
Ali Bailian stellt die QwQ-32B-API kostenlos zur Verfügung, und jeden Tag können 1 Million Token kostenlos verwendet werden!

Kürzlich wurde die AliCloud Hundred Refinement Platform angekündigt für QwQ-32B Das Big Language Model eröffnet API-Schnittstellen und bietetKostenloser Zugang zu 1 Million Token pro TagDas QwQ-32B-Modell ist eine neue und aufregende Technologie, die die Hürden für den Zugang zu modernster KI-Technologie deutlich senkt. Für Nutzer, die die starke Leistung des QwQ-32B-Modells erleben möchten, aber durch die lokale Hardware-Rechenleistung eingeschränkt sind, ist der Aufruf des Cloud-Modells über die API-Schnittstelle definitiv eine attraktivere Option.
Empfohlene Lektüre für alle, die QwQ-32B nicht kennen:Kleines Modell, große Leistung: QwQ-32B mit 1/20-Parametern im Kampf gegen den vollblütigen DeepSeek-R1
Vorteile der API-Schnittstelle: Überwindung von Hardware-Beschränkungen, leistungsstarke Rechenleistung an Ihren Fingerspitzen
Zuvor haben wir veröffentlicht Lokaler Einsatz von QwQ-32B-Großmodellen: Ein einfacher Leitfaden für PCs Darüber hinaus müssen Nutzer, die große Sprachmodelle wie QwQ-32B nutzen wollen, oft vor Ort eine Hochleistungsrechnerausrüstung einsetzen. Die Hardwareanforderung von 24 GB oder mehr Videospeicher versperrt vielen Nutzern die Tür zur KI-Erfahrung. Die API-Schnittstelle der AliCloud-Plattform Hundred Refine löst dieses Problem auf intelligente Weise.
Durch den Aufruf von QwQ-Modellen über die API-Schnittstelle können die Benutzer mehrere Vorteile nutzen:
- Kein Schwellenwert für die Hardware-Konfiguration. Es muss keine Hochleistungshardware vor Ort eingesetzt werden, was die Schwelle für die Nutzung senkt. Selbst dünne und leichte Laptops und sogar Smartphones können problemlos die leistungsstarke Modellierungsleistung der Cloud nutzen. Es wird empfohlen, eine Grafikkarte mit mindestens 24 GB Videospeicher zu verwenden, um eine reibungslosere Ausführung der lokalen Modelle zu gewährleisten.
- Systemkompatibilität. Die API-Schnittstelle ist betriebssystemunabhängig und plattformübergreifend. Egal, ob Sie Windows, macOS oder Linux verwenden, Sie können problemlos darauf zugreifen.
- Die leistungsstärkere Plus-Version. Benutzer können die verbesserte Version von QwQ Plus erleben, die die lokal eingesetzte Vollversion von QwQ-32B übertrifft. Die Plus-Version, d. h. die verbesserte Version des QwQ-Inferenzmodells für Tongyi Qianqi, basiert auf dem Qwen2.5-Modell und wird durch Reinforcement Learning trainiert. Verglichen mit der Basisversion hat die Plus-Version die Fähigkeit des Modells zur Inferenz erheblich verbessert. Bei der Bewertung von Kernmetriken (z. B. AIME 24/25, Livecodebench) und einigen allgemeinen Metriken (z. B. IFEval, LiveBench usw.) hat die Plus-Version die höchste Leistung erzielt. DeepSeek-R1 Vollblütige Version der Stufe des Modells.
- Hohe Reaktionsgeschwindigkeit. Die API-Schnittstelle ermöglicht schnelle Antwortzeiten von 40-50 Token/Sekunde. Dies bedeutet, dass die Nutzer eine interaktive Erfahrung nahezu in Echtzeit machen können, was die Effizienz erheblich verbessert.
Es ist erwähnenswert, dass die In-silico-Mobilitätsplattform zusätzlich zu AliCloud Hundred Refine auch eine API-Schnittstelle zum QwQ-32B-Modell bietet. Benutzer, die sich für die In-silico-Flow-Plattform interessieren, können sich auf den vorherigen Artikel beziehen. In diesem Artikel werden wir hauptsächlich die Verwendung der API-Schnittstelle der Aliyun Hundred Refine-Plattform vorstellen.
Aliyun Hundred Refined API Access Guide: Drei einfache Schritte für den Einstieg!
