

Com o rápido desenvolvimento dos recursos de modelagem de linguagem em larga escala (LLM), os benchmarks tradicionais, como o MMLUAs limitações na distinção entre os melhores modelos estão gradualmente se tornando aparentes. Não é mais possível confiar apenas em questionários de conhecimento ou testes padronizados para medir de forma abrangente as competências sutis que são essenciais para os modelos nas interações do mundo real, como inteligência emocional, criatividade, julgamento e habilidades de comunicação. É nesse contexto que uma série de programas de pesquisa denominados EQ-Bench Uma nova estrutura de avaliação surgiu com o objetivo de investigar mais profundamente o desempenho do LLM nessas dimensões complexas.
EQ-Bench e seu conjunto de testes associado oferecem uma perspectiva diversificada que não se limita mais a simples julgamentos de certo e errado, mas se concentra na qualidade do comportamento do modelo e na tomada de decisões em cenários simulados da vida real.
DeepSeek existirHá muitas ilusões nas revisões de recuperação de conhecimentoNo entanto, pode-se dizer que o aspecto criativo da escrita da consideração da relação custo-benefício prejudica a lista, o que não é surpreendente, e muitas pessoas realmente usam a experiência, que também é basicamente a mesma.
Canais e requisitos de envio
Atualmente, o programa só aceita inscrições que podem ser enviadas por meio do site HuggingFace Modelos de ponderação abertos disponíveis publicamente para menção e teste. Os remetentes serão solicitados a fornecer um link para o modelo, o formato ideal de sinalização e a configuração de geração, além de seus próprios resultados de teste por e-mail ou pelo Twitter. EQ-Bench Pontuações. O projeto validará os resultados e atualizará a tabela de classificação. Como o projeto é autofinanciado e tem recursos de computação limitados, os remetentes precisam entender que o processo de validação pode levar algum tempo.
EQ-Bench 3: Avaliação da capacidade de mediação de conflitos
EQ-Bench 3 é um teste de referência de inteligência emocional que se concentra em habilidades proativas de mediação de conflitos. Ele avalia a capacidade dos modelos de linguagem de lidar com questões emocionais complexas em cenários desafiadores e diversos. O teste não se parece mais com o teste inicial EQ-Bench Dessa forma, ele apenas prevê estados emocionais, mas examina diretamente a capacidade do modelo de aplicar a inteligência emocional ativa.
Métodos de teste.
- Estrutura. O teste consiste em várias rodadas de diálogo (até 21 rodadas) entre o modelo em teste, que atua como mediador de conflitos, e um modelo "ator" (atualmente em uso) que desempenha o papel de um cliente ou disputante.
gemini-2.0-flash-001) para interagir. Cada cena contém uma caracterização detalhada com estados emocionais e cenários específicos. - Critérios de avaliação. A base para a pontuação inclui:
- Habilidades básicas de inteligência emocional (reconhecimento de emoções, expressão de empatia)
- Habilidades profissionais relacionadas à terapia ou mediação
- Evitar erros profissionais graves
- Mecanismos operacionais. O benchmarking usa três modelos: o modelo em teste, o modelo do ator e o modelo do árbitro (
Claude-3.7-Sonnet). O modelo de árbitro é responsável por pontuar o desempenho do modelo em teste. - Classificação. A pontuação final combina classificações em várias áreas de habilidades, bem como uma contagem de erros identificados e sua gravidade. O modelo do árbitro também fornecerá uma análise crítica de erros específicos, classificando-os como leves, moderados ou graves, identificando assim com precisão as deficiências do modelo em um diálogo profissional real.
O problema de autopreferência na modelagem de árbitros.
Uma preocupação comum é que os juízes do LLM possam ser tendenciosos, favorecendo particularmente o resultado de seus próprios modelos. Para explorar esse fenômeno, oEQ-Bench 3 fazer uso de Claude-3.7-Sonnet responder cantando gpt-4o-2024-11-20 Dois modelos de árbitros avaliaram o modelo superior.

Os resultados mostram que, pelo menos entre os dois modelos de árbitros, não foi observada nenhuma autopreferência clara e suas pontuações foram quase idênticas. Isso proporciona alguma confiança no uso do LLM como árbitro, mas ainda é preciso ter em mente a possibilidade de possíveis vieses.
