

Large Language Models (LLMs) are evolving rapidly, and their reasoning ability has become a key indicator of their intelligence level. In particular, models with long reasoning capabilities, such as OpenAI's o1,DeepSeek-R1,QwQ-32B cap (a poem) Kimi K1.5 These models have attracted a great deal of attention for their ability to solve complex problems by simulating deep human thought processes. This capability often involves a technique called Inference-Time Scaling, which allows the model to spend more time exploring and correcting as it generates answers.
However, a deeper look reveals that these models often fall into two extremes in their reasoning:Underthinking cap (a poem) OverthinkingThe
not enough food for thought This refers to models that frequently switch ideas in their reasoning, making it difficult to focus on a promising direction for deeper digging. The model output may be filled with words such as "alternatively", "but wait", "let me reconsider", etc. that as shown in the figure below, resulting in a wrong final answer. This phenomenon can be analogized to human inattention, which affects the validity of reasoning.

overthinking Instead, the model generates long and unnecessary "chains of thought" on simple problems. For example, for a basic arithmetic problem such as "2+3=?" For example, for a basic arithmetic problem such as "2+3=?", some models may take hundreds or even thousands of hours. token to iteratively verify or explore multiple solutions, as shown below. While complex thought processes are beneficial for difficult problems, in simple scenarios this certainly results in a waste of computational resources.
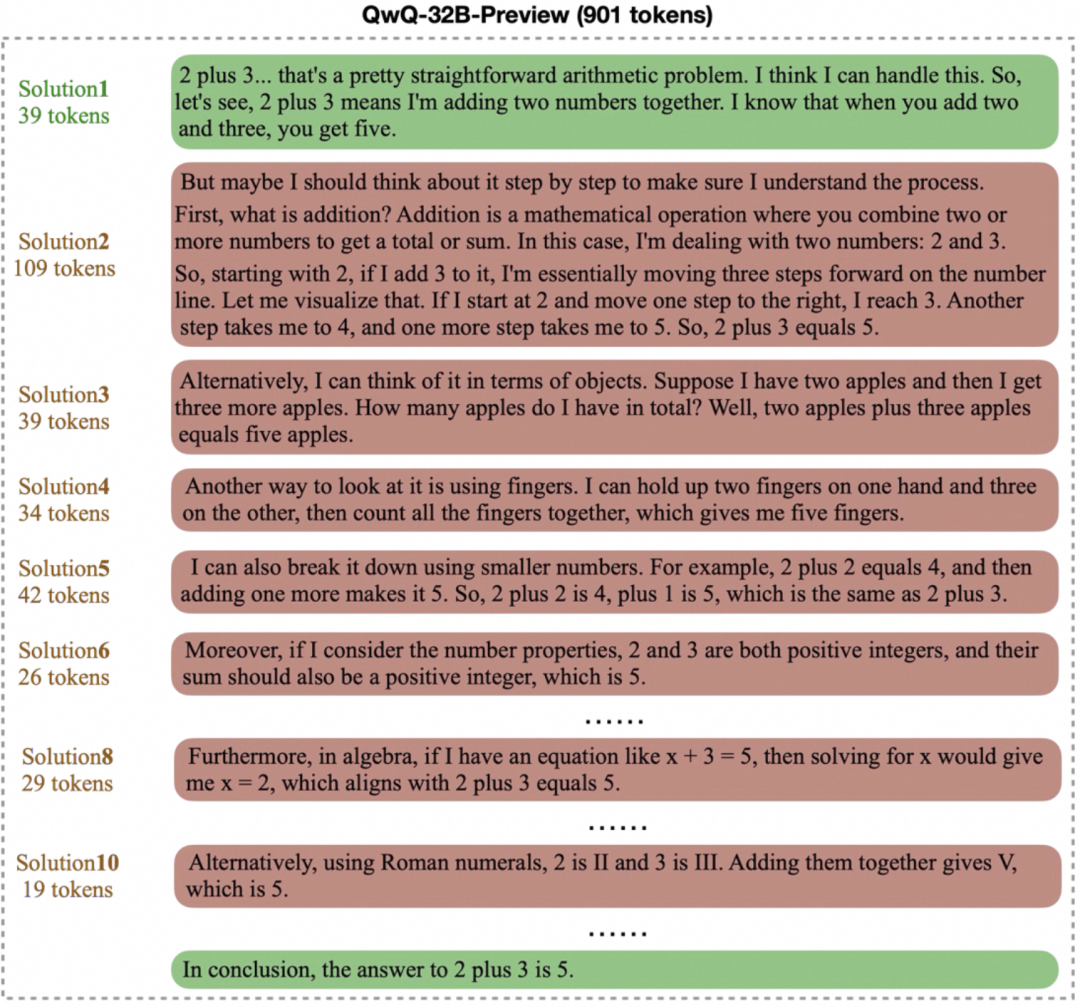
Together, these two questions point to a central challenge: how to improve the efficiency of the model's thinking while ensuring the quality of the answers? An ideal model should be able to find and give the correct answer within the shortest output.
