在正式讨论之前,需要先明确 AI 爬虫(也称为 LLM 爬虫)的概念,它大致可以分为两类:大概可以分为两类,一类就是常规的爬虫工具,只不过它的结果是直接用于 LLM 的上下文,这类严格来说和 AI 没啥关系;另一类则是由 LLM 驱动的新型爬虫方案,用户通过自然语言指定数据采集的目标,随后 LLM 会自主分析网页结构,制定爬取策略,执行交互操作以获取动态数据,并最终返回结构化的目标内容。
LLM 驱动的爬虫方案
关于通用 AI 驱动的网页爬虫的思路与实践方法,可以详细读下这篇文章,作者从构思到解决方案,再到调优和结果分析,十分详细,干货满满,我这里力求简单的向大家快速介绍这个过程。整个流程详尽模拟了人的操作步骤:
- 首先爬取整个网页 HTML 代码。
- 然后利用 AI 生成一系列相关词汇,例如寻找价格时,AI 会生成相关关键词(prices,fee,,cost 等)。
- 根据这些关键词搜索 HTML 结构,定位到相关节点列表。
- 利用 AI 分析节点列表,确定最相关的节点。
- 应用 AI 判断是否需要与该节点进行交互(通常为点击操作)。
- 重复上述步骤,直至获得最终结果。
Skyvern
Skyvern 是一个基于多模态模型的浏览器自动化操作工具,旨在提高工作流程的自动化效率和适应性。与传统的自动化方法不同,传统方法通常依赖于特定的网站脚本、DOM 解析和 XPath 路径,这些方法在网站布局变动时容易失效。Skyvern 通过实时分析浏览器窗口中的视觉元素,结合 LLM 生成交互计划,从而能够在没有定制代码的情况下运行在未知的网站上,并且对网站布局的变化具有更高的韧性。通过结合浏览器自动化库如 Playwright,来自动化基于浏览器的工作流程,由以下几个关键的代理组成:
- Interactable Element Agent:负责解析网页的 HTML 结构,并提取可交互的元素。
- Navigation Agent:负责规划完成任务所需的导航路径,如点击按钮、输入文本等。
- Data Extraction Agent:负责从网页中提取数据,能够读取表格和文本,并将数据输出到用户定义的结构化格式中。
- Password Agent:负责填充网站的密码表单,能够从密码管理器中读取用户名和密码,并在保护用户隐私的同时填写表单。
- 2FA Agent:负责填充二次验证(2FA)表单,能够拦截网站的 2FA 请求,并通过用户定义的 API 获取 2FA 码或等待用户手动输入。
- Dynamic Auto-complete Agent:负责填写动态自动完成的表单,能够根据用户输入和表单反馈选择合适的选项,并调整输入内容。

ScrapegraphAI
ScrapeGraphAI 通过大言模型和图逻辑自动化构建抓取管道,减少了手动编码的需求。普通人只需指定所需信息,ScrapeGraphAI 就能自动处理单页或多页抓取任务,高效抓取网页。它支持多种文档格式,如 XML、HTML、JSON 和 Markdown,ScrapeGraphAI 提供了多种类型的抓取方式,包括:
- SmartScraperGraph:只需用户提示和输入源即可实现单页抓取。
- SearchGraph:从顶部搜索结果中提取信息的多页抓取器。
- SpeechGraph:将网站内容转换为音频文件的单页抓取器。
- ScriptCreatorGraph:为提取的数据创建 Python 脚本的单页抓取器。
- SmartScraperMultiGraph:通过单一提示和一系列来源实现多页抓取。
- ScriptCreatorMultiGraph:从多个页面和来源提取信息的多页抓取器,并创建相应的 Python 脚本。
ScrapeGraphAI 简化了网页抓取过程,普通人无需深入编程知识,只需提供信息需求,便能自动化抓取任务,支持从单个页面到多个页面的抓取,适用于不同规模的数据提取任务,提供不同用途的抓取管道,以满足不同的抓取需求,包括信息提取、音频生成和脚本创建。
常规的爬虫工具
这类工具通过将常规在线网页内容清洗并转换为 Markdown 格式,以便大模型更好地理解和处理(当数据以结构化和 Markdown 格式出现时,大模型的响应质量更高),转换后的内容作为 LLM 的上下文,使模型能够结合在线资源回答问题。
Crawl4AI
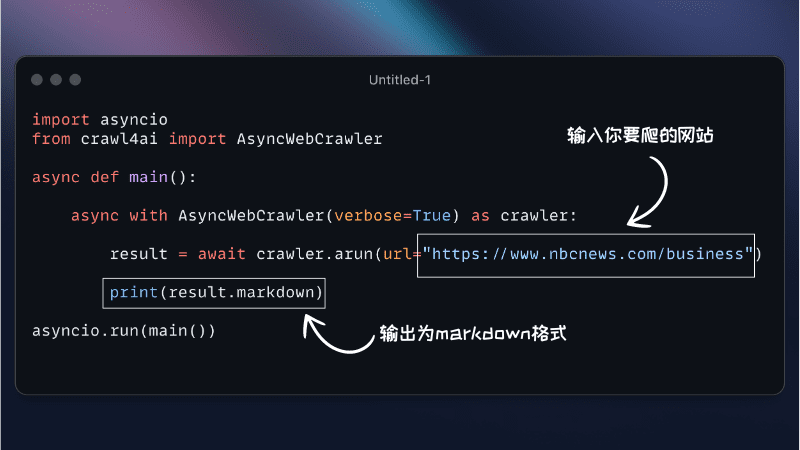
Crawl4AI 是一个专为 AI 应用设计的开源网络爬虫和数据提取框架,允许同时对多个 URL 进行爬取,大大减少了大规模数据收集所需的时间。Crawl4AI 在网页爬虫领域表现出色的关键特性包括:
- 多种输出格式:支持 JSON、极简 HTML 和 Markdown 等多种输出格式。
- 动态内容支持:通过自定义 JavaScript 代码,Crawl4AI 可以模拟用户行为,如点击 “下一页” 按钮来加载更多的动态内容。这种方法使得 Crawl4AI 能够处理分页和无限滚动等常见的动态内容加载机制。
- 多种分块策略:支持主题、正则表达式和句子等多种分块策略,使用户能够根据具体需求定制数据。
- 媒体提取:采用 XPath 和正则表达式等强大方法,使得用户能够精确地定位和提取所需的数据,能够提取各种媒体类型,包括图片、音频和视频,对于依赖多媒体内容的应用特别有用。
- 自定义钩子:用户可以定义自定义钩子(hooks),例如在爬虫执行开始时执行的
on_execution_started钩子。这可以用来确保在开始爬取之前所有必要的 JavaScript 都已经执行完毕,动态内容已经加载到页面上。 - 稳定性好:动态内容的爬取可能会因为网络问题或 JavaScript 执行错误而失败。Crawl4AI 的错误处理和重试机制能够确保即使在遇到这些问题时也能够重新尝试,以此来保证数据的完整性和准确性。
Reader
Jina AI 开发的网页内容抓取工具 Reader API ,用户只需输入网址,即可清理和格式化页面内容,输出纯文本或 Markdown 格式。目的是将任何网页转换为适合大模型理解的输入格式,即将富文本内容转换为纯文本,例如将图片转换为描述文字。

