Recently, the Qwen team proudly launched a series of Qwen2.5-VL Use Case Notebook ExampleThis is a comprehensive demonstration of the power of native models and APIs. This collection of carefully crafted Notebooks is designed to help developers and users gain a deeper understanding of the Qwen2.5-VL powerful visual understanding and inspire more innovative applications.
Notebook Example: Getting Started with the Qwen2.5-VL
With these detailed Notebook examples, developers are able to Get up to speed and see for yourself how the Qwen 2.5-VL model performs in every task!The Qwen2.5-VL is the perfect solution for the most complex documents. Whether it's dealing with complex document parsing, performing accurate OCR tasks, or performing in-depth video content comprehension, Qwen2.5-VL delivers efficient and accurate feedback that demonstrates its superior performance.
At the same time, the Qwen team is looking forward to the community's feedback and contributions to improve and expand the capabilities of Qwen 2.5-VL, and to work together to promote the development of multimodal technology.
🔗 RELATED:
- GitHub repository. https://github.com/QwenLM/Qwen2.5-VL/tree/main/cookbooks
- Online Experience. https://chat.qwenlm.ai (select Qwen2.5-VL-72B-Instruct model)
- ModelScope model link: https://www.modelscope.cn/collections/Qwen25-VL-58fbb5d31f1d47
- Parsons Brinckerhoff API Interface. https://help.aliyun.com/zh/model-studio/user-guide/vision/

Notebook Examples Explained
01 Computer Use
This Notebook example demonstrates how to utilize Qwen2.5-VL to perform tasks related to computer usage.
Users only need to take a screenshot of the computer desktop and make a query, Qwen2.5-VL model can analyze the content of the screenshot, understand the user's intention, and then generate precise operation commands such as clicking or typing to realize intelligent control of the computer.
👉 Notebook Links. https://github.com/QwenLM/Qwen2.5-VL/blob/main/cookbooks/computer_use.ipynb

02 Spatial Understanding
This Notebook example highlights Qwen2.5-VL's advanced spatial localization capabilities, including accurate object detection and localization of specific targets in an image.
The examples provide insight into how Qwen2.5-VL effectively integrates visual and linguistic understanding to accurately interpret complex scenes and enable advanced spatial reasoning.
👉 Notebook Links. https://github.com/QwenLM/Qwen2.5-VL/blob/main/cookbooks/spatial_understanding.ipynb

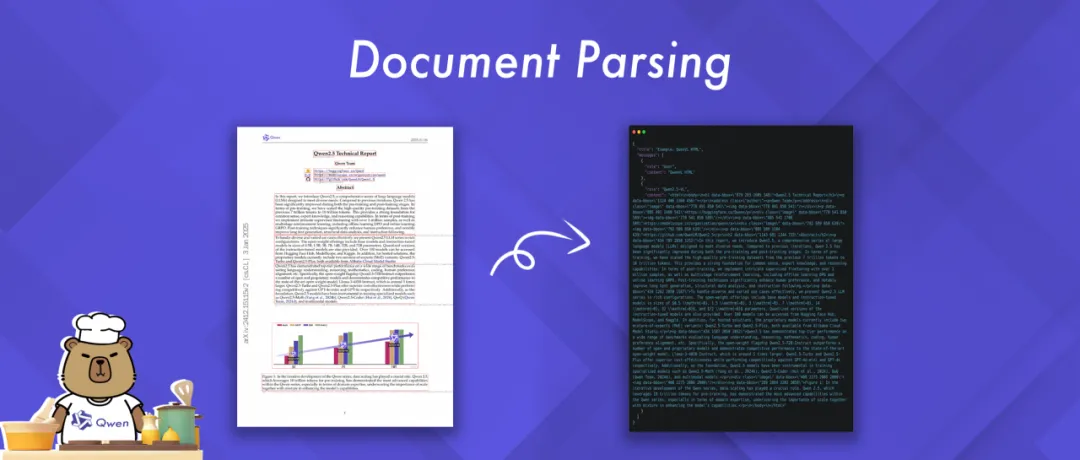
03 Document Parsing
This Notebook example highlights the powerful document parsing capabilities of Qwen2.5-VL. It can process documents in a variety of image formats and output the parsed results in a variety of formats including HTML, JSON, MD and LaTeX.
Of particular interest is Qwen's innovative introduction of a unique QwenVL HTML format. This format contains information about the location of each component in the document, allowing for accurate reconstruction and flexible manipulation of the document.
👉 Notebook Links. https://github.com/QwenLM/Qwen2.5-VL/blob/main/cookbooks/document_parsing.ipynb
04 Mobile Agent (Mobile Device Agent)
This Notebook example demonstrates how to intelligently interact with a mobile device using Qwen2.5-VL's agent capabilities.
The example shows how the Qwen2.5-VL model generates and executes actions based on the user's query and the visual context of the mobile device, enabling convenient control of the mobile device.
👉 Notebook Links. https://github.com/QwenLM/Qwen2.5-VL/blob/main/cookbooks/mobile_agent.ipynb

