

大規模言語モデル(LLM)は急速に進化しており、その推論能力は知能レベルを示す重要な指標となっている。特に、長い推論能力を持つモデル、例えばOpenAIの o1そしてDeepSeek-R1そしてQwQ-32B 歌で応える Kimi K1.5 これらのモデルは、人間の深い思考プロセスを模倣することで、複雑な問題を解決する能力で大きな注目を集めている。この能力には、推論時間スケーリングと呼ばれる技法が使われることが多く、モデルが答えを生成する際に、より多くの時間を探索や修正に費やすことができる。
しかし、深く考えてみると、これらのモデルはしばしば両極端の推論に陥っていることがわかる:アンダーシンキング 歌で応える 考えすぎ.
不十分な思考 これは、モデルの推論において頻繁に考えが入れ替わることを指し、より深く掘り下げるための有望な方向性に焦点を絞ることを難しくしている。モデルの出力は、下図のように、「あるいは」、「しかし待て」、「考え直してみよう」などの言葉で埋め尽くされることがあります。下図に示すように、最終的な答えが不正確になります。この現象は、推論の妥当性に影響を与える人間の不注意に例えることができる。

考え過ぎ その代わりに、このモデルは単純な問題に対して長く不必要な「思考の連鎖」を生み出す。例えば、"2+3=? "のような基本的な算数の問題に対してである。 例えば、"2+3=? "のような基本的な算数の問題では、モデルによっては何百時間、何千時間もの作業を要することもある。 token 下図のように、複数の解を繰り返し検証したり探索したりする。複雑な思考プロセスは難しい問題には有益だが、単純なシナリオでは、これは確実に計算資源の浪費につながる。
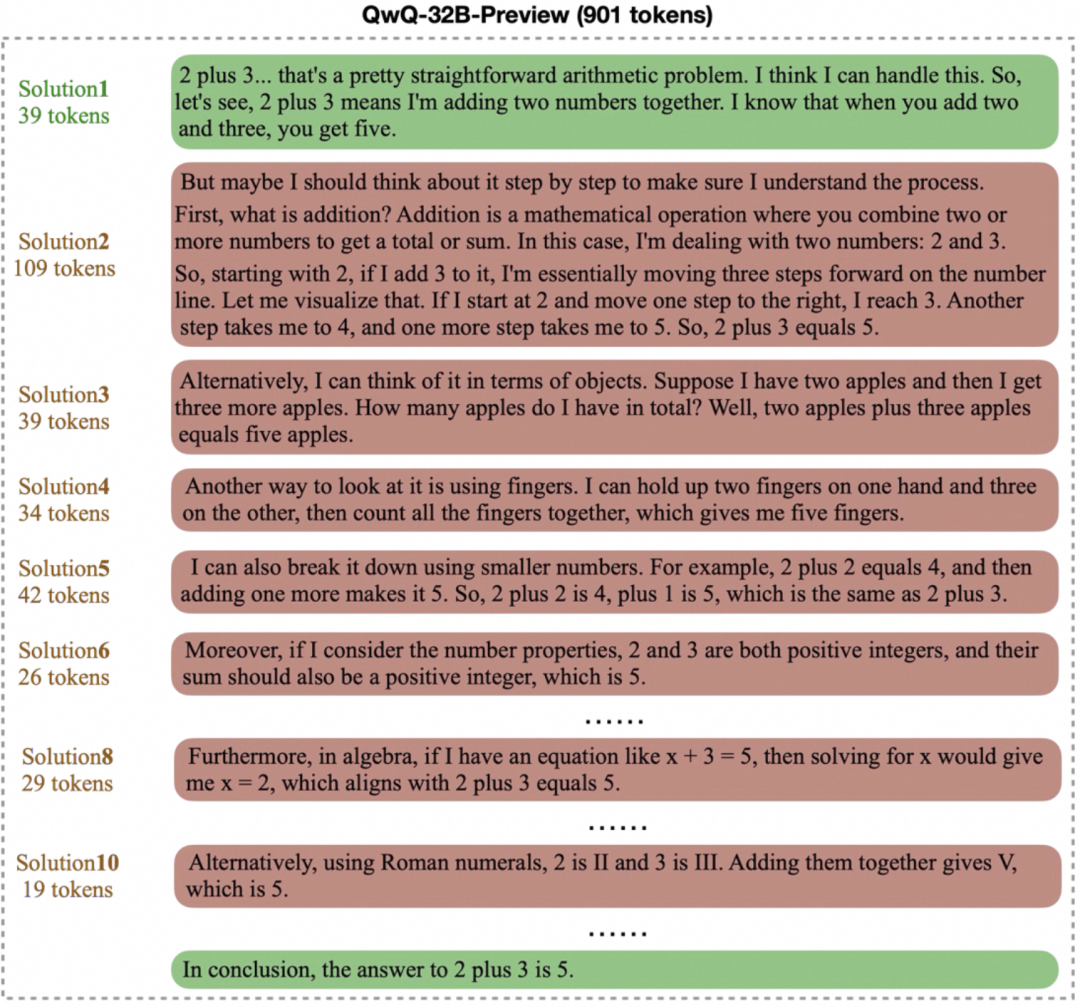
これら2つの疑問は共に、「答えの質を維持しながら、モデルの思考効率をいかに向上させるか」という中心的な課題を指し示している。理想的なモデルは、最短の出力で正しい答えを見つけ、与えることができなければならない。
この課題に対処するためだ。EvalScope を紹介する。 EvalThink コンポーネントは、モデルの思考効率を評価するための標準化されたツールを提供することを目的としている。本稿では MATH-500 一例として、データセットの分析には以下が含まれる。 DeepSeek-R1-Distill-Qwen-7B 6つの次元に焦点を当てた推論モデルを含む、さまざまな推論モデルの性能:モデル推論 token 番号、初回権利 token 数、残りの反射 token 数字だ、token 効率、サブ思考チェーンの数、精度。
評価方法とプロセス
評価プロセスは、モデル推論評価とモデル思考効率評価の2つの主要段階からなる。
モデル推論の評価
このフェーズの目的は、次のようなモデルを得ることである。 MATH-500 データセットに対する生の推論結果と基本精度。MATH-500 このデータセットには、難易度(レベル1からレベル5まで)の異なる数学の問題が500問含まれている。
評価環境の準備
