

Os modelos de linguagem grande (LLMs) estão evoluindo rapidamente, e sua capacidade de raciocínio tornou-se um indicador importante do seu nível de inteligência. Em particular, modelos com recursos de raciocínio longos, como o OpenAI's o1eDeepSeek-R1eQwQ-32B responder cantando Kimi K1.5 Esses modelos têm atraído muita atenção por sua capacidade de resolver problemas complexos simulando processos profundos de pensamento humano. Essa capacidade geralmente envolve uma técnica chamada Inference-Time Scaling, que permite que o modelo passe mais tempo explorando e corrigindo à medida que gera respostas.
No entanto, uma análise mais profunda revela que esses modelos geralmente caem em dois extremos em seu raciocínio:Pensando mal responder cantando Pensando demais.
não há alimento suficiente para reflexão Isso se refere à troca frequente de ideias no raciocínio do modelo, o que dificulta o foco em uma direção promissora para uma investigação mais profunda. O resultado do modelo pode estar repleto de palavras como "alternativamente", "mas espere", "deixe-me reconsiderar" etc., conforme mostrado na figura abaixo, levando a respostas finais incorretas. conforme mostrado na figura abaixo, levando a respostas finais incorretas. Esse fenômeno pode ser comparado à desatenção humana, que afeta a validade do raciocínio.

pensar demais Em vez disso, o modelo gera "cadeias de pensamento" longas e desnecessárias em problemas simples. Por exemplo, para um problema aritmético básico como "2+3=?" Por exemplo, para um problema aritmético básico como "2+3=?", alguns modelos podem levar centenas ou até milhares de horas de trabalho. token para verificar ou explorar iterativamente várias soluções, conforme mostrado abaixo. Embora os processos de pensamento complexos sejam benéficos para problemas difíceis, em cenários simples isso certamente resulta em um desperdício de recursos computacionais.
Juntas, essas duas perguntas apontam para um desafio central: como melhorar a eficiência do raciocínio do modelo e, ao mesmo tempo, manter a qualidade das respostas? Um modelo ideal deve ser capaz de encontrar e dar a resposta correta no menor tempo possível.
Para enfrentar esse desafio.EvalScope O projeto apresenta EvalThink com o objetivo de fornecer uma ferramenta padronizada para avaliar a eficiência de raciocínio de um modelo. Neste documento, usaremos o MATH-500 Por exemplo, a análise do conjunto de dados inclui DeepSeek-R1-Distill-Qwen-7B O desempenho de uma série de modelos de raciocínio, incluindo aqueles que se concentram em seis dimensões: raciocínio de modelo token Número, primeira vez certo token Número, reflexões restantes token Números,token Eficiência, número de cadeias de sub-pensamento e precisão.
Metodologia e processo de avaliação
O processo de avaliação consiste em dois estágios principais: avaliação do raciocínio do modelo e avaliação da eficiência do raciocínio do modelo.
Avaliação do raciocínio do modelo
O objetivo dessa fase é obter o modelo em MATH-500 Resultados brutos de inferência e precisão básica no conjunto de dados.MATH-500 O conjunto de dados contém 500 problemas de matemática de dificuldade variável (do Nível 1 ao Nível 5).
Preparação do ambiente de avaliação
A avaliação pode ser realizada acessando um serviço de raciocínio compatível com a API da OpenAI.EvalScope A estrutura também oferece suporte ao uso de transformers A biblioteca é revisada localmente. Para aqueles que precisam lidar com longas cadeias de pensamento (possivelmente mais de 10.000 token) do modelo de inferência usando vLLM talvez ollama Estruturas de inferência eficientes, como essas, implantam modelos que podem acelerar significativamente o processo de avaliação.
