はじめに
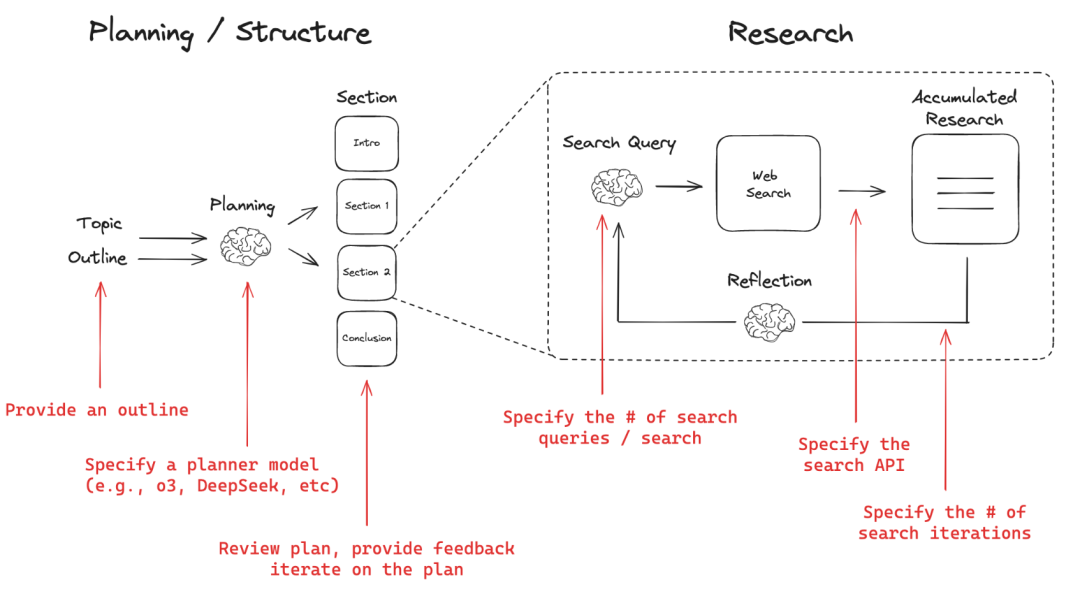
Open Deep Researchは、あらゆるトピックに関する包括的なリサーチレポートを作成するウェブベースのリサーチアシスタントです。このシステムは、時間のかかる調査フェーズに移る前に、ユーザがレポートの構成を計画し、レビューすることを可能にする計画と実行のワークフローを使用しています。ユーザーは、個々のニーズに合わせて、Tavily、Perplexity、Anthropic、OpenAIなどの異なる計画モデル、検索API、およびライティングモデルから選択することができます。Open Deep Researchは、レポートの深さと正確さを確保するために、考察と検索を複数回繰り返すことをサポートします。ユーザーは、簡単な設定ファイルとコマンドライン操作によって、ツールを迅速に導入して使用することができます。
機能一覧
- 報告書の構成の概要を説明する。
- 計画モデルの設定(DeepSeek、OpenAIの推論モデルなど)
- レポートの各セクションのプランにフィードバックし、ユーザーが満足するまで反復する。
- 検索API(例:Tavily、Perplexity)と研究反復あたりの検索回数の設定
- 各セクションの検索深度(反復回数)の設定
- カスタムライティングモデル(例:Anthropic)
- LangGraph Studio UIをローカルで実行する
- 構造化された調査レポートの自動生成
- レポートの品質を向上させるために、複数の検索と反射的な反復をサポートする。
ヘルプの使用
クイックスタート
- 必要なツールのAPIキーが設定されていることを確認する。
- ウェブ検索ツールを選択します(デフォルトではTavilyが使用されています):
- タビリーAPI
- 当惑 API
- ライティングモデルを選択する(デフォルトではAnthropicが使用される) クロード 3.5ソネット):
- プランニングモデルを選択します(デフォルトではOpenAI o3-miniが使用されています):
- オープンAI
- グロック
使用方法
仮想化環境
- 仮想環境を作る:
复制复制复制复制复制复制复制复制复制复制复制复制复制复制复制复制
python -m venv open_deep_research source open_deep_research/bin/activate
复制复制复制复制复制复制复制复制复制复制复制复制复制复制
复制
- インストール:
复制复制复制复制复制复制复制复制复制复制复制复制复制复制
pip install open-deep-research
Jupyterノートブックを使う
- チャートをインポートしてコンパイルする:
复制复制复制复制复制复制复制复制复制复制复制复制复制
from langgraph.checkpoint.memory import MemorySaver from open_deep_research.graph import builder memory = MemorySaver() graph = builder.compile(checkpointer=memory) - チャートを見る
复制复制复制复制复制复制复制复制复制复制复制复制
from IPython.display import Image, display display(Image(graph.get_graph(xray=1).draw_mermaid_png())) - チャートを実行する:
复制复制复制复制复制复制复制复制复制复制复制
import uuid thread = {"configurable": {"thread_id": str(uuid.uuid4()), "search_api": "tavily", "planner_provider": "openai", "planner_model": "o3-mini", "writer_provider": "anthropic", "writer_model": "claude-3-5-sonnet-latest", "max_search_depth": 1, }} topic = "Overview of the AI inference market with focus on Fireworks, Together.ai, Groq" async for event in graph.astream({"topic":topic,}, thread, stream_mode="updates"): print(event) print("\n") - レポートプランを作成した後、レポートを更新するためにフィードバックを提出する:
复制复制复制复制复制复制复制复制复制复制
from langgraph.types import Command async for event in graph.astream(Command(resume="Include a revenue estimate (ARR) in the sections"), thread, stream_mode="updates"): print(event) print("\n") - 報告スキームに満足した場合に提出
Trueを使用してレポートを作成します:复制复制复制复制复制复制复制复制复制async for event in graph.astream(Command(resume=True), thread, stream_mode="updates"): print(event) print("\n")
LangGraph Studio UIをローカルで実行する
- クローン倉庫
复制复制复制复制复制复制复制复制
git clone https://github.com/langchain-ai/open_deep_research.git cd open_deep_research - コンパイラ
.envファイルでAPIキーを設定する:复制复制复制复制复制复制复制cp .env.example .env - 環境変数の設定:
复制复制复制复制复制复制
export TAVILY_API_KEY=<your_tavily_api_key> export ANTHROPIC_API_KEY=<your_anthropic_api_key> export OPENAI_API_KEY=<your_openai_api_key> - LangGraphサーバーを起動する:
- マックだ:
复制复制复制复制复制
curl -LsSf https://astral.sh/uv/install.sh | sh uvx --refresh --from "langgraph-cli[inmem]" --with-editable . --python 3.11 langgraph dev - ウィンドウズ
复制复制复制复制
pip install -e . pip install langgraph-cli[inmem] langgraph dev
- マックだ:
- スタジオUIを開く:
复制复制复制
- 🚀 API: http://127.0.0.1:2024 - 🎨 Studio UI: https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:2024 - 📚 API Docs: http://127.0.0.1:2024/docs
カスタマイズされたレポート
report_structure: : カスタムのレポート構造を定義する (デフォルトでは標準の調査レポート形式が使用されます)number_of_queries:: セクションごとに生成される検索クエリの数 (デフォルト: 2)max_search_depth検索深度の最大値(デフォルト:2)planner_provider:: 計画段階のモデリングプロバイダー(デフォルト:"openai"、オプション:"groq)planner_model:: 計画に使用する特定のモデル(デフォルト:"o3-mini"、オプションで "deepseek-r1-distill-llama-70b")。writer_model:: レポート作成に使用されるモデル(デフォルト:"claude-3-5-sonnet-latest)search_api検索APIを使用(デフォルト:Tavily)