In order to meet this challenge.EvalScope The project introduces EvalThink component, aiming to provide a standardized tool to assess the efficiency of the model's thinking. In this paper, we will use the MATH-500 As an example, the analysis of the dataset includes DeepSeek-R1-Distill-Qwen-7B The performance of a range of reasoning models, including those focusing on six dimensions: model reasoning token Number, first time right token Number, remaining reflections token Numbers,token Efficiency, number of sub-thinking chains and accuracy.
Assessment methodology and process
The evaluation process consists of two main phases: model reasoning evaluation and model thinking efficiency assessment.
Model Reasoning Assessment
The goal of this phase is to obtain the model's performance in MATH-500 Raw inference results and base accuracy on the dataset.MATH-500 The dataset contains 500 math problems of varying difficulty (from Level 1 to Level 5).
Preparing the evaluation environment
Evaluation can be performed by accessing an OpenAI API-compatible reasoning service.EvalScope The framework also supports the use of transformers The library is reviewed locally. For those who need to deal with long thought chains (possibly more than 10,000 token) of the inference model using vLLM maybe ollama Efficient inference frameworks such as these deploy models that can significantly speed up the evaluation process.
in order to DeepSeek-R1-Distill-Qwen-7B As an example, use the vLLM The sample command to deploy the service is as follows:
VLLM_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --served-model-name DeepSeek-R1-Distill-Qwen-7B --trust_remote_code --port 8801
Executive Reasoning Review
pass (a bill or inspection etc) EvalScope (used form a nominal expression) TaskConfig Configure the model API address, name, dataset, batch size, and generation parameters, and then run the evaluation task. The following is sample Python code:
from evalscope import TaskConfig, run_task
task_config = TaskConfig(
api_url='http://0.0.0.0:8801/v1/chat/completions', # 推理服务地址
model='DeepSeek-R1-Distill-Qwen-7B', # 模型名称 (需与部署时一致)
eval_type='service', # 评测类型:服务
datasets=['math_500'], # 数据集
dataset_args={'math_500': {'few_shot_num': 0, 'subset_list': ['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5']}}, # 数据集参数,包含难度级别
eval_batch_size=32, # 并发请求数
generation_config={
'max_tokens': 20000, # 最大生成 token 数,设置较大值防截断
'temperature': 0.6, # 采样温度
'top_p': 0.95, # top-p 采样
'n': 1, # 每个请求生成一个回复
},
)
run_task(task_config)
Once the evaluation is complete, the model will be exported in the MATH-500 Accuracy at each difficulty level (AveragePass@1):
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|-----------------------------|-----------|---------------|----------|-----|--------|---------|
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 1 | 43 | 0.9535 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 2 | 90 | 0.9667 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 3 | 105 | 0.9587 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 4 | 128 | 0.9115 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 5 | 134 | 0.8557 | default |
Model Thinking Efficiency Assessment
After obtaining the inferenceEvalThink components intervene for a more in-depth efficiency analysis. Core assessment metrics include:
- model-based reasoning
tokenReasoning Tokens: The model generates answers in the process of thinking about the chain (as in the O1/R1 model)</think>(what precedes the flag) contained in thetokenTotal amount. - first time right
tokenNumber (First Correct Tokens): From the beginning of the model output to the first occurrence of recognizable correct answer locationstokenQuantity. - Remaining Reflections
tokenReflection Tokens:: From the first correct answer position to the end of the chain of thoughttokenQuantity. This partly reflects the cost of continuing validation or exploration after the model has found an answer. - Num Thought:: By counting specific signifiers (e.g.
