Lokaler Einsatz von QwQ-32B-Großmodellen: Ein einfacher Leitfaden für PCs

Der Bereich der Modellierung künstlicher Intelligenz (KI) steckt immer voller Überraschungen, und jeder technologische Durchbruch kann die Nerven der Branche strapazieren. Kürzlich hat das QwQ-Team von Alibaba in den frühen Morgenstunden sein neuestes Inferenzmodell, QwQ-32B, veröffentlicht, das wieder einmal viel Aufmerksamkeit erregt hat.

In der offiziellen Mitteilung heißt esQwQ-32B ist ein Inferenzmodell mit einer Parameterskala von nur 32 MilliardenUnd doch behaupten sie, dass sie in der Lage sind, mit den DeepSeek-R1 und anderen branchenführenden, innovativen Modellen. Die Ankündigung war ein Paukenschlag, der die Tech-Community sofort in helle Aufregung versetzte. Sie enthielt Links zum offiziellen Blog, zur Hugging Face-Modellbibliothek, zu Modell-Downloads, Online-Demos und zu einer Website, auf der Nutzer mehr über das Produkt erfahren und es ausprobieren können.
Obwohl die Release-Informationen kurz und prägnant sind, ist die technische Stärke dahinter alles andere als einfach. Die Formulierung "32 Milliarden Parameter, vergleichbar mit DeepSeek-R1" ist schon beeindruckend genug, wenn man weiß, dass im Allgemeinen die Leistung umso höher ist, je größer die Anzahl der Parameter in einem Modell ist, was aber auch einen höheren Bedarf an Rechenressourcen bedeutet. QwQ-32B Mit einer geringen Anzahl von Parametern eine Leistung zu erreichen, die mit der des Megamodells vergleichbar ist, ist zweifelsohne ein großer Durchbruch, der bei Technikbegeisterten und Fachleuten natürlich großes Interesse geweckt hat.
Um die Leistung von QwQ-32B intuitiver zu demonstrieren, wurde gleichzeitig eine offizielle Benchmark-Testtabelle veröffentlicht. Benchmarking ist ein wichtiges Mittel zur Bewertung der Fähigkeiten eines KI-Modells, das die Leistung des Modells bei verschiedenen Aufgaben misst, indem es an einer Reihe von voreingestellten, standardisierten Datensätzen getestet wird und den Nutzern somit eine objektive Leistungsreferenz bietet.

Aus diesem Benchmarking-Diagramm können wir schnell die folgenden Schlüsselinformationen ablesen:
- Phänomenale Ausbreitungsgeschwindigkeit: Die Informationen zur Modellfreigabe достига́ть wurden in nur 12 Stunden von mehr als 1,69 Millionen Menschen gelesen, was die dringende Nachfrage des Marktes nach leistungsstarken KI-Modellen und die hohen Erwartungen an QwQ-32B widerspiegelt.
- Ausgezeichnete Leistung: Mit nur 32 Milliarden Parametern ist QwQ-32B in der Lage, im Benchmark-Test mit der Vollparameter-Version von DeepSeek-R1 zu konkurrieren, die eine Parameterzahl von 671 Milliarden hat, was ein erstaunliches Energieeffizienz-Verhältnis zeigt. Dieses Phänomen, dass ein kleines Modell ein großes Modell übertrifft, bricht definitiv mit der traditionellen Vorstellung von der Beziehung zwischen Modellleistung und Parametergröße.
- Übertrifft die Destillationsmodelle in seiner Klasse: QwQ-32B übertrifft die 32B-Destillationsversion von DeepSeek-R1 erheblich. Bei der Destillation handelt es sich um eine Technik zur Modellkomprimierung, die darauf abzielt, das Verhalten eines größeren Modells durch das Training eines kleineren Modells zu imitieren und so die Rechenkosten bei gleichbleibender Leistung zu senken. Die Tatsache, dass QwQ-32B das 32B-Destillationsmodell übertrifft, ist ein weiterer Beweis für die Ausgefeiltheit seiner Architektur und Trainingsmethodik.
- Mehrdimensionale Leistungsführung: QwQ-32B übertrifft das Closed-Source-Modell o1-mini von OpenAI in mehreren Benchmarking-Dimensionen, was zeigt, dass QwQ-32B mit den besten Closed-Source-Modellen in Bezug auf die Allzweckfähigkeiten konkurrieren kann.
Von besonderem Interesse ist die Tatsache, dass QwQ-32B mit nur 32 Milliarden Parametern in der Lage ist, riesige Modelle mit mehr als der 20-fachen Anzahl von Parametern zu übertreffen, was einen weiteren Sprung nach vorn in der KI-Technologie darstellt. Noch spannender ist, dass Nutzer die quantisierte Version von QwQ-32B jetzt problemlos lokal mit einer Consumer-Grafikkarte der Klasse RTX3090 oder RTX4090 ausführen können. Der lokale Einsatz senkt nicht nur die Hürde für die Nutzung, sondern eröffnet auch mehr Möglichkeiten für Datensicherheit und personalisierte Anwendungen. Benutzer mit einer schwächeren Grafikkarte können versuchen, mit der empfohlenen Cloud-Bereitstellungslösung zu beginnen:Online-Einsatz des Open-Source-Modells DeepSeek-R1 mit kostenloser GPU-Leistungoder bewerben Sie sich direkt für die Nutzung der kostenlosen API.Alibaba (Vulkan) bietet 1 Million Token pro Tag (für 180 Tage), und die Akash Die API ist kostenlos und kann ohne Registrierung genutzt werden.
