

大規模言語モデリング(LLM)機能の急速な発展に伴い、従来のベンチマークである MMLUトップモデルを見分けることの限界が徐々に明らかになりつつある。感情的知性、創造性、判断力、コミュニケーション能力など、実社会での交流においてモデルにとって重要な微妙な能力を総合的に測定するために、知識クイズや標準化されたテストだけに頼ることはもはや不可能なのだ。このような背景の下で、以下のような一連の研究プログラムが実施されている。 EQ-Bench このような複雑な側面から、LLMのパフォーマンスをより深く探ることを目的とした、新しい評価の枠組みが登場した。
EQ-Bench と関連するテスト・スイートは、もはや単純な善悪の判断に限定されない多様な視点を提供し、シミュレーションされた現実のシナリオにおけるモデルの挙動と意思決定の質に焦点を当てる。
ディープシーク ある知識想起レビューには幻想があふれているしかし、コストパフォーマンスを考慮したクリエイティブな文章を書くという面では、リストをブッチするのは当然とも言えるし、多くの人が実際に使っている経験も基本的には同じだ。
提出経路と提出条件
現在、このプログラムでは、以下の方法で提出できる申請書のみを受け付けています。 HuggingFace 一般に公開された重み付けモデルの言及とテスト。投稿者には、モデルへのリンク、最適なキューイング・フォーマットと生成設定、および自身のテスト結果を、電子メールまたはツイッターで提供するよう求められる。 EQ-Bench スコア。プロジェクトは結果を検証し、リーダーボードを更新する。プロジェクトは自己資金で運営されており、計算機資源も限られているため、提出者は検証プロセスに時間がかかる可能性があることを理解する必要がある。
EQ-Bench 3: 紛争調停能力アセスメント
EQ-Bench 3 は、積極的な紛争調停スキルに焦点を当てたエモーショナル・インテリジェンス・ベンチマーク・テストです。困難で多様なシナリオの中で複雑な感情的問題に対処する言語モデルの能力を評価する。このテストは、当初の EQ-Bench そうすることで、感情状態を予測するだけでなく、能動的なエモーショナル・インテリジェンスを適用するモデルの能力を直接検証することができる。
試験方法。
- 構造。 このテストは、紛争調停役を務めるテスト対象モデルと、顧客や紛争当事者役を演じる「アクター」モデル(現在使用中)との間で行われる複数ラウンドの対話(最大21ラウンド)で構成される。
gemini-2.0-flash-001)と交流する。各シーンには、特定の感情状態や背景を持つ詳細なキャラクター設定が含まれている。 - 評価基準 採点基準は以下の通り:
- 基本的なエモーショナル・インテリジェンス・スキル(感情の認識、共感の表現)
- セラピーまたは調停に関する専門的スキル
- プロとしての重大なミスを避ける
- 操作メカニズム。 ベンチマークでは3つのモデルを使用する:テスト対象モデル、アクターモデル、レフリーモデル(
Claude-3.7-Sonnet).レフェリーモデルは、テスト対象モデルのパフォーマンスを採点する役割を担っている。 - 格付け 最終的なスコアは、複数のスキル分野にわたる評価と、特定されたエラーの数とその深刻度を組み合わせたものです。レフェリー・モデルはまた、特定のエラーについて批判的な分析を行い、軽微、中程度、深刻のいずれかに評価することで、実際のプロフェッショナルな対話におけるモデルの欠点を正確に特定します。
審判モデリングにおける自己優先問題。
