
Wie lange kann ein Video von einem großen Modell verstanden werden? Smart Spectrum GLM-4V-Plus: 2 Stunden


Basierend auf den beiden vorangegangenen Generationen von Videomodellen (CogVLM2-Video und GLM-4V-PLUS) haben wir mit der Veröffentlichung der Beta-Version GLM-4V-Plus-0111 die Techniken zum Verstehen von Videos weiter optimiert. Diese Version führt Techniken wie die native variable Auflösung ein, die die Fähigkeit des Modells verbessert, sich an unterschiedliche Videolängen und Auflösungen anzupassen.
- Detaillierteres Verständnis von kurzen Videos: Für Inhalte mit kurzer Videolänge unterstützt das Modell native hochauflösende Videos, um die genaue Erfassung detaillierter Informationen zu gewährleisten.
- Besseres Verständnis langer Videos: Bei Videos mit einer Länge von bis zu 2 Stunden kann sich das Modell automatisch an eine geringere Auflösung anpassen und so die Erfassung zeitlicher und räumlicher Informationen effektiv ausbalancieren, um ein tiefgreifendes Verständnis langer Videos zu erreichen.
Mit diesem Update setzt die Beta-Version des GLM-4V-Plus-0111 nicht nur die Vorteile der beiden vorangegangenen Modellgenerationen in Bezug auf die zeitliche Q&A fort, sondern erzielt auch deutliche Verbesserungen bei der Videolänge und der Anpassbarkeit der Auflösung.
I. Leistungsvergleich
In dem kürzlich veröffentlichten Artikel Smart Spectrum Realtime, 4V, Air new model release, synchronisiert mit dem neuen API-Artikel, haben wir die Bewertungsergebnisse des Modells GLM-4V-Plus-0111 (beta) im Bereich des Bildverständnisses ausführlich dargestellt. Das Modell erreichte auf mehreren öffentlichen Bewertungslisten die Sota-Stufe.
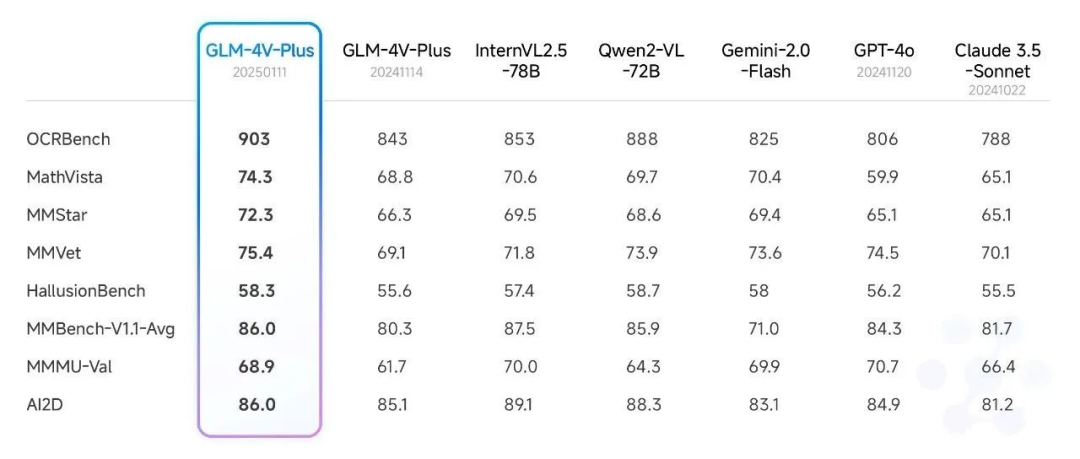
Darüber hinaus haben wir auch einen umfassenden Test mit einem maßgeblichen Videoverständnis-Review-Set durchgeführt und dabei ebenfalls ein relativ hohes Niveau erreicht. Insbesondere das GLM-4V-Plus-0111 Beta-Modell übertrifft vergleichbare Videoverstehensmodelle in Bezug auf das feinkörnige Handlungsverständnis in Videos und das Verständnis langer Videos deutlich.
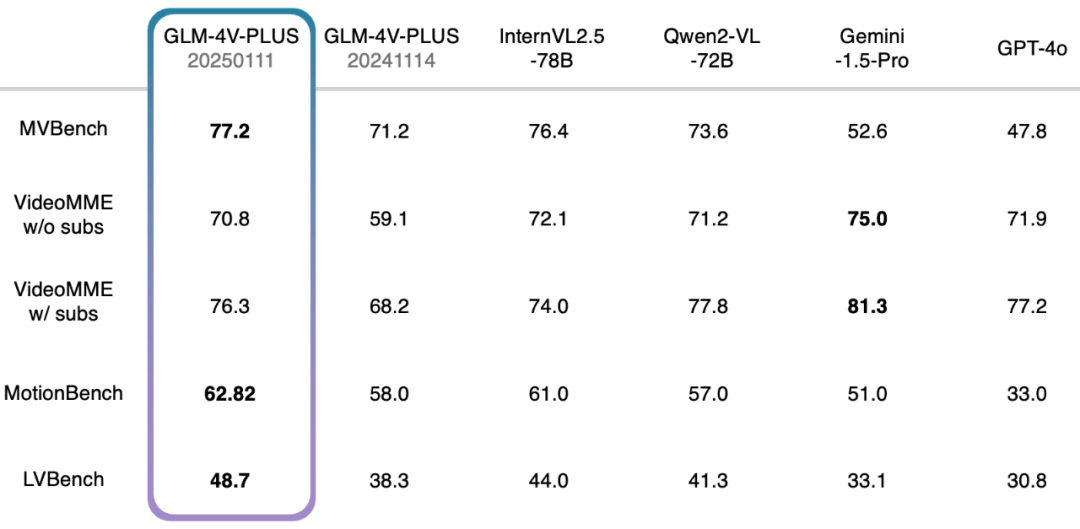
- MVBench: Dieser Prüfsatz besteht aus 20 komplexen Videoaufgaben, mit denen die kombinierten Fähigkeiten multimodaler Makromodelle beim Verstehen von Videos umfassend bewertet werden sollen.
