Vor der formalen Diskussion ist es notwendig, das Konzept des KI-Crawlers (auch LLM-Crawler genannt) zu klären, das grob in zwei Kategorien eingeteilt werden kann: grob kann in zwei Kategorien eingeteilt werden, eine ist das konventionelle Crawler-Tool, außer dass seine Ergebnisse direkt im Kontext des LLM verwendet werden, was streng genommen nichts mit der KI zu tun hat; die andere ist eine neue Art von Crawler-Programm, das vom LLM angetrieben wird, wo der Benutzer das Ziel der Datensammlung durch natürliche Sprache angibt, und dann wird der LLM autonom die Struktur der Webseite analysieren, um eine interaktive Operation zu formulieren, um dynamische Daten zu erhalten, und schließlich strukturierte Zielinhalte zurückgeben. Die andere ist eine neue Art von LLM-gesteuerter Crawler-Lösung, bei der der Benutzer das Ziel für die Datenerfassung durch natürliche Sprache angibt und der LLM dann die Struktur der Webseite analysiert, eine Crawling-Strategie entwickelt, Interaktionen durchführt, um dynamische Daten zu erhalten, und schließlich strukturierte Zielinhalte zurückgibt.
LLM-gesteuertes Crawler-Programm
Auf der Idee und Praxis der generischen KI-gesteuerten Web-Crawler, können Sie diesen Artikel im Detail zu lesen, der Autor von der Idee bis zur Lösung, und dann auf die Abstimmung und Analyse der Ergebnisse, sehr detailliert, voll von trockenen Waren, ich bemühe mich, kurz vorstellen, diesen Prozess zu Ihnen schnell. Der gesamte Prozess ist eine erschöpfende Simulation der menschlichen Schritte:
- Durchsuchen Sie zunächst den gesamten HTML-Code der Webseite.
- Die KI wird dann verwendet, um eine Reihe von verwandten Begriffen zu generieren, z. B. wenn man nach Preisen sucht, generiert die KI verwandte Schlüsselwörter (Preise, Gebühren, Kosten usw.).
- Durchsuchen Sie die HTML-Struktur anhand dieser Schlüsselwörter, um eine Liste der relevanten Knoten zu finden.
- Verwenden Sie AI, um die Liste der Knoten zu analysieren und die wichtigsten zu identifizieren.
- Die AnwendungskI bestimmt, ob eine Interaktion mit dem Knoten erforderlich ist (in der Regel eine Klick-Aktion).
- Wiederholen Sie die oben genannten Schritte, bis das endgültige Ergebnis erreicht ist.
Skyvern
Skyvern ist ein Browser-Automatisierungstool, das auf einem multimodalen Modell basiert, um die Effizienz und Anpassungsfähigkeit der Workflow-Automatisierung zu erhöhen. Im Gegensatz zu herkömmlichen Automatisierungsansätzen, die oft auf Site-spezifischen Skripten, DOM-Parsing und XPath-Pfaden beruhen, die dazu neigen, bei Änderungen des Site-Layouts zu versagen, generiert Skyvern Interaktionspläne durch die Analyse visueller Elemente im Browserfenster in Echtzeit, in Verbindung mit dem LLM, wodurch es auf unbekannten Sites ohne benutzerdefinierten Code ausgeführt werden kann und viel widerstandsfähiger gegenüber Site-Layout Änderungen. Browser-basierte Workflows werden durch die Einbindung von Browser-Automatisierungsbibliotheken wie Playwright automatisiert, die aus den folgenden Schlüsselagenten bestehen:
- Interaktiver Element-Agent: verantwortlich für das Parsen der HTML-Struktur einer Webseite und das Extrahieren interaktiver Elemente.
- Navigationsagent: Verantwortlich für die Planung des Navigationspfads, der für die Erledigung der Aufgabe erforderlich ist, wie z. B. das Anklicken von Schaltflächen, die Eingabe von Text usw.
- Data Extraction Agent: Verantwortlich für die Extraktion von Daten aus Webseiten, kann Tabellen und Text lesen und Daten in einem benutzerdefinierten strukturierten Format ausgeben.
- Passwort-Agent: Verantwortlich für das Ausfüllen der Passwortformulare der Website. Er kann Benutzernamen und Passwörter aus einem Passwort-Manager auslesen und die Formulare ausfüllen, wobei er die Privatsphäre des Benutzers schützt.
