Mixture of Experts and Sparse attention make virtually unlimited contexts possible. It allows the RAG AI Agent to devour entire codebases and documents without contextual limitations.
📌 The Challenge of Long Context Attention
Transformers still face a heavy computational burden when sequences become very large. The default attention model places each token Comparison with all other tokens results in a quadratic increase in computational cost. This overhead becomes a problem when reading entire code bases, multi-chapter documents, or large amounts of legal text.
📌 MoBA
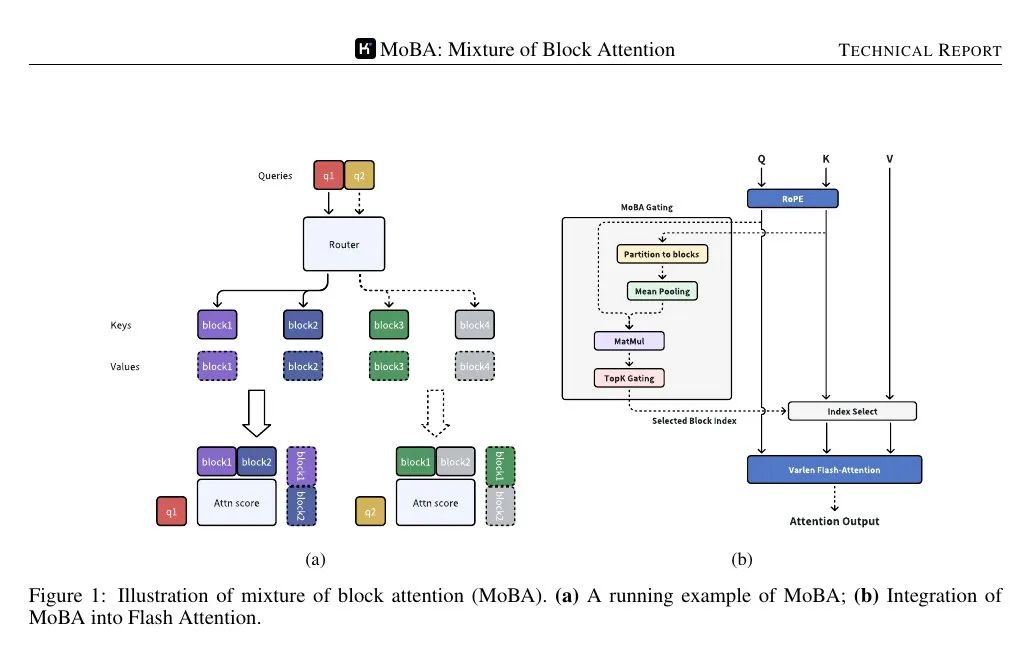
MoBA (Mixture of Block Attention) applies the Mixture of Experts concept to the attention mechanism. The model divides the input sequence into blocks, and then a trainable gating function calculates the correlation score between each query token and each block. Only the highest scoring blocks are used for attention computation, thus avoiding paying attention to each token in the complete sequence.
Blocks are defined by splitting the sequence into equal spans. Each query token looks at the aggregated representation of the keys in each block (e.g., using mean pooling) and then ranks their importance, selecting a few blocks for detailed attention computation. The block containing the query is always selected. Causal masking ensures that tokens do not see future information, maintaining a left-to-right generation order.
📌 Seamless switching between sparse and full attention
MoBA replaces the standard attention mechanism, but does not change the number of parameters. It is similar to the standard Transformer The interfaces are compatible so that sparse and full attention can be switched between different layers or training phases. Some layers may reserve full attention for specific tasks (e.g., supervised fine-tuning), while most layers use MoBA to reduce computational cost.
📌 This applies to larger Transformer stacks, by replacing standard attention calls. The gating mechanism ensures that each query only focuses on a small number of blocks. Causality is handled by filtering out future blocks and applying a local mask within the current block of the query.
📌 The following figure shows that the query is routed to only a few "expert" blocks of keys/values, not to the entire sequence. The gating mechanism assigns each query to the most relevant block, thus reducing the complexity of the attention computation from quadratic to subquadratic.
📌 The gating mechanism computes a correlation score between each query and the cohesive representation of each block. It then selects the top k highest scoring blocks for each query, regardless of how far back in the sequence they are.
Since each query only processes a few blocks, the computation is still subquadratic, but the model can still jump to tokens far away from the current block if the gating score shows a high correlation.
