Introdução geral
O VideoMind é uma ferramenta de IA multimodal de código aberto que se concentra em inferência, perguntas e respostas e geração de resumo para vídeos longos. Ela foi desenvolvida por Ye Liu, da Universidade Politécnica de Hong Kong, e por uma equipe do Show Lab da Universidade Nacional de Cingapura. A ferramenta imita a maneira como os humanos entendem vídeos, dividindo a tarefa em etapas como planejamento, posicionamento, verificação e resposta para resolver o problema passo a passo. A tecnologia principal é a Chain-of-LoRA, que alterna entre funções por meio de um modelo de base, que é eficiente e eficiente em termos de recursos.O VideoMind lança oficialmente o código, o modelo e o conjunto de dados em 21 de março de 2024, e o relatório técnico é atualizado em 17 de março de 2025.O VideoMind está disponível no GitHub ou via GitHub. Os usuários podem acessar os recursos via GitHub ou Hugging Face.
O projeto não extrai áudio para texto para entender o conteúdo, mas puramente gráfico e de acordo com o registro de data e hora para entender com precisão o conteúdo do vídeo, pode ser usado para ajuste fino automático de vídeo, cenários de ensino, muito prático!

Experiência: https://huggingface.co/spaces/yeliudev/VideoMind-2B
Lista de funções
- Segmentação temporal de vídeos longos: encontre o período de tempo no vídeo que seja relevante para a pergunta.
- Função de vídeo Q&A: extrai respostas precisas de vídeos com base nas perguntas do usuário.
- Geração de resumo de vídeo: destile o conteúdo principal do vídeo para gerar uma visão geral concisa.
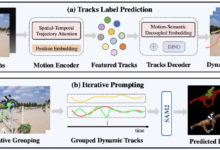
- Estrutura de agente multimodal: inclui planejadores, localizadores, validadores e respondedores que colaboram em tarefas.
- Tecnologia Chain-of-LoRA: multifuncionalidade com um único modelo e consumo reduzido de recursos.
- Suporte a vários hardwares: é executado em GPUs NVIDIA ou NPUs Ascend.
- Suporte eficiente ao treinamento: integração de DeepSpeed, LoRA, FlashAttention2 e outras tecnologias.
- Demonstração on-line: experimente rapidamente a funcionalidade por meio da interface do Gradio.
Usando a Ajuda
O VideoMind é um projeto de código aberto, os usuários precisam fazer download do código e configurar o ambiente para usá-lo. A seguir, um guia detalhado que abrange a instalação e o uso dos recursos.
Processo de instalação
- Repositório de código clone
Execute o seguinte comando no terminal para fazer download do código-fonte do VideoMind:
git clone https://github.com/yeliudev/VideoMind.git
Vá para o catálogo de projetos:
cd VideoMind
- Configuração do ambiente Python
Crie um ambiente virtual usando o conda (recomenda-se o Python 3.12):
conda create -n videomind python=3.12 -y
conda activate videomind
- Instalação de bibliotecas dependentes
Execute o seguinte comando para instalar as dependências necessárias:
pip install -r requirements.txt
Para um treinamento eficiente, instale o DeepSpeed:
pip install deepspeed
- Faça o download de modelos e conjuntos de dados
- Acesse https://huggingface.co/collections/yeliudev/videomind-67dd41f42c57f0e7433afb36 para fazer download de modelos pré-treinados (por exemplo
VideoMind-2B), descompacte-o no diretóriomodelsPasta. - Os conjuntos de dados estão disponíveis em https://huggingface.co/datasets/yeliudev/VideoMind-Dataset下载 e incluem 27 conjuntos de dados de vídeo e VideoMind-SFT (481 mil dados de treinamento) colocados no
dataCatálogo.