alternatively,but wait,let me reconsider) occurrences to estimate how often the model switches ideas. tokenToken Efficiency:: Measuring effective thinkingtokenIndicator of share, calculated as first time righttokenNumber and General ReasoningtokenThe mean of the ratio of the number (counting only samples with correct responses):
Token Efficiency = 1⁄N ∑ First Correct Tokensi⁄Reasoning Tokensi
where N is the number of questions answered correctly. The higher the value, the more "efficient" the model's thinking.
For the purpose of determining "first time right token number," an assessment framework that draws on the ProcessBench The idea is to use a separate "Judge" model, for example Qwen2.5-72B-Instruct, to check the inference steps and locate the position where the correct answer occurs earliest. The implementation involves decomposing the model output into steps (strategy optional: by a specific separator) separatorPress keyword keywords, or rewritten and sliced with the aid of the LLM llm), and then let the referee model the judgment on a case-by-case basis.
Sample code for performing a think efficiency assessment:
from evalscope.third_party.thinkbench import run_task
# 配置裁判模型服务
judge_config = dict(
api_key='EMPTY',
base_url='http://0.0.0.0:8801/v1', # 假设裁判模型也部署在此服务
model_name='Qwen2.5-72B-Instruct',
)
# 配置待评估模型的信息
model_config = dict(
report_path='./outputs/2025xxxx', # 上一步推理结果路径
model_name='DeepSeek-R1-Distill-Qwen-7B', # 模型名称
tokenizer_path='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', # Tokenizer 路径,用于计算 token
dataset_name='math_500', # 数据集名称
subsets=['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5'], # 数据集子集
split_strategies='separator', # 推理步骤分割策略
judge_config=judge_config
)
max_tokens = 20000 # 过滤 token 过长的输出
count = 200 # 每个子集抽样数量,加速评测
# 运行思考效率评估
run_task(model_config, output_dir='outputs', max_tokens=max_tokens, count=count)
The assessment results will detail the model's six dimensional metrics at each difficulty level.
Analysis and discussion of results
The research team used EvalThink right DeepSeek-R1-Distill-Qwen-7B and several other models (QwQ-32B,QwQ-32B-Preview,DeepSeek-R1,DeepSeek-R1-Distill-Qwen-32B) was evaluated and a non-inferential math-specific model was added Qwen2.5-Math-7B-Instruct As a comparison.