DeepSeek ist kein Eintagsfliege mehr, wie also kann OpenAI an der Spitze bleiben?
Angesichts der starken Konkurrenzfähigkeit des QwQ-32B stehen die bestehenden Produkte von OpenAI, sowohl die 200-Dollar-Pro-Version als auch die 20-Dollar-Plus-Version, vor einer ernsthaften Herausforderung in Bezug auf das Preis-/Leistungsverhältnis. Der QwQ-32B hat den Markt zum Nachdenken angeregt, insbesondere im Hinblick auf die Leistungsschwankungen, die OpenAI-Modelle manchmal aufweisen und die von den Benutzern als "Dumbing Down" kritisiert wurden. Nichtsdestotrotz kann OpenAI auf eine lange Geschichte und ein umfangreiches Ökosystem im Bereich der KI zurückblicken, und es könnte immer noch einen Vorteil bei der Feinabstimmung von Modellen und der Optimierung von Anwendungen in bestimmten Bereichen haben. Die Veröffentlichung von QwQ-32B durchbricht jedoch zweifellos das ursprüngliche Muster des Marktes und zwingt alle Akteure, ihre eigenen technischen Vorteile und Marktstrategien zu überprüfen.
Um die Fähigkeiten des QwQ-32B in der Praxis besser beurteilen zu können, ist es notwendig, ihn vor Ort zu installieren und im Detail zu testen, insbesondere um seine Argumentationsleistung und seinen "IQ" in einer lokalen Betriebsumgebung zu untersuchen.
Zum Glück, denn dank der Ollama Mit dem Aufkommen von Werkzeugen wie Ollama ist es nun sehr einfach geworden, große Sprachmodelle lokal auf Personalcomputern einzusetzen und auszuführen. Ollama, ein Open-Source-Framework für die Ausführung von Modellen, vereinfacht den Prozess der Bereitstellung und Verwaltung großer lokaler Modelle erheblich.
Ollama ist bekannt für seine Effizienz und Benutzerfreundlichkeit. Kurz nach der Veröffentlichung des QwQ-32B kündigte Ollama die Unterstützung des Modells an, um die Hürde für Nutzer, die neueste KI-Technologie zu erleben, weiter zu senken und den Einstieg in die Leistungsfähigkeit des QwQ-32B für jeden einfach zu gestalten.
1. die Installation und der Betrieb von Ollama
Besuchen Sie zunächst die offizielle Ollama-Website unter ollama.com und klicken Sie auf die Schaltfläche Download, um das entsprechende Installationspaket für Ihr Betriebssystem herunterzuladen.
Ollama bietet volle Unterstützung für alle wichtigen Betriebssysteme, einschließlich macOS (Intel und Apple Silicon), Windows und Linux, so dass das Modell QwQ-32B problemlos auf allen Plattformen eingesetzt werden kann.
Sobald der Download abgeschlossen ist, doppelklicken Sie auf das Installationsprogramm und folgen Sie dem Assistenten, um den Installationsprozess abzuschließen. Nach erfolgreicher Installation sehen Sie ein niedliches Alpaka-Symbol in der Taskleiste unter Windows oder in der Menüleiste unter macOS, das anzeigt, dass Ollama erfolgreich gestartet wurde und im Hintergrund läuft, bereit, Ihnen zu dienen.
2. das Herunterladen des Modells QwQ-32B
Unbedingt lesen:Unsloth löst das Problem der doppelten Inferenz in der quantisierten Version von QwQ-32B
Nach erfolgreicher Installation und Ausführung von Ollama können Sie nun mit dem Download des Modells QwQ-32B beginnen.

Öffnen Sie den Ollama-Client im Modelle Auf der Seite Modelle sehen Sie, dass das Modell QwQ-32B schnell an die Spitze der Liste der beliebtesten Modelle geklettert ist, was ein Beweis für seine Beliebtheit ist. Suchen Sie den Eintrag des Modells "qwq" und klicken Sie darauf, um die Detailseite des Modells aufzurufen. Kopieren Sie auf der Detailseite die rot umrandeten Befehle.
Öffnen Sie ein lokales Terminal (macOS/Linux) oder eine Eingabeaufforderung (Windows).
Fügen Sie in ein Terminal oder eine Eingabeaufforderung den folgenden Befehl ein und führen Sie ihn aus:ollama run qwq
ollama run qwq
Ollama beginnt automatisch mit dem Download der QwQ-32B-Modelldateien aus der Cloud und startet die Modell-Laufzeitumgebung automatisch, sobald der Download abgeschlossen ist.
Es ist erwähnenswert, dassFür das Herunterladen des Modells ist offenbar keine zusätzliche Netzwerkkonfiguration seitens des Benutzers erforderlich. Dies ist zweifelsohne eine sehr freundliche Funktion für private Nutzer. Schließlich wird eine Modelldatei mit einer Größe von fast 20 GB das Nutzererlebnis stark beeinträchtigen, wenn die Download-Geschwindigkeit zu langsam ist oder eine spezielle Netzwerkumgebung erforderlich ist.