Espera-se que o código relevante e a documentação completa estejam disponíveis em breve em EQ-Bench Liberação de armazém.
💗 EQ-Bench (Legacy): Benchmarks de reconhecimento de emoções
geração inicial EQ-Bench Ele foi projetado para avaliar a inteligência emocional dos modelos de linguagem, que é uma parte essencial da experiência do usuário e não foi testada explicitamente por outros benchmarks. Sua vantagem exclusiva é que é relativamente difícil "melhorar" as pontuações por meio do ajuste fino, o que torna a tabela de classificação mais reflexiva dos verdadeiros recursos do modelo.
O teste é formatado de tal forma que o modelo é solicitado a ler o diálogo e avaliar a força das possíveis reações emocionais de um dos personagens (para 4 emoções predefinidas). O processo de avaliação não exige a intervenção de um modelo árbitro, é de baixo custo (apenas 171 perguntas) e os resultados são consistentes com as preferências humanas (Arena ELO) e benchmarks de vários domínios (MMLU) apresentaram uma forte correlação.
MAGI-Hard: um subconjunto de testes discriminatórios de alta dificuldade
Considerando que os benchmarks de LLM existentes apresentam desempenho saturado e dificuldade em distinguir entre os principais modelos.MAGI-Hard foi apresentado. É um exemplo de um exemplo do MMLU responder cantando AGIEval Um subconjunto cuidadosamente selecionado desses modelos tem o objetivo de aprimorar a diferenciação dos modelos de alta capacidade. Os desenvolvedores podem aproveitar as vantagens do EleutherAI lm-evaluation-harness Ramo a ser executado MAGI Conjuntos de teste.
Creative Writing v3: Avaliação atualizada de redação criativa
O Creative Writing Benchmark recebeu uma versão v3, com atualizações importantes que incluem:
- Nova dica. O objetivo é diferenciar melhor e verificar se há um "senso de atmosfera".
- Sistema de pontuação híbrido. Combina o Rubric e o
Elosistema de pontuação que melhora significativamente a discriminação do modelo superior e o alcance dinâmico do teste. - Aprimoramento da página de saída de amostra.
Processo de benchmarking.
- O modelo foi executado para 3 iterações (96 itens no total) usando 32 prompts de escrita com a temperatura definida como 0,7 e min_p como 0,1.
- fazer uso de
Claude 3.7 SonnetComo árbitro, marque o resultado de acordo com as regras de pontuação abrangentes. - Modelo de inferência inicial baseado em pontuações de regras
EloClassificação. - São realizadas comparações entre pares com modelos vizinhos na tabela de classificação (amostragem esparsa), com o vencedor recebendo até 5 "+" com base em pontuações de vários critérios.
- fazer uso de
GlickoSistema de pontuação (modificado para levar em conta a margem de vitória do número de "+") CálculosElopontuações, alternando até que as classificações se estabilizem. - Foram feitas comparações abrangentes com os modelos vizinhos finalizados para calcular a tabela final da liga
Elo.
Regras de pontuação Pontuação vs. Pontuação Elo.
Dois tipos de pontuação coexistem. A pontuação de regras é o resultado da avaliação independente de um árbitro sobre os resultados de modelos individuais;Elo A pontuação, por outro lado, é uma classificação relativa produzida pelo confronto direto de dois a dois entre os modelos. A diferença entre os dois decorre da forma como são avaliados: as comparações entre pares facilitam a identificação de nuances pelos juízes, mas também podem introduzir diferentes vieses. Os critérios de pontuação também diferem entre os dois modelos.
Padronização das pontuações.
Para neutralizar Elo A adição de novos modelos ao sistema causou um problema com o desvio da pontuação geral, e as tabelas de classificação serão DeepSeek-R1 com uma pontuação ancorada em 1.500.ministral-3b Ancorado em 200.
Filosofia de Benchmarking.