AliCloud's Hundred Refinement Platform bietet den Nutzern der QwQ-Modell-API täglich 1 Million Token Das kostenlose Guthaben. Für die meisten Nutzer ist dieser Betrag ausreichend für die täglichen Erfahrungen und Tests. Die Nutzer müssen lediglich eine einfache Registrierung und Konfiguration durchführen, um loszulegen.
Nachfolgend finden Sie eine kurze Anleitung zur Konfiguration der Aliyun Bai Lian QwQ Plus API auf der Client-Seite:
1. den API-Schlüssel und den Modellnamen abrufen
Besuchen Sie zunächst die AliCloud-Plattform für hundertfache Verfeinerung und schließen Sie die Registrierung oder Anmeldung ab.
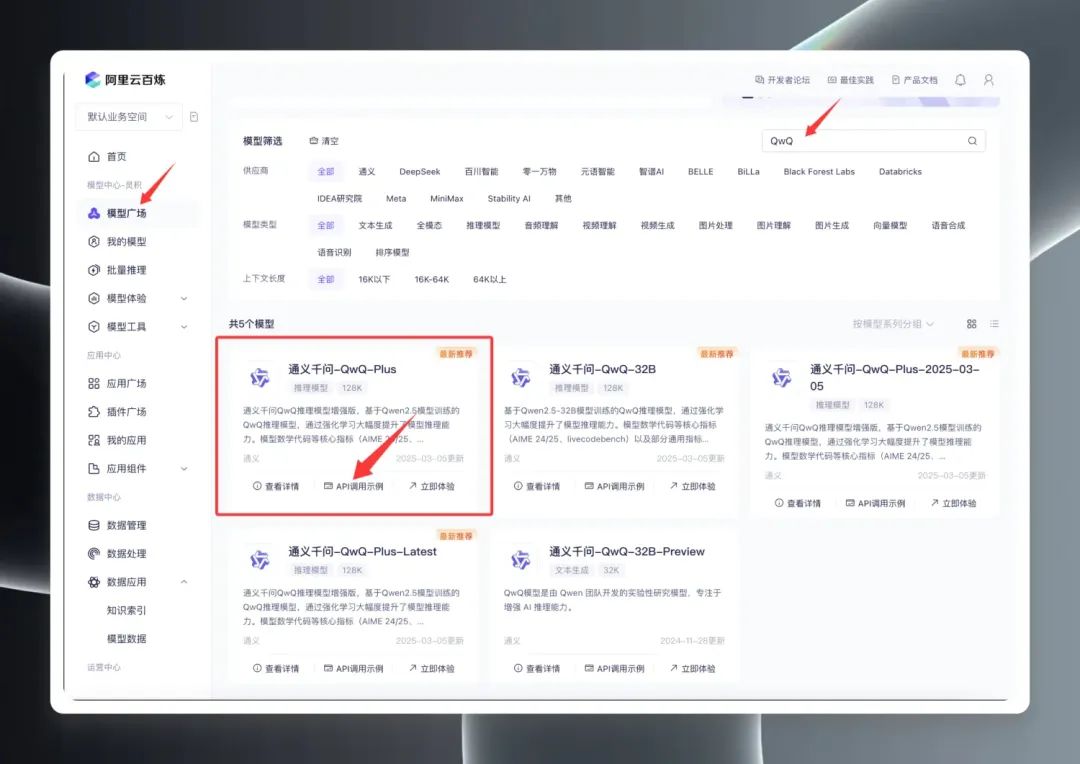
Wenn Sie angemeldet sind, suchen Sie im Model Square nach "QwQ", um die QwQ-Modellpalette zu sehen. Im Model Square werden drei Hauptversionen angezeigt: QwQ32B (offizielle Version), QwQ32B-Preview (Vorabversion) und QwQ Plus (erweiterte Version, auch als kommerzielle Version bekannt).