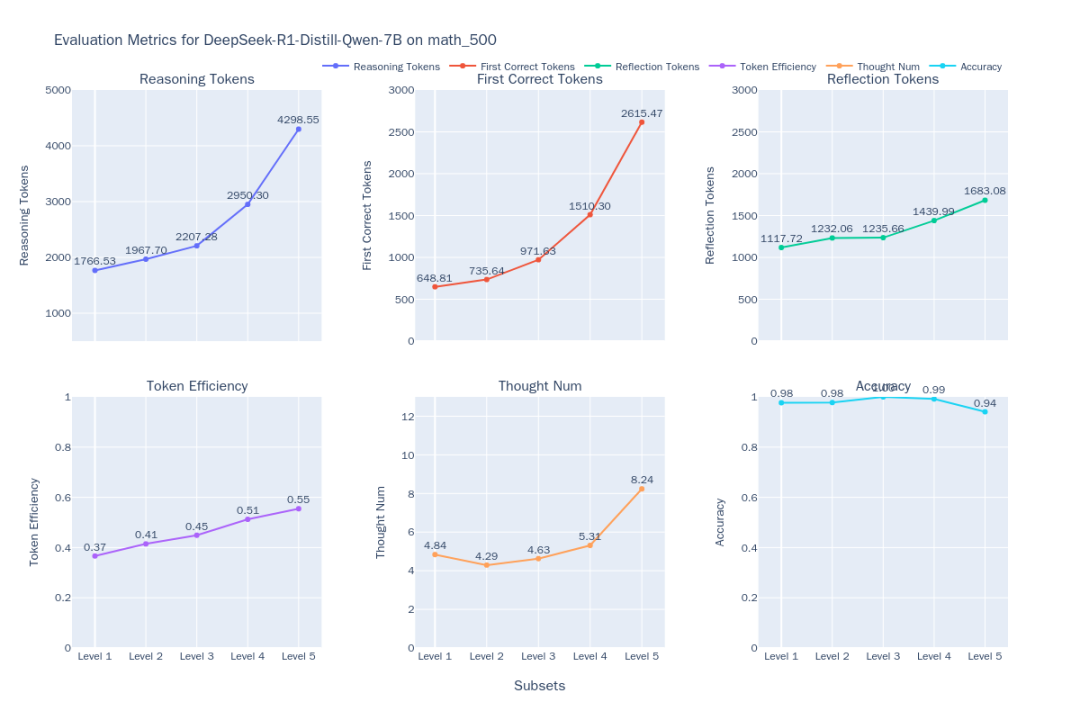
Figure 1: DeepSeek-R1-Distill-Qwen-7B Thinking Efficiency Indicator
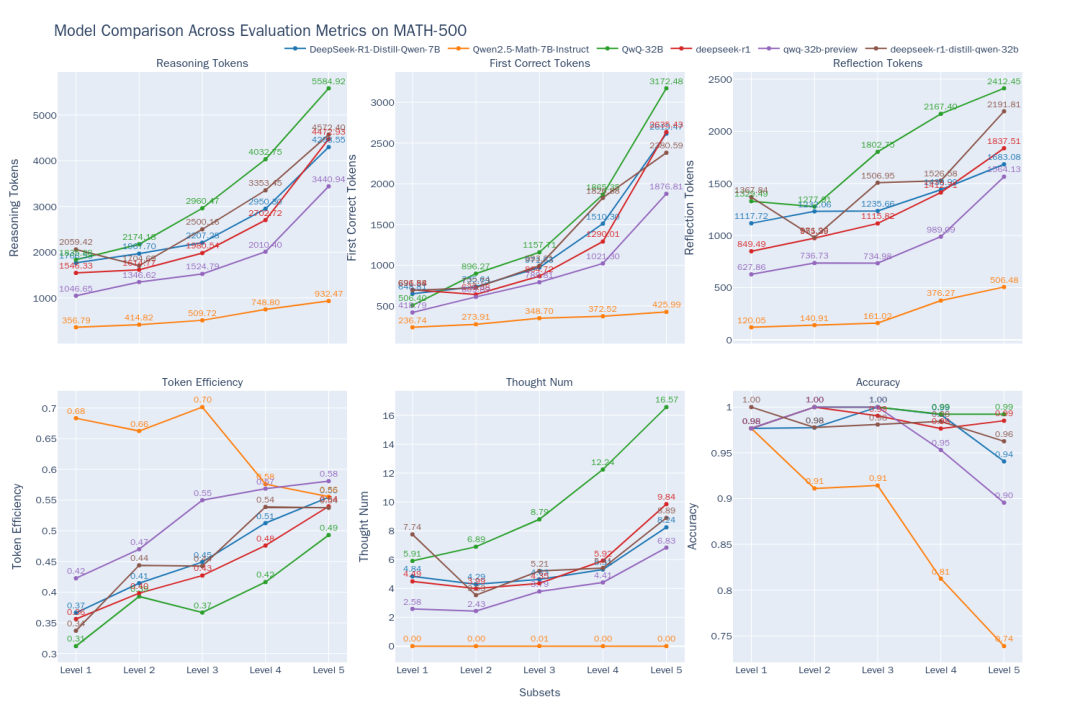
Figure 2: Comparison of the thinking efficiency of the 6 models at different difficulty levels of MATH-500
The following trends can be observed from the comparison results (Figure 2):
- Difficulty-Performance Correlation: As the difficulty of the problem (Level 1 to Level 5) increases, the accuracy of most models decreases. However.