É muito difícil julgar a escrita criativa de forma confiável e de acordo com as preferências humanas. A versão v3 torna mais difícil julgar a escrita criativa ao introduzir comparações entre pares e Elo Sistema de classificação para melhorar a diferenciação. As palavras de estímulo são cuidadosamente selecionadas para desafiar os pontos fracos do modelo, criando assim um gradiente de avaliação mais acentuado para os juízes. O teste contém aspectos de humor, romance, consciência espacial, perspectivas não tradicionais em primeira pessoa e outros aspectos que os LLMs normalmente têm dificuldade de alcançar em nível humano.
Mitigação de custos e vieses.
Apesar do sistema de pontuação híbrido, ainda há um custo de API de cerca de US$ 10 para executar uma avaliação. As comparações entre pares introduziram novos desafios de viés que a equipe do projeto tentou atenuar:
- Comprimento do viés. Controlado pelo truncamento da saída para 4000 caracteres.
- Viés posicional. A mitigação é obtida pela avaliação e cálculo da média dos valores em ambas as direções.
- Viés de redundância complexa. A escala de pontuação inclui penalidades para vocabulário excessivamente vistoso.
- Viés de obscuridade poética: o O esquema de avaliação tenta penalizar a prosa excessivamente poética e desconexa.
Viés não controlado.
- Preconceito próprio. Árbitros sem controle podem favorecer seus próprios resultados.
- Viés positivo. A direção e o impacto ainda não estão claros.
- Preconceito de Smut. Os árbitros tendem a penalizar severamente o conteúdo que se inclina para o erótico.
- Viés de estilo e conteúdo: o As preferências dos árbitros podem ser diferentes das preferências dos usuários ou dos humanos em geral.
- Preconceito de Slop. Os árbitros podem favorecer certos tipos ou estilos comumente usados pelo LLM.
Critérios básicos para solicitações de julgamento em pares. Autenticidade do personagem, diversão e originalidade, qualidade da escrita, coerência, quão bem as instruções são seguidas, construção do mundo e da atmosfera, evitar clichês, evitar redundância florida, evitar metáforas excessivas.
Limitações.
Os resultados da avaliação são apenas uma indicação aproximada da capacidade de redação. A redação criativa é altamente subjetiva e recomenda-se que você faça seu próprio julgamento em conjunto com a leitura de exemplos de resultados. Esta referência não é uma avaliação de interpretação de papéis (RP), não testa várias rodadas de diálogo e limita-se apenas à redação em inglês.
Creative Writing (Legacy v2): antiga avaliação de redação criativa
Uso mais antigo (v2) Claude 3.5 Sonnet atua como árbitro, avaliando a capacidade do modelo de escrever em uma série de solicitações. Ele introduz as métricas "Vocab Complexity" e "GPT-Slop" e permite que o usuário ajuste os pesos de penalidade para ambas por meio de um controle deslizante. Essa versão avalia 24 prompts usando regras de pontuação e resultados de referência, executando 10 iterações para melhorar a estabilidade. Da mesma forma, ela tenta atenuar o viés de comprimento por meio dos critérios de pontuação e do controle deslizante de comprimento, mas reconhece que ainda pode haver viés.
⚖️ Judgemark V2: Avaliação da capacidade de modelagem de julgamento
Judgemark V2 O que está sendo avaliado é a capacidade dos modelos de linguagem de atuarem como "juízes" por direito próprio, ou seja, eles estão avaliando a redação criativa de acordo com regras detalhadas. pontuação numérica A capacidade de fazer isso. Esse teste é mais complexo do que um simples teste de preferência emparelhada, exigindo que o modelo do árbitro compreenda instruções complexas, analise o texto e pontue até 36 dimensões de qualidade literária.
Principais aprimoramentos na versão V2.
- Um aumento de 6 vezes no tamanho da amostra reduz a variação de execução.
- Métricas de pontuação refinadas: medidas de discriminação (distinção entre textos fortes e fracos), estabilidade (consistência na classificação entre execuções) e relevância para as preferências humanas.
- Estão disponíveis pontuações brutas e calibradas: a última as torna mais comparáveis entre os juízes ao padronizar a distribuição.
- Um teste de estabilidade de perturbação (temp=0,5, top_k=3) foi introduzido para avaliar a robustez dos resultados.
- Base de código autônoma simplificada.