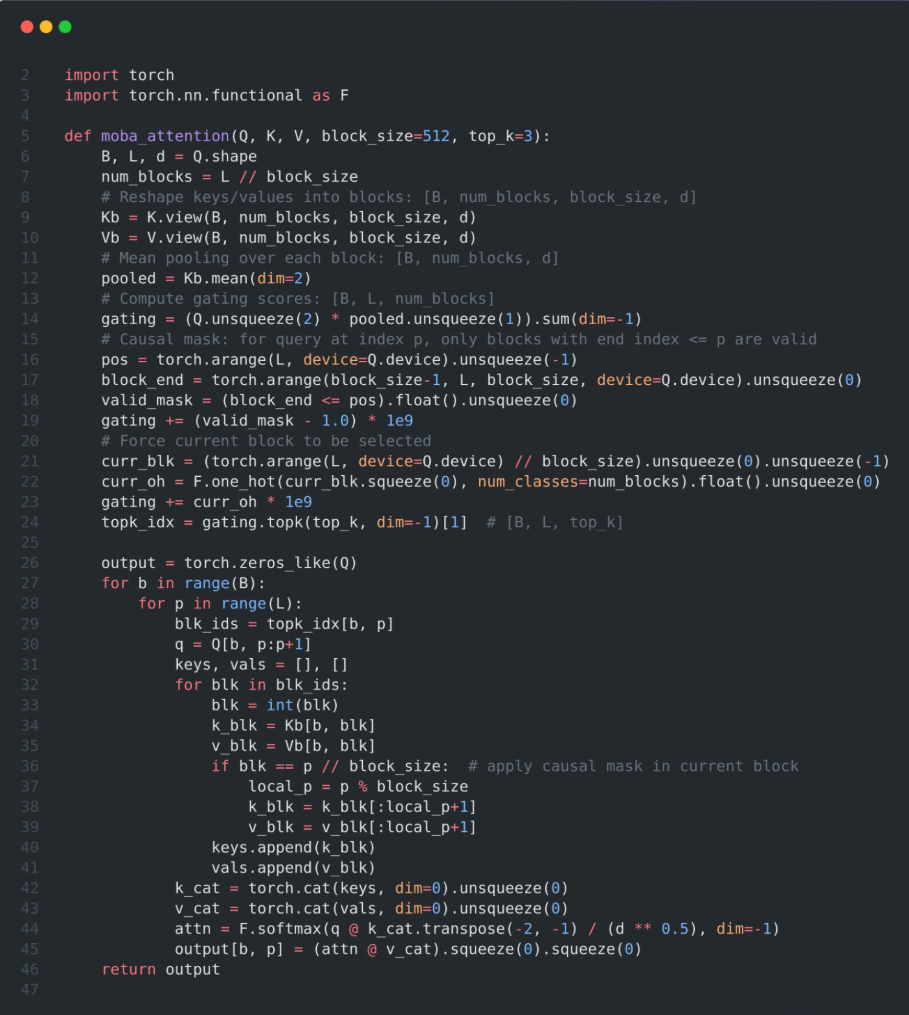
PyTorch Implementation
This pseudo-code divides the keys and values into blocks, computes the mean pooled representation of each block, and computes the gating score (S) by multiplying the query (Q) with the pooled representation.
📌 It then applies causal masks to ensure that queries cannot focus on future blocks, uses the top-k operator to select the most relevant blocks for each query, and organizes the data for efficient attention computation.
📌 FlashAttention were applied to the self-attentive block (current position) and the MoBA-selected block, respectively, and finally the outputs were merged using online softmax.
📌 The end result is a sparse attention mechanism that preserves causal structure and captures long-range dependencies while avoiding the full quadratic computational cost of standard attention.

This code combines mixture-of-experts logic with sparse attention so that each query focuses on only a few blocks.
The gating mechanism scores each block and query and selects the top k "experts", thus reducing the number of key/value comparisons.
This keeps the computational overhead of attention at a subquadratic level, allowing extremely long inputs to be processed without increasing the computational or memory burden.
At the same time, the gating mechanism ensures that the query can still focus on distant tokens when necessary, thus preserving the Transformer's ability to process the global context.
This block- and gating-based strategy is exactly how MoBA implements near-infinite contexts in LLM.
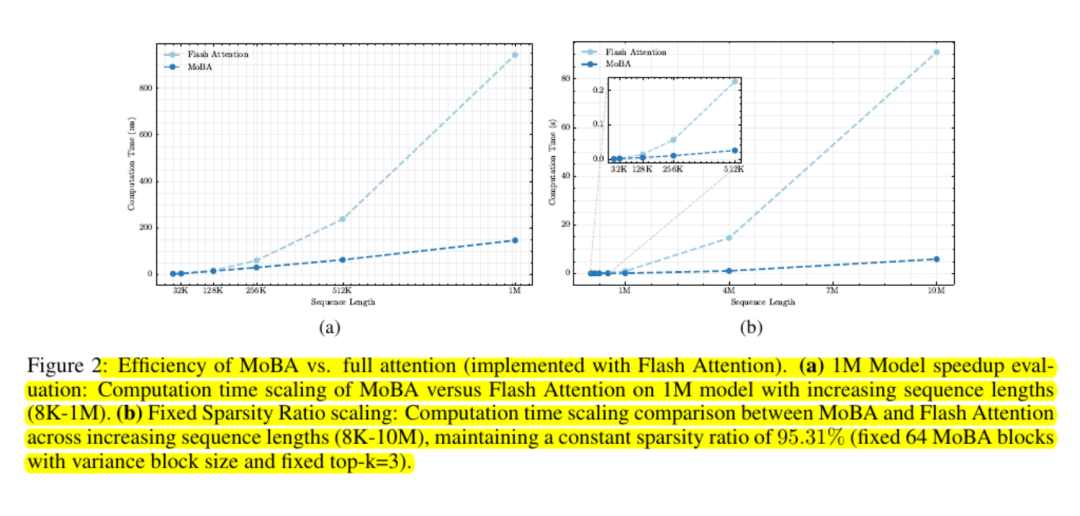
Experimental Observations
Models using MoBA are nearly equivalent to full attention in terms of language modeling loss and downstream task performance. The results are consistent even at context lengths of hundreds of thousands or millions of tokens. Experiments evaluated with "tail tokens" confirm that important long-distance dependencies are still captured when queries identify relevant chunks.
Scalability tests show that its cost curve is subquadratic. The researchers report speedups of up to six times at one million tokens and greater gains outside that range.
MoBA maintains memory-friendliness by avoiding the use of full attention matrices and utilizing standard GPU kernels for block-based computation.
Final Observations
MoBA reduces the attention overhead by a simple idea: let the query learn which blocks are important and ignore all others.
It preserves the standard softmax-based attention interface and avoids enforcing a rigid local model. Many large language models can integrate this mechanism in a plug-and-play fashion.
This makes MoBA very attractive for workloads that need to deal with extremely long contexts, such as scanning an entire codebase or summarizing huge documents, without having to make major changes to the pre-training weights or consuming a lot of retraining overhead.