一般的な懸念は、LLMの裁定者が偏見を持ち、特に自分のモデルの出力を好むのではないかということである。この現象を調べるためにEQ-Bench 3 利用する Claude-3.7-Sonnet 歌で応える gpt-4o-2024-11-20 2つのレフリーモデルがトップモデルをベンチマークした。

その結果、少なくとも2つのレフェリー・モデルの間では、明確な自己選好は観察されず、両者のスコアはほぼ同じであった。これは、LLMをレフェリーとして使用することに一定の自信を与えるものであるが、潜在的なバイアスの可能性には留意する必要がある。
関連するコードと完全なドキュメントは、近日中に以下のサイトで公開される予定だ。 EQ-Bench ウェアハウス・リリース
EQ-Bench (Legacy): 感情認識ベンチマーク
アーリージェネレーション EQ-Bench このベンチマークは、言語モデルのエモーショナル・インテリジェンスを評価するように設計されており、ユーザー・エクスペリエンスの重要な部分でありながら、他のベンチマークでは明確にテストされていません。そのユニークな利点は、微調整によってスコアを「ブラッシュアップ」することが比較的難しく、リーダーボードがモデルの真の能力をより反映したものになることです。
このテストは、モデルが台詞を読み、登場人物の1人の感情的な反応の強さを評価するよう求められる形式になっている(4つの事前定義された感情について)。この評価プロセスは、レフェリー・モデルの介入を必要とせず、低コストであり(わずか171問)、結果は人間の嗜好と一致している(Arena ELO) とマルチドメインベンチマーク (MMLU)は強い相関を示した。
MAGI-Hard:高難易度の識別テストのサブセット。
既存のLLMベンチマークの性能が飽和状態にあり、トップモデルを区別することが困難であることを考えると。MAGI-Hard が発表された。の一例である。 MMLU 歌で応える AGIEval これらのモデルの中から厳選されたサブセットは、高能力モデルの差別化を強化することを目的としている。開発者は、提供される EleutherAI lm-evaluation-harness 実行するブランチ MAGI テストセット。
クリエイティブ・ライティングの評価をアップグレード 🎨 クリエイティブ・ライティングの評価をアップグレード
クリエイティブ・ライティング・ベンチマークがv3リリースされ、以下を含む主要なアップデートが行われた:
- 新しいヒント その目的は、より良い差別化を図り、「空気感」をチェックすることである。
- ハイブリッド採点システム。 ルーブリックと
Eloトップモデルの識別能力とテストのダイナミックレンジを大幅に向上させる採点システム。 - サンプル出力ページの改善。
ベンチマーキング・プロセス。
- 温度は0.7、min_pは0.1に設定し、32のライティング・プロンプトを使用してモデルを3反復(合計96項目)実行した。
- 利用する
Claude 3.7 Sonnetレフェリーとして、総合的な採点ルールに従って採点する。 - ルールスコアに基づく初期推論モデル
Elo格付け - リーダーボード(スパースサンプリング)上の近隣モデルとの一対比較が行われ、勝者には複数の基準スコアに基づいて最大5つの「+」が与えられる。
- 利用する
Glicko採点方法("+"の数の勝率を考慮したものに変更) 計算方法Eloスコアは、順位が安定するまで循環する。 - 最終的なリーグテーブルを算出するために、最終決定された近隣モデルとの包括的な比較が行われた。
Elo.