Testes de repetibilidade. direito Llama-3.1-70B-instruct Foram realizados 20 testes, mostrando que o desvio padrão da pontuação final foi de aproximadamente 1,0, indicando certa estabilidade nos resultados.
Tarefas de julgamento. O modelo de adjudicador lê peças criativas curtas geradas por 17 níveis diferentes de "modelos de escritores" e emite pontuações numéricas com base em prompts longos que contêm critérios positivos e negativos (por exemplo, "caráter detalhado: 0-10", "pretensioso: 0-10", sendo que quanto mais baixo, melhor). 10", sendo que, neste último caso, quanto menor, melhor). Final Judgemark A pontuação é baseada na soma ponderada de várias métricas calculadas, como discriminação, estabilidade e relevância para as preferências humanas.
Essa é uma tarefa extremamente desafiadora para o LLM, pois requer habilidades meticulosas de crítica literária e a capacidade de seguir instruções de pontuação numérica multidimensional.
🎤 BuzzBench: uma referência para análise de humor
BuzzBench Analisando os programas de perguntas e respostas sobre música britânica Never Mind The Buzzcocks A capacidade do LLM de entender o humor foi avaliada por meio da apresentação de piadas aos convidados do programa. A tarefa exigia não apenas a explicação da mecânica da piada, mas também a previsão de quão "engraçada" a piada seria para o público e para o autor da comédia.
Projetos desafiadores.
- A seleção de piadas do programa aumentou a dificuldade de identificar o LLM devido à variedade de estilos (sutil, aventureiro, grosseiro, obscuro, óbvio, inteligente).
- O requisito de prever "níveis de diversão" envolve a modelagem de respostas humanas.
- Use "respostas de ouro" escritas por humanos como referência para as pontuações dos juízes.
O parâmetro de comparação foi projetado para testar a compreensão mental teórica e o conhecimento complexo da mecânica de como as piadas funcionam. O modelo de árbitro foi escolhido Claude 3.5 SonnetPorque está no Judgemark Os árbitros de cada país tiveram pontuação alta e pareceram ter menos preferência por respostas longas e excessivamente analisadas. Mais uma vez, é preciso prestar atenção às preferências pessoais subjacentes dos árbitros.
🌍 DiploBench: uma estrutura para avaliar negociações estratégicas (experimental)
DiploBench É um jogo de tabuleiro que usa estratégia Diplomacy Uma estrutura experimental para avaliar as capacidades de negociação estratégica do LLM. O modelo em teste desempenha Austria-Hungary (Áustria-Hungria), uma função desafiadora que exige habilidades superiores de negociação e planejamento estratégico. Os modelos precisam se comunicar com outros jogadores de IA, fazer alianças, reconhecer enganos e tomar decisões táticas.
Principais recursos.
- Impressão completa. Várias rodadas de negociações antes da operação.
- Ambientes corporais multiinteligentes. Cada país é controlado por um LLM independente.
- Simulação diplomática realista. Teste as habilidades de alinhamento, negociação e reconhecimento de fraude.
- Abertura desafiadora.
Austria-HungarySua localização central a torna vulnerável, mas estratégica.
O jogo é executado em até 50 rodadas, com 4 rodadas de negociação antes de cada rodada de ação. A estrutura testa de forma exclusiva as capacidades do LLM em planejamento estratégico de longo prazo, negociação com várias inteligências, atenção teórica e detecção de fraude.
Observação: Devido à grande variação nos resultados da execução do jogo, oDiploBench Ainda é uma estrutura experimental e os resultados devem ser interpretados com cautela.
Considerações finais
EQ-Bench A série de referências de LLM fornece um conjunto valioso de ferramentas que levam a avaliação de LLM além das métricas tradicionais para dimensões complexas de competência que respondem melhor às necessidades da interação humana. Embora desafios como o viés do árbitro e a subjetividade da avaliação permaneçam, o design e a iteração desses benchmarks (por exemplo, melhorias na v2, v3, discussão explícita do viés e tentativas de atenuá-lo) representam uma etapa importante na evolução do campo da avaliação de LLM para um nível mais profundo e diferenciado. Para os desenvolvedores e pesquisadores, essas ferramentas não só fornecem um parâmetro para medir o progresso do modelo, mas também apontam na direção dos principais aprimoramentos futuros dos recursos do modelo: inteligência emocional, criatividade, julgamento e comunicação eficaz em interações sociais complexas.