Da das Modell QwQ-32B jedoch derzeit sehr beliebt ist und von vielen Nutzern heruntergeladen wird, kann die tatsächliche Download-Geschwindigkeit in gewissem Maße beeinträchtigt werden, was zu einer längeren Download-Zeit führt, was von den Nutzern etwas Geduld erfordert.
Nach einer Weile des Wartens wurde das Modell schließlich heruntergeladen. Ich habe das QwQ-32B-Modell auf einem Computer mit einer RTX3060-Desktop-Grafikkarte mit 12 GB Videospeicher ausgeführt, um es auszuprobieren, und war angenehm überrascht: Das Modell wurde nicht nur erfolgreich geladen, sondern es war auch in der Lage, reibungslose Antworten auf der Grundlage der Benutzereingaben zu geben, und, was noch wichtiger ist, es gab während des gesamten Prozesses keine Probleme mit einem Überlauf des Videospeichers. Noch wichtiger ist, dass es während des gesamten Prozesses kein Problem mit dem Speicherüberlauf gab, was bedeutet, dass selbst Mainstream-Grafikkarten die Anforderungen des quantitativen Modells QwQ-32B erfüllen können.

In Bezug auf die tatsächliche Inferenzleistung hat die Fähigkeit von QwQ-32B bereits einige OpenAI-Modelle übertroffen, die von den Nutzern scherzhaft als "IQ Underline" bezeichnet werden. Dies bestätigt auch die Überlegenheit von QwQ-32B in Bezug auf die Leistung.
Mit dem Windows Task Manager können wir die Ressourcennutzung des Modells in Echtzeit überwachen. Die Ergebnisse zeigen, dass die CPU, der Arbeitsspeicher und der Grafikspeicher während des Modellinferenzprozesses stark belastet werden, was auch die hohen Hardware-Ressourcenanforderungen für die lokale Ausführung großer Modelle widerspiegelt.
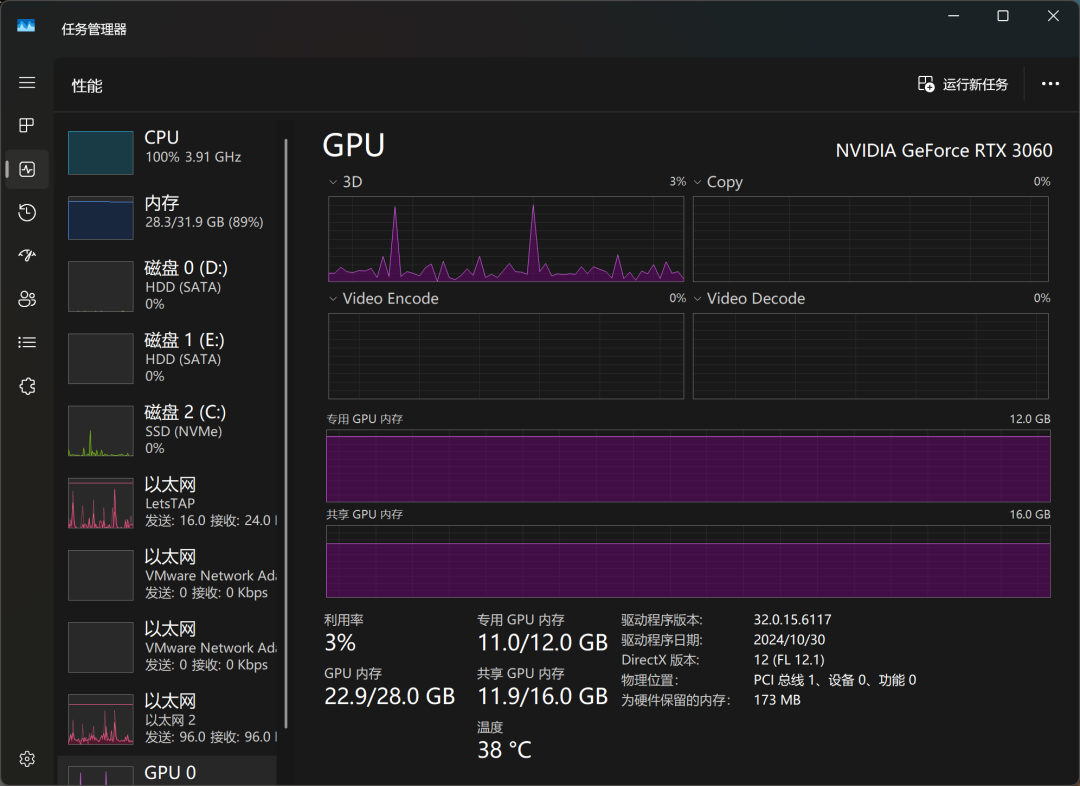
Mit einer RTX3060-Grafikkarte antwortet QwQ-32B in etwa mit dem Tempo "da, da, da, da...", was die grundlegenden Bedürfnisse der Nutzung befriedigen kann, aber es gibt noch Raum für Verbesserungen in Bezug auf Reaktionsfähigkeit und Laufruhe. Wenn Sie auf der Suche nach einem extremeren lokalen Modell sind, benötigen Sie möglicherweise eine höhere Hardwarekonfiguration.