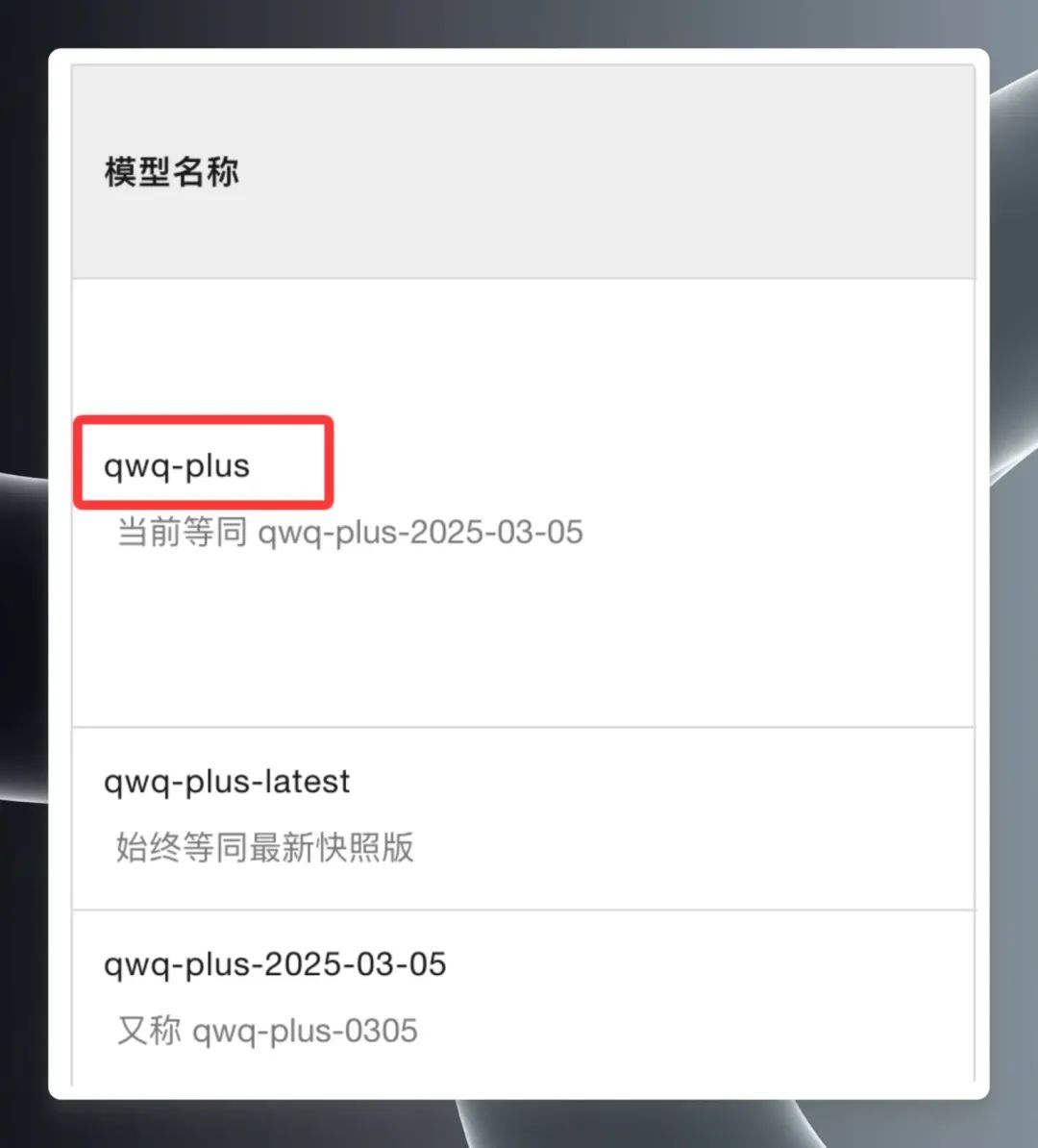
Wählen Sie "QwQ Plus (Enhanced)", klicken Sie auf "API Call Examples", und suchen Sie auf der neuen Seite die Name des Modells qwq-plus.
