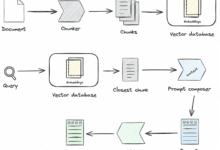
Grundkonzept
Im Bereich der Informationstechnologie.Abruf bedeutet, dass aus einem großen Datenbestand (in der Regel ein Dokument, eine Webseite, ein Bild, ein Audio, ein Video oder eine andere Form von Information) auf der Grundlage der Anfrage oder des Bedarfs eines Nutzers dieDer Prozess des effizienten Auffindens und Extrahierens relevanter Informationen. Ihr Hauptziel ist die Suche nachInformationen, die den Bedürfnissen der Nutzer entsprechenund präsentieren sie dem Benutzer.
- AbfrageSuchbegriff: Ein vom Benutzer eingegebener Suchbegriff oder eine Bedingung.
- IndexEine Datenstruktur, die Daten vorverarbeitet, um die Abfrageeffizienz zu verbessern.
- RelevanzDie Übereinstimmung der abgerufenen Ergebnisse mit der Abfrage.
RAG-Schemata, die auf dem Aufbau großer Modell-Wissensbasen beruhen, verwenden oft nicht nur eine einzige "Retrieval"-Technik, z.B. die häufig verwendete: sparse + dense hybrid retrieval. Die Auswahl der Retrieval-Technik muss sorgfältig an den abzurufenden Inhalt angepasst werden, was einen hohen Aufwand an Fehlersuche erfordert.

Das Mainstream-Retrieval-Modell
Retrieval-Modelle werden hauptsächlich wie folgt klassifiziert: boolesche Modelle, Vektorraummodelle, probabilistische Modelle, neuronale Netzmodelle, Graphenmodelle (z. B. Knowledge Graph) und Sprachmodelle (z. B. GPT3).
Die wichtigsten Retrieval-Modelle lassen sich "einfach" in zwei Kategorien einteilen, wobei der Hauptunterschied darin besteht, wie sie Text verstehen und zuordnen:
1. lexikalisches/schlüsselwortbasiertes Matching.
Diese Art von Modell konzentriert sich auf Abfragen und Dokumente inWörtlich übereinstimmende Wörterohne ein tieferes Verständnis für die Bedeutung hinter den Worten.
-
Kerngedanke. Zählen Sie die Vorkommen von Wörtern in Dokumenten und Abfragen und gleichen Sie diese ab.
-
Hauptmodelle.
-
Boolesches Modell. Einfacher Abgleich auf der Grundlage des Vorhandenseins oder Nichtvorhandenseins des Schlüsselworts (AND, OR, NOT).
-
Vektorraummodell (VSM). Dokumente und Abfragen werden als Vektoren von Wortgewichten dargestellt, die durch Vektorähnlichkeit (z. B. Kosinusähnlichkeit) abgeglichen werden. Eine gängige Gewichtungsmethode ist TF-IDF.
-
BM25. Ein verbessertes, auf probabilistischen Statistiken basierendes Modell, das Faktoren wie die Dokumentlänge berücksichtigt, ist ein Eckpfeiler vieler Suchmaschinen.
-
Vorteile. Einfach, effizient und leicht zu implementieren.
Benachteiligungen. Unfähigkeit, die semantischen Beziehungen von Wörtern zu verstehen und Anfälligkeit für Probleme wie Synonyme und Polysemie.
2. semantisches/bedeutungsbasiertes Matching.
Semantisch basierte Einbettungsmodelle unterstützen nicht nur unterschiedliche Längen und Dimensionen des eingebetteten Textes, sondern auch unterschiedliche Arten des Verständnisses von "Sätzen", was bei der Auswahl von Einbettungsmodellen eine Priorität darstellt (obwohl die meisten von ihnen allgemeinere Modelle verwenden).
So wird beispielsweise das Wort "Apfel" von einigen Modellen semantisch dem Wort "Obst" und von anderen dem Wort "Mobiltelefon" vorgezogen.
Diese Art von Modell versucht, die Abfrage und das Dokument zu verstehentiefe semantische Informationenund nicht nur oberflächliche Wortübereinstimmungen.