- VideoMME ohne Untertitel: Als multimodaler Evaluierungsbenchmark wird VideoMME verwendet, um die Videoanalysefähigkeiten großer Sprachmodelle zu bewerten. In diesem Fall bezeichnet die Version ohne Untertitel eine multimodale Eingabe ohne Untertitel und konzentriert sich auf die Analyse des Videos selbst.
- VideoMME mit Untertiteln: Ähnlich wie die Version ohne Untertitel, aber mit dem Zusatz von Untertiteln als multimodale Eingaben, um eine umfassendere Bewertung der Gesamtleistung des Modells beim Umgang mit multimodalen Daten zu ermöglichen.
- MotionBench: MotionBench ist ein umfassender Benchmark-Datensatz, der verschiedene Videodaten und qualitativ hochwertige menschliche Anmerkungen enthält, um die Fähigkeiten von Videoverstehensmodellen für die Bewegungsanalyse zu evaluieren, wobei der Schwerpunkt auf feinkörnigem Bewegungsverständnis liegt.
- LVBench: Mit dem Ziel, die Fähigkeit des Modells, lange Videos zu verstehen, zu bewerten, stellt LVBench die Leistung multimodaler Modelle bei der Bewältigung der Aufgabe langer Videos auf die Probe und überprüft die Stabilität und Genauigkeit der Modelle bei der Analyse langer Zeitreihen.
II. Anwendung des Szenarios
Im vergangenen Jahr haben sich die Anwendungsbereiche von Videoverstehensmodellen erweitert und bieten vielfältige Funktionen wie die Erstellung von Videobeschreibungen, die Segmentierung von Ereignissen, die Klassifizierung, die Kennzeichnung und die Ereignisanalyse für neue Medien, Werbung, Sicherheitsüberprüfung, industrielle Fertigung und andere Branchen. Unser neu veröffentlichtes GLM-4V-Plus-0111 Beta-Videoverstehensmodell übernimmt und stärkt diese grundlegenden Funktionen und verbessert die Verarbeitungs- und Analysemöglichkeiten von Videodaten weiter.
Präzisere Videobeschreibung: Durch die Verwendung nativer Auflösungseingaben und die kontinuierliche Schwungrad-Phantomoptimierung reduziert das neue Modell die Phantomrate bei der Erstellung von Videobeschreibungen erheblich und ermöglicht eine umfassendere Beschreibung von Videoinhalten, so dass die Nutzer genauere und umfassendere Videoinformationen erhalten.


Effiziente Videodatenverarbeitung: Das neue Modell ist nicht nur in der Lage, detaillierte Videobeschreibungen zu liefern, sondern kann auch Videoklassifizierungs-, Titelerstellungs- und Etikettierungsaufgaben effizient erledigen. Benutzer können die Verarbeitungseffizienz weiter verbessern, indem sie die Eingabeaufforderungen anpassen oder automatisierte Videodatenprozesse für eine intelligente Verwaltung erstellen.

Präzises Zeitbewusstsein: Als Reaktion auf die zeitliche Dimension von Videodaten hat sich unser Modell seit seiner ersten Generation der Verbesserung der Zeitabfragekapazitäten gewidmet. Jetzt kann das neue Modell die Zeitpunkte bestimmter Ereignisse genauer lokalisieren, eine semantische Segmentierung und automatische Bearbeitung von Videos ermöglichen und eine leistungsstarke Unterstützung für die Videobearbeitung und -analyse bieten.
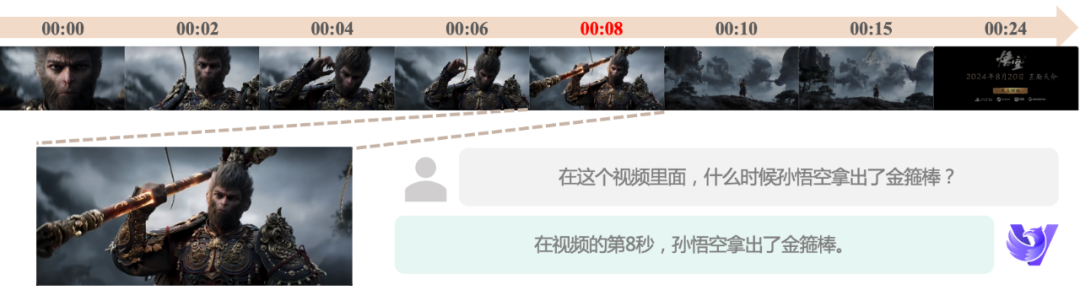
Feines Bewegungsverständnis: Das neue Modell unterstützt Eingaben mit höherer Bildrate, wodurch kleine Bewegungsänderungen erfasst und ein feineres Bewegungsverständnis erreicht werden kann, selbst wenn die Videobildrate niedrig ist. Dies bietet eine starke Garantie für Anwendungsszenarien, die eine präzise Bewegungsanalyse erfordern.


Ultralanges Videoverstehen: Durch die innovative Technologie mit variabler Auflösung durchbricht das neue Modell die Grenzen der Videoverarbeitungszeit und unterstützt ein Videoverstehen von bis zu 2 Stunden, was die geschäftlichen Anwendungsszenarien des Videoverstehensmodells erheblich erweitert:

Echtzeit-Videogespräche: Auf der Grundlage eines leistungsstarken Modells für das Verstehen von Videos haben wir ein Modell für Echtzeit-Videogespräche, GLM-Realtime, entwickelt, das Videoverstehen und Fragen und Antworten in Echtzeit ermöglicht und Anrufe bis zu 2 Minuten speichern kann. Das Modell ist jetzt onlineSmart Spectrum AI Offene PlattformGLM-Realtime hilft Kunden nicht nur beim Aufbau von intelligenten Videoanrufen, sondern kann auch mit vorhandener vernetzbarer Hardware kombiniert werden, um auf einfache Weise intelligente Häuser, KI-Spielzeug, KI-Brillen und andere innovative Produkte zu entwickeln.
Derzeit können auch normale Nutzer mit der Smart Spectrum Clear Speech App Videoanrufe mit KI tätigen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel




Keine Kommentare...