Um die Laufgeschwindigkeit des Modells weiter zu verbessern, habe ich das QwQ-32B-Modell erneut heruntergeladen und auf einem Gerät mit einer RTX3090-Grafikkarte der Spitzenklasse ausgeführt. Die Versuchsergebnisse zeigen, dass sich die Laufgeschwindigkeit des Modells nach dem Austausch der hochwertigen Grafikkarte erheblich verbessert hat, und es ist keine Übertreibung, sie als "flugschnell" zu bezeichnen. Dies bestätigt auch die Bedeutung der Hardwarekonfiguration für das Lauferlebnis eines großen lokalen Modells.
3. die Integration von QwQ-32B in Clients
Die direkte Kommunikation mit dem Modell über die Befehlszeilenschnittstelle ist zwar eine einfache und unkomplizierte Möglichkeit, aber für diejenigen, die das Modell häufig verwenden müssen oder eine bessere Interaktionserfahrung suchen, ist die Verwendung eines grafischen Clients zweifellos die bequemere Wahl. Es gibt viele hervorragende KI-Modell-Client-Software auf dem Markt, und wir haben bereits viele von ihnen vorgestellt, wie z. B. ChatWise. Der Hauptgrund für die Wahl von ChatWise ist die einfache und intuitive Gestaltung der Benutzeroberfläche, die klare und leicht verständliche Betriebslogik und die Fähigkeit, den Benutzern eine gute Erfahrung zu bieten.
Im Folgenden werden die Schritte zur Konfiguration eines QwQ-32B-Modells für den ChatWise-Client beschrieben.
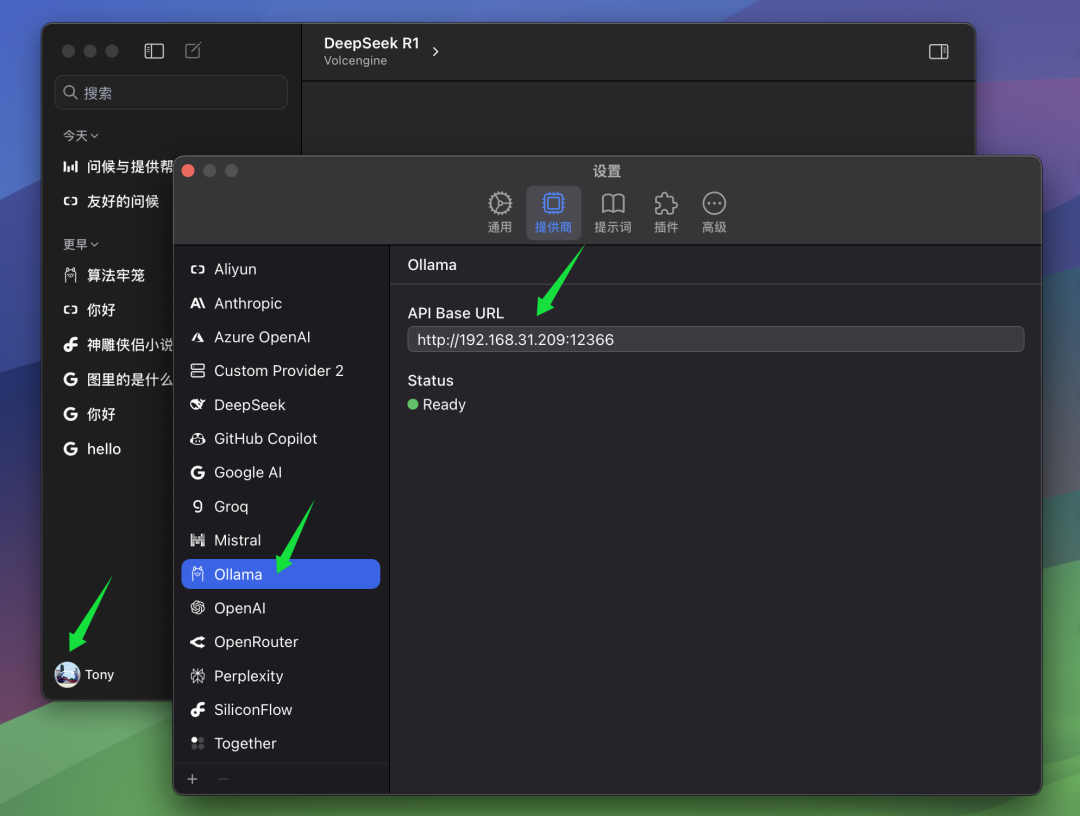
Wenn Ihr ChatWise-Client und der Ollama-Dienst auf demselben Computer laufen, können Sie in der Regel den ChatWise-Client öffnen und das Modell QwQ-32B direkt ohne zusätzliche Konfiguration verwenden. Dies ist bei den meisten Benutzern der Fall, d. h. sowohl der Ollama-Dienst als auch die Client-Anwendung sind auf demselben Gerät installiert.
Wenn Sie jedoch, wie der Autor, den Ollama-Dienst auf einem anderen Computer (z. B. einem Server) installiert haben und der ChatWise-Client auf Ihrem lokalen Computer läuft, müssen Sie manuell die ChatWise BaseURL Einstellungen, damit Clients eine Verbindung zum entfernten Ollama-Dienst herstellen können. In der BaseURL In den Einstellungen müssen Sie die IP-Adresse des Computers eingeben, auf dem der Ollama-Dienst läuft, sowie die Portnummer, die Sie auf dem Ollama-Server konfiguriert haben. Der Standardport für Ollama ist 13434. Wenn Sie ihn also nicht speziell konfiguriert haben, können Sie einfach den Standardport verwenden.
erfüllen BaseURL Einmal konfiguriert, können Sie das Modell auswählen, das Sie im ChatWise-Client verwenden möchten.