-
Kerngedanke. Abbildung von Texten im semantischen Raum und Abgleich durch semantische Ähnlichkeit.
-
Hauptmodelle.
-
Thema Modelle. Durchsuchen von Dokumenten nach potenziellen Themen, die anhand der Themenähnlichkeit (z. B. LDA) ermittelt werden.
-
Modelle einbetten. Durch die Abbildung von Wörtern, Sätzen oder Dokumenten in einen niedrigdimensionalen dichten Vektorraum werden semantische Informationen erfasst.
-
Wort-Einbettungen. Beispiele sind Word2Vec, GloVe, FastText.
-
Satzeinbettungen. Beispiele sind Sentence-BERT, Universal Sentence Encoder. OpenAI-Einbettungen.
-
-
Dichte Retrieval-Modelle. Abfragen und Dokumente werden mithilfe von Deep-Learning-Modellen (in der Regel Transformer) in hochdimensionale dichte Vektoren kodiert und anhand der Vektorähnlichkeit abgerufen. Beispiele hierfür sind DPR, Contriever und das OpenAI-Einbettungen Das konstruierte Abfragesystem.
-
Neuronale Interaktionsmodelle. Feinere Modellierung der Interaktionen zwischen Abfragen und Dokumenten, z. B. ColBERT, RocketQA.
-
Graphische neuronale Netzmodelle. Dokumente und Abfragen werden zu Graphen aufgebaut und anhand der Graphenstruktur abgerufen.
-
Vorteile. Die Fähigkeit, die Bedeutung von Texten besser zu verstehen, mit semantischen Zusammenhängen umzugehen und relevante Informationen genauer zu finden.
Benachteiligungen. In der Regel komplexer und rechenintensiver.
Hauptunterschied:
-
Lexikalische Abgleichsmodelle sehen "wörtlich" ausmit Schwerpunkt auf dem Vorkommen von Schlüsselwörtern.
-
Semantische Abgleichsmodelle betrachten die "Bedeutung"Der Schwerpunkt liegt dabei auf den inneren Bedeutungen und Beziehungen des Textes.
Zusammenfassende Tabelle:
| Kategorisierung | Kerngedanke | Hauptmodelle | RAG Anwendungsschwerpunkt in |
| Wortschatzbasierter Abgleich | Wörtlich übereinstimmende Wörter | Boolesche Modelle, Vektorraummodelle (VSMs), BM25 | Frühe oder einfache Szenarien |
| Semantisch basierter Abgleich | Verstehen tiefer semantischer Informationen | Themenmodelle, Modelle zur Einbettung von Wörtern, Modelle zur Einbettung von Sätzen (mit OpenAI-Einbettungen), dichte Suchmodelle (einschließlich solcher, die auf OpenAI-Einbettungen Systeme), Interaktionsmodelle für neuronale Netze, Modelle für graphische neuronale Netze | Mainstream-Auswahl, mit besonderem Schwerpunkt auf Satzeinbettung und intensiver Suche |
Anwendungen in der RAG
RAG (Abruf-Augmented Generation)ist ein KI-Rahmenwerk, das Abruf- und Generierungstechniken kombiniert, deren Hauptzweck darin besteht, die Genauigkeit und kontextuelle Relevanz der generierten Inhalte zu verbessern.
- AbrufphaseIdentifizierung von Dokumenten oder Passagen aus einer großen Wissensdatenbank, die für die Benutzereingabe relevant sind.
- Erzeugungsphase: Verwenden Sie die abgerufenen Informationen als Kontext, um Antworten oder Inhalte zu generieren.
In RAG ist das Retrieval-Modell für die Bereitstellung hochwertiger Informationsquellen zuständig, während das generative Modell für die Generierung natürlichsprachlicher Antworten auf der Grundlage dieser Informationen verantwortlich ist. Da RAG aktuelle Informationen aus externen Wissensquellen beziehen kann, ist es besonders leistungsfähig bei der Beantwortung wissensintensiver Fragen.
