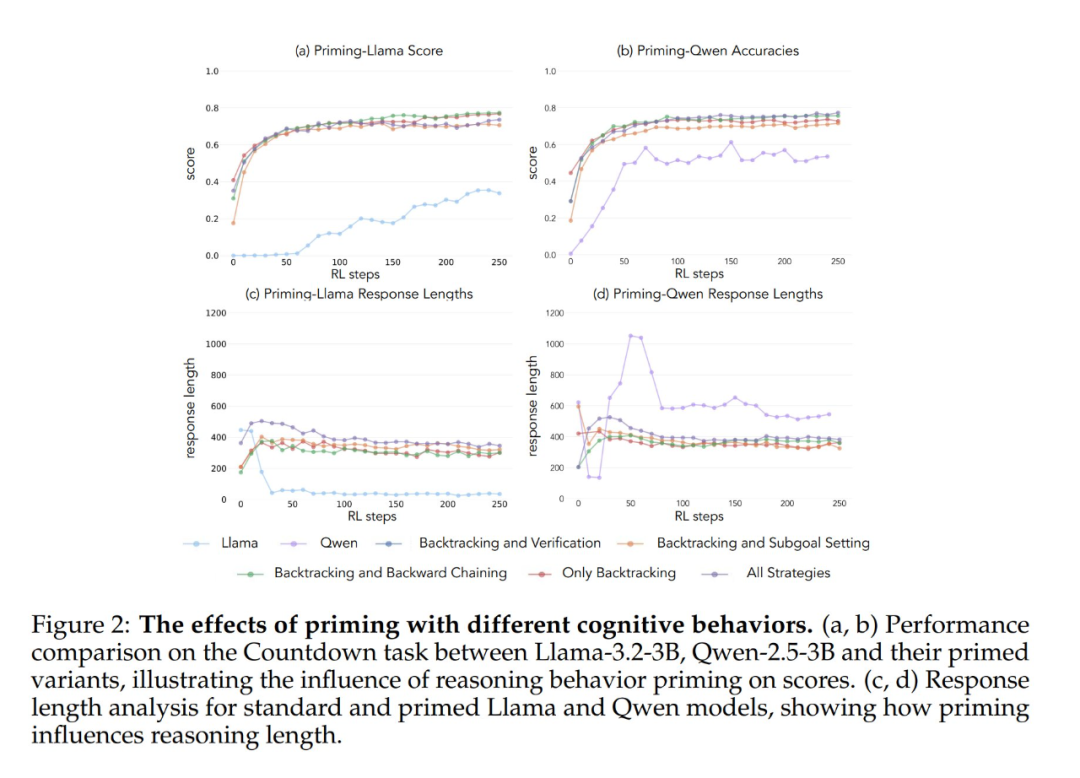
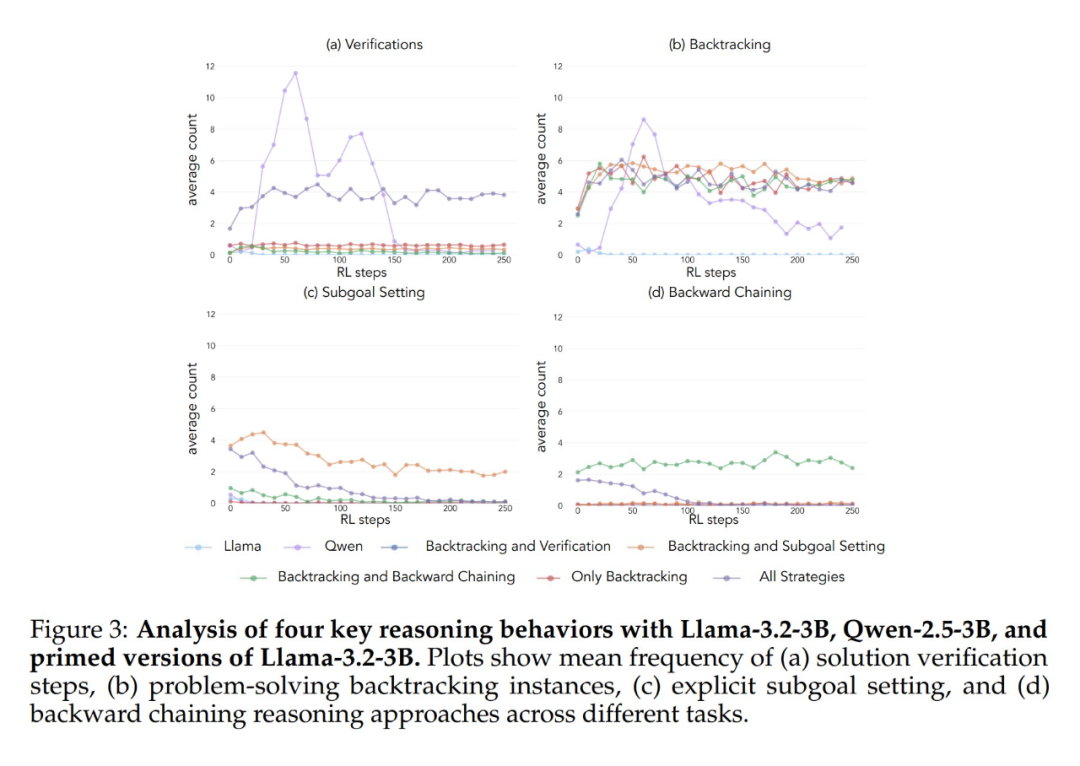
Wenn eine leere Gedankenkette als Kontrollbedingung verwendet wurde, schnitten beide Modelle vergleichbar gut ab wie das Llama-3-Basismodell (Genauigkeiten von etwa 30%-35%). Dies deutet darauf hin, dass die einfache Zuweisung zusätzlicher Token ohne Einbeziehung kognitiver Verhaltensweisen keine effiziente Nutzung der Testzeitberechnung darstellt. Noch überraschender ist, dass sich das Training mit leeren Gedankenketten sogar nachteilig auswirkte, da das Qwen-2.5-3B-Modell keine neuen Verhaltensmuster mehr erforschte. Dies ist ein weiterer Beweis dafür, dass Diese kognitiven Verhaltensweisen sind entscheidend dafür, dass das Modell die erweiterten Rechenressourcen durch längere Inferenzsequenzen effizient nutzen kann.
Noch überraschender ist, dass Modelle, die mit falschen Lösungen, aber mit korrektem kognitiven Verhalten initialisiert wurden, fast das gleiche Leistungsniveau erreichten wie Modelle, die auf Datensätzen mit korrekten Lösungen trainiert wurden. Dieses Ergebnis deutet stark darauf hin, dass Das Vorhandensein kognitiver