OpenAI API互換の推論サービスにアクセスすることで、評価を行うことができます。EvalScope また、このフレームワークは transformers ライブラリーは現地でレビューされる。長い思考の連鎖を処理する必要がある人のために(おそらく10,000以上 token)を使った推論モデルの vLLM もしかしたら ollama このような効率的な推論フレームワークは、評価プロセスを大幅にスピードアップできるモデルを展開する。
には DeepSeek-R1-Distill-Qwen-7B 例として vLLM サービスをデプロイするサンプル・コマンドは以下の通り:
VLLM_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --served-model-name DeepSeek-R1-Distill-Qwen-7B --trust_remote_code --port 8801
エグゼクティブの推論
とおす EvalScope な TaskConfig モデルAPIのアドレス、名前、データセット、バッチサイズ、生成パラメータを設定し、評価タスクを実行する。以下はサンプルPythonコードです:
from evalscope import TaskConfig, run_task
task_config = TaskConfig(
api_url='http://0.0.0.0:8801/v1/chat/completions', # 推理服务地址
model='DeepSeek-R1-Distill-Qwen-7B', # 模型名称 (需与部署时一致)
eval_type='service', # 评测类型:服务
datasets=['math_500'], # 数据集
dataset_args={'math_500': {'few_shot_num': 0, 'subset_list': ['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5']}}, # 数据集参数,包含难度级别
eval_batch_size=32, # 并发请求数
generation_config={
'max_tokens': 20000, # 最大生成 token 数,设置较大值防截断
'temperature': 0.6, # 采样温度
'top_p': 0.95, # top-p 采样
'n': 1, # 每个请求生成一个回复
},
)
run_task(task_config)
評価が完了すると、モデルは次のようにエクスポートされる。 MATH-500 各難易度における精度AveragePass@1):
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|-----------------------------|-----------|---------------|----------|-----|--------|---------|
