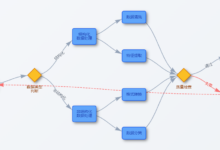
ワークフロー(仕事の流れ):ワークフローの動作原理を読むための記事
ワークフロー:簡単に言えば、「何かを成し遂げるための完全な手順」のこと。 目標に到達するために、誰が、どのような順序で、何をすべきかを示した「取扱説明書」のようなものだ。 インプット:ワークフローを開始する前に、...

ワークフロー:簡単に言えば、「何かを成し遂げるための完全な手順」のこと。 目標に到達するために、誰が、どのような順序で、何をすべきかを示した「取扱説明書」のようなものだ。 インプット:ワークフローを開始する前に、...
この記事は「知的身体AIの理解と展開」シリーズの一部です:知的身体AIシリーズ1:Devinとエージェント・カーソルの比較 知的身体AIシリーズ2:考える人から実行する人へ-知的身体AIのパラダイム革命と技術アーキテクチャ知的身体AIと技術アーキテクチャ 知的身体AIシリーズ3:20ドルを50ドルに...

ビルダーインテリジェントプログラミングモード、DeepSeek-R1とDeepSeek-V3の無制限の使用、海外版よりも滑らかな経験を有効にします。ただ、中国語のコマンドを入力し、プログラミングの知識はまた、独自のアプリケーションを書くためにゼロしきい値をすることはできません。

大規模言語モデル(LLM)アプリケーションを構築する際、メモリシステムは対話のコンテキスト管理、長期的な情報保存、意味理解を強化する重要な技術の一つである。効率的なメモリシステムは、モデルが長い対話の一貫性を維持し、重要な情報を抽出し、さらに過去の対話を検索する機能を持つことができます...

OpenAIの関数呼び出しV2の特徴 関数呼び出しV2の中核的な目標は、OpenAIのモデルに外界と相互作用する能力を与えることです。

基本概念 情報技術の分野では、検索とは、ユーザーの問い合わせや必要性に応じて、大規模なデータセット(通常は文書、ウェブページ、画像、音声、動画、その他の形式の情報)から関連する情報を効率的に探し出し、抽出するプロセスを指す。 その中心的な目的は、使用目的に関連する情報を見つけることである。
![Agent AI: 探索多模态交互的前沿世界[李飞飞-经典必读]-首席AI分享圈](https://www.aisharenet.com/wp-content/uploads/2025/01/6dbf9ac2da09ee1-220x150.png)
Agent AI: Surveying the Horizons of Multimodal Interaction Original published at https://ar5iv.labs.arxiv.org/html/2401.03568 Abstract マルチモーダルAIシステムは、我々の日常生活においてユビキタスになる可能性が高い。このようなシステムをよりインタラクティブなものにする一つの方法として ...

GraphReader:大規模な言語モデルのための長文テキスト処理を強化するグラフベースのインテリジェンス Graphic Expert:マインドマップを作るのが得意な家庭教師のように、長文テキストを明確な知識ネットワークに変換することで、AIが地図に沿って探索するように、答えに必要な各キーポイントを簡単に見つけることができ、効果的に...

CAG(キャッシュ・オーグメンテッド・ジェネレーション)は、RAG(リトリーバル・オーグメンテッド・ジェネレーション)よりも40倍高速です。CAGは、知識獲得に革命をもたらします:リアルタイムで外部データを取得する代わりに、すべての知識がモデル・コンテキストにあらかじめロードされます。CAGは知識獲得に革命をもたらします:外部データをリアルタイムで取得する代わりに、すべての知識がモデル・コンテキストに事前にロードされます。これは、巨大なライブラリを、必要なときにすぐに使えるツールキットに凝縮したようなものです...

ジュリア・ヴィージンガー、パトリック・マーロウ、ウラジミール・ヴスコヴィッチ 著 原文 https://www.kaggle.com/whitepaper-agents 目次 はじめに インテリジェント・ボディとは何か? モデル ツール オーケストレーションレイヤー インテリジェントボディとモデル 認知アーキテクチャ:インテリジェントボディの仕組み ツール ...

検索拡張生成(RAG)は、大規模言語モデル(LLM)とベクターデータベースのための最も人気のあるアプリケーションの1つになりつつある。RAGは、ベクターデータベース(Weaviateなど)から取得したコンテキストでLLMへの入力を拡張するプロセスである。
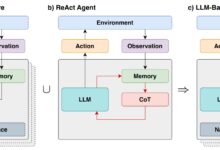
マルチエージェントシステム(MAS)は、相互作用する複数のインテリジェントエージェントから構成されるコンピューティングシステムである。マルチ・エージェント・システムは、単一のインテリジェント・エージェントや単一のシステムでは解決が難しい、あるいは不可能な問題を解決するために使用される。インテリジェント・エージェントは、ロボット、人間、ソフト・・・のいずれでもある。
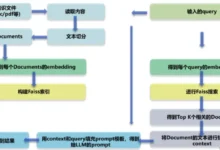
I. LLMはすでに高い能力を持っているのに、なぜRAG(Retrieval Augmented Generation)が必要なのか? 錯覚問題:LLMは統計的な確率論的アプローチを使ってテキストを単語ごとに生成するが、このメカニズムは本質的に...

o3が個人的な洞察をお伝えします。テストタイム・スケーリング法の進展は、私たちが考えていたよりもずっと早かった。しかし、その道筋は実は少し入り組んでいることを提案したい。AGIを追求するOpenAIの国難を救う方法だ。 強化学習と近道思考 ...

ベクトル埋め込みは、現在の検索拡張世代(RAG)アプリケーションの中核をなしている。ベクトル埋め込みは、データオブジェクト(テキスト、画像など)の意味情報をキャプチャし、それらを数値の配列として表現する。現在の生成AIアプリケーションでは、これらのベクトルEmbeddingは通常Embeddingモデルによって生成されます。RAGへの応募方法 ...
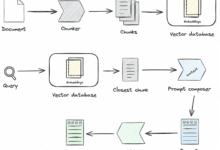
まえがき 過去2年間で、検索拡張生成(RAG、Retrieval-Augmented Generation)技術は徐々に拡張知能の中心的な構成要素となってきた。検索と生成の2つの機能を組み合わせることで、RAGは外部の知識を取り込むことができ、複雑なシナリオにおける大規模なモデルの応用を広げることができる。

エージェント これまで私が目にした最も一般的な訳語は「知的身体」だが、直訳すると「エージェント」だ。 Agenticは何と訳すべきだろうか?私は "agentic "の方が適切だと感じている。 そこで、読者を混乱させないために、本稿では英語をそのまま使うことにする。 LLMの発達に伴い、AIの能力...

AIモデルが特定のシナリオで役立つためには、通常、背景知識を利用する必要がある。例えば、カスタマー・サポート・チャットボットは、それがサービスを提供する特定のビジネスを理解する必要があり、法的分析ボットは、過去の多数のケースにアクセスする必要がある。 開発者はしばしば、検索オーグメンテ...

大規模モデルのファインチューニングの全過程 ファインチューニングの際には、上記のプロセスに厳密に従うことが推奨される。例えば、データセットの構築が十分でなく、最終的にファインチューニングしたモデルの効果の低さがデータセットの質の問題であることが判明した場合、事前の努力は無駄になり、問題...

OlaChat AI デジタル・インテリジェンス・アシスタント 1万字の徹底分析でText-to-SQL技術の過去と現在をお届けします。 論文:次世代データベース・インターフェース:LLMベースのText-to-SQLに関する調査 自然言語の問題から正確なSQLを生成すること(Text-to-SQL)は、長い歴史を持つ...