

With the rapid development of large-scale language modeling (LLM) capabilities, traditional benchmarks such as the MMLU, are gradually showing limitations in distinguishing between top models. It is no longer possible to rely solely on knowledge quizzes or standardized tests to comprehensively measure the nuanced competencies that are critical for models in real-world interactions, such as emotional intelligence, creativity, judgment, and communication skills. It is against this backdrop that a series of programs called EQ-Bench A new evaluation framework has emerged that aims to probe more deeply into the performance of LLM on these complex dimensions.
EQ-Bench and its associated test suite provide a diversified perspective that is no longer limited to simple right and wrong judgments, but focuses on the quality of the model's behavior and decision making in simulated real-world scenarios.
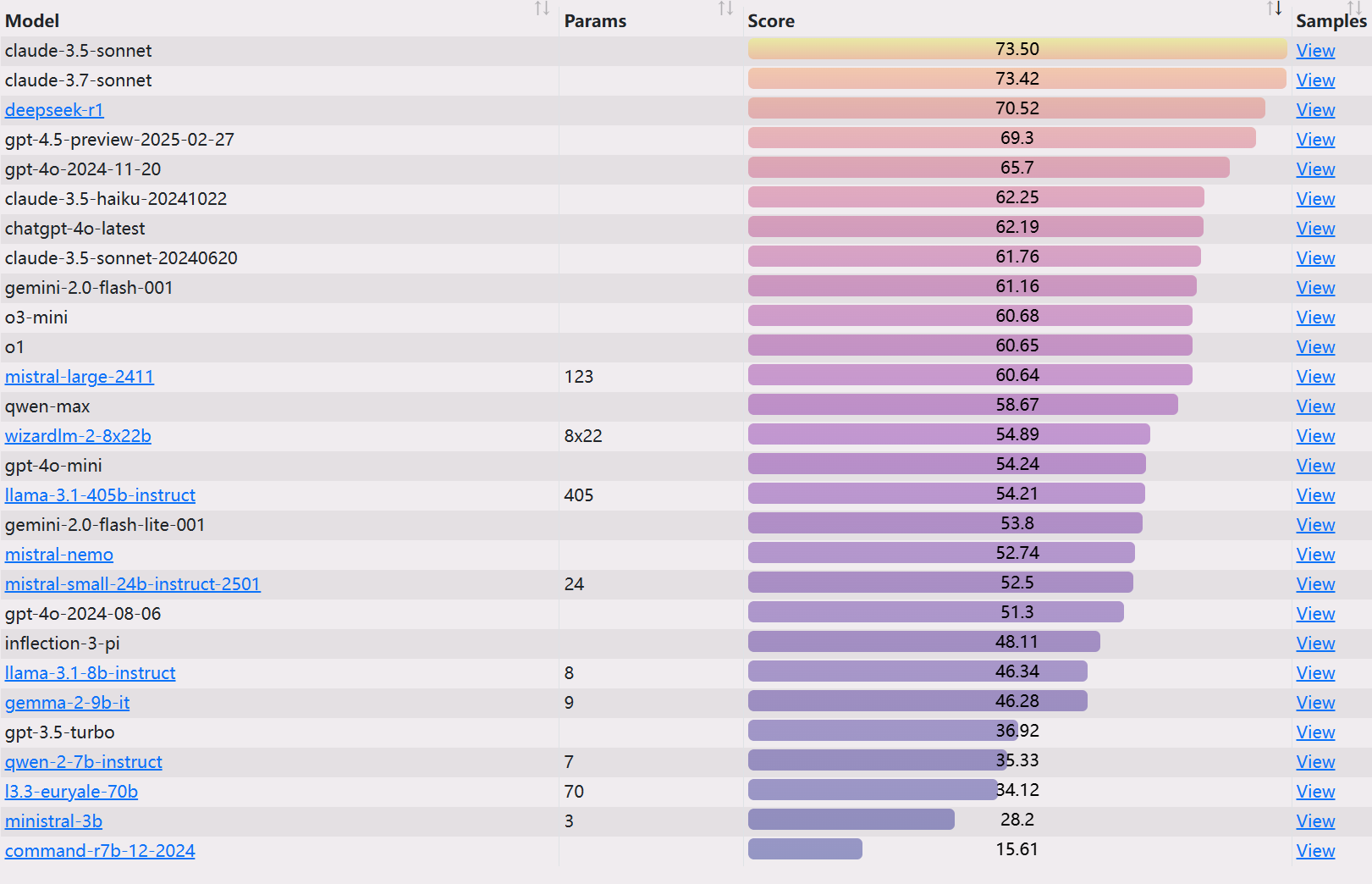
DeepSeek existIllusions abound in knowledge recall reviewsBut the writing creative aspect of the consideration of cost-effective can be said to butcher the list, which is not surprising, and many people actually use the experience is also basically the same.
