

Mit der rasanten Entwicklung groß angelegter Sprachmodellierungsfunktionen (LLM) werden traditionelle Benchmarks wie der MMLUDie Grenzen der Unterscheidung zwischen Spitzenmodellen werden allmählich deutlich. Es ist nicht mehr möglich, sich allein auf Wissensquizze oder standardisierte Tests zu verlassen, um die subtilen Kompetenzen umfassend zu messen, die für Models in realen Interaktionen entscheidend sind, wie z. B. emotionale Intelligenz, Kreativität, Urteilsvermögen und Kommunikationsfähigkeit. Vor diesem Hintergrund wurde eine Reihe von Forschungsprogrammen mit der Bezeichnung EQ-Bench Es wurde ein neuer Bewertungsrahmen entwickelt, der darauf abzielt, die Leistung von LLM in diesen komplexen Bereichen genauer zu untersuchen.
EQ-Bench und die dazugehörige Testsuite bieten eine vielfältige Perspektive, die sich nicht mehr auf einfache Richtig-oder-Falsch-Urteile beschränkt, sondern sich auf die Qualität des Verhaltens und der Entscheidungsfindung des Modells in simulierten realen Szenarien konzentriert.
DeepSeek existierenIllusionen bei der Überprüfung des Wissensabrufs sind weit verbreitetAber das Schreiben kreativen Aspekt der Betrachtung des Preis-Leistungs-Verhältnis kann gesagt werden, um die Liste, die nicht überraschend ist, und viele Menschen tatsächlich nutzen die Erfahrung ist auch im Grunde die gleichen schlachten.
Einreichungskanäle und Anforderungen
Derzeit akzeptiert das Programm nur Bewerbungen, die über das HuggingFace Öffentlich verfügbare offene Gewichtungsmodelle zur Nennung und Prüfung. Die Einsender werden gebeten, einen Link zum Modell, das optimale Cueing-Format und die Generierungskonfiguration sowie ihre eigenen Testergebnisse per E-Mail oder Twitter bereitzustellen. EQ-Bench Punktestand. Das Projekt wird die Ergebnisse validieren und die Rangliste aktualisieren. Da das Projekt selbstfinanziert ist und nur über begrenzte Computerressourcen verfügt, müssen die Einreicher damit rechnen, dass der Validierungsprozess einige Zeit in Anspruch nimmt.
💙 EQ-Bench 3: Bewertung der Fähigkeit zur Konfliktmediation
EQ-Bench 3 ist ein Benchmark-Test für emotionale Intelligenz, der sich auf proaktive Konfliktvermittlungsfähigkeiten konzentriert. Er bewertet die Fähigkeit von Sprachmodellen, mit komplexen emotionalen Problemen in herausfordernden und unterschiedlichen Szenarien umzugehen. Der Test sieht nicht mehr aus wie der ursprüngliche EQ-Bench Auf diese Weise werden nur emotionale Zustände vorhergesagt, aber stattdessen wird direkt die Fähigkeit des Modells untersucht, aktive emotionale Intelligenz anzuwenden.
Testmethoden.
- Struktur. Der Test besteht aus mehreren Dialogrunden (bis zu 21 Runden) zwischen dem zu testenden Modell, das als Konfliktvermittler fungiert, und einem "Akteur"-Modell (das derzeit im Einsatz ist), das die Rolle eines Kunden oder Streitpartners spielt.
gemini-2.0-flash-001) zu interagieren. Jede Szene enthält eine detaillierte Charakterisierung mit spezifischen emotionalen Zuständen und Hintergründen. - Bewertungskriterien. Die Grundlage für die Punktevergabe umfasst:
- Grundlegende Fähigkeiten im Bereich der emotionalen Intelligenz (Erkennen von Emotionen, Ausdruck von Empathie)
- Berufliche Fähigkeiten in Bezug auf Therapie oder Mediation
- Schwere berufliche Fehler vermeiden
- Betriebsmechanismen. Beim Benchmarking werden drei Modelle verwendet: das zu prüfende Modell, das Akteursmodell und das Schiedsrichtermodell (
Claude-3.7-Sonnet). Das Schiedsrichtermodell ist für die Bewertung der Leistung des zu prüfenden Modells zuständig. - Bewertung. Die endgültige Punktzahl setzt sich aus Bewertungen für mehrere Kompetenzbereiche sowie aus der Anzahl der festgestellten Fehler und deren Schweregrad zusammen. Das Schiedsrichtermodell liefert auch eine kritische Analyse spezifischer Fehler, indem es sie als geringfügig, mäßig oder schwerwiegend einstuft und so die Unzulänglichkeiten des Modells im realen beruflichen Dialog genau aufzeigt.
Das Problem der Selbstpräferenz bei der Modellierung von Schiedsrichtern.
Eine häufige Befürchtung ist, dass LLM-Beurteiler voreingenommen sein könnten und insbesondere die Ergebnisse ihrer eigenen Modelle bevorzugen. Um dieses Phänomen zu untersuchen, hat dieEQ-Bench 3 ausnutzen Claude-3.7-Sonnet im Gesang antworten gpt-4o-2024-11-20 Das Spitzenmodell wurde mit zwei Schiedsrichtermodellen verglichen.

Die Ergebnisse zeigen, dass zumindest zwischen den beiden Schiedsrichtermodellen keine eindeutige Selbstbevorzugung zu beobachten war und ihre Bewertungen nahezu identisch waren. Dies gibt ein gewisses Vertrauen in die Verwendung des LLM als Schiedsrichter, aber die Möglichkeit einer potