General Introduction
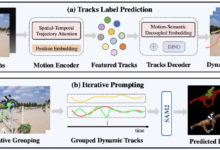
VideoMind is an open source multimodal AI tool focused on inference, Q&A and summary generation for long videos. It was developed by Ye Liu of the Hong Kong Polytechnic University and a team from Show Lab at the National University of Singapore. The tool mimics the way humans understand videos by breaking down the task into steps such as planning, positioning, verifying and answering to solve the problem step by step. The core technology is Chain-of-LoRA, which switches between roles through a base model, which is both efficient and resource-efficient.VideoMind officially released the code, model, and dataset on March 21, 2024, and the technical report was updated on March 17, 2025.VideoMind is available on GitHub or via GitHub. Users can access the resources via GitHub or Hugging Face.
The project is not to extract audio to text to understand the content, but purely graphical and according to the timestamp accurate understanding of the video content, can be used for automatic video fine-tuning, teaching scenarios, very practical!

Experience: https://huggingface.co/spaces/yeliudev/VideoMind-2B
Function List
- Long video time localization: find the time period in the video that is relevant to the question.
- Video Q&A function: extract accurate answers from videos based on user questions.
- Video Summary Generation: Distill key video content to generate a concise overview.
- Multimodal agent framework: includes planners, locators, validators and responders that collaborate on tasks.
- Chain-of-LoRA Technology: Multi-functionality with a single model to reduce resource consumption.
- Multiple hardware support: runs on NVIDIA GPUs or Ascend NPUs.
- Efficient training support: Integration of DeepSpeed, LoRA, FlashAttention2 and other technologies.
- Online Demo: Quickly experience the functionality through the Gradio interface.
Using Help
VideoMind is an open source project, users need to download the code and configure the environment to use it. The following is a detailed guide covering installation and feature usage.
Installation process
- Clone Code Repository
Run the following command in the terminal to download the VideoMind source code:
git clone https://github.com/yeliudev/VideoMind.git
Go to the project catalog:
cd VideoMind
- Setting up the Python environment
Create a virtual environment using conda (Python 3.12 recommended):
conda create -n videomind python=3.12 -y
conda activate videomind
- Installation of dependent libraries
Execute the following command to install the required dependencies:
pip install -r requirements.txt
For efficient training, install DeepSpeed:
pip install deepspeed
- Download models and datasets
- Visit https://huggingface.co/collections/yeliudev/videomind-67dd41f42c57f0e7433afb36 to download pre-trained models (e.g.
VideoMind-2B), unzip it into themodelsFolder. - The dataset is available at https://huggingface.co/datasets/yeliudev/VideoMind-Dataset下载 and includes 27 video datasets and VideoMind-SFT (481K training data) placed in the
dataCatalog.
- test installation
Run the test script to confirm that the environment is correct:
python test.py
Main Functions
1. Long-form video time positioning
- Preparation Video: Place the video file into the
data/videosCatalog, support MP4, AVI and other formats. - Run command::
python run_grounding.py --video_path data/videos/sample.mp4 --query "找到讨论AI的部分"
- Result Output: Returns a time range, such as "00:05:12 - 00:07:34".
2. Video quiz
- Input Issues: New
query.txtWrite questions, such as "Who is the main character in the video?" . - execute a command::
python run_qa.py --video_path data/videos/sample.mp4 --query_file query.txt
- Get Answers: The terminal displays the results, such as "The protagonist is Li Ming".
3. Video summary generation
- Run command::
python run_summary.py --video_path data/videos/sample.mp4
- View Summary: The results are saved as
summary.txtFor example, "The video introduces a science and technology lecture".
Featured Function Operation
Chain-of-LoRA technology
- VideoMind uses a single model to switch roles via LoRA adapters. The configuration file is available in the
config/lora.yamlAdjustablerankParameter boosting effect:
lora:
rank: 16
Online Demo
- There is no need for a local installation, so you can visit https://huggingface.co/spaces/yeliudev/VideoMind-2B, upload a video and enter your question to experience the functionality directly. For more information, see
docs/DEMO.mdThe
training model
- Prepare data: Use
VideoMind-SFTor 27 other datasets, placed in thedataCatalog. - priming training: Run:
python train.py --dataset data/VideoMind-SFT --model models/VideoMind-2B
- Monitor training: Supports Tensorboard or Wandb to view progress, see configuration for details
docs/TRAIN.mdThe
caveat
- When the video file is too large, it is recommended to process it in segments to avoid memory overflow.
- Ascend NPU users need to install the Ascend driver and add parameters when running.
--device ascendThe - For more information on commissioning see
docs/EVAL.md, including benchmarking guidelines.
With these steps, users can quickly install and use VideoMind to handle long video tasks.
application scenario
- Video Content Analysis
Users can use VideoMind to analyze long YouTube videos, locate key segments or generate summaries to save viewing time. - Education and Research
Students or researchers processing lecture videos can ask "What algorithms were covered?" and get the answers, organizing notes more efficiently. - Content Audit
Platform administrators use it to verify that video content is compliant, such as checking for offending clips.
QA
- How long of a video can VideoMind handle?
Depending on the hardware, 16GB of RAM can handle an hour of video, and 32GB supports longer content. - What is the difference between an online demo and a local deployment?
The online version requires no installation but has limited functionality; the local version supports customized training and large-scale processing. - How are the datasets used?
27 datasets were used for training and evaluation, and VideoMind-SFT was suitable for optimizing the models, as described at https://huggingface.co/datasets/yeliudev/VideoMind-Dataset.