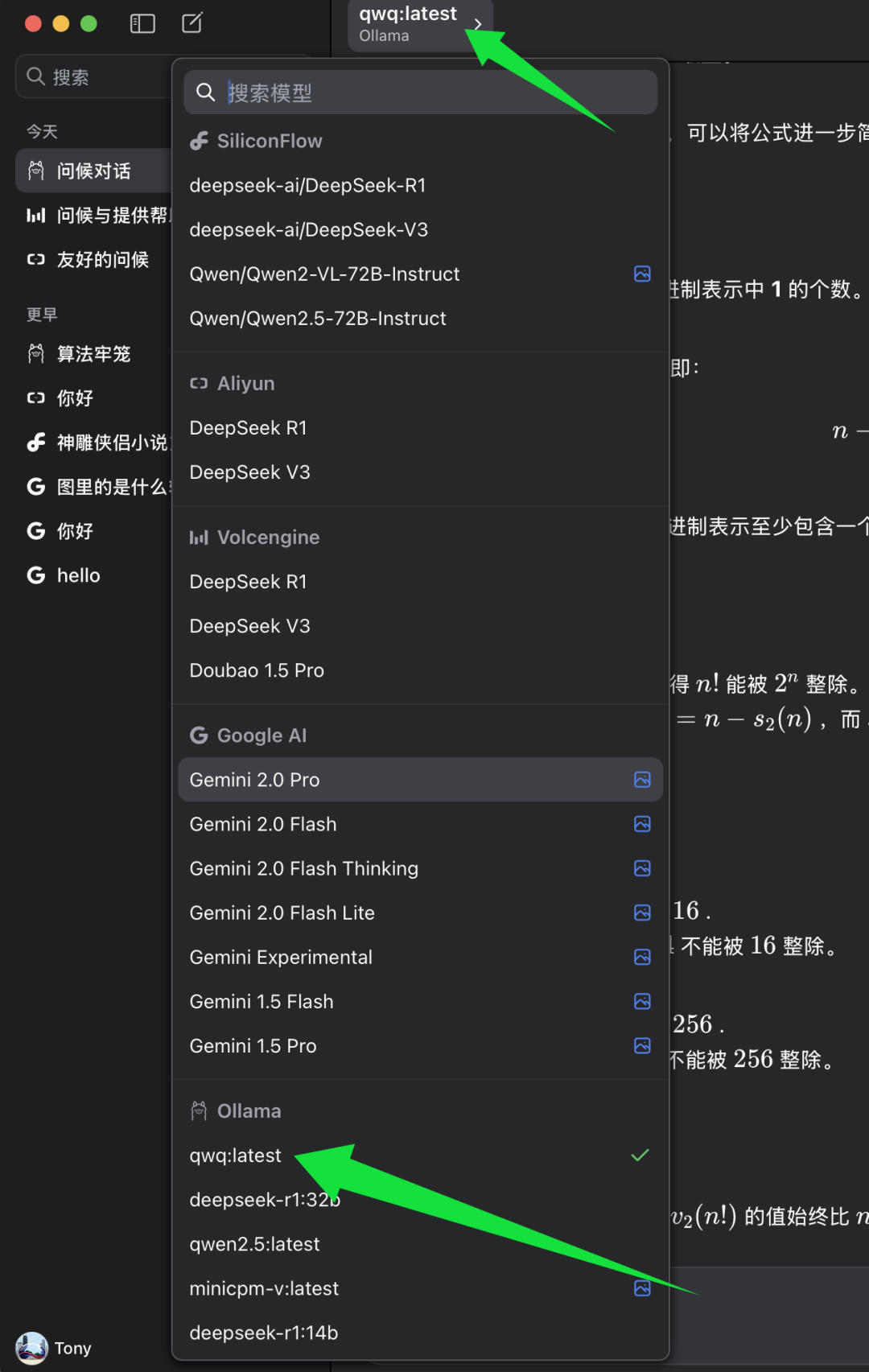
Suchen Sie in der Modellauswahlliste von ChatWise die Modellkategorie Ollama und wählen Sie darunter qwq:zuletzt. qwq:zuletzt Stellt die neueste Version des Modells QwQ-32B dar, in der Regel auch die quantisierte 4-Bit-Version. Wählen Sie qwq:zuletzt Danach können Sie die Leistungsfähigkeit des Modells QwQ-32B im ChatWise-Client erleben.
4. der Intelligenztest nach dem Modell QwQ-32B
Um das Intelligenzniveau des QwQ-32B-Modells objektiver beurteilen zu können, haben wir eine Reihe klassischer Fragen verwendet, die zuvor für die Prüfung des Problems der "reduzierten Intelligenz" des OpenAI-Modells entwickelt worden waren. Dieser Satz besteht aus vier sorgfältig ausgewählten Fragen, die sich empirisch als nützlich erwiesen haben, wenn die ChatGPT (insbesondere bei den Modellen GPT-3 oder GPT-4) ist es oft schwierig, diese Fragen richtig zu beantworten, wenn der Benutzer eine "verminderte Intelligenz" angibt. Daher kann dieser Fragensatz bis zu einem gewissen Grad als Referenz für die Prüfung des Intelligenzniveaus der größeren Modelle verwendet werden.