- 2FA-Agent: Verantwortlich für das Ausfüllen des 2FA-Formulars, in der Lage, 2FA-Anfragen von einer Website abzufangen und den 2FA-Code entweder über eine benutzerdefinierte API zu erhalten oder darauf zu warten, dass der Benutzer ihn manuell eingibt.
- Dynamischer Autovervollständigungs-Agent: Verantwortlich für das Ausfüllen dynamischer Autovervollständigungsformulare, die in der Lage sind, geeignete Optionen auszuwählen und die Eingabe auf der Grundlage von Benutzereingaben und Formularfeedback anzupassen.

ScrapegraphAI
ScrapeGraphAI reduziert den Bedarf an manueller Programmierung, indem es den Aufbau von Crawling-Pipelines durch Big Talk-Modelle und Graphenlogik automatisiert. Die durchschnittliche Person gibt einfach die erforderlichen Informationen an und ScrapeGraphAI erledigt automatisch einzelne oder mehrseitige Crawling-Aufgaben, um Webseiten effizient zu crawlen. Es unterstützt eine Vielzahl von Dokumentenformaten wie XML, HTML, JSON und Markdown, und ScrapeGraphAI bietet mehrere Crawling-Typen, darunter:
- SmartScraperGraphSingle-Page-Crawling: Das Crawling einer einzelnen Seite kann mit nur einer Benutzerabfrage und einer Eingabequelle erreicht werden.
- SearchGraphEin mehrseitiger Crawler, der Informationen aus den wichtigsten Suchergebnissen extrahiert.
- SpeechGraphEin One-Page-Grabber, der Website-Inhalte in Audiodateien umwandelt.
- ScriptCreatorGraphSingle Page Grabber, der Python-Skripte für die extrahierten Daten erstellt.
- SmartScraperMultiGraphMulti-Page-Crawling durch eine einzige Eingabeaufforderung und eine Reihe von Quellen.
- ScriptCreatorMultiGraphEin Multi-Page-Crawler, der Informationen von mehreren Seiten und Quellen extrahiert und die entsprechenden Python-Skripte erstellt.
ScrapeGraphAI vereinfacht den Prozess des Web-Scrapings, indem es normalen Menschen ermöglicht, Scraping-Aufgaben ohne tiefgreifende Programmierkenntnisse zu automatisieren, indem es einfach Informationsanforderungen bereitstellt, das Scraping von einer einzelnen Seite bis hin zu mehreren Seiten für Datenextraktionsaufgaben unterschiedlichen Umfangs unterstützt und eine Pipeline verschiedener Anwendungen für unterschiedliche Scraping-Bedürfnisse bereitstellt, einschließlich Informationsextraktion, Audiogenerierung und Skripterstellung.
Konventionelle Crawler-Tools
Solche Tools bereinigen und konvertieren reguläre Online-Webinhalte in das Markdown-Format, damit sie vom Big Model besser verstanden und verarbeitet werden können (die Antworten des Big Models sind von höherer Qualität, wenn die Daten in einem strukturierten und Markdown-Format vorliegen), und die konvertierten Inhalte dienen als Kontext für das LLM, so dass das Modell Fragen in Verbindung mit Online-Ressourcen beantworten kann.