QwQ-32Bcap (a poem)DeepSeek-R1excelling in difficult problems.QwQ-32Bhighest accuracy at Level 5. At the same time, the output of all modelstokenThe numbers all get longer as the difficulty increases, which is consistent with the expectation of "reasoning while expanding" - the model needs to "think" more to solve the puzzle. - O1/R1 Class Reasoning Model Properties:
- Efficiency gains:: Interestingly, for
DeepSeek-R1cap (a poem)QwQ-32BThis type of inference model, although the output becomes longer, thetokenEfficiency (effective)tokenpercentage) also increases with difficulty (DeepSeek-R1From 36% to 54%.QwQ-32B(from 31% to 49%). This suggests that their extra thinking on difficult problems is more "cost-effective", while on simple problems there may be some "over-thinking", e.g. unnecessary iterations.QwQ-32B(used form a nominal expression)tokenConsumption is high overall, which may be one of the reasons it can maintain a high accuracy rate at Level 5, but it also hints at a tendency to overthink things. - Paths of thought:
DeepSeekThe number of sub-thinking chains for the series models is relatively stable at Levels 1-4, but increases dramatically at the most difficult Level 5, suggesting that Level 5 poses a significant challenge for these models and requires multiple attempts. In contrast.QwQ-32BThe series model has smoother growth in the number of thought chains, reflecting different coping strategies.
- Efficiency gains:: Interestingly, for
- Non-inferential model limitations:: Mathematics-specific models
Qwen2.5-Math-7B-InstructThe accuracy drops dramatically when dealing with difficult problems and its outputtokenThe number is much lower than that of inference models (about one-third). This suggests that, while such models may be faster and less resource-intensive on common problems, the lack of deeper thought processes gives them a significant performance "ceiling" on complex reasoning tasks.
Methodological considerations and limitations
in application EvalThink There are a few things to keep in mind when conducting an assessment:
- Definition of indicators:
- proposed in this paper
tokenEfficiency indicators, which draw on the concepts of "overthinking" and "underthinking" in the literature, focus ontokenQuantity, a simplified measure of the thinking process, fails to capture the full details of the quality of thinking. - The calculation of the number of subthinking chains relies on predefined keywords, and the list of keywords may need to be adjusted for different models to accurately reflect their thinking patterns.
- proposed in this paper
- Scope of application:
- The current metrics are mainly validated on mathematical reasoning datasets, and their effectiveness in other scenarios such as open quizzing and idea generation is yet to be tested.
- cater
DeepSeek-R1-Distill-Qwen-7Bis based on a mathematical model of distillation of theMATH-500There may be a natural advantage in performance on the dataset. Evaluation results need to be interpreted in the context of the model.
- Refereeing Model Dependency:
tokenThe computation of efficiency relies on the Judge Model (JM) to accurately determine the correctness of reasoning steps. AsProcessBench4What the study points out is that this is a challenging task for existing models and usually requires highly capable models to be up to the task.- Referee modeling miscues can have a direct impact on
tokenaccuracy of the efficiency metrics, so choosing the right referee model is critical.
In a nutshell.EvalThink A set of frameworks and metrics for quantitatively assessing the efficiency of LLM thinking is provided, revealing the accuracy of different models in..,token tradeoff between consumption and depth of thought. These findings are useful for guiding model training (e.g. GRPO and SFT), it is informative to develop next-generation models that are more efficient and can adaptively adjust the depth of thinking according to the difficulty of the problem.















