Allgemeine Einführung Aana SDK ist ein von Mobius Labs entwickeltes Open-Source-Framework, benannt nach dem Malayalam-Wort ആന (Elefant). Es hilft Entwicklern, multimodale KI-Modelle schnell einzusetzen und zu verwalten und unterstützt die Verarbeitung von Text, Bildern, Audio, Video und anderen Daten.
Allgemeine Einführung BrowserAI ist ein Open-Source-Tool, mit dem Benutzer native KI-Modelle direkt im Browser ausführen können. Es wurde von dem Cloud-Code-AI-Team entwickelt und unterstützt Sprachmodelle wie Llama, DeepSeek und Kokoro. Benutzer brauchen keinen Server oder eine komplexe Einrichtung, um Text zu...
Aktivieren Sie Builder intelligenten Programmiermodus, unbegrenzte Nutzung von DeepSeek-R1 und DeepSeek-V3, reibungslosere Erfahrung als die Übersee-Version. Geben Sie einfach die chinesischen Befehle, keine Programmierkenntnisse können auch Null-Schwelle, um ihre eigenen Anwendungen zu schreiben.
Umfassende Einführung LitServe ist eine Open-Source-KI-Modell-Service-Engine von Lightning AI, die auf FastAPI aufbaut und sich auf die schnelle Bereitstellung von Inferenzdiensten für Allzweck-KI-Modelle konzentriert. Es unterstützt ein breites Feld klassischer maschineller Lernmodelle von großen Sprachmodellen (LLMs), visuellen Modellen, Audiomodellen bis hin zu...
Umfassende Einführung Nexa AI ist eine Plattform, die sich auf multimodale KI-Lösungen konzentriert, die lokal ausgeführt werden. Sie bietet eine breite Palette von KI-Modellen, einschließlich Natural Language Processing (NLP), Computer Vision, Spracherkennung und -generierung (ASR und TTS), die alle lokal auf Geräten ausgeführt werden können, ohne auf die Cloud angewiesen zu sein...
Umfassende Einführung vLLM ist eine durchsatzstarke und speichereffiziente Reasoning- und Service-Engine, die für Large Language Modelling (LLM) entwickelt wurde. Ursprünglich vom Sky Computing Lab an der UC Berkeley entwickelt, ist es zu einem Gemeinschaftsprojekt geworden, das von Wissenschaft und Industrie getragen wird. vLLM zielt darauf ab,...
Allgemeine Einführung Transformers.js ist eine JavaScript-Bibliothek, die von Hugging Face zur Verfügung gestellt wird. Sie wurde entwickelt, um hochmoderne Modelle für maschinelles Lernen direkt im Browser auszuführen, ohne Serverunterstützung. Die Bibliothek ist vergleichbar mit Hugging Face's Transformers-Bibliothek für Python und unterstützt eine Vielzahl von...
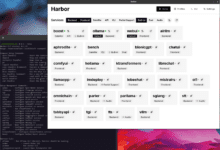
Umfassende Einführung Harbor ist ein revolutionäres containerisiertes LLM-Toolset, das sich auf die Vereinfachung der Bereitstellung und Verwaltung von lokalen KI-Entwicklungsumgebungen konzentriert. Es ermöglicht Entwicklern den Start und die Verwaltung aller KI-Dienste, einschließlich LLM-Backends, API-Schnittstellen, Front-End-Schnittstellen usw. mit einem einzigen Klick über eine übersichtliche Befehlszeilenschnittstelle (CLI) und eine Begleit-App...
Umfassende Einführung Xorbits Inference (kurz: Xinference) ist eine leistungsstarke und vielseitige Bibliothek, die sich auf die verteilte Bereitstellung von Sprachmodellen, Spracherkennungsmodellen und multimodalen Modellen konzentriert. Mit Xorbits Inference können Benutzer ihre eigenen Modelle oder eingebaute Vorgängermodelle einfach einsetzen und...
Umfassende Einführung Die AI Dev Gallery ist eine Anwendung für KI-Entwicklungstools von Microsoft (derzeit in der öffentlichen Vorschau), die für Windows-Entwickler gedacht ist. Sie bietet eine umfassende Plattform, die Entwicklern hilft, KI-Funktionen einfach in ihre Windows-Anwendungen zu integrieren. Das bemerkenswerteste Merkmal des Tools ist die...