Als Nächstes werden wir das lokal ausgeführte Modell QwQ-32B nacheinander testen, um zu sehen, ob es alle Fragen erfolgreich beantworten kann.
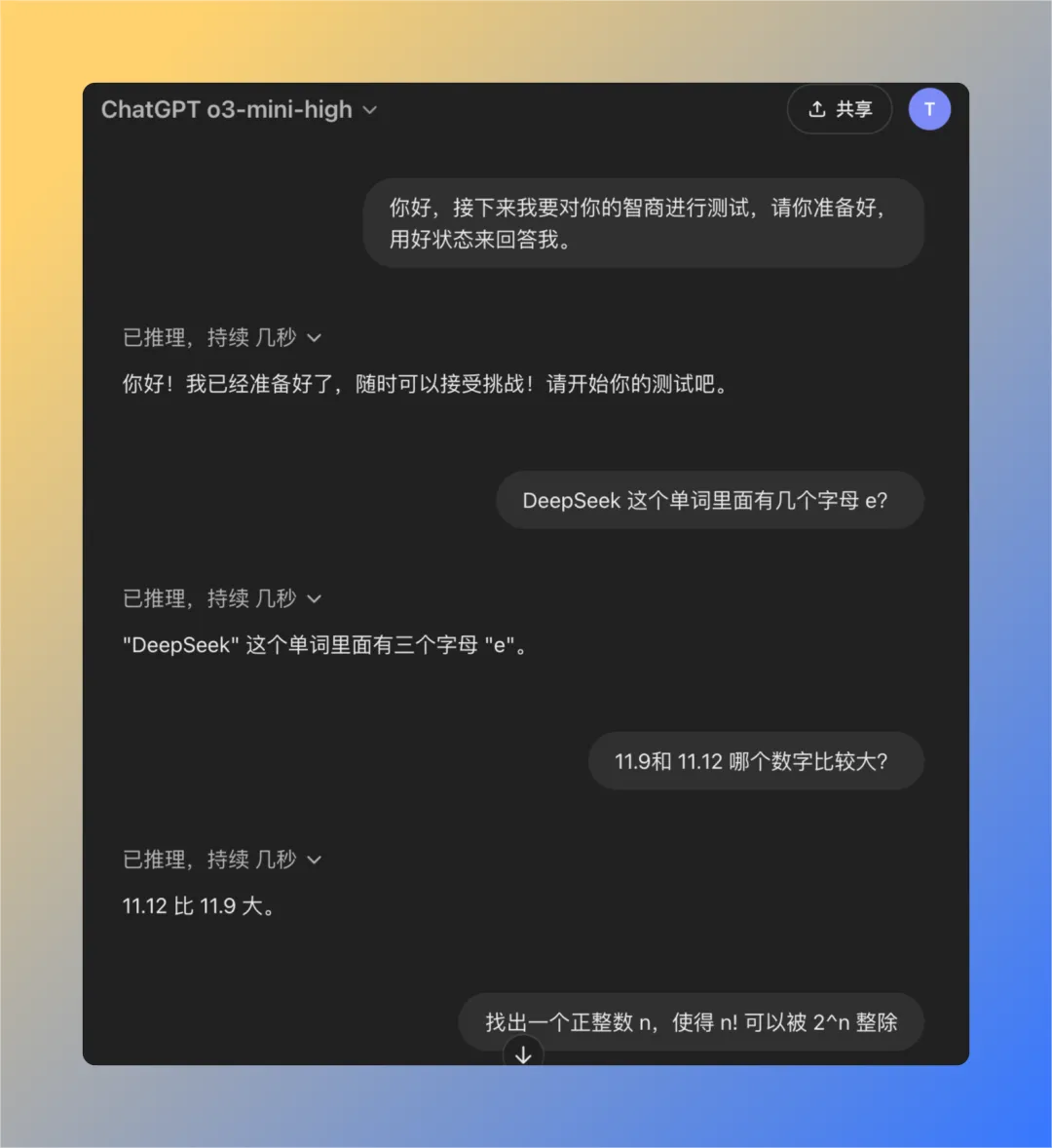
Frage 1: Wie viele Buchstaben des Buchstabens e sind in dem Wort deepseek enthalten?