- instalação de teste
Execute o script de teste para confirmar que o ambiente está correto:
python test.py
Funções principais
1. posicionamento de tempo de vídeo de formato longo
- Preparar o vídeo: Coloque o arquivo de vídeo na pasta
data/videosCatálogo, compatível com MP4, AVI e outros formatos. - Executar comando::
python run_grounding.py --video_path data/videos/sample.mp4 --query "找到讨论AI的部分"
- Saída de resultadosIntervalo de tempo: Retorna o intervalo de tempo, por exemplo, "00:05:12 - 00:07:34".
2. questionário em vídeo
- Problemas de entrada: Novo
query.txtEscreva perguntas, como "Quem é o personagem principal do vídeo?" . - executar um comando::
python run_qa.py --video_path data/videos/sample.mp4 --query_file query.txt
- Obter respostasO terminal exibe resultados como "O personagem principal é Li Ming".
3. geração de resumo de vídeo
- Executar comando::
python run_summary.py --video_path data/videos/sample.mp4
- Ver ResumoOs resultados são salvos como
summary.txtPor exemplo, "O vídeo apresenta uma palestra sobre ciência e tecnologia".
Operação da função em destaque
Tecnologia Chain-of-LoRA
- O VideoMind usa um único modelo para alternar funções por meio de adaptadores LoRA. Os arquivos de configuração estão disponíveis no diretório
config/lora.yamlAjustávelrankEfeito de aumento do parâmetro:
lora:
rank: 16
Demonstração on-line
- Não há necessidade de instalação local, portanto, você pode visitar https://huggingface.co/spaces/yeliudev/VideoMind-2B, carregar um vídeo e inserir sua pergunta para experimentar a funcionalidade diretamente. Para obter mais informações, consulte
docs/DEMO.md.
Modelos de treinamento
- Preparar dados: Uso
VideoMind-SFTou 27 outros conjuntos de dados, colocados nodataCatálogo. - treinamento de preparação: Executar:
python train.py --dataset data/VideoMind-SFT --model models/VideoMind-2B
- Monitorar o treinamentoSuporte para Tensorboard ou Wandb para visualizar o progresso, consulte a configuração para obter detalhes
docs/TRAIN.md.
advertência
- Quando o arquivo de vídeo é muito grande, recomenda-se processá-lo em segmentos para evitar o estouro de memória.
- Os usuários da Ascend NPU precisam instalar o driver Ascend e adicionar parâmetros durante a execução.
--device ascend. - Para obter mais informações sobre comissionamento, consulte
docs/EVAL.mdincluindo diretrizes de benchmarking.
Com essas etapas, os usuários podem instalar e usar rapidamente o VideoMind para lidar com tarefas de vídeo longas.
cenário do aplicativo
- Análise de conteúdo de vídeo
Os usuários podem usar o VideoMind para analisar vídeos longos do YouTube, localizar clipes importantes ou gerar resumos para economizar tempo de visualização. - Educação e pesquisa
Os alunos ou pesquisadores que trabalham com vídeos de palestras podem perguntar "Quais algoritmos foram abordados?" e obter as respostas, organizando as anotações com mais eficiência. - Auditoria de conteúdo
Os administradores da plataforma o utilizam para verificar se o conteúdo de vídeo está em conformidade, como, por exemplo, verificar se há clipes ofensivos.
QA
- Qual é o tamanho do vídeo que o VideoMind pode suportar?
Dependendo do hardware, 16 GB de RAM podem suportar uma hora de vídeo, e 32 GB suportam conteúdo mais longo. - Qual é a diferença entre uma demonstração on-line e uma implantação local?
A versão on-line não requer instalação, mas tem funcionalidade limitada; a versão local oferece suporte a treinamento personalizado e processamento em larga escala. - Como os conjuntos de dados são usados?
Foram usados 27 conjuntos de dados para treinamento e avaliação, e o VideoMind-SFT foi adequado para otimizar os modelos, conforme descrito em https://huggingface.co/datasets/yeliudev/VideoMind-Dataset.