Crawl4AI
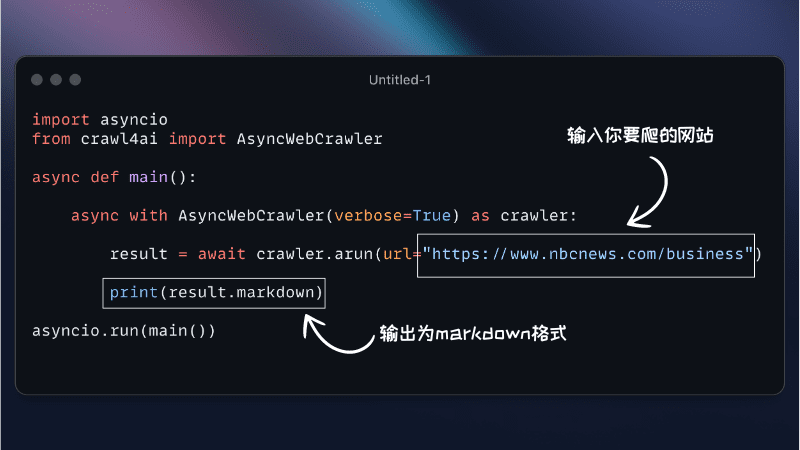
Crawl4AI ist ein Open-Source-Web-Crawler und ein Datenextraktions-Framework, das speziell für KI-Anwendungen entwickelt wurde und es ermöglicht, mehrere URLs gleichzeitig zu crawlen, wodurch die Zeit, die für eine umfangreiche Datenerfassung benötigt wird, erheblich reduziert wird.4AI zeichnet sich durch folgende Merkmale aus, die es zu einem leistungsstarken Web-Crawler machen:
- Mehrere AusgabeformateUnterstützt mehrere Ausgabeformate wie JSON, Minimal HTML und Markdown.
- Unterstützung für dynamische InhalteDurch benutzerdefinierten JavaScript-Code kann Crawl4AI das Benutzerverhalten simulieren, z. B. das Klicken auf die Schaltfläche "Weiter", um weitere dynamische Inhalte zu laden. Mit diesem Ansatz kann Crawl4AI gängige Mechanismen zum Laden dynamischer Inhalte wie Paging und unendliches Scrollen handhaben.
- Mehrere Chunking-StrategienUnterstützt eine Vielzahl von Chunking-Strategien, wie z. B. Themen, reguläre Ausdrücke und Sätze, die es den Benutzern ermöglichen, die Daten an ihre spezifischen Bedürfnisse anzupassen.
- MedienextraktionMit leistungsstarken Methoden wie XPath und regulären Ausdrücken, die es dem Benutzer ermöglichen, die benötigten Daten zu lokalisieren und zu extrahieren, kann es eine Vielzahl von Medientypen extrahieren, einschließlich Bilder, Audio und Video, und ist besonders nützlich für Anwendungen, die auf Multimedia-Inhalte angewiesen sind.
- Benutzerdefinierte HakenBenutzer können benutzerdefinierte Hooks definieren, z. B. solche, die zu Beginn der Ausführung des Crawlers ausgeführt werden.
on_execution_startedHaken. Damit kann sichergestellt werden, dass alle erforderlichen JavaScript ausgeführt und dynamische Inhalte auf die Seite geladen wurden, bevor das Crawling beginnt. - gute StabilitätDas Crawling dynamischer Inhalte kann aufgrund von Netzwerkproblemen oder JavaScript-Ausführungsfehlern fehlschlagen. Die Fehlerbehandlung und der Wiederholungsmechanismus von Crawl4AI stellen sicher, dass die Daten auch bei solchen Problemen erneut versucht werden können, um Integrität und Genauigkeit zu gewährleisten.
Leser
Web Content Crawling Tool entwickelt von Jina AI Leser-API Darüber hinaus kann der Benutzer den Inhalt einer Seite bereinigen und formatieren, indem er einfach die URL eingibt und sie im einfachen Text- oder Markdown-Format ausgibt. Ziel ist es, jede Webseite in ein Eingabeformat umzuwandeln, das für das Verständnis durch große Modelle geeignet ist, d. h. Rich-Text-Inhalte in einfachen Text, z. B. Bilder in Beschreibungstext.

Firecrawl
Firecrawl ist eleganter und leistungsfähiger als Reader und ist ein ausgereifteres Produkt. Es bietet eine vereinfachte API-Schnittstelle für das Crawlen und Extrahieren von Daten aus einer gesamten Website. Firecrawl ist in der Lage, Website-Inhalte in Markdown, formatierte Daten, Screenshots, komprimiertes HTML, Hyperlinks und Metadaten zu konvertieren, um die Verwendung von LLM besser zu unterstützen. Darüber hinaus ist Firecrawl in der Lage, komplexe Aufgaben wie Proxy-Setup, Anti-Crawler-Mechanismen, Umgang mit dynamischen Inhalten wie JavaScript-Rendering, Output-Parsing und Task-Koordination zu übernehmen. Entwickler können das Verhalten des Crawlers individuell anpassen, z. B. bestimmte Tags ausschließen, Seiten crawlen, die eine Authentifizierung erfordern, die maximale Crawling-Tiefe festlegen usw. Firecrawl unterstützt das Parsen von Daten aus einer Vielzahl von Medientypen, einschließlich PDFs, DOCX-Dokumenten und Bildern. Seine Zuverlässigkeit gewährleistet einen effektiven Zugriff auf die benötigten Daten in einer Vielzahl von komplexen Umgebungen. Benutzer können mit Webseiten interagieren, indem sie das Klicken, Scrollen, Tippen usw. simulieren. Die neueste Version unterstützt auch die Stapelverarbeitung einer großen Anzahl von URLs.