Anwendungsschwerpunkt in der RAG:
In RAG (Retrieval Augmentation Generation).Semantische Abgleichsmodelle werden oft bevorzugtSie sind in der Lage, kontextbezogene Informationen, die für die Anfrage des Nutzers relevant sind, genauer abzurufen und so dem generativen Modell zu helfen, genauere und kohärentere Antworten zu geben. Im Besonderen.Modelle zur Einbettung von Sätzen und dichte RetrievalmodelleZum Beispiel, basierend auf OpenAI-Einbettungen die in RAG-Systemen aufgrund ihrer hervorragenden semantischen Darstellungsfähigkeit und Abrufeffizienz weit verbreitet ist.
Fall (Recht)
1. die Anwendung von Lexical Retrieval (Lexical Retrieval)
-
Kerngedanken: Das Retrievalsystem stützt sich stark auf Abfragen und Dokumente inWörtlich: Stichwortabgleich.
-
Fall 1: Suche nach einem bestimmten Befehl in der technischen Dokumentation
-
Schauplatz: Sie verwenden eine Software und möchten wissen, wie Sie eine Datei kopieren können, und müssen den entsprechenden Befehl finden.
-
Mechanismus zum Abrufen: Das RAG-System verwendet ein wortschatzbasiertes Modell (z.B. BM25), um die Hilfedokumentation der Software nach Passagen zu durchsuchen, die die Schlüsselwörter "copy file", "file copy command" oder "copy file" enthalten.
-
Beispiel für Suchergebnisse: Das System kann einen Abschnitt des Dokuments mit dem Titel "File Management Commands" finden, der den Abschnitt "Using the cp Nachfolgend finden Sie eine Beschreibung des Befehls "Befehl zum Kopieren einer Datei".
-
Wie man helfen kann, zu generieren: Die spezifischen Anweisungen für die abgerufenen Einschließungsbefehle werden dem Generierungsmodell zur Verfügung gestellt, das genauere Handlungsschritte generieren kann, z. B. "Sie können die cp Befehl, um eine Datei zu kopieren. Zum Beispiel.cp quelle.txt ziel.txt kopiert source.txt nach destination.txt."
-
Wichtige Punkte: Der Abruf beruht auf der exakten Übereinstimmung von Schlüsselwörtern. Wenn Sie einen anderen Begriff verwenden, z. B. "Kopien von Dokumenten verschieben", erhalten Sie möglicherweise nicht die gleichen Ergebnisse.
-
-
Fall 2: Suche nach einem bestimmten Modell in einem Katalog
-
Schauplatz: Sie möchten ein bestimmtes Druckermodell kaufen, z. B. "Modell XYZ-123".
-
Mechanismus zum Abrufen: Das RAG-System sucht in der Katalogdatenbank nach Einträgen, die die genaue Modellbezeichnung "XYZ-123" enthalten.
-
Beispiel für Suchergebnisse: Das System findet Produkteinträge mit dem Namen, den detaillierten Spezifikationen, dem Preis und anderen Informationen über "Drucker XYZ-123".
-
Wie man helfen kann, zu generieren: Die abgerufenen Produktinformationen können direkt genutzt werden, um Einführungen, Preisanfragen oder Kauflinks etc. zu dem Druckermodell zu generieren.
-
Wichtige Punkte: Verlassen Sie sich auf die genaue Übereinstimmung der Produktmodelle. Wenn der Benutzer eine vage Beschreibung eingibt, wie z. B. "Hochleistungsdrucker", funktioniert eine begriffsbasierte Suche möglicherweise nicht gut.
-
2. semantische Retrieval-Anwendungen
-
Kerngedanken: Das Retrievalsystem versteht die Anfrage und das Dokumenttiefe semantische Informationenkönnen Sie relevante Inhalte finden, auch wenn Sie nicht genau dieselben Schlüsselwörter haben.
-
Fall 3: Suche nach Informationen über die Symptome einer Krankheit in der medizinischen Literatur
-
Schauplatz: Möchten Sie wissen: "Was sind die häufigsten Beschwerden, die durch Bluthochdruck verursacht werden?"