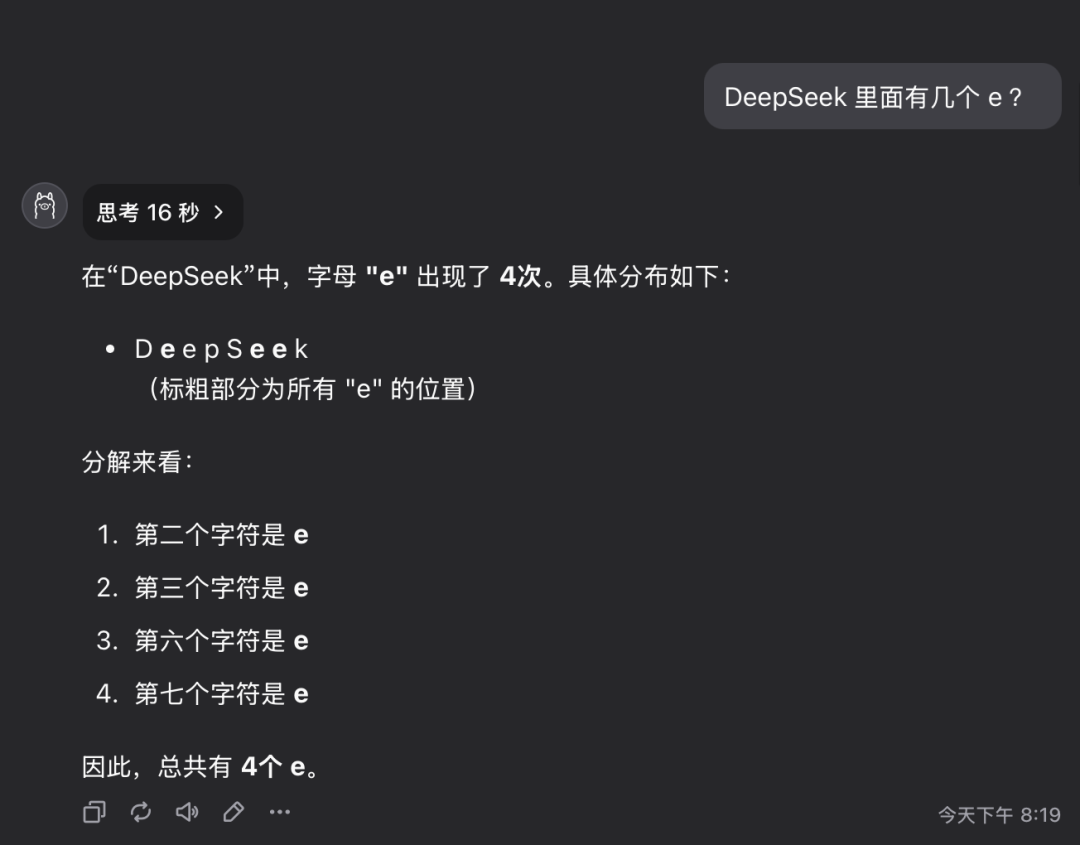
Das Modell QwQ-32B gab die richtige Antwort in 16 Sekunden: 3. Die Antwort ist richtig..
Diese Frage mag einfach erscheinen, aber tatsächlich wird damit die Fähigkeit des Modells geprüft, detaillierte Informationen genau zu verstehen und zu extrahieren. Überraschenderweise gibt es immer noch eine beträchtliche Anzahl großer Modelle, die solche Fragen nicht genau beantworten können.
Frage 2: Welcher Wert ist größer, 11,9 oder 11,12?

Das Modell QwQ-32B gab die richtige Antwort in 47 Sekunden: 11,12 ist größer. Die Antwort ist richtig..
Auch hier handelt es sich um ein scheinbar einfaches, aber klassisches Problem. Viele große Modelle sind verwirrt oder verkennen einfache numerische Vergleiche, was mögliche Mängel in der zugrunde liegenden logischen Argumentation des Modells widerspiegelt.
Aufgabe 3: Finde eine positive ganze Zahl n so, dass die Fakultät von n (n!) durch die n-te Potenz von 2 (2^n) teilbar ist.

Das Modell QwQ-32B gibt die richtige Antwort in 121 Sekunden: Es gibt keine solche positive ganze Zahl n. Die Antwort ist richtig..
Bei dieser Frage geht es nicht darum, eine bestimmte numerische Antwort zu finden, sondern zu prüfen, ob das Modell über die Fähigkeit verfügt, abstrakt zu denken und logisch zu folgern, die Natur des Problems zu verstehen und schließlich zu der Schlussfolgerung zu gelangen, dass "es nicht existiert". QwQ-32B war in der Lage, diese Frage korrekt zu beantworten und zeigte damit eine gewisse Fähigkeit zum logischen Denken.
Frage 4: Klassisches logisches Denken - Hutfarbenrätsel
"Es stehen 5 Personen in einer Reihe und jede von ihnen trägt einen Hut auf dem Kopf, der rot oder blau sein kann. Jede Person kann nur die Farbe des Hutes der Person vor ihr in der Reihe sehen, aber nicht die Farbe des Hutes auf ihrem eigenen Kopf. Der Moderator sagt der Gruppe im Voraus: "Von diesen 5 Personen gibt es mindestens einen roten Hut." Nun wird jede Person, beginnend mit der Person am Ende der Reihe, der Reihe nach gefragt: "Weißt du, welche Farbe dein Hut hat? Jede Person kann nur mit "Ja" oder "Nein" antworten. Angenommen, die 5. Person antwortet mit "Nein" und die 4. Person mit "Ja", wie ist die Verteilung aller möglichen Hutfarben?"
Im Vergleich zu den ersten drei Fragen war diese Frage zum logischen Denken deutlich schwieriger und verlangte dem Modell mehr logische Analyse- und Argumentationsfähigkeiten ab.