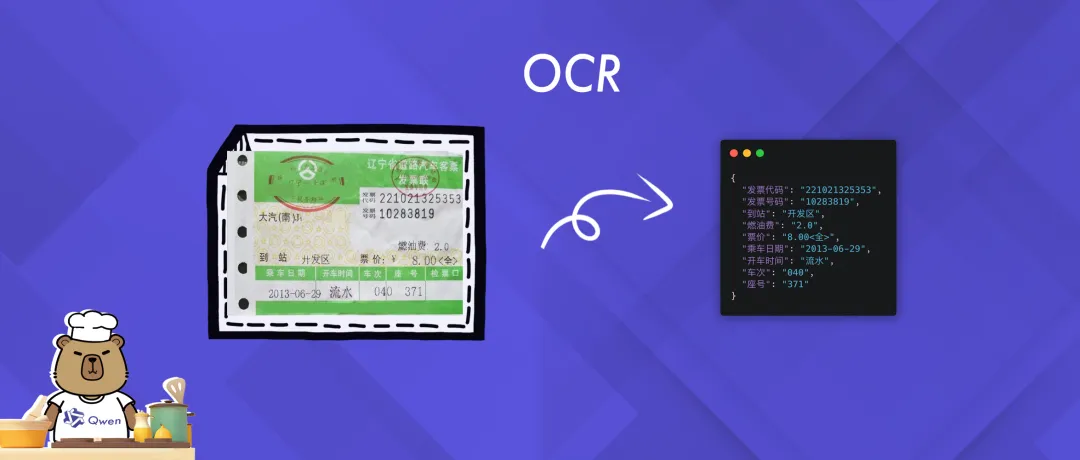
05 OCR (Optical Character Recognition)
This Notebook example focuses on demonstrating the OCR (Optical Character Recognition) capabilities of Qwen2.5-VL, including the accurate extraction and recognition of text information from images.
Through the examples, users can visualize how Qwen2.5-VL can accurately capture and interpret text content in complex scenarios, demonstrating its powerful text recognition capabilities.
👉 Notebook Links. https://github.com/QwenLM/Qwen2.5-VL/blob/main/cookbooks/ocr.ipynb
06 Universal Recognition
This Notebook example demonstrates how to use Qwen2.5-VL for generic object recognition.
The user only needs to provide an image and a query, and the Qwen2.5-VL model can analyze the image, understand the user's query intent, and provide the corresponding recognition results to achieve a comprehensive understanding of the image content.
👉 Notebook Links. https://github.com/QwenLM/Qwen2.5-VL/blob/main/cookbooks/universal_recognition.ipynb

07 Video Understanding
Qwen2.5-VL has powerful long video comprehension capabilities and can handle video content longer than 1 hour. This Notebook example provides an in-depth exploration of the capabilities of the Qwen2.5-VL model for video comprehension tasks.
Qwen2.5-VL is designed to demonstrate its potential in a wide range of video analytics scenarios, from basic OCR (Optical Character Recognition) to complex event detection and content summarization.
👉 Notebook Links. https://github.com/QwenLM/Qwen2.5-VL/blob/main/cookbooks/video_understanding.ipynb

Magic Hitch Best Practices: Free Arithmetic Play Cookbook Example
In the ModelScope Magic Hitch community, users can easily experience these Cookbook examples with free arithmetic.
First, download the Qwen2.5-VL code.
git clone https://github.com/QwenLM/Qwen2.5-VL.git
Use the Model API in Notebook: The MagicBuilder Platform API-Inference provides a free API for the Qwen2.5-VL family of models, which can be used directly by MagicBuilder users via API calls by replacing the base-URL in the Cookbook and filling out the MagicBuilder SDK. Token Ready to go.Detailed Documentation: https://www.modelscope.cn/docs/model-service/API-Inference/intro
from openai import OpenAI
client = OpenAI(
api_key="<MODELSCOPE_SDK_TOKEN>", # ModelScope Token
base_url="https://api-inference.modelscope.cn/v1"
)
response = client.chat.completions.create(
model="Qwen/Qwen2.5-VL-72B-Instruct", # ModelScope Model-Id
messages = [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://modelscope.oss-cn-beijing.aliyuncs.com/demo/images/bird-vl.jpg"}
},
{ "type": "text",
"text": "Count the number of birds in the figure, including those that are only showing their heads. To ensure accuracy, first detect their key points, then give the total number."
},
],
}
],
stream=True
)
Notebook uses a local model: Please select the GPU model.
Conclusion: Welcome to experience and create the future together
In the future, the Qwen team will continue to update and expand these Notebook examples to incorporate more useful features and application scenarios, in an effort to provide developers with more comprehensive solutions. Welcome to visit Qwen2.5-VL's GitHub repository or ModelScope to experience these Notebook examples and share your experience and innovative applications! The Qwen team is looking forward to exploring the possibilities of Qwen2.5-VL with you.