Submission Channels and Requirements
Currently, the program is only accepting applications that can be submitted through the HuggingFace Publicly available open weighting models for tip testing. Submitters will be asked to provide a link to the model, the optimal cue format and generation configuration, as well as their own test results via email or Twitter. EQ-Bench Scores. The project will validate the results and update the leaderboard. As the project is self-funded and has limited computing resources, submitters need to understand that the validation process may take time.
💙 EQ-Bench 3: Conflict Mediation Capacity Assessment
EQ-Bench 3 is an Emotional Intelligence Benchmark Test that focuses on proactive conflict mediation skills. It assesses the ability of language models to deal with complex emotional issues in challenging and diverse scenarios. The test no longer looks like the initial EQ-Bench That way it only predicts emotional states, but instead directly examines the model's ability to apply active emotional intelligence.
Test Methods.
- Structure. The test consists of multiple rounds of dialog (up to 21 rounds) between the model under test, acting as a conflict mediator, and an "actor" model (currently in use), acting as a customer or disputant.
gemini-2.0-flash-001) to interact. Each scene contains detailed characterizations with specific emotional states and backgrounds. - Assessment criteria. Scoring bases include:
- Basic Emotional Intelligence Skills (Recognizing Emotions, Expressing Empathy)
- Professional skills related to therapy or mediation
- Avoiding serious professional mistakes
- Operating Mechanisms. Benchmarking uses three models: the model under test, the actor model, and the referee model (
Claude-3.7-Sonnet). The referee model is responsible for scoring the performance of the model under test. - Rating. The final score combines ratings across multiple skill areas as well as a count of identified errors and their severity. The referee model will also provide a critical analysis of specific errors, rating them as minor, moderate, or severe, thus accurately identifying the model's shortcomings in real professional conversations.
The Self-Preference Problem in Refereeing Models.
A common concern is that LLM adjudicators may be biased, especially favoring the output of their own models. In order to explore this phenomenon, theEQ-Bench 3 utilization Claude-3.7-Sonnet cap (a poem) gpt-4o-2024-11-20 Two referee models benchmarked the top model.

The results show that, at least between the two referee models, no significant self-preference was observed, and their scores were nearly identical. This provides some confidence in using the LLM as a referee, but the possibility of potential bias still needs to be kept in mind.
The relevant code and full documentation is expected to be available soon in the EQ-Bench Warehouse Release.
💗 EQ-Bench (Legacy): Emotion Recognition Benchmarks
first generation EQ-Bench It is designed to assess the emotional intelligence of language models, which is a critical part of the user experience and has not been explicitly tested by other benchmarks. Its unique advantage is that it is relatively difficult to "brush up" the scores through fine-tuning, making the leaderboard more reflective of the model's true capabilities.
The test is formatted in such a way that the model is asked to read the dialog and assess the strength of the possible emotional reactions of one of the characters (for 4 predefined emotions). The evaluation process does not require the intervention of a referee model, is relatively inexpensive (only 171 questions), and the results are consistent with human preference (Arena ELO) and multi-domain benchmarks (MMLU) showed a strong correlation.
🧙 MAGI-Hard: a subset of high-difficulty discriminatory tests
Given that existing LLM benchmarks face saturated performance and difficulty in distinguishing between top models.MAGI-Hard was presented. It is an example of an example from the MMLU cap (a poem) AGIEval A carefully selected subset of these models is intended to enhance the differentiation of high-capability models. Developers can utilize the provided EleutherAI lm-evaluation-harness Branch to run MAGI Test Sets.