Verhaltensweisen (und nicht der Erwerb richtiger Antworten) ist ein Schlüsselfaktor für eine erfolgreiche Selbstverbesserung durch Verstärkungslernen. Folglich können Schlussfolgerungsmuster aus relativ schwachen Modellen den Lernprozess zur Erstellung stärkerer Modelle wirksam anleiten. Dies beweist einmal mehr, dass Das Vorhandensein von kognitivem Verhalten ist wichtiger als die Korrektheit des Ergebnisses.

Verhaltensauswahl in Daten vor dem Training
Die Ergebnisse dieser Experimente deuten darauf hin, dass bestimmte kognitive Verhaltensweisen für die Selbstverbesserung der Modelle wesentlich sind. Allerdings waren die Methoden, die in der vorangegangenen Studie verwendet wurden, um bestimmte Verhaltensweisen in den Ausgangsmodellen hervorzurufen, domänenspezifisch und stützten sich auf Countdown-Spiele. Dies kann die Generalisierungsfähigkeit der endgültigen Schlussfolgerung beeinträchtigen. Ist es also möglich, die Häufigkeit von vorteilhaftem Inferenzverhalten zu erhöhen, indem man die Verteilung der Pre-Trainingsdaten für das Modell verändert, um eine allgemeinere Fähigkeit zur Selbstverbesserung zu erreichen?