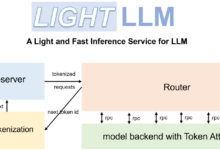
Umfassende Einführung LightLLM ist ein Python-basiertes Large Language Model (LLM) Inferenz- und Service-Framework, das für sein schlankes Design, seine einfache Erweiterbarkeit und seine effiziente Leistung bekannt ist. Das Framework nutzt eine Vielzahl bekannter Open-Source-Implementierungen, darunter FasterTransformer, TGI, vLLM und FlashAttention ...
Allgemeine Einführung Transformers.js ist eine JavaScript-Bibliothek, die von Hugging Face entwickelt wurde, um Benutzern die Möglichkeit zu geben, modernste Machine-Learning-Modelle direkt im Browser ohne Serverunterstützung auszuführen. Die Bibliothek ist funktional äquivalent zu Hugging Face's Transformers-Bibliothek für Python...
Umfassende Einführung GLM-Edge ist eine Reihe von großen Sprachmodellen und multimodalen Verständigungsmodellen, die von der Tsinghua-Universität (Smart Spectrum Light Language) für Endgeräte entwickelt wurden. Diese Modelle umfassen GLM-Edge-1.5B-Chat, GLM-Edge-4B-Chat, GLM-Edge-V-2B und GLM-Edge-V-5B, die sich für Mobiltelefone,...
Allgemeine Einführung Exo ist ein Open-Source-Projekt, das darauf abzielt, einen eigenen KI-Cluster auf alltäglichen Geräten (z.B. iPhone, iPad, Android, Mac, Linux, etc.) zu betreiben. Durch dynamische Modellpartitionierung und automatische Geräteerkennung ist Exo in der Lage, mehrere Geräte in einer einzigen leistungsstarken GPU zu vereinen und mehrere Modelle wie LLaMA, Mis...
Allgemeine Einführung LocalAI ist eine Open-Source-Alternative für lokale KI, die API-Schnittstellen bietet, die mit OpenAI, Claude und anderen kompatibel sind. Es unterstützt den Betrieb auf Consumer-Hardware, benötigt keine GPU und ist in der Lage, eine breite Palette von Aufgaben wie Text, Audio, Video, Bilderzeugung und Sprache cloning.LocalAI von Ettore ...
Allgemeine Einführung llamafile ist ein Tool des Mozilla Builders-Projekts, das die Bereitstellung und den Betrieb des Large Language Model (LLM) vereinfachen soll. Durch die Kombination von llama.cpp mit Cosmopolitan Libc reduziert llamafile den komplexen LLM-Einsatzprozess auf eine einzige ausführbare Datei,...
Allgemeine Einführung Petals ist ein Open-Source-Projekt, das vom BigScience Workshop entwickelt wurde, um große Sprachmodelle (Large Language Models, LLMs) über einen verteilten Rechenansatz auszuführen. Benutzer können LLMs zu Hause mit Consumer-GPUs oder Google Colab, wie Llama 3.1, Mixtral, F...
Umfassende Einführung Die Aphrodite Engine ist die offizielle Backend-Engine für PygmalionAI. Sie wurde entwickelt, um einen Inferenz-Endpunkt für PygmalionAI-Sites bereitzustellen und die schnelle Bereitstellung von Hugging-Face-kompatiblen Modellen zu unterstützen. Die Engine nutzt die Paged Attention-Technologie von vLLM für effizientes K/V-Management und kontinuierliche Stapelverarbeitung,...
Allgemeine Einführung llama.cpp ist eine in reinem C/C++ implementierte Bibliothek, die den Inferenzprozess für Large Language Models (LLMs) vereinfachen soll. Sie unterstützt eine breite Palette von Hardware-Plattformen, einschließlich Apple Silicon, NVIDIA GPUs und AMD GPUs, und bietet eine Vielzahl von Quantisierungsoptionen, um die Inferenzgeschwindigkeit zu verbessern und den Speicherverbrauch zu reduzieren. Das Projekt ...
Allgemeine Einführung Hyperspace ist ein innovativer generativer Browser (aiOS), der auf dem weltweit größten Peer-to-Peer-KI-Netzwerk basiert und den Nutzern leistungsstarke Werkzeuge für tiefgreifende Recherchen und Analysen zur Verfügung stellen soll. Durch die Integration eines breiten Spektrums von KI-Modellen und Datenquellen ermöglicht Hyperspace den Nutzern die schnelle Generierung von Informationsnetzwerken unter Verwendung hochwertiger Quellen...
Sie können keine AI-Tools finden? Versuchen Sie es hier!
Geben Sie einfach das Schlüsselwort Barrierefreiheit Bing-SucheDer Bereich KI-Tools auf dieser Website bietet eine schnelle und einfache Möglichkeit, alle KI-Tools auf dieser Website zu finden.