採点ルール スコア対エロスコア。
2種類の採点が共存している。ルール採点は、レフェリーが個々のモデル出力を独自に評価した結果である;Elo 一方、スコアリングは、モデル間の2対2の直接対決によって生み出される相対的なランキングである。この2つの違いは、評価の仕方に起因する。2人1組で比較することで、審査員はニュアンスの違いを見つけやすくなるが、異なるバイアスが生じる可能性もある。採点基準も2つのモデルで異なる。
スコアの標準化。
対策 Elo 新モデルの追加により、総合スコアのドリフトが問題視されており、リーダーボードは以下のようになる。 DeepSeek-R1 スコアは1500点。ministral-3b 200に固定。
ベンチマーキング哲学。
v3バージョンでは、二者択一の比較を導入することで、クリエイティブ・ライティングの判定をより難しくしている。 Elo 差別化を図るためのランキングシステム。プロンプトの単語は、モデルの弱点に挑戦するように注意深く選択され、審査員にとってより急な評価勾配を生み出します。このテストには、ユーモア、ロマンス、空間認識、非伝統的な一人称視点など、一般的にLLMが人間レベルで達成するのに苦労する側面が含まれている。
コストとバイアスの軽減。
ハイブリッドスコアリングシステムにもかかわらず、アセスメントを実行するためのAPIコストは約10ドルである。一対比較は、プロジェクトチームが軽減を試みた新たなバイアスの課題をもたらした:
- 長さのバイアス。 出力を4000文字に切り詰めることで制御。
- ポジションの偏り。 緩和は、両方向の値を評価し平均化することで達成される。
- 複雑な冗長性バイアス。 採点基準には、過度に派手な語彙に対する罰則も含まれている。
- 詩的曖昧さバイアス 採点方法は、過度に詩的で支離滅裂な散文にペナルティを科そうとしている。
制御不能なバイアス。
- 自己バイアス。 コントロールされていない審判は、自分のアウトプットを優先するかもしれない。
- ポジティブなバイアス。 その方向性と影響はまだ明らかではない。
- スマット・バイアス。 審判は、エロティックに傾いたコンテンツに厳しいペナルティを科す傾向がある。
- スタイルと内容の偏り 審判の好みは、ユーザーや一般的な人間の好みとは異なるかもしれない。
- ドロドロのバイアス。 レフェリーは、LLMでよく使われる特定の型やスタイルを好むかもしれない。
ペア判定プロンプトのコア基準。 キャラクターの信憑性、面白さと独創性、文章の質、首尾一貫性、指示への従順さ、世界観と雰囲気の構築、決まり文句の回避、華美な冗長の回避、過剰な比喩の回避。
制限。
評価結果は、ライティング能力の大まかな目安に過ぎません。クリエイティブ・ライティングは非常に主観的なものであり、サンプル・アウトプットを読むことと合わせて、自分自身で判断することをお勧めします。このベンチマークはロールプレイ(RP)評価ではなく、複数ラウンドの対話はテストされません。