para DeepSeek-R1-Distill-Qwen-7B Como exemplo, use o vLLM O comando de exemplo para implantar o serviço é o seguinte:
VLLM_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --served-model-name DeepSeek-R1-Distill-Qwen-7B --trust_remote_code --port 8801
Revisão do raciocínio executivo
aprovar (um projeto de lei ou inspeção etc.) EvalScope (usado em uma expressão nominal) TaskConfig Configure o endereço da API do modelo, o nome, o conjunto de dados, o tamanho do lote e os parâmetros de geração e, em seguida, execute a tarefa de avaliação. A seguir, um exemplo de código Python:
from evalscope import TaskConfig, run_task
task_config = TaskConfig(
api_url='http://0.0.0.0:8801/v1/chat/completions', # 推理服务地址
model='DeepSeek-R1-Distill-Qwen-7B', # 模型名称 (需与部署时一致)
eval_type='service', # 评测类型:服务
datasets=['math_500'], # 数据集
dataset_args={'math_500': {'few_shot_num': 0, 'subset_list': ['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5']}}, # 数据集参数,包含难度级别
eval_batch_size=32, # 并发请求数
generation_config={
'max_tokens': 20000, # 最大生成 token 数,设置较大值防截断
'temperature': 0.6, # 采样温度
'top_p': 0.95, # top-p 采样
'n': 1, # 每个请求生成一个回复
},
)
run_task(task_config)
Quando a avaliação for concluída, o modelo será exportado em MATH-500 Precisão em cada nível de dificuldade (AveragePass@1):
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|-----------------------------|-----------|---------------|----------|-----|--------|---------|
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 1 | 43 | 0.9535 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 2 | 90 | 0.9667 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 3 | 105 | 0.9587 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 4 | 128 | 0.9115 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 5 | 134 | 0.8557 | default |
Avaliação da eficiência do Model Thinking
Após obter a inferênciaEvalThink Intervenções de componentes para análises de eficiência mais aprofundadas. As principais métricas de avaliação incluem:
- raciocínio modelado
token(Tokens de raciocínio)Cadeias de raciocínio durante a geração de respostas do modelo (como no modelo O1/R1)</think>(o que precede o sinalizador) contido notokenValor total. - certo na primeira vez
tokenNúmero (primeiros tokens corretos)Desde o início da saída do modelo até a primeira ocorrência de um local de resposta correta identificáveltokenQuantidade. - Reflexões remanescentes
tokenTokens de reflexão:: Da primeira posição de resposta correta até o final da cadeia de raciocíniotokenQuantidade. Isso reflete parcialmente o custo de continuar a validação ou a exploração depois que o modelo encontrou uma resposta. - Pensamento numérico:: Ao contar significantes específicos (por exemplo
alternatively,but wait,let me reconsider) para estimar a frequência com que o modelo troca de ideias. tokenEficiência do token:: Medição do pensamento eficaztokenIndicador de porcentagem, calculado como a primeira vez corretatokenNúmero e raciocínio geraltokenA média da proporção do número de (somente amostras com respostas corretas foram contadas):
Eficiência do token = 1⁄N ∑ Primeiro Correto Tokensi⁄Tokensi de raciocínio
em que N é o número de perguntas respondidas corretamente. Quanto maior o valor, mais "eficiente" é o raciocínio do modelo.
Para fins de determinação do "direito de primeira vez token número", uma estrutura de avaliação que se baseia no ProcessBench A ideia é usar um modelo de juiz separado, por exemplo Qwen2.5-72B-Instructpara verificar as etapas de inferência e localizar a posição em que a resposta correta ocorre mais cedo. A implementação envolve a decomposição da saída do modelo em etapas (estratégia opcional: por separador específico) separatorPalavras-chave de imprensa keywordsou reescrito e fatiado com o auxílio do LLM llm) e, em seguida, deixar que o modelo do árbitro julgue cada uma delas.
Código de amostra para realizar uma avaliação de eficiência do think:
from evalscope.third_party.thinkbench import run_task
# 配置裁判模型服务
judge_config = dict(
api_key='EMPTY',
base_url='http://0.0.0.0:8801/v1', # 假设裁判模型也部署在此服务
model_name='Qwen2.5-72B-Instruct',
)
# 配置待评估模型的信息
model_config = dict(
report_path='./outputs/2025xxxx', # 上一步推理结果路径
model_name='DeepSeek-R1-Distill-Qwen-7B', # 模型名称
tokenizer_path='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', # Tokenizer 路径,用于计算 token
dataset_name='math_500', # 数据集名称
subsets=['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5'], # 数据集子集
split_strategies='separator', # 推理步骤分割策略
judge_config=judge_config
)
max_tokens = 20000 # 过滤 token 过长的输出
count = 200 # 每个子集抽样数量,加速评测
# 运行思考效率评估
run_task(model_config, output_dir='outputs', max_tokens=max_tokens, count=count)
Os resultados da avaliação detalharão as seis métricas dimensionais do modelo em cada nível de dificuldade.
Análise e discussão dos resultados
A equipe de pesquisa usou EvalThink direito DeepSeek-R1-Distill-Qwen-7B e vários outros modelos (QwQ-32BeQwQ-32B-PrevieweDeepSeek-R1eDeepSeek-R1-Distill-Qwen-32B) foi avaliado e um modelo matemático especializado não inferencial foi adicionado Qwen2.5-Math-7B-Instruct Como comparação.