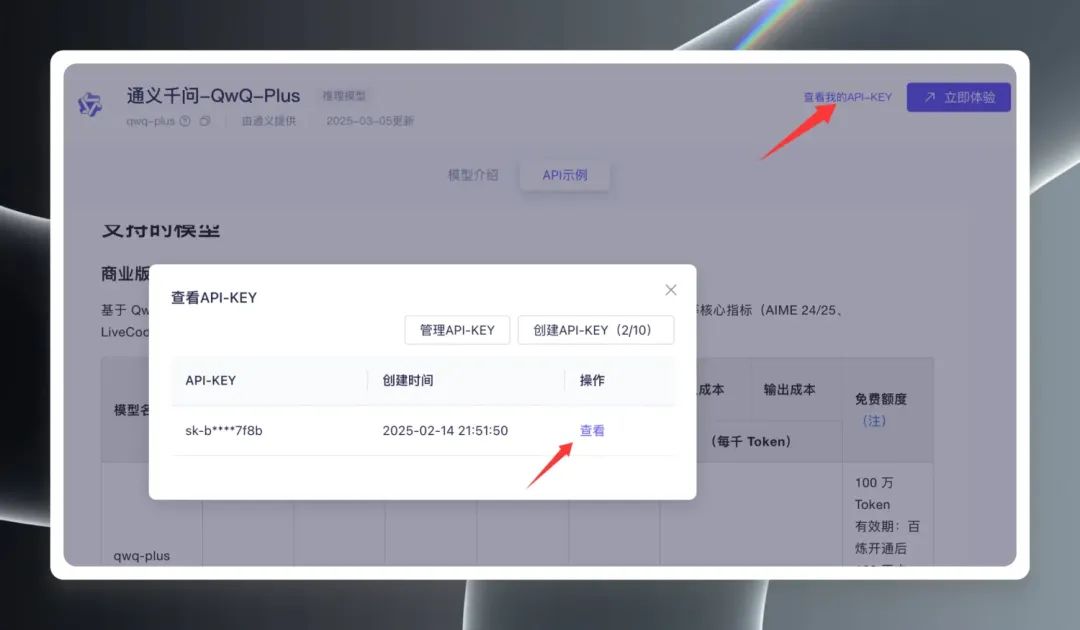
Als Nächstes klicken Sie auf "Meinen API-Schlüssel anzeigen" in der oberen rechten Ecke der Seite. Sie müssen zum ersten Mal einen API-Schlüssel erstellen, wenn Sie bereits einen erstellt haben, können Sie ihn direkt anzeigen und kopieren. API-Schlüssel.
2. die Client-Konfiguration
dieses Papier basiert auf Chatwise Der Client wird zu Demonstrationszwecken als Beispiel verwendet. Öffnen Sie die Chatwise-Software, klicken Sie auf den Avatar des Benutzers und gehen Sie auf den Bildschirm "Einstellungen".
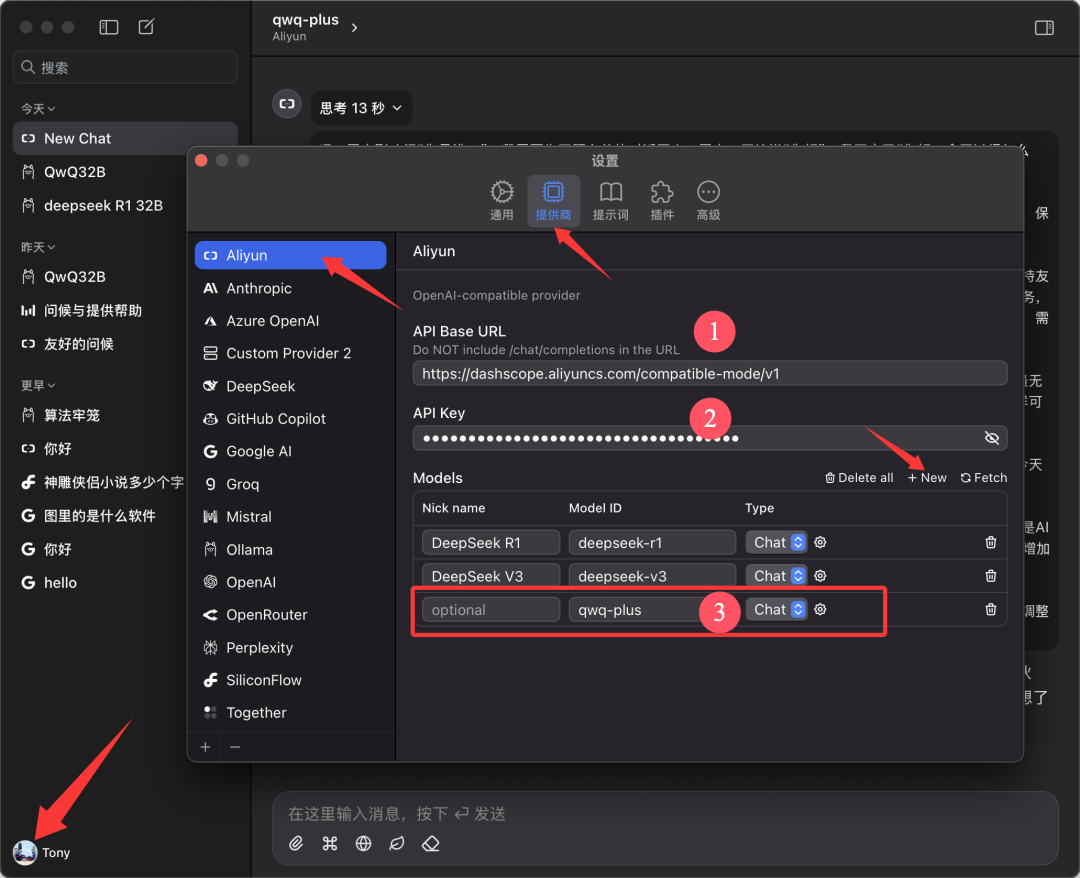
Suchen Sie "Aliyun" in der Liste der Anbieter. Wenn Sie ihn nicht finden, klicken Sie unten auf "➕", um ihn hinzuzufügen.
