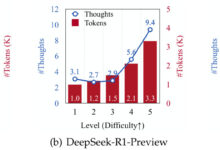
AI知識 3ページ 興味深い論文「Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs」を見つけた。トピックは、o1-like推論モデル、思考経路の頻繁な切り替え、「underthinking」と呼ばれる思考焦点の欠如を分析することである。o1様推論モデルの思考経路の頻繁な切り替えと、「アンダーシンキング」と呼ばれる思考焦点の欠如を分析し、同時にそれを緩和するための解決策を与えることをテーマとしている。
2025-02-13
はじめに AI技術の広大な星空の中で、ディープラーニングモデルはその優れた性能で多くの分野の革新と発展を牽引している。しかし、モデルサイズの継続的な拡大は諸刃の剣のようなものであり、性能を向上させる一方で、演算需要の劇的な増大とストレージの圧迫をもたらす。特にリソースに制約のあるアプリケーションでは ...
2025-02-13
ビルダーインテリジェントプログラミングモード、DeepSeek-R1とDeepSeek-V3の無制限の使用、海外版よりも滑らかな経験を有効にします。ただ、中国語のコマンドを入力し、プログラミングの知識はまた、独自のアプリケーションを書くためにゼロしきい値をすることはできません。
2025-03-26
概要 ラージ・ランゲージ・モデル(LLM)は、その優れた性能にもかかわらず、幻覚を見たり、事実と異なる情報を生成したりしがちである。この課題は、LLMに裏付けとなる証拠を含むコンテンツを生成するよう促す、属性テキスト生成の取り組みを動機づけてきた。本稿では、Think&Citeと呼ばれる新しいアプローチを紹介する。
2025-02-11
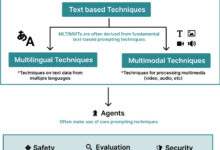
はじめに 本書の目的は、一連のプロンプトの例(一部)を通して、プロンプト・エンジニアリングの中核となる概念と応用を読者が素早く理解し、把握できるようにすることである。これらの例はすべて、プロンプト・エンジニアリング技術の体系的レビューに関する学術論文("The Prompt Report: A Systematic Survey of Pr...
2025-02-10
Titans: Learning to Memorise at Test Time 原文: https://arxiv.org/pdf/2501.00663v1 Titans architecture 非公式実装: https://github.com/lucidrains/titans-pytorch I. 研究の背景と動機: ...のトランスフォーマー。
2025-02-09
RAG(Retrieval Augmented Generation)システムを必要とするアプリケーションにとって、膨大なPDF文書を機械可読なテキストブロックにすること(「PDFチャンキング」とも呼ばれる)は大きな頭痛の種だ。 市場にはオープンソースのソリューションと商用製品の両方がありますが、正直なところ、本当にできるソリューションはありません...
2025-02-09
DeepSeek R1公式ジェイルブレイクは、基本的にあらゆるタイプの検閲メカニズムをトリガーするための素晴らしい実験環境であり、あなたは多くの防御テクニックを学ぶことができるので、これは長年にわたって大規模なモデルのジェイルブレイクの例を紹介する大規模なモデルの検閲メカニズムに関する学習記事です。 大規模なモデルの検閲メカニズムは、通常、使用されている...
2025-02-03
Original: https://cdn.openai.com/o3-mini-system-card.pdf 1 はじめに OpenAI oのモデルファミリーは、大規模な強化学習を使って学習され、思考の連鎖を使って推論する。これらの高度な推論機能は、我々のモデルの安全性と頑健性を向上させる新しい方法を提供する。特に、 ...
2025-02-02
Quick Reads 大規模言語モデル(LLM)のスケーリング法則の過去と現在、そしてAI研究の今後の方向性を包括的かつ詳細に考察。著者のキャメロン・R・ウルフは、明確な論理と豊富な例で、読者を基本的な概念から...
2025-02-01
概要 OpenAIのGPT-4、GoogleのPaLM、MetaのLLaMAなどの大規模言語モデル(LLM)は、人間のようなテキスト生成と自然言語理解を可能にすることで、人工知能(AI)を劇的に変化させてきた。しかし、静的な学習データに依存しているため、動的でリアルタイムのクエリへの対応には限界がある。
2025-01-31
人工知能(AI)は急速に成長している分野である。言語モデルは、AIエージェントが複雑なタスクを実行し、複雑な意思決定を行えるように進化してきた。しかし、これらのエージェントのスキルが成長し続けるにつれて、それをサポートするインフラは追いつくのに苦労しています。 LangGraphは、AIエージェントに革命を起こすために設計された画期的なライブラリです...
2025-01-30
はじめに 先週リリースされた中国製の大規模言語モデルDeepSeek-R1について、他の多くの人と同様、ここ数日、私のニュースツイートはニュース、賞賛、苦情、憶測で埋め尽くされている。DeepSeek-R1は、OpenAI、Meta、その他の優れた推論モデルと比較されている。
CORAGの主要な貢献の概要 CORAG(Cost-Constrained Retrieval Optimization for Retrieval-Augmented Generation)は、既存のRAGアプローチの主要な課題に対処するために設計された革新的なRAG(Retrieval-Augmented Generation)システムである。以下のCORAG ...
2025-01-28
知識蒸留は、事前に訓練された大きなモデル(すなわち「教師モデル」)から、より小さな「生徒モデル」へと学習を移行させることを目的とした機械学習技術である。蒸留技術は、知的対話、コンテンツ作成、その他の分野での軽量な生成モデルの開発に役立つ。 最近、ディスティレーション...
2025-01-28
近年、大規模モデルの学習や推論に携わる多くの人々が、モデルのパラメータ数とモデルサイズの関係について議論している。例えば、有名なalpacaシリーズのLLaMAラージモデルには、LLaMA-7B、LLaMA-13B、LLaMA-33B、LLaMA-65Bというパラメータサイズの異なる4つのバージョンがある。 ここでは「...
2025-01-28
元記事:https://arxiv.org/pdf/2412.15479 解釈:この記事自体はあまり革新的ではなく、応用も利かない。しかし、ずっとずっと昔に読んだ非常に有益な3つの記事を思い起こさせる。 前の3つの記事と合わせてこの記事を読むことで、より多くのインスピレーションが得られることを期待したい。お薦めの一冊:...
2025-01-25
人工知能や機械学習の分野では、特にRAG(Retrieval Augmented Generation)システムやセマンティック検索などのアプリケーションを構築する際、膨大な量の非構造化データを効率的に処理・検索することが極めて重要になる。ベクターデータベースは、この課題に対処するための中核技術として登場した。ベクターデータベースは、高次元データを格納するためだけのものではない。
2025-01-25
中国だけでなくアジアでも話題のソーシャルEコマースプラットフォーム「小紅秀」は、単なるショッピングアプリの域を超え、若者のライフスタイルの風見鶏となり、ブランドマーケティングの新たなポジションを確立して久しい。中国市場に参入したい、あるいは若い消費者にリーチしたいと考える海外のブランドや個人にとって、小紅樹を使いこなすことは...
思いがけず、AIはプログラミング分野に半端ない変革の空を起こしている。v0、bolt.newから、Agantを組み合わせた様々なプログラミングツールCursorやWindsurfまで、AIコーディングはアイデアMVPの巨大な可能性を秘めている。伝統的なAIアシスト・コーディングから、今日の直接的なプロジェクト生成の背後にあるものまで、結局は...。
2025-01-24