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 1 | 43 | 0.9535 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 2 | 90 | 0.9667 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 3 | 105 | 0.9587 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 4 | 128 | 0.9115 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 5 | 134 | 0.8557 | default |
モデル思考効率評価
推論を得た後EvalThink より詳細な効率分析のためのコンポーネント介入。核となる評価指標には以下が含まれる:
- モデル化された推論
token(推論トークン)O1/R1モデルのように)模範解答を生成する際の思考連鎖</think>(フラグの前にあるもの)に含まれている。token総額。 - 最初から
token番号(最初の正解トークン)モデル出力の開始から、特定可能な正解位置の最初の発生までtoken数量。 - 残された反省
token反射トークン:: 最初の正解位置から思考の連鎖の終わりまでtoken数量。これは、モデルが答えを見つけた後、検証や探索を続けるコストを一部反映している。 - ナム・ソート:: 特定の記号を数えることによって(例えば
alternatively,but wait,let me reconsider)の発生頻度から、モデルがアイデアを切り替える頻度を推定する。 tokenトークン効率:: 効果的な思考を測るtoken初回正解率として計算されるパーセンテージの指標token数と一般推理token正解サンプルのみをカウント)の数の比率の平均:
トークンの効率 1⁄N ∑ 最初の正解 トークンi⁄推論トーケンシ
ここで、Nは正解した問題数である。この値が大きいほど、モデルの思考が「効率的」であることを意味する。
初回権利」を決定するために token ナンバー "と呼ばれる評価フレームワークがある。 ProcessBench 別のジャッジモデルを使用することです。 Qwen2.5-72B-Instruct推論ステップをチェックし、最も早く正解が得られる位置を特定する。この実装では、モデルの出力をステップに分解する(ストラテジーはオプション:特定のセパレータによる)。 separatorプレスキーワード keywordsあるいは、LLMの助けを借りて書き直し、スライスする。 llm)、レフェリーモデルにそれぞれのジャッジを任せる。
思考効率評価を行うためのサンプルコード:
from evalscope.third_party.thinkbench import run_task
# 配置裁判模型服务
judge_config = dict(
api_key='EMPTY',
base_url='http://0.0.0.0:8801/v1', # 假设裁判模型也部署在此服务
model_name='Qwen2.5-72B-Instruct',
)
# 配置待评估模型的信息
model_config = dict(