-
Mechanismus zum Abrufen: Das RAG-System verwendet ein semantisches Modell (z.B. dichte Suche auf der Basis von Sentence-BERT oder OpenAI Embeddings), um die Anfrage und die medizinische Literatur zu vektorisieren, und findet dann die dem Anfragevektor am nächsten liegende Passage im semantischen Raum. Selbst wenn die Dokumente nicht exakt denselben Wortlaut enthalten, z. B. wenn "erhöhter Blutdruck" statt "Hypertonie" oder spezifische Symptombeschreibungen statt "Unwohlsein" verwendet werden, können sie dennoch abgerufen werden. durchsucht werden.
-
Beispiel für Suchergebnisse: Das System kann Passagen finden, die den folgenden Text enthalten: "Menschen mit Bluthochdruck berichten häufig über Symptome wie Kopfschmerzen, Schwindel und Engegefühl in der Brust. Länger anhaltender unkontrollierter Bluthochdruck kann zu Herzklopfen und Atembeschwerden führen."
-
Wie man helfen kann, zu generieren: Die abgerufenen Beschreibungen der Symptome von Bluthochdruck werden dem generativen Modell zur Verfügung gestellt, das eine natürlichere und umfassendere Antwort geben kann: "Bluthochdruck kann eine Vielzahl von Beschwerden verursachen, zu denen in der Regel Kopfschmerzen, Schwindel und Engegefühl in der Brust gehören. Schwerer oder lang anhaltender Bluthochdruck kann auch Herzklopfen und Atembeschwerden verursachen."
-
Wichtige Punkte: Synonyme ("erhöhter Blutdruck" vs. "Bluthochdruck"), unmittelbare Ausdrücke ("körperliches Unwohlsein" vs. "Kopfschmerzen, Schwindelgefühl ") und verwandte Konzepte, die einen umfassenderen Kontext bieten.
-
-
Fall 4: Auffinden ähnlicher Textstile in der Unterstützung für kreatives Schreiben
-
Schauplatz: Sie arbeiten an einem Science-Fiction-Roman und suchen nach Passagen in einem ähnlichen literarischen Stil, die Ihnen als Inspiration dienen sollen. Sie tippen: "Beschreiben Sie eine blühende Vision einer zukünftigen Stadt, voller hoch aufragender Gebäude und dichtem Verkehr".
-
Mechanismus zum Abrufen: Das RAG-System verwendet ein semantisches Modell, um eine große Bibliothek von Science-Fiction-Texten zu durchsuchen und nach Passagen zu suchen, die Ihrer Beschreibung semantisch am nächsten kommen, auch wenn sie nicht genau Schlüsselwörter wie "Stadt der Zukunft" oder "Boom" enthalten.
-
Beispiel für Suchergebnisse: Das System könnte Passagen finden wie: "Stahlriesen durchstießen die Wolken, und Glaswände reflektierten buntes Licht. Fliegende Autos pendelten wie Shuttles zwischen den Gebäuden hin und her, am Boden wuselten Menschenmassen, und das Summen der Energie erfüllte die Stadt, die niemals schläft.
-
Wie man helfen kann, zu generieren: Abgerufene Passagen mit ähnlichen Stimmungen und Beschreibungen können als Referenz für das generative Modell verwendet werden und helfen ihm, einen Text zu erstellen, der Ihrem gewünschten Stil besser entspricht.
-
Wichtige Punkte: Die Fähigkeit, die implizite Bedeutung, die emotionale Färbung und den Stil eines Textes zu verstehen, geht über den einfachen Abgleich von Schlüsselwörtern hinaus und konzentriert sich mehr auf semantische Ähnlichkeiten.
-
![Agenten-KI: Erkundung der Grenzwelt der multimodalen Interaktion [Fei-Fei Li - Classic Must Read] - Chief AI Sharing Circle](https://www.aisharenet.com/wp-content/uploads/2025/01/6dbf9ac2da09ee1-220x150.png)