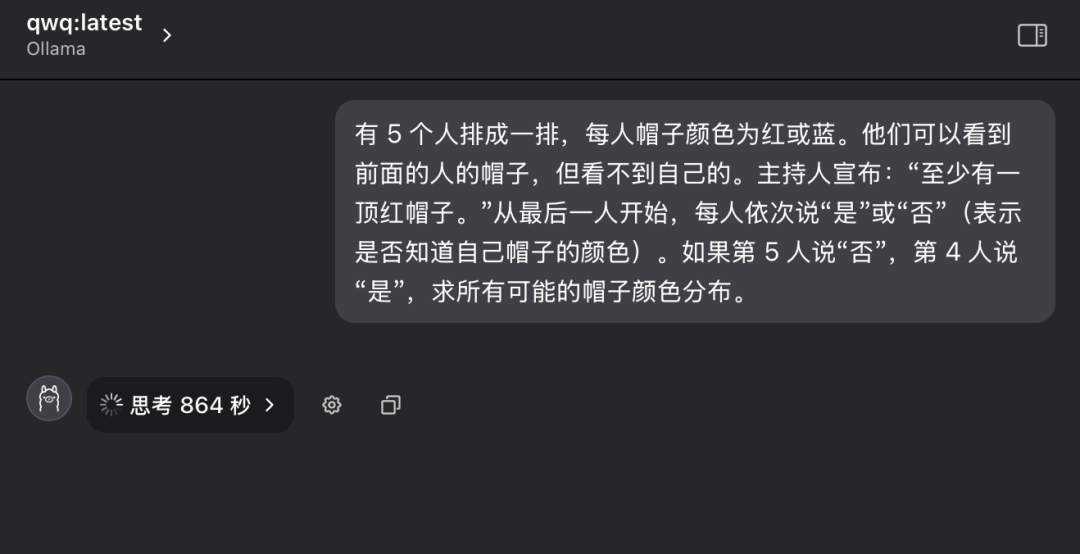
Während der ersten Befragung trat das Modell QwQ-32B in einen Zustand anhaltenden Denkens ein, wobei die Worte "Thinking..." auf dem Bildschirm aufblinkten, als ob das "Gehirn" mit hoher Geschwindigkeit laufen würde, und es ließ sogar Zweifel aufkommen, ob die Hardware einer solch intensiven Rechenlast standhalten könnte. Es ließ sogar Zweifel aufkommen, ob die Hardware einer so hohen Rechenleistung standhalten könnte. In Anbetracht der Zeit und des Zustands der Hardware habe ich nach mehr als zehn Minuten Wartezeit den Denkprozess des Modells manuell unterbrochen.
Anschließend eröffnete der Autor eine neue Dialogsitzung und stellte dem Modell QwQ-32B erneut die gleichen Fragen.

Diesmal gab das Modell QwQ-32B nach 196 Sekunden endlich eine völlig korrekte Antwort und erläuterte die Gründe dafür ausführlich. Die Antwort ist richtig..
Ein Blick auf die Aufzeichnung des Denkprozesses des Modells zeigt, dass QwQ-32B trotz der relativ kleinen Parametergröße einen sehr "harten" Denk- und Analyseprozess aufweist, wenn es mit einem komplexen logischen Denkproblem konfrontiert wird. Das Modell führt im Hintergrund viele logische Berechnungen und Wahrscheinlichkeitsabzüge durch, bevor es schließlich zu der richtigen Schlussfolgerung kommt.
Nach der obigen Reihe strenger und detaillierter IQ-Tests können wir vorläufig feststellen, dass die quantisierte Version des 4-Bit-Modells QwQ-32B eine beeindruckende Gesamtleistung gezeigt hat, insbesondere beim logischen Denken und bei Quizfragen, und andere Modelle seiner Klasse übertroffen hat. Es ist anzunehmen, dass die Leistung der nicht quantisierten Version des QwQ-32B noch besser sein wird. 32B Full Blood Edition Modell Leistungsbewertungsbericht QwQ-32B bietet umfassendere Leistungsdaten und -analysen. Daher können wir grundsätzlich beurteilen, dass die vom Alibaba QwQ-Team bei der Veröffentlichung des QwQ-32B-Modells gemachte Leistungswerbung nicht übertrieben ist, und QwQ-32B ist in der Tat ein hervorragendes neues Inferenzmodell, das die Stärke hat, mit dem DeepSeek-R1-Modell mit 671 Milliarden Parametern und einer Parameterskala von 32 Milliarden Parametern zu konkurrieren.
Der rasante Aufstieg der einheimischen Open-Source-Big-Models ist ein deutlicher Beweis für Chinas Innovationskraft und sein enormes Entwicklungspotenzial im Bereich der KI-Technologie.
Noch besser ist, dass die QwQ-32B 32B-Version des Modells nur eine Grafikkarte mit 24 GB Arbeitsspeicher benötigt, um es reibungslos und mit beeindruckender Geschwindigkeit zu betreiben. Während noch vor einigen Jahren für den Betrieb eines solchen Hochleistungsmodells in großem Maßstab Spezialgeräte im Wert von mehreren Millionen Dollar erforderlich gewesen wären, können die Benutzer es jetzt dank technologischer Fortschritte wie QwQ-32B und Ollama lokal auf einem 10.000-Dollar-PC einsetzen und erleben. Die Veröffentlichung des QwQ-32B-Modells signalisiert, dass hochleistungsfähige KI-Modelle immer beliebter werden und die Ära der "KI für alle" immer schneller voranschreitet und hochleistungsfähige KI-Technologie eine breitere Anwendungsperspektive in persönlichen Endgeräten und verschiedenen Branchen haben wird.
Jetzt ist der beste Zeitpunkt, um aktiv zu werden, die Leistungsfähigkeit des QwQ-32B zu erkunden und voll auszuschöpfen! Lassen Sie uns gemeinsam in die strahlende Zukunft der KI-Technologie eintauchen!
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Verwandte Beiträge

Keine Kommentare...