クリエイティブ・ライティング(レガシーv2):旧クリエイティブ・ライティング・アセスメント
旧型(v2)使用 Claude 3.5 Sonnet はレフェリーの役割を果たし、様々なプロンプトに対するモデルの作文能力を評価します。また、「語彙の複雑さ」と「GPT-Slop」メトリクスを導入し、スライダーで両者のペナルティの重みを調整できるようにした。このバージョンでは、採点ルールと参照出力を使用して24のプロンプトを評価し、安定性を向上させるために10回の反復を実行する。同様に、スコアリング基準と長さコントロールスライダーによって長さの偏りを軽減しようと試みているが、それでも偏りが存在する可能性があることを認めている。
⚖️ Judgemark V2: 判定モデリング能力評価
Judgemark V2 評価されるのは、言語モデルがそれ自体で「審査員」として機能する能力、つまり、詳細なルールに従って創作された文章を評価する能力である。 スコア 能力である。これは単純なペア嗜好テストよりも複雑で、審判モデルは複雑な指示を理解し、テキストを分析し、文学的な質を36の次元まで採点する必要がある。
バージョンV2の主な改良点。
- サンプルサイズを6倍に増やすと、実行分散が減少する。
- 洗練された採点基準:識別性(強いテキストと弱いテキストの区別)、安定性(ランクの一貫性)、人間の嗜好との関連性を測定。
- 生得点と較正得点があり、後者は分布を標準化することで審査員間の比較可能性を高める。
- 結果の頑健性を評価するため、摂動安定性テスト(temp=0.5, top_k=3)を導入した。
- 簡素化されたスタンドアロンのコードベース。
反復性試験。 右 Llama-3.1-70B-instruct 20回のテストが実施され、最終スコアの標準偏差は約1.0であり、結果がある程度安定していることが示された。
審査課題。 審査員モデルは、17の異なるレベルの「作家モデル」によって作成された短い創作作品を読み、肯定的な基準と否定的な基準の両方を含む長いプロンプトに基づいて数値スコアを出力する(例えば、「詳細なキャラクター:0-10」、「気取った:0-10」。)10」、後者は低いほど良い)。最終 Judgemark スコアは、識別性、安定性、人間の嗜好との関連性など、計算されたいくつかの指標の加重合計に基づいている。
綿密な文芸批評のスキルと、多角的な数値採点指示に従う能力が要求されるため、LLMにとっては極めて困難な課題である。
🎤 BuzzBench:ユーモア分析のベンチマーク
BuzzBench イギリスの音楽クイズ番組を分析することによって Never Mind The Buzzcocks LLMのユーモア理解能力は、ショーのゲストにジョークを紹介することで評価された。この課題では、ジョークの仕組みを説明するだけでなく、そのジョークが観客やコメディ作家にとってどの程度「面白い」かを予測する必要があった。
挑戦的なデザイン。