🎨 Creative Writing v3: Upgraded Creative Writing Assessment
The Creative Writing Benchmark has received a v3 release, with major updates including:
- New Tip. The aim is to better differentiate and check for a "sense of atmosphere".
- Hybrid scoring system. Combines the scoring rules (Rubric) and
Eloscoring system, which significantly improves the discrimination of top models and the dynamic range of the test. - Improved sample output page.
Benchmarking Process.
- The model was run for 3 iterations (96 items total) using 32 writing prompts with the temperature set to 0.7 and min_p to 0.1.
- utilization
Claude 3.7 SonnetAs a referee, score the output according to comprehensive scoring rules. - Initial modeling based on bylaw score inference
EloScoring. - Pairwise comparisons with neighboring models on the leaderboard (sparse sampling) are performed, and the winner receives up to 5 "+"s based on multiple criteria scores.
- utilization
GlickoScoring system (modified to take into account the margin of victory for the number of "+'s") CalculationsEloscores, cycling until the rankings stabilize. - Comprehensive comparisons were made with finalized neighboring models to calculate the final rankings
EloThe
Scoring Rules Score vs Elo Score.
Two types of scoring coexist. Rule scoring is where judges independently assess the results of individual model outputs;Elo Scoring, on the other hand, is a relative ranking produced by direct two-by-two confrontation between models. The difference between the two stems from the way they are assessed: pairwise comparisons make it easier for judges to detect nuances, but may also introduce different biases. Scoring criteria also differ between the two models.
Standardization of scores.
For counteract Elo The addition of new models to the system caused an issue with overall score drift, and the leaderboards will be DeepSeek-R1 with a score anchored at 1500.ministral-3b Anchored at 200.
Benchmarking Philosophy.
It is very difficult to judge creative writing reliably and in accordance with human preferences. v3 version makes it more difficult to judge creative writing by introducing pairwise comparisons and Elo Ranking system to improve differentiation. Prompt words are carefully selected to challenge model weaknesses, thus creating a steeper assessment gradient for judges. Tests include humor, romance, spatial awareness, non-traditional first-person perspectives, and other aspects of LLM that are often difficult for LLMs to achieve at the human level.
Cost and Bias Mitigation.
Despite the hybrid scoring system, there is still an API cost of about $10 to run an assessment. Pairwise comparisons introduced new bias challenges that the program attempted to mitigate:
- Length Bias. controlled by truncating the output to 4000 characters.
- Positional bias. Mitigation is achieved by assessing and averaging values in both directions.
- Complex redundancy bias. The grading scale includes penalties for overly showy vocabulary.
- Poetic Obscurity Bias: The The scoring rubric attempts to penalize overly poetic and disjointed prose.
Uncontrolled bias.
- Self-bias. Uncontrolled referees may favor their own output.
- Positive bias. The direction and impact are not yet clear.
- Smut Bias. Referees tend to harshly penalize content that leans toward the erotic.
- Style and Content Bias: The The referee's preferences may differ from user or universal human preferences.
- Slop Bias. Referees may favor certain tropes or styles commonly used by LLM.
Pairwise Judging Prompts Core Criteria. Character authenticity, fun and originality, quality of writing, coherence, how well instructions are followed, world and atmosphere building, avoidance of clichés, avoidance of florid redundancy, avoidance of excessive metaphors.
Limitations.
The assessment results are only a rough indication of writing ability. Creative writing is highly subjective and it is recommended that you make your own judgment in conjunction with reading sample output. This benchmark is not a role-play (RP) assessment, does not test multiple rounds of dialog, and is limited to English writing only.
🎨 Creative Writing (Legacy v2): old Creative Writing Assessment
Older versions (v2) use Claude 3.5 Sonnet acts as a referee, assessing the model's ability to write on a range of prompts. It introduces "Vocab Complexity" and "GPT-Slop" metrics and allows the user to adjust the penalty weights for both via a slider. This version evaluates 24 prompts using scoring rules and reference output, running 10 iterations to improve stability. Similarly, it attempts to mitigate length bias through scoring criteria and a length control slider, but recognizes that bias may still exist.