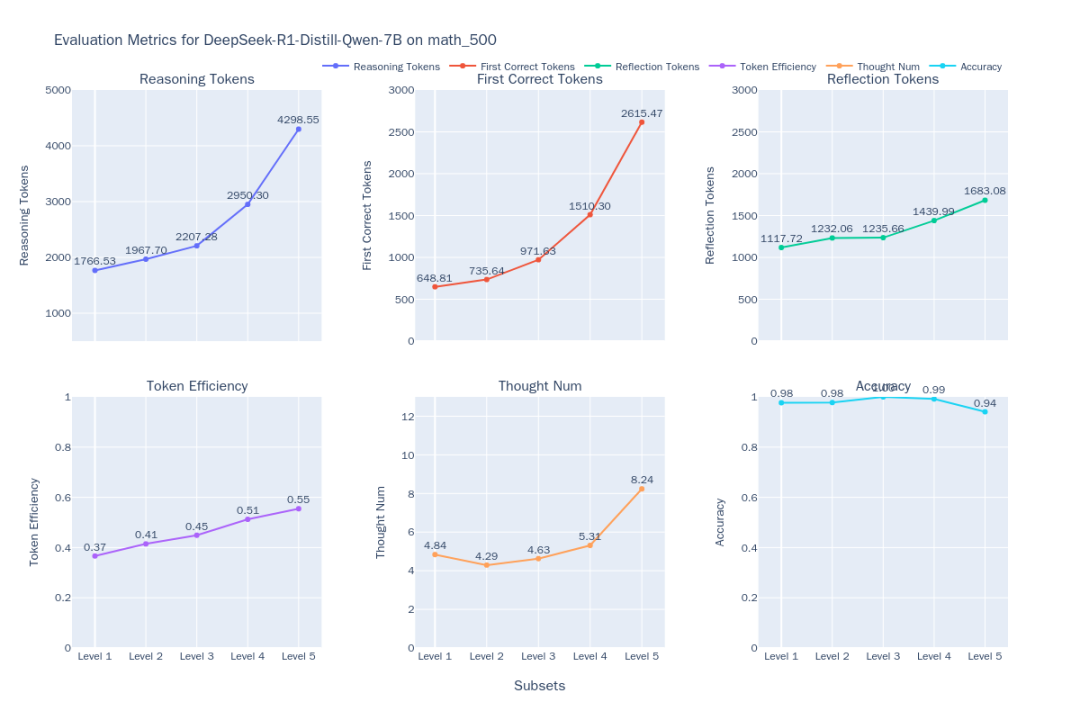
Figura 1: Indicador de eficiência de pensamento DeepSeek-R1-Distill-Qwen-7B
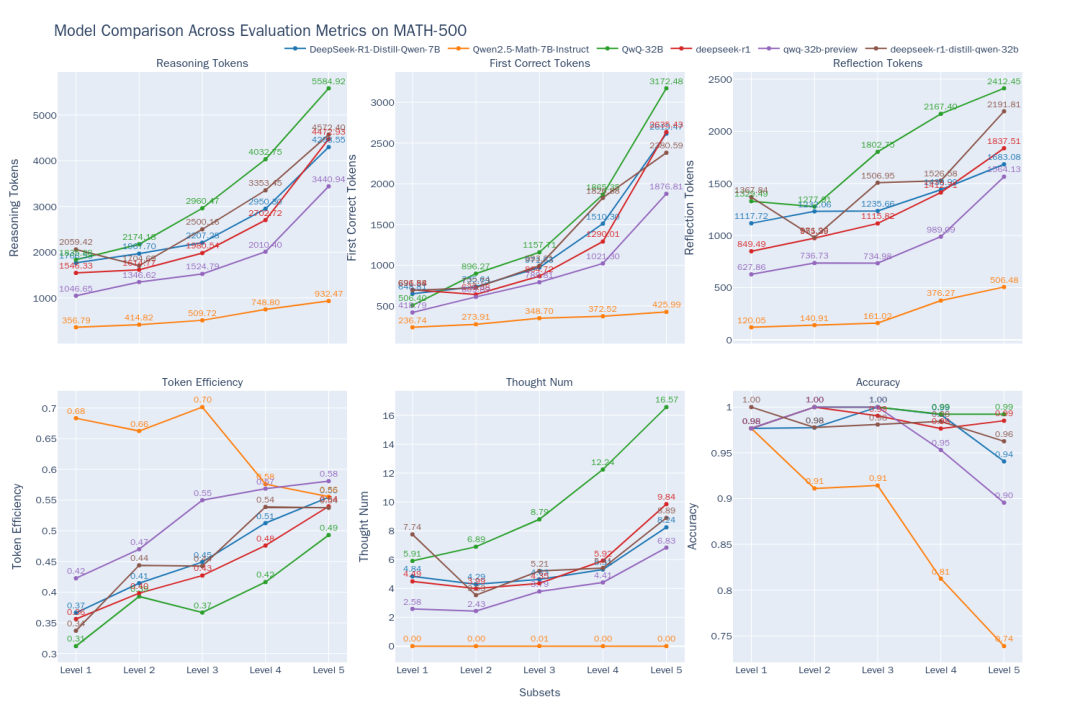
Figura 2: Comparação da eficiência de raciocínio dos 6 modelos em diferentes níveis de dificuldade do MATH-500
As seguintes tendências podem ser observadas nos resultados da comparação (Figura 2):
- Correlação entre dificuldade e desempenho: À medida que a dificuldade do problema (do Nível 1 ao Nível 5) aumenta, a precisão da maioria dos modelos diminui. No entanto.