Firecrawl
Firecrawl 设计得比 Reader 更加优雅和强大,更像是一款成熟的产品。它提供了一个简化的 API 接口,用于整个网站的抓取和数据提取。Firecrawl 能够将网站内容转换成 Markdown、格式化数据、屏幕截图、精简的 HTML、超链接和元数据等形式,以更好地支持 LLM 的使用。此外,Firecrawl 还具备处理复杂任务的能力,比如代理设置、反爬虫机制、动态内容(如 JavaScript 渲染)的处理、输出解析和任务协调。开发者可以自定义爬虫的行为,例如排除特定标签、爬取需要身份验证的页面、设置最大爬取深度等。Firecrawl 支持多种媒体类型的数据解析,包括 PDF、DOCX 文档和图片。其可靠性能确保在各种复杂环境下有效获取所需数据。用户可以通过模拟点击、滚动、输入等操作与网页进行交互,最新版本还支持批量处理大量 URL。
- 支持多种编程语言 SDK:Python、Node、Go、Rust
- 兼容多个 AI 开发框架:[Langchain (Python)](https://python.langchain.com/docs/integrations/document_loaders/firecrawl/ "Langchain (Python "Langchain (Python)")")、[Langchain (JS)](https://js.langchain.com/docs/integrations/document_loaders/web_loaders/firecrawl "Langchain (JS "Langchain (JS)")")、LlamaIndex、Crew.ai、Composio、PraisonAI、Superinterface、Vectorize
- 低代码 AI 平台支持:Dify、Langflow、Flowise AI、Cargo、Pipedream
- 自动化工具支持:Zapier、Pabbly Connect
Markdowner
如果前两个工具的付费额度不足,或者自行部署占用资源过多,可以考虑使用 Markdowner。Markdowner 能将网站内容转换为 Markdown 格式,虽然其功能不如 Firecrawl 多样,但已足够满足日常需求。该工具支持自动爬取、LLM 过滤、详细的 Markdown 模式及文本和 JSON 响应格式。Markdowner 提供了一个 API 接口,允许用户通过 GET 请求访问,并可通过 URL 参数自定义响应类型和内容。技术上,Markdowner 利用了 Cloudflare Workers 和 Turndown 库进行网页内容的转换。
其他
类似的抓取工具还包括 webscraper、code-html-to-markdown(特别擅长处理代码块)、MarkdownDown、gpt-api 和 web.scraper.workers.dev(一直在使用的工具,支持内容过滤,稍加修改即可访问付费内容),这些工具经过自行部署后,可用作大模型获取在线内容的插件,属于数据预处理阶段的重要工具。
写在最后
常规的爬虫工具没有太多探讨的地方,也没有引入什么新的技术,只不过 LLM 催生的新一代爬虫工具,显著改善了开发者的使用体验,仅需一个 API 即可灵活定制抓取所需内容,极大地提升了便利性。值得注意的是,LLM 驱动的爬虫方案实际上属于 Claude 的“计算机使用”功能的一个分支,例如,微软的 UFO 项目(模拟人操作 Windows 系统电脑)、智谱的 AutoGLM 以及腾讯的 AppAgent(模拟人操作手机)等研究方向,都可能涵盖浏览器操作的功能。因此,LLM 驱动的爬虫工具目前可能只是临时解决方案,未来将被这类更全面的项目所取代。

![Agent AI: 探索多模态交互的前沿世界[李飞飞-经典必读]-首席AI分享圈](https://www.aisharenet.com/wp-content/uploads/2025/01/6dbf9ac2da09ee1-220x150.png)