- Unterstützung für mehrere Programmiersprachen SDK: Python, Node, Go, Rust
- Kompatibel mit mehreren KI-Entwicklungsframeworks: [Langchain (Python)](https://python.langchain.com/docs/integrations/document_loaders/firecrawl/ "Langchain (Python " Langchain (Python)")"), [Langchain (JS)](https://js.langchain.com/docs/integrations/document_loaders/web_loaders/firecrawl "Langchain ( JS "Langchain (JS)")"), LlamaIndex, Crew.ai, Composio, PraisonAI, Superinterface, Vectorize
- Unterstützung von Low-Code-KI-Plattformen: Dify, Langflow, Flowise AI, Cargo, Pipedream
- Unterstützung von Automatisierungstools: Zapier, Pabbly Connect
Markdowner
Wenn Sie es sich nicht leisten können, für die ersten beiden Tools zu bezahlen, oder wenn deren Bereitstellung zu viele Ressourcen in Anspruch nimmt, sollten Sie Markdowner in Betracht ziehen. Markdowner konvertiert Website-Inhalte in das Markdown-Format und verfügt zwar nicht über so viele Funktionen wie Firecrawl, ist aber für den täglichen Bedarf mehr als ausreichend. Das Tool unterstützt automatisiertes Crawling, LLM-Filterung, ein detailliertes Markdown-Schema sowie Text- und JSON-Antwortformate. markdowner bietet eine API-Schnittstelle, über die Nutzer über GET-Anfragen auf das Tool zugreifen und den Antworttyp und den Inhalt über URL-Parameter anpassen können. Technisch gesehen nutzt Markdowner die Cloudflare Workers und Turndown-Bibliotheken für die Transformation von Webinhalten.
der Rest
Ähnliche Crawler sind webscraper, code-html-to-markdown (das besonders gut mit Codeblöcken umgehen kann), MarkdownDown, gpt-api und web.scraper.workers.dev (Stets verwendetes Tool, das die Filterung von Inhalten und den Zugang zu kostenpflichtigen Inhalten mit geringfügigen Änderungen unterstützt), können diese Werkzeuge nach der Selbstentwicklung als Plug-ins für große Modelle verwendet werden, um auf Online-Inhalte zuzugreifen, und gehören zur Phase der Datenvorverarbeitung.
am Ende schreiben
Herkömmliche Crawler-Tools haben nicht viel zu erforschen, auch nicht die Einführung einer neuen Technologie, außer dass LLM eine neue Generation von Crawler-Tools hervorgebracht hat, die die Erfahrung des Entwicklers erheblich verbessert, nur eine API, die flexibel angepasst werden kann, um den gewünschten Inhalt zu crawlen, was den Komfort erheblich verbessert. Es ist erwähnenswert, dass LLM-gesteuerte Crawler-Lösungen eigentlich Teil der Claude Das UFO-Projekt von Microsoft (das die menschliche Bedienung von Windows-Computern simuliert), AutoGLM von Smart Spectrum und AppAgent von Tencent (das die menschliche Bedienung von Mobiltelefonen simuliert) sind Beispiele für Forschungsrichtungen, die auch die Browser-Bedienung abdecken können. Daher sind LLM-gesteuerte Crawler-Tools möglicherweise nur eine vorübergehende Lösung, die in Zukunft durch solche umfassenderen Projekte ersetzt werden wird.

![Agenten-KI: Erkundung der Grenzwelt der multimodalen Interaktion [Fei-Fei Li - Classic Must Read] - Chief AI Sharing Circle](https://www.aisharenet.com/wp-content/uploads/2025/01/6dbf9ac2da09ee1-220x150.png)