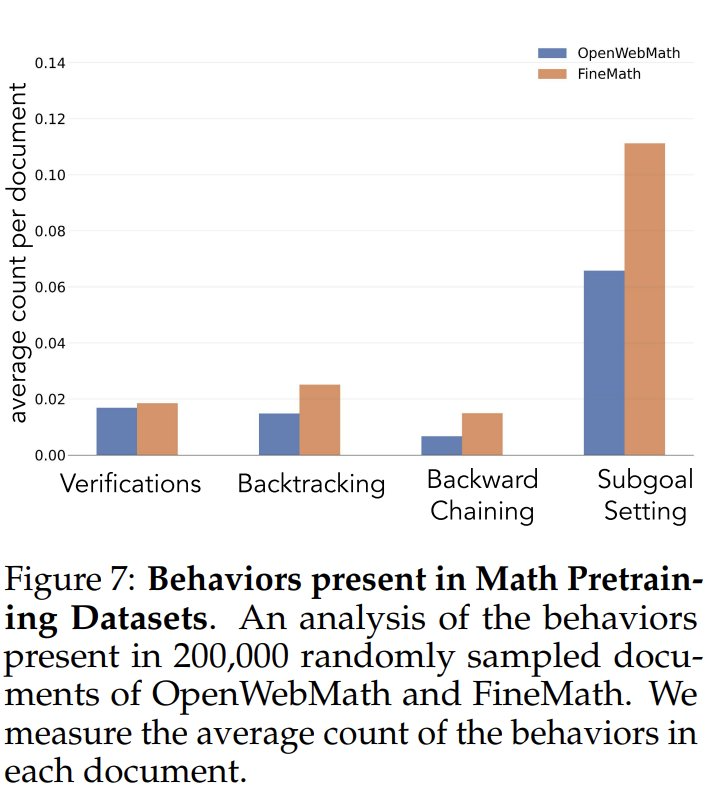
Um die Häufigkeit der kognitiven Verhaltensweisen in den Daten vor dem Training zu untersuchen, analysierten die Forscher zunächst die natürlichen Häufigkeiten der kognitiven Verhaltensweisen in den Daten vor dem Training. Sie konzentrierten sich dabei auf die OpenWebMath- und FineMath-Datensätze, die speziell für mathematisches Denken entwickelt wurden. Unter Verwendung des Qwen-2.5-32B-Modells als Klassifikator analysierten die Forscher 200.000 zufällig ausgewählte Dokumente aus diesen beiden Datensätzen auf das Vorhandensein des gewünschten kognitiven Verhaltens. Die Ergebnisse zeigten, dass selbst in diesen mathematisch ausgerichteten Korpora die Häufigkeit von kognitiven Verhaltensweisen wie Backtracking und Validierung gering blieb. Dies deutet darauf hin, dass die standardmäßigen Pre-Trainingsprozesse diese wichtigen Verhaltensmuster nur in begrenztem Maße berücksichtigen.
