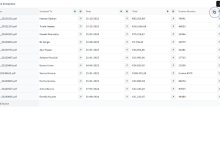
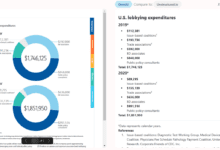
Comprehensive Introduction Rowfill is an open source document processing platform designed for knowledge workers. It utilizes advanced AI technologies to extract, analyze and process data from complex documents, images and PDFs.Rowfill supports native Large Language Models (LLM) and OpenAI Visual Models to ensure that data is hidden...
General Introduction PPTX2MD is an open source tool designed to convert PowerPoint PPTX files to Markdown format. Developed by GitHub user ssine, the tool supports retaining headings, lists, text formatting (such as bold, italic, color, and hyperlinks), images, and tables in a variety of formats.PPTX2MD...
Enable Builder Smart Programming Mode, unlimited use of DeepSeek-R1 and DeepSeek-V3, smoother experience than the overseas version. Just enter the Chinese commands, even a novice programmer can write his own apps with zero threshold.
General Introduction Repomix (formerly known as Repopack) is an open source tool designed to package an entire codebase into a single, AI-friendly file. This tool makes it easy for developers to make their codebase available to large language models (such as Claude, ChatGPT, and Gemini) for analysis and processing...
General Introduction Yek is a fast Rust-based tool for reading text files from repositories or directories, chunking them, and serializing them for use in Large Language Models (LLMs). The tool uses the .gitignore rule by default to skip unwanted files and uses Git history to infer important files....
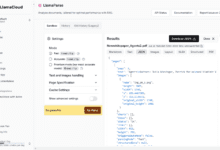
Comprehensive Introduction LlamaParse is a powerful document parsing tool that can process complex documents such as PDF, PowerPoint, Word documents and spreadsheets and convert them to structured data.LlamaParse offers multiple ways to use it, including a standalone REST API, Python packages, TypeScr...
Comprehensive Introduction UnDatas.IO is a platform focused on parsing and processing unstructured data. It utilizes advanced technology to automatically recognize document layouts and categorize tables, images, formulas and text, greatly simplifying the data processing process. The platform not only saves a lot of time in organizing data, but also helps...
Comprehensive introduction Zerox is an open source project designed to convert PDF, DOCX, images and other documents to Markdown format through visual modeling . The project is developed by getomni-ai team , provides a simple and efficient OCR (Optical Character Recognition) solution.Zerox supports Node and Python programming languages, ...
General Introduction SemHash is a lightweight and flexible tool for dataset de-duplication by semantic similarity. It combines the fast embedding generation of Model2Vec with the efficient ANN (Approximate Nearest Neighbor) similarity search of Vicinity.SemHash supports single dataset de-duplication (e.g., cleaning the training...
General Introduction Parseur is a leading AI data extraction software designed to help users automatically extract text data from PDFs, emails and other documents. With Parseur, users can easily convert unstructured data into structured data and send it to various applications. The software is widely ...
Comprehensive Introduction Weco AI Functions is a powerful platform designed to help users rapidly build and deploy AI functions. By simply describing tasks, users can generate structured output patterns with A/B testing and observational monitoring. The platform supports code-free prototyping, enabling even non-technical users to...
Comprehensive Introduction NV Ingest (NVIDIA Ingest) is a suite of early access microservices designed for parsing hundreds of thousands of complex, messy unstructured PDFs and other enterprise documents. It can convert these documents into metadata and text for embedding into retrieval systems.NVIDIA Ingest supports...
General Introduction Trellis is a data platform focused on converting complex unstructured data sources into a structured SQL format. Through its powerful AI engine, Trellis is able to process a wide range of data sources such as financial documents, voice calls, and emails and convert them into SQL that can be used by data and operations teams...
Comprehensive Introduction Ollama OCR is a powerful Optical Character Recognition (OCR) toolkit that utilizes the state-of-the-art visual language model provided by the Ollama platform to extract text from images. The project is available both as a Python package and provides a user-friendly Streamlit web application interface. It supports multiple ...
Comprehensive Introduction llmstxt-generator is a professional web content extraction and integration tool specialized in preparing high-quality textual datasets for training and inference in Large Language Models (LLMs). Developed by Mendable AI, the tool uses web crawling technology provided by @firecrawl_dev and GPT-4-mini ...
Comprehensive introduction Doc2X is a powerful document image formula recognition and conversion tools, is committed to providing efficient and intelligent document processing solutions. Whether it is an academic research paper, textbooks, corporate documents or financial reports, Doc2X can accurately recognize the tables and formulas in PDF and convert them with one key...
Comprehensive Introduction ExtractThinker is a flexible document intelligence tool that utilizes Large Language Models (LLMs) to extract and classify structured data from documents, providing a seamless ORM-like document processing workflow. It supports multiple document loaders, including Tesseract OCR, Azure Form Recog...
Comprehensive Introduction HtmlRAG is an innovative open source project focused on improving the processing of HTML documents in Retrieval Augmented Generation (RAG) systems. The project presents a novel approach that argues that using HTML formatting in RAG systems is more efficient than plain text. The project encompasses a complete data processing flow from the cha...
Comprehensive Introduction ScrapeGraphAI is an innovative Python web scraping library that cleverly combines Large Language Modeling (LLM) and Direct Graph Logic to create a scraping pipeline for websites and local documents. The uniqueness of this tool lies in its perfect balance of simplicity and power: the user simply describes what he/she wants to mention...
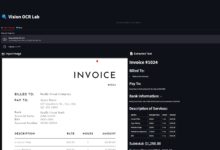
Comprehensive Introduction Vision Parse is a revolutionary document processing tool that cleverly combines state-of-the-art Visual Language Models (Vision Language Models) technology to intelligently convert PDF documents into high-quality Markdown format content. The tool supports a wide range of top-notch visual language models, including o...