Konfigurieren Sie wie in der Abbildung unten gezeigt:
- API-Basis-URL.
https://bailian.aliyuncs.com(Allgemein) - API-Schlüssel. Fügen Sie den API-Schlüssel ein, den Sie im vorherigen Schritt kopiert haben
- Modelle. Modellname hinzufügen
qwq-plus(muss der Name sein)
3. die Erfahrung beginnen
Kehren Sie zum Chatwise-Hauptbildschirm zurück und wählen Sie das Modell "qwq-plus" aus dem Dropdown-Menü für die Modellauswahl, um Ihren Dialog zu beginnen.
Leistung unter realen Bedingungen: vergleichbar mit oder besser als lokale Bereitstellungen
Um die tatsächliche Leistung der QwQ Plus API zu überprüfen, haben wir einen einfachen Vergleichstest durchgeführt.
Geschwindigkeitstest:
Die Messungen zeigen, dass die Geschwindigkeit der QwQ Plus API-Schnittstelle mit einer stabilen Rate von 40-50 Token/Sekunde hervorragend ist. Im Vergleich dazu ist die DeepSeek R1-Modell-API ist die Rate mit 10+ Token/Sek. deutlich langsamer.
Kompatibilitätstests:
Benutzer können die QwQ Plus API auch auf einem Client wie CherryStudio konfigurieren und verwenden, aber während der Tests von CherryStudio wurde ein potenzielles Problem beobachtet: Wenn das Modell über einen langen Zeitraum komplexe Schlussfolgerungen durchführt, kann CherryStudio eine große Menge an Systemressourcen verbrauchen, und auf einigen konfigurierten Geräten kann es zu einem Neustart der Software kommen. Bei der Verwendung des Chatwise-Clients in der gleichen Hardwareumgebung traten jedoch keine ähnlichen Probleme auf. Dies kann mit Unterschieden in den Entwicklungs-Frameworks für verschiedene Clients zusammenhängen.
Kompetenzvergleich:
Wir folgen den vorherigen Fragen zum logischen Denken mit Hut und vergleichen die Leistung des nativen QwQ32-Modells mit der der QwQ Plus API.
Problembeschreibung:
Es stehen 5 Personen in einer Reihe, jede mit einem roten oder blauen Hut. Sie können die Hüte der Personen vor ihnen sehen, aber nicht ihren eigenen. Der Moderator verkündet: "Es gibt mindestens einen roten Hut". Beginnend mit der letzten Person, sagt jede Person der Reihe nach "ja" oder "nein" (und gibt damit an, ob sie die Farbe ihres Hutes kennt oder nicht). Wenn die 5. Person "Nein" sagt und die 4. Person "Ja" sagt, wird die Verteilung aller möglichen Hutfarben ermittelt.
Lokale Leistung des QwQ32-Modells:

Das lokale Modell QwQ32 wurde schließlich nach zwei Versuchen erfolgreich beantwortet, wobei der zweite 196 Sekunden dauerte.