⚖️ Judgemark V2: Judgement Model Capacity Assessment
Judgemark V2 What is being assessed is the ability of the language models to act as 'judges' themselves, i.e., they are assessing creative writing according to detailed rules. numerical score The ability to do this. This is more complex than a simple paired preference test, requiring the referee model to understand complex instructions, analyze the text, and score up to 36 dimensions of literary quality.
Major improvements in version V2.
- A 6-fold increase in sample size reduces running variance.
- Refined scoring metrics: measures of discriminability (distinguishing between strong and weak texts), stability (consistency in ranking across runs), and relevance to human preferences.
- Raw scores and calibrated scores are available: the latter are made more comparable across referees by standardizing the distribution.
- A perturbation stability test (temp=0.5, top_k=3) was introduced to assess the robustness of the results.
- Simplified standalone code base.
Repeatability Tests. right Llama-3.1-70B-instruct Twenty tests were performed, showing that the standard deviation of the final score was approximately 1.0, indicating some stability in the results.
Judging Tasks. The adjudicator model reads short creative pieces generated by 17 different levels of "writer models" and outputs numerical scores based on long prompts containing both positive and negative criteria (e.g., "detailed character: 0-10", "pretentious: 0-10", the latter being the lower the better). 10", the latter the lower the better). Final Judgemark The score is based on a weighted sum of several calculated metrics such as discrimination, stability, and relevance to human preferences.
This is an extremely challenging task for LLM because it requires meticulous literary criticism skills and the ability to follow multidimensional numerical scoring instructions.
🎤 BuzzBench: a benchmark for humor analysis
BuzzBench By analyzing the British music quiz show Never Mind The Buzzcocks The LLM's ability to understand humor was assessed by introducing jokes to the guests in the show. The task required not only explaining the mechanics of the joke, but also predicting how "funny" the joke would be to the audience and the comedy writer.
Challenging Designs.
- The selection of program jokes increased the difficulty of identifying LLM due to their variety of styles (subtle, adventurous, crude, obscure, obvious, and clever).
- The requirement to predict the "level of amusement" involves modeling human responses.
- Use human-written "golden answers" as a benchmark for judges' scoring.
The benchmark is designed to test theoretical mental understanding and complex knowledge of the mechanics of how jokes work. The referee model was chosen Claude 3.5 SonnetBecause it's in the Judgemark scored high on and appeared to be less likely to favor lengthy, over-analyzed responses. Again, attention needs to be paid to the underlying self-preferences of the referees.
🌍 DiploBench: A Framework for Assessing Strategic Negotiations (Experimental)
DiploBench is a strategy board game utilizing Diplomacy An experimental framework for assessing LLM's strategic negotiation capabilities. The model under test plays Austria-Hungary (Austria-Hungary), a challenging role that requires superior negotiation skills and strategic planning. Models need to communicate with other AI players, make alliances, recognize deception and make tactical decisions.
Key features.
- Full-press. Multiple rounds of negotiations prior to the operation.
- Multi-Intelligent Body Environment. Each country is controlled by an independent LLM.
- Realistic Diplomacy Simulation. Test alignment, negotiation, and deception recognition skills.
- Challenging Opening.
Austria-HungaryIts central location makes it vulnerable but strategic.
The game runs for up to 50 rounds, with 4 rounds of negotiation before each round of action. The framework uniquely tests LLM's capabilities in long-term strategic planning, multi-intelligence negotiation, theoretical mindfulness, and deception detection.
Note: Due to the large variance in the results of the game run, theDiploBench This is still an experimental framework and results should be interpreted with caution.
Concluding thoughts
EQ-Bench series provides a valuable set of tools to push LLM assessment beyond traditional metrics to complex dimensions of competence that are more responsive to the needs of human interaction. While challenges such as referee bias and assessment subjectivity remain, the design and iteration of these benchmarks (e.g., improvements in v2, v3, explicit discussion of bias and attempts to mitigate it) represent an important step in moving the field of LLM assessment to a deeper, more nuanced level. For developers and researchers, these tools not only provide a yardstick for measuring model progress, but also point in the direction of key future enhancements to model capabilities: emotional intelligence, creativity, judgment, and effective communication in complex social interactions.
EQ-Bench 3 Ranking
https://eqbench.com/