QwQ-32Bresponder cantandoDeepSeek-R1destacando-se em problemas difíceis.QwQ-32Bmaior precisão no Nível 5. Ao mesmo tempo, o resultado de todos os modelostokenTodos os números ficam mais longos à medida que a dificuldade aumenta, o que está de acordo com a expectativa de "raciocinar enquanto expande" - o modelo precisa "pensar" mais para resolver o quebra-cabeça. - Propriedades do modelo de raciocínio de classe O1/R1:
- Ganhos de eficiência:: É interessante notar que, para
DeepSeek-R1responder cantandoQwQ-32BEsse tipo de modelo de inferência, embora a saída se torne mais longa, otokenEficiência (efetiva)token) também aumenta com a dificuldade (DeepSeek-R1De 36% a 54%.QwQ-32B(de 31% para 49%). Isso sugere que o pensamento extra em problemas difíceis é mais "econômico", enquanto que em problemas simples pode haver um certo excesso de pensamento, por exemplo, iterações desnecessárias.QwQ-32B(usado em uma expressão nominal)tokenO consumo é alto em geral, o que pode ser um dos motivos pelos quais ele consegue manter uma alta taxa de precisão no Nível 5, mas também indica uma tendência a pensar demais nas coisas. - Caminhos do pensamento:
DeepSeekO número de cadeias de sub-pensamento para os modelos em série é relativamente estável nos níveis 1 a 4, mas aumenta drasticamente no nível 5, o mais difícil, sugerindo que o nível 5 representa um desafio significativo para esses modelos e exige várias tentativas. Em contraste.QwQ-32BO modelo em série tem um crescimento mais suave no número de cadeias de pensamento, refletindo diferentes estratégias de enfrentamento.
- Ganhos de eficiência:: É interessante notar que, para
- Limitações dos modelos não inferenciais:: Modelos matemáticos especializados
Qwen2.5-Math-7B-InstructA precisão cai drasticamente ao lidar com problemas difíceis, e sua saídatokenEsse número é muito menor do que o dos modelos de raciocínio (cerca de um terço). Isso sugere que, embora esses modelos possam ser mais rápidos e consumir menos recursos em problemas comuns, a falta de processos de pensamento mais profundos faz com que eles tenham um "teto" de desempenho significativo em tarefas de raciocínio complexas.
Considerações e limitações metodológicas
no aplicativo EvalThink Há vários pontos que devem ser levados em conta ao realizar uma avaliação:
- Definição de indicadores:
- proposto neste documento
tokenOs indicadores de eficiência, baseados nos conceitos de "overthinking" e "underthinking" da literatura, concentram-se principalmente emtokenA quantidade, uma medida simplificada do processo de pensamento, não consegue captar todos os detalhes da qualidade do pensamento. - O cálculo do número de cadeias de sub-pensamento depende de palavras-chave predefinidas, e a lista de palavras-chave pode precisar ser adaptada para diferentes modelos a fim de refletir com precisão seus padrões de pensamento.
- proposto neste documento
- Escopo de aplicação:
- As métricas atuais são validadas principalmente em conjuntos de dados de raciocínio matemático, e sua eficácia em outros cenários, como questionários abertos e geração de ideias, ainda não foi testada.
- bufê
DeepSeek-R1-Distill-Qwen-7Bbaseia-se em um modelo matemático de destilação doMATH-500Pode haver uma vantagem natural no desempenho do conjunto de dados. Os resultados da avaliação precisam ser interpretados no contexto do modelo.
- Dependência do modelo de adjudicação:
tokenO cálculo da eficiência depende do Modelo de Juiz (JM) para julgar com precisão a correção das etapas de raciocínio. ComoProcessBench4Essa é uma tarefa desafiadora para os modelos existentes, conforme observado pelo estudo, e geralmente requer modelos altamente capacitados para a tarefa.- Julgamentos equivocados no modelo de arbitragem podem ter um impacto direto sobre
tokenprecisão dos indicadores de eficiência, portanto, é fundamental escolher o modelo de árbitro correto.
Em poucas palavras.EvalThink É fornecido um conjunto de estruturas e métricas para avaliar quantitativamente a eficiência do raciocínio LLM, revelando o desempenho de diferentes modelos em termos de precisão,token entre consumo e profundidade de pensamento. Essas descobertas são úteis para orientar o treinamento de modelos (por exemplo GRPO e SFT), é informativo desenvolver modelos de última geração que sejam mais eficientes e possam ajustar de forma adaptativa a profundidade do pensamento de acordo com a dificuldade do problema.