Classificação do EQ-Bench 3
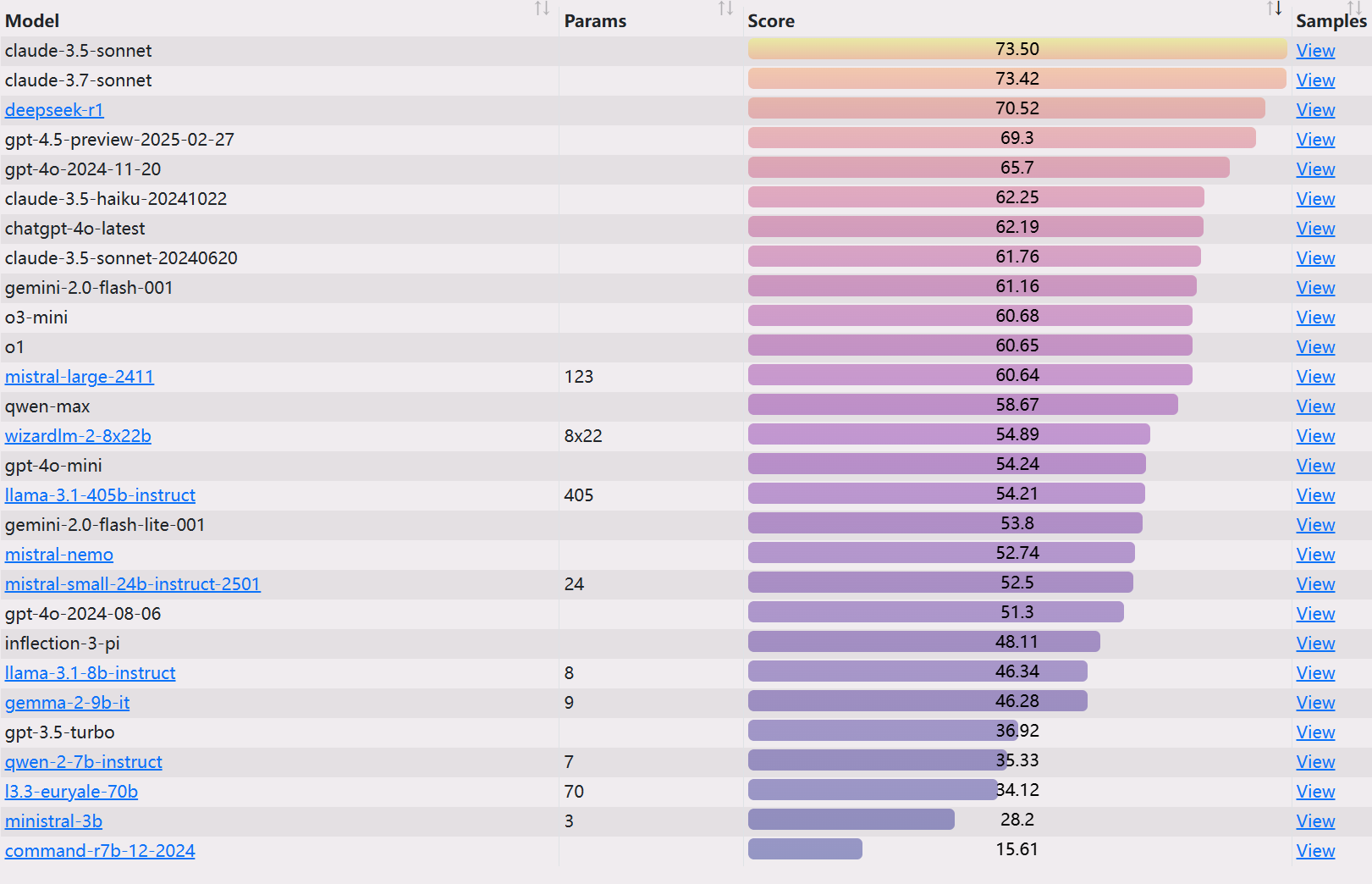
https://eqbench.com/















