Allgemeine Einführung
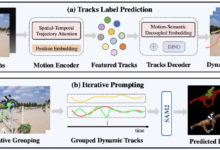
VideoMind ist ein quelloffenes, multimodales KI-Tool, das sich auf Schlussfolgerungen, Fragen und Antworten sowie die Erstellung von Zusammenfassungen für lange Videos konzentriert. Entwickelt wurde es von Ye Liu von der Polytechnischen Universität Hongkong und einem Team des Show Lab an der Nationalen Universität von Singapur. Das Tool ahmt die Art und Weise nach, wie Menschen Videos verstehen, indem es die Aufgabe in Schritte wie Planung, Positionierung, Verifizierung und Beantwortung unterteilt, um das Problem Schritt für Schritt zu lösen. VideoMind veröffentlicht den Code, das Modell und den Datensatz offiziell am 21. März 2024, und der technische Bericht wird am 17. März 2025 aktualisiert.VideoMind ist auf GitHub oder über GitHub verfügbar. Nutzer können über GitHub oder Hugging Face auf die Ressourcen zugreifen.
Das Projekt extrahiert nicht Audio zu Text, um den Inhalt zu verstehen, sondern rein grafisch und nach dem Zeitstempel, um genau zu verstehen, den Inhalt des Videos, kann für die automatische Video-Feinabstimmung, Lehr-Szenarien verwendet werden, sehr praktisch!

Erfahrung: https://huggingface.co/spaces/yeliudev/VideoMind-2B
Funktionsliste
- Zeitliches Targeting bei langen Videos: Finden Sie den Zeitraum im Video, der für die Frage relevant ist.
- Video-Q&A-Funktion: Extrahiert präzise Antworten aus Videos auf der Grundlage von Benutzerfragen.
- Erstellung von Videozusammenfassungen: Destillieren Sie die wichtigsten Videoinhalte, um einen prägnanten Überblick zu erstellen.
- Multimodaler Agentenrahmen: umfasst Planer, Lokalisierer, Validierer und Responder, die bei Aufgaben zusammenarbeiten.
- Chain-of-LoRA-Technologie: Multifunktionalität mit einem einzigen Modell und reduziertem Ressourcenverbrauch.
- Unterstützung verschiedener Hardware: läuft auf NVIDIA GPUs oder Ascend NPUs.
- Effiziente Trainingsunterstützung: Integration von DeepSpeed, LoRA, FlashAttention2 und anderen Technologien.
- Online-Demo: Erleben Sie die Funktionalität schnell über die Gradio-Schnittstelle.
Hilfe verwenden
VideoMind ist ein Open-Source-Projekt. Benutzer müssen den Code herunterladen und die Umgebung konfigurieren, um es zu verwenden. Im Folgenden finden Sie eine detaillierte Anleitung zur Installation und Nutzung der Funktionen.
Einbauverfahren
- Code-Repository klonen
Führen Sie den folgenden Befehl im Terminal aus, um den VideoMind-Quellcode herunterzuladen:
git clone https://github.com/yeliudev/VideoMind.git
Rufen Sie den Projektkatalog auf:
cd VideoMind
- Einrichten der Python-Umgebung
Erstellen Sie eine virtuelle Umgebung mit conda (Python 3.12 empfohlen):
conda create -n videomind python=3.12 -y
conda activate videomind
- Installation von abhängigen Bibliotheken
Führen Sie den folgenden Befehl aus, um die erforderlichen Abhängigkeiten zu installieren:
pip install -r requirements.txt
Für ein effizientes Training installieren Sie DeepSpeed:
pip install deepspeed
- Modelle und Datensätze herunterladen
- Besuchen Sie https://huggingface.co/collections/yeliudev/videomind-67dd41f42c57f0e7433afb36, um bereits trainierte Modelle herunterzuladen (z. B.
VideoMind-2B), entpacken Sie es in das VerzeichnismodelsMappe. - Die Datensätze sind unter https://huggingface.co/datasets/yeliudev/VideoMind-Dataset下载 verfügbar und umfassen 27 Videodatensätze und VideoMind-SFT (481K Trainingsdaten), die in der
dataKatalog.