Um zu testen, ob eine künstliche Erhöhung der Exposition gegenüber kognitiven Verhaltensweisen das Selbstverbesserungspotenzial des Modells steigert, entwickelten die Forscher einen gezielten kontinuierlichen Vortrainingsdatensatz aus dem OpenWebMath-Datensatz. Sie nutzten zunächst das Qwen-2.5-32B-Modell als Klassifikator, um mathematische Dokumente aus dem Pre-Training-Korpus zu analysieren und das Vorhandensein des angestrebten Denkverhaltens zu identifizieren. Auf dieser Grundlage erstellten sie zwei Vergleichsdatensätze: einen mit vielen kognitiven Verhaltensweisen und einen Kontrolldatensatz mit sehr wenig kognitivem Inhalt. Anschließend wurde mit dem Qwen-2.5-32B-Modell jedes Dokument in beiden Datensätzen in ein strukturiertes Frage- und Antwortformat umgeschrieben, wobei das natürliche Vorhandensein bzw. Fehlen kognitiver Verhaltensweisen in den Quelldokumenten erhalten blieb. Die resultierenden Pre-Training-Datensätze enthielten jeweils insgesamt 8,3 Millionen Token. Dieser Ansatz ermöglichte es den Forschern, die Auswirkungen des Denkverhaltens effektiv zu isolieren und gleichzeitig das Format und die Menge des mathematischen Inhalts während des Pre-Trainings zu kontrollieren.
Nach dem Vortraining des Llama-3.2-3B-Modells auf diesen Datensätzen und der Anwendung von Reinforcement Learning beobachteten die Forscher:
- Verhaltensintensive, vortrainierte Modelle erreichen schließlich ein Leistungsniveau, das mit dem des Qwen-2.5-3B-Modells vergleichbar ist, wobei die Leistung des Kontrollmodells nur relativ begrenzt verbessert wird.
- Die Verhaltensanalyse der Modelle nach dem Training zeigte, dass die verhaltensmäßig angereicherte Variante des vortrainierten Modells während des gesamten Trainingsprozesses eine hohe Aktivierung des Inferenzverhaltens beibehielt, während das Kontrollmodell ähnliche Verhaltensmuster wie das Llama-3-Basismodell aufwies.
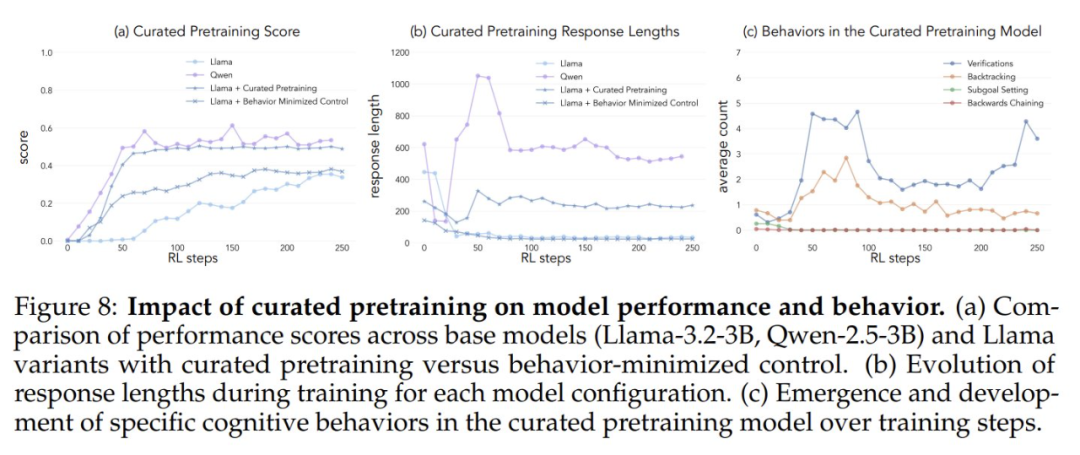
Die Ergebnisse dieser Experimente deuten stark darauf hin, dass Durch eine gezielte Modifizierung der vor dem Training erhobenen Daten können die wichtigsten kognitiven Verhaltensweisen, die für eine effektive Selbstverbesserung erforderlich sind, durch Verstärkungslernen erfolgreich erzeugt werden. Diese Studie liefert neue Ideen und Methoden zum Verständnis und zur Verbesserung der Selbstverbesserungsfähigkeiten großer Sprachmodelle. Weitere Einzelheiten finden Sie in der Originalarbeit.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...