report_path='./outputs/2025xxxx', # 上一步推理结果路径
model_name='DeepSeek-R1-Distill-Qwen-7B', # 模型名称
tokenizer_path='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', # Tokenizer 路径,用于计算 token
dataset_name='math_500', # 数据集名称
subsets=['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5'], # 数据集子集
split_strategies='separator', # 推理步骤分割策略
judge_config=judge_config
)
max_tokens = 20000 # 过滤 token 过长的输出
count = 200 # 每个子集抽样数量,加速评测
# 运行思考效率评估
run_task(model_config, output_dir='outputs', max_tokens=max_tokens, count=count)
評価結果には、各難易度におけるモデルの6つの次元の測定基準が詳述される。
結果の分析と考察
調査チームが使用したのは EvalThink 右 DeepSeek-R1-Distill-Qwen-7B その他いくつかのモデル(QwQ-32BそしてQwQ-32B-PreviewそしてDeepSeek-R1そしてDeepSeek-R1-Distill-Qwen-32B)を評価し、非推論的な数学的特殊モデルを追加した。 Qwen2.5-Math-7B-Instruct 比較として。
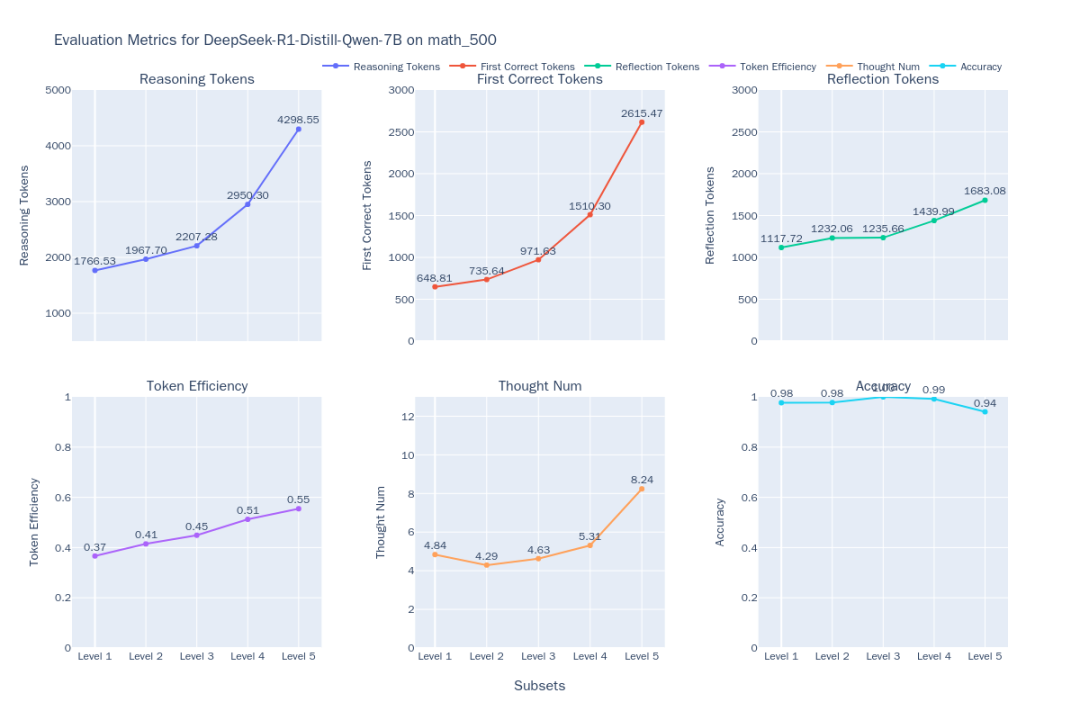
図1:DeepSeek-R1-Distill-Qwen-7Bの思考効率指標
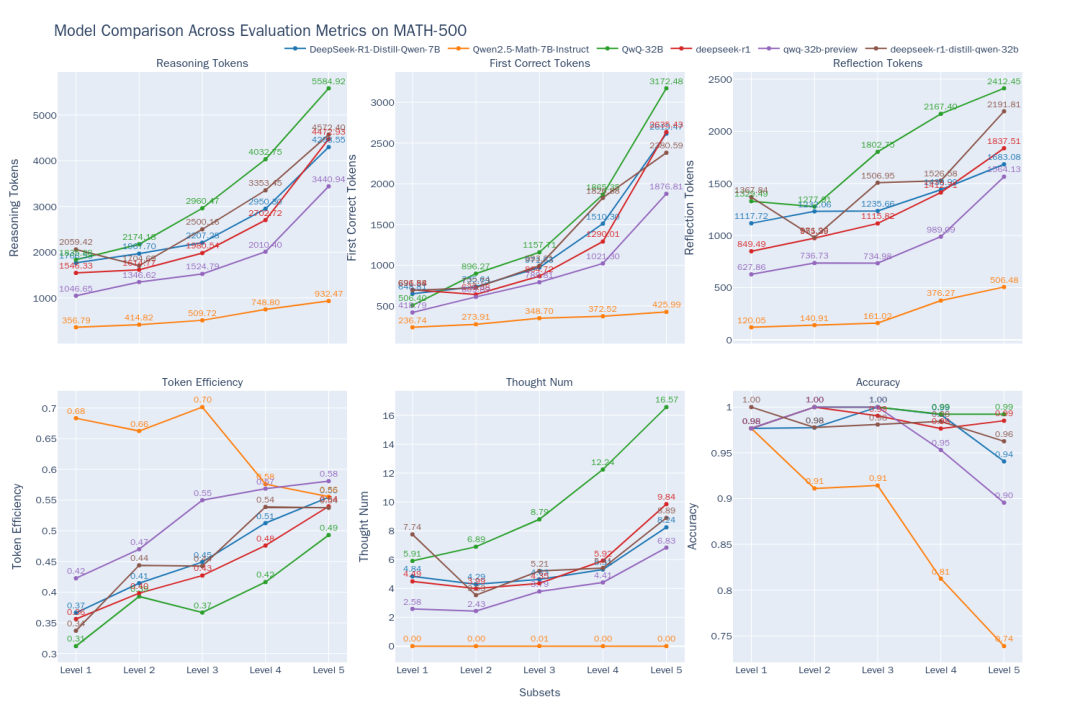
図2:MATH-500の難易度別6モデルの思考効率の比較
比較結果(図2)からは、以下のような傾向が見られる:
- 難易度とパフォーマンスの相関関係問題の難易度(レベル1からレベル5)が上がるにつれて、ほとんどのモデルの精度は低下する。しかし
QwQ-32B歌で応えるDeepSeek-R1難問を得意とするQwQ-32Bレベル5で最も精度が高い。同時に、すべてのモデルの出力はtoken難易度が上がるにつれて数字が長くなっていくが、これは「拡大しながら推理する」という期待に沿ったものである。 - O1/R1クラスの推論モデルの特性:
- 効率性の向上:: 興味深いことに
DeepSeek-R1歌で応えるQwQ-32Bこのタイプの推論モデルは、出力は長くなるもののtoken効率(有効)tokenパーセンテージ)も難易度とともに増加する(DeepSeek-R136%から54%まで。QwQ-32B(31%から49%へ)。このことは、難しい問題では彼らの余分な思考がより「費用対効果」に優れているのに対し、簡単な問題では不必要な反復検証など、ある程度の「考えすぎ」があることを示唆している。QwQ-32Bなtoken全体的に消費量が多く、それがレベル5で高い精度を維持できる理由のひとつかもしれないが、物事を考えすぎる傾向もうかがえる。 - 思考の道:
DeepSeekシリーズ・モデルのサブ思考連鎖の数は、レベル1~4では比較的安定しているが、最も難しいレベル5では劇的に増加する。このことは、レベル5がこれらのモデルにとって大きな挑戦であり、複数回の試行を必要とすることを示唆している。これに対してQwQ-32B系列モデルは、対処戦略の違いを反映して、思考の連鎖数の伸びがよりスムーズである。
- 効率性の向上:: 興味深いことに
- 非推測モデルの限界:: 数学的特殊モデル
Qwen2.5-Math-7B-Instruct難しい問題を扱うと精度は劇的に低下し、出力も低下する。tokenこの数字は推論モデルの場合(約3分の1)よりもはるかに低い。このことは、このようなモデルは、一般的な問題ではより速く、より少ないリソースで処理できるかもしれないが、より深い思考プロセスがないため、複雑な推論タスクでは性能に大きな「上限」があることを示唆している。
方法論的考察と限界
アプリケーションで EvalThink 査定を行う際には、いくつかの留意点がある:
- 指標の定義:
- 本稿で提案する
token効率性指標は、文献にある「考えすぎ」と「考えなさすぎ」の概念に基づくもので、主に以下の点に焦点を当てている。token思考プロセスの簡略化された尺度である「量」では、思考の質の詳細を完全に把握することはできない。 - サブシンキングチェーンの数の計算は、あらかじめ定義されたキーワードに依存しており、異なるモデルの思考パターンを正確に反映させるためには、キーワードのリストを適合させる必要があるかもしれない。
- 本稿で提案する
- 適用範囲:
- 現在のメトリクスは、主に数学的推論のデータセットで検証されており、オープンクイズやアイデア生成などの他のシナリオでの有効性はまだ検証されていない。
- ケータリング
DeepSeek-R1-Distill-Qwen-7Bの蒸留の数学的モデルに基づいている。MATH-500データセットの性能には当然優位性があるかもしれない。評価結果はモデルの文脈で解釈する必要がある。
- 裁定モデルの依存関係:
token効率の計算は、推論ステップの正しさを正確に判断するジャッジモデル(JM)に依存する。としてProcessBench4この研究は、既存のモデルにとって困難なタスクであることを指摘している。- レフェリングモデルにおける誤った判断は、次のようなことに直接影響を与える可能性がある。
tokenそのため、適切なレフリーモデルを選ぶことが重要である。
一言で言えばEvalThink LLM思考の効率性を定量的に評価するためのフレームワークとメトリクスのセットが提供され、異なるモデルが精度という点でどの程度優れているかが明らかにされる、token 消費量と思考の深さのトレードオフ。これらの知見は、モデルトレーニングの指針として有用である(例えば、以下のような)。 グルポ やSFTのように、問題の難易度に応じて思考の深度を適応的に調整できる、より効率的な次世代モデルの開発は有益である。