QwQ Plus API-Leistung:
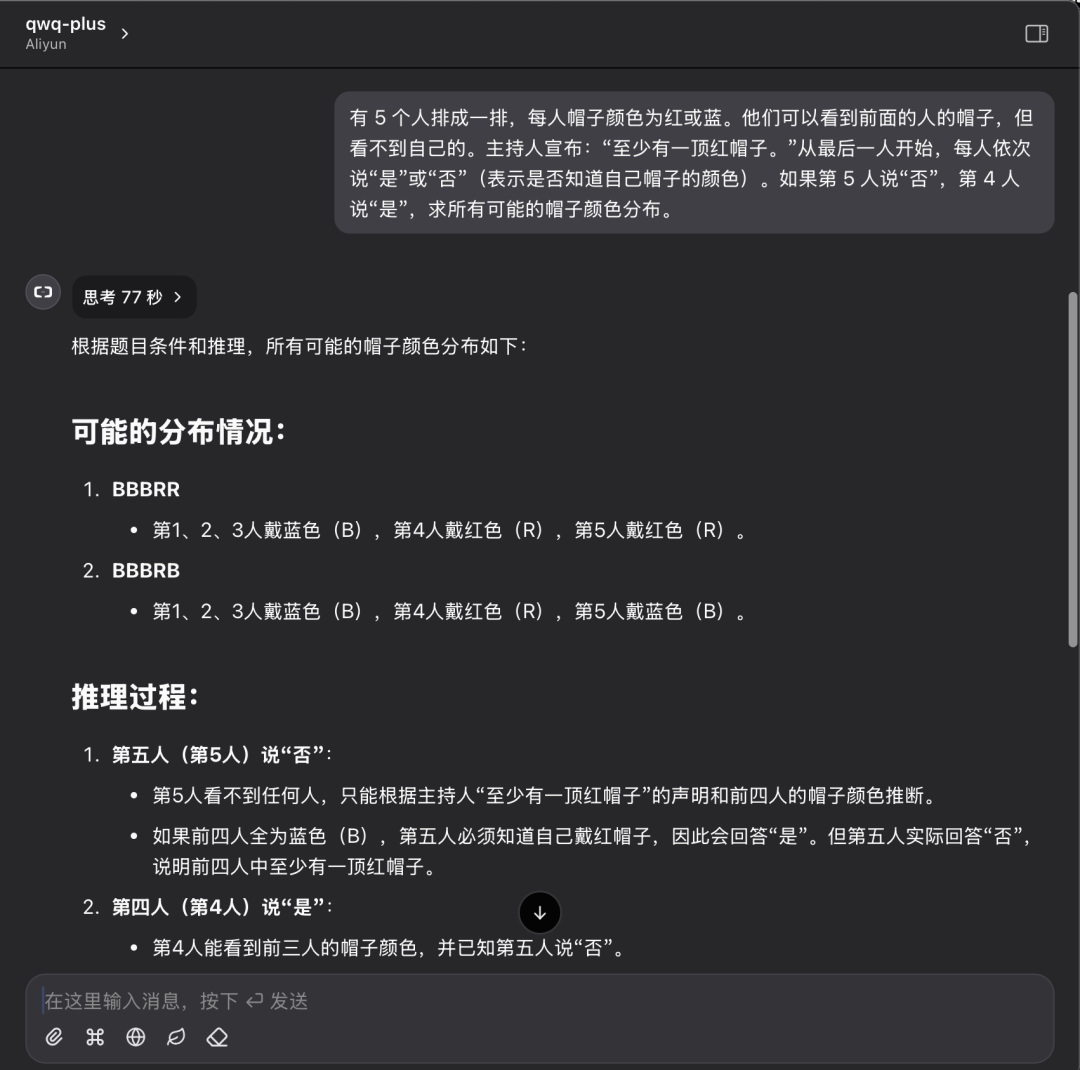
QwQ Plus API-Leistung bei derselben Frage: einmalige richtige Antwort in 77 Sekunden.
Analyse der Testergebnisse:
Obwohl ein einziger Fall nicht ausreicht, um die Fähigkeit des Modells vollständig zu bewerten, können die Ergebnisse dieses Tests den Unterschied zwischen dem lokal bereitgestellten Modell und der Cloud-API-Lösung visuell widerspiegeln. Beim Lösen logischer Schlussfolgerungen können beide Lösungen korrekte Antworten geben, aber die QwQ Plus API ist besser in Bezug auf Effizienz und Klarheit des Schlussfolgerungsprozesses, mit kürzerer Schlussfolgerungszeit und geringerem Tokenverbrauch.
Cloud AI für alle zugänglich machen
Die kostenlose Öffnung der QwQ-32B API-Schnittstelle auf der AliCloud Hundred Refine-Plattform und die Bereitstellung großzügiger kostenloser Token ist zweifellos ein wichtiger Schritt zur Förderung der Popularität der Technologie zur Modellierung großer Sprachen. Mit der API-Schnittstelle können Nutzer die Leistungsfähigkeit von leistungsstarken KI-Modellen in der Cloud einfach erleben, ohne in teure Hardware zu investieren. Egal, ob Sie Entwickler, Forscher oder KI-Enthusiast sind, Sie können jetzt die kostenlosen Ressourcen von Aliyun Hundred Refine in vollem Umfang nutzen, um Ihre KI-Erkundungsreise zu beginnen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel




Keine Kommentare...