- 番組ジョークの選択は、そのスタイルの多様性(微妙、冒険的、下品、不明瞭、明白、巧妙)により、LLMを特定する難易度を高めた。
- 娯楽レベル」を予測する要件には、人間の反応をモデル化することが含まれる。
- 審査員の採点の基準として、人間が書いた「ゴールデンアンサー」を使用する。
このベンチマークは、理論的な心的理解と、ジョークの仕組みに関する複雑な知識をテストするためにデザインされた。レフリーモデルが選ばれた Claude 3.5 Sonnetにあるからだ。 Judgemark の得点が高く、長くて過剰に分析された回答をあまり好まないようだ。ここでも、審判の根底にある自己選好に注意を払う必要がある。
DiploBench: 戦略的交渉の評価フレームワーク(実験的) 🌍 DiploBench: 戦略的交渉の評価フレームワーク(実験的
DiploBench 戦略を使うボードゲームだ Diplomacy LLMの戦略的交渉能力を評価するための実験的枠組み。実験モデルは Austria-Hungary (オーストリア=ハンガリー)は、卓越した交渉スキルと戦略的プランニングが要求されるやりがいのある役割だ。モデルは他のAIプレーヤーとコミュニケーションを取り、同盟を結び、欺瞞を見抜き、戦術的な決断を下す必要があります。
主な特徴
- フルプレス 手術の前に何度も交渉を重ねた。
- マルチインテリジェントな身体環境。 各国は独立したLLMによって管理されている。
- リアルな外交シミュレーション。 アラインメント、ネゴシエーション、欺瞞認識能力をテストする。
- チャレンジングなオープニング。
Austria-Hungary中心部に位置するため、脆弱だが戦略的だ。
ゲームは最大50ラウンド行われ、各ラウンドの行動の前に4ラウンドの交渉が行われる。このフレームワークは、LLMの長期戦略計画、マルチインテリジェンス交渉、理論的マインドフルネス、欺瞞検知の能力をユニークにテストする。
注:試合結果のばらつきが大きいためDiploBench これはまだ実験的な枠組みであり、結果は慎重に解釈されるべきである。
まとめ
EQ-Bench シリーズは、LLM評価を伝統的な評価基準を超えて、より人間的相互作用のニーズに対応した複雑な能力の次元へと押し進める貴重なツール群を提供する。レフェリーのバイアスや評価の主観性といった課題は残るものの、これらのベンチマークの設計と反復(例えば、v2、v3における改善、バイアスに関する明確な議論とそれを軽減する試み)は、LLM評価の分野がより深く、よりニュアンスのあるレベルへと進化するための重要な一歩となる。開発者や研究者にとって、これらのツールはモデルの進歩を測定するための基準を提供するだけでなく、将来的にモデルの能力を向上させるための重要な方向性を示している。
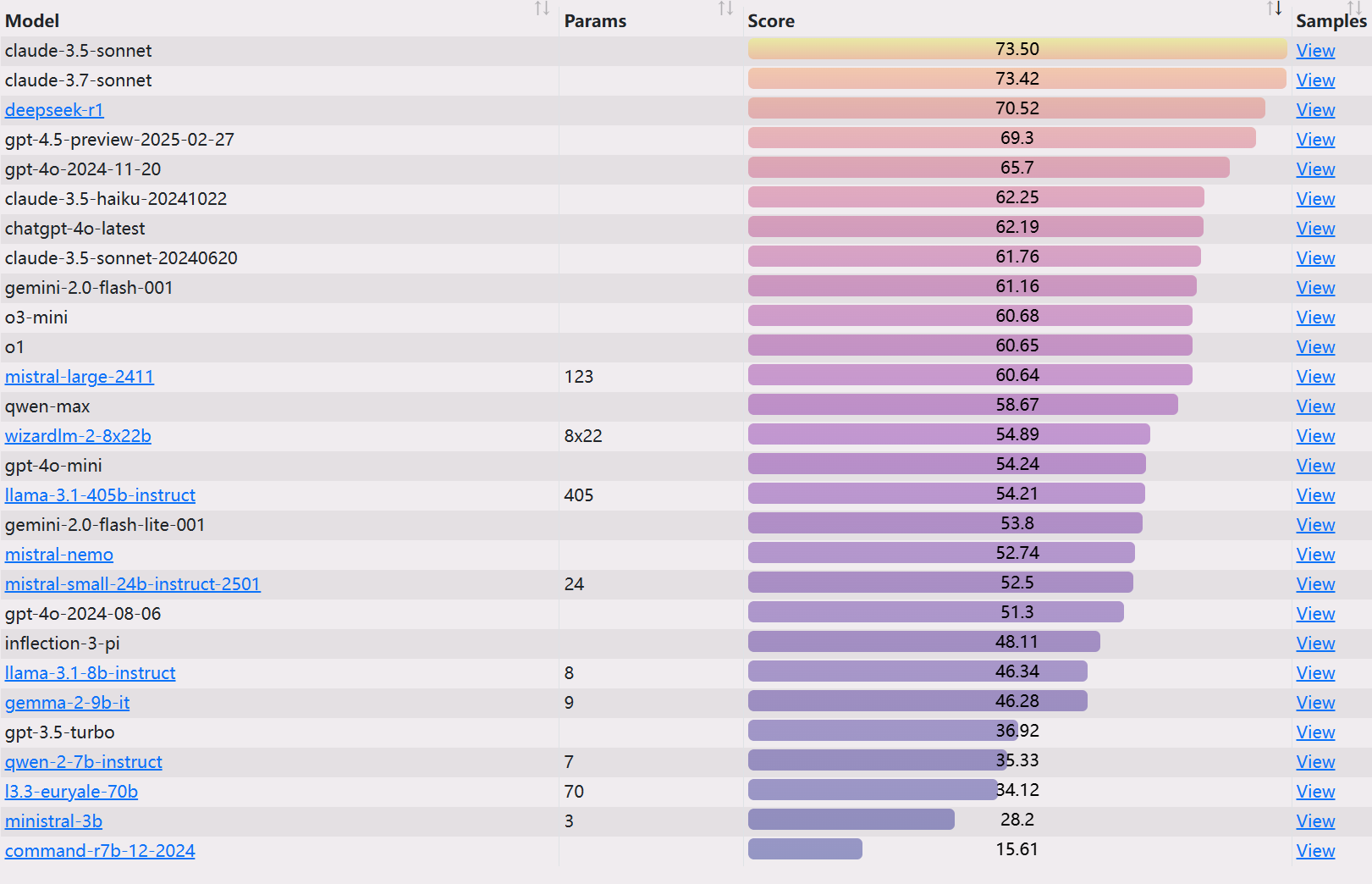
EQベンチ3ランキング
https://eqbench.com/