- Probeaufbau
Führen Sie das Testskript aus, um sicherzustellen, dass die Umgebung korrekt ist:
python test.py
Hauptfunktionen
1. zeitliche Positionierung von Videos in langer Form
- Das Video vorbereiten: Legen Sie die Videodatei im Ordner
data/videosKatalog, unterstützt MP4, AVI und andere Formate. - Befehl ausführen::
python run_grounding.py --video_path data/videos/sample.mp4 --query "找到讨论AI的部分"
- Ergebnis AusgabeGibt den Zeitbereich zurück, z. B. "00:05:12 - 00:07:34".
2. ein Video-Quiz
- Probleme bei der Eingabe: Neu
query.txtSchreiben Sie Fragen auf, z. B. "Wer ist die Hauptfigur in dem Video?". . - einen Befehl ausführen::
python run_qa.py --video_path data/videos/sample.mp4 --query_file query.txt
- Antworten erhaltenDas Terminal zeigt Ergebnisse wie "Die Hauptfigur ist Li Ming" an.
3. die Erstellung von Videozusammenfassungen
- Befehl ausführen::
python run_summary.py --video_path data/videos/sample.mp4
- Zusammenfassung anzeigenDie Ergebnisse werden gespeichert als
summary.txtZum Beispiel: "Das Video stellt eine wissenschaftliche und technische Vorlesung vor".
Featured Function Bedienung
Chain-of-LoRA-Technologie
- VideoMind verwendet ein einziges Modell für den Rollenwechsel über LoRA-Adapter. Die Konfigurationsdateien sind im Verzeichnis
config/lora.yamlEinstellbarrankParameterverstärkende Wirkung:
lora:
rank: 16
Online-Demo
- Eine lokale Installation ist nicht erforderlich. Sie können also https://huggingface.co/spaces/yeliudev/VideoMind-2B besuchen, ein Video hochladen und Ihre Frage eingeben, um die Funktionalität direkt zu erleben. Für weitere Informationen, siehe
docs/DEMO.md.
Ausbildungsmodelle
- Daten vorbereiten: Verwendung
VideoMind-SFToder 27 andere Datensätze, die in derdataKatalog. - Grundlagentraining: Laufen:
python train.py --dataset data/VideoMind-SFT --model models/VideoMind-2B
- Ausbildung überwachenUnterstützung für Tensorboard oder Wandb zur Fortschrittsanzeige, siehe Konfiguration für Details
docs/TRAIN.md.
caveat
- Wenn die Videodatei zu groß ist, empfiehlt es sich, sie in Segmenten zu verarbeiten, um einen Speicherüberlauf zu vermeiden.
- Ascend NPU-Benutzer müssen den Ascend-Treiber installieren und Parameter hinzufügen, wenn er läuft.
--device ascend. - Weitere Informationen zur Inbetriebnahme finden Sie unter
docs/EVAL.mdeinschließlich Benchmarking-Leitlinien.
Mit diesen Schritten können Benutzer VideoMind schnell installieren und verwenden, um lange Videoaufgaben zu erledigen.
Anwendungsszenario
- Analyse des Videoinhalts
Benutzer können mit VideoMind lange YouTube-Videos analysieren, wichtige Clips finden oder Zusammenfassungen erstellen, um Zeit beim Ansehen zu sparen. - Bildung und Forschung
Studenten oder Forscher, die mit Vorlesungsvideos arbeiten, können fragen: "Welche Algorithmen wurden behandelt?" und erhalten die Antworten, wodurch die Notizen effizienter organisiert werden. - Inhaltliche Prüfung
Plattformadministratoren verwenden es, um zu überprüfen, ob die Videoinhalte konform sind, z. B. um zu prüfen, ob es sich um anstößige Clips handelt.
QA
- Wie lange kann VideoMind ein Video bearbeiten?
Je nach Hardware können 16 GB RAM eine Stunde Video verarbeiten, und 32 GB unterstützen längere Inhalte. - Was ist der Unterschied zwischen einer Online-Demo und einer lokalen Bereitstellung?
Die Online-Version erfordert keine Installation, hat aber nur einen begrenzten Funktionsumfang; die lokale Version unterstützt benutzerdefinierte Schulungen und die Bearbeitung großer Datenmengen. - Wie werden die Datensätze verwendet?
27 Datensätze wurden für das Training und die Auswertung verwendet, und VideoMind-SFT war für die Optimierung der Modelle geeignet, wie unter https://huggingface.co/datasets/yeliudev/VideoMind-Dataset beschrieben.