Crawl4AI: quelloffenes asynchrones Webcrawler-Tool zur Extraktion strukturierter Daten ohne LLM

Allgemeine Einführung
Crawl4AI ist ein quelloffenes asynchrones Webcrawler-Tool, das für Large Language Models (LLMs) und Anwendungen der Künstlichen Intelligenz (KI) entwickelt wurde. Es vereinfacht den Web-Crawling- und Datenextraktionsprozess, unterstützt effizientes Web-Crawling und bietet LLM-freundliche Ausgabeformate wie JSON, bereinigtes HTML und Markdown.Crawl4AI unterstützt das gleichzeitige Crawlen mehrerer URLs, ist komplett kostenlos und quelloffen und eignet sich für eine Vielzahl von Daten-Crawling-Bedürfnissen.
Offizielle Hilfe-Dokumentation
Funktionsliste
- Asynchrone Architektur: effiziente Verarbeitung mehrerer Webseiten, schnelles Crawling von Daten
- Mehrere Ausgabeformate: Unterstützung von JSON, HTML, Markdown
- Multi-URL-Crawling: crawlen Sie mehrere Webseiten gleichzeitig
- Extraktion von Medien-Tags: Extraktion von Bild-, Audio- und Video-Tags
- Link-Extraktion: Extraktion aller externen und internen Links
- Metadatenextraktion: Extraktion von Metadaten aus Seiten
- Benutzerdefinierte Hooks: Unterstützung für Authentifizierung, Anfrage-Header und Seitenänderungen
- Anpassung von Benutzeragenten: Anpassung von Benutzeragenten
- Screenshot der Seite: Screenshot der Crawl-Seite
- Benutzerdefiniertes JavaScript ausführen: Führen Sie mehrere benutzerdefinierte JavaScripts vor dem Crawling aus.
- Proxy-Unterstützung: Verbesserung der Privatsphäre und des Zugangs
- Sitzungsmanagement: Handhabung komplexer mehrseitiger Crawling-Szenarien
Hilfe verwenden
Einbauverfahren
Crawl4AI bietet flexible Installationsoptionen für eine Vielzahl von Nutzungsszenarien. Sie können es als Python-Paket installieren oder Docker verwenden.
Installation mit pip
- Grundlegende Installation
pip install crawl4aiDadurch wird standardmäßig die asynchrone Version von Crawl4AI installiert, die Playwright für das Web-Crawling verwendet.
- Manuelle Installation von Playwright (falls erforderlich)
playwright installoder
python -m playwright install chromium
Installieren mit Docker
- Ziehen eines Docker-Images
docker pull unclecode/crawl4ai - Ausführen von Docker-Containern
docker run -it unclecode/crawl4ai
Leitlinien für die Verwendung
- Grundlegende Verwendung
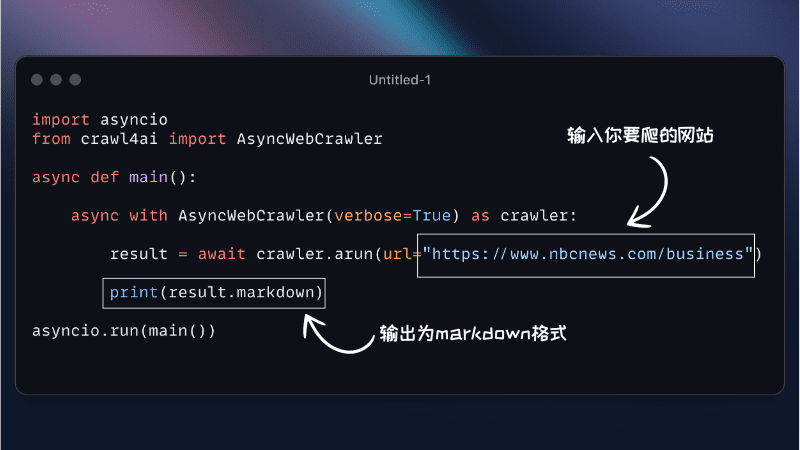
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() results = crawler.crawl(["https://example.com"]) print(results) - Benutzerdefinierte Einstellungen
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler( user_agent="CustomUserAgent", headers={"Authorization": "Bearer token"}, custom_js=["console.log('Hello, world!')"] ) results = crawler.crawl(["https://example.com"]) print(results) - Extrahieren spezifischer Daten
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() results = crawler.crawl(["https://example.com"], extract_media=True, extract_links=True) print(results) - Sitzungsmanagement
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() session = crawler.create_session() session_results = session.crawl(["https://example.com"]) print(session_results)
Crawl4AI bietet eine Vielzahl von Funktionen und flexiblen Konfigurationsoptionen für eine Vielzahl von Web-Crawling- und Data-Crawling-Anforderungen. Detaillierte Installations- und Nutzungsanleitungen erleichtern den Einstieg und ermöglichen es den Nutzern, die leistungsstarken Funktionen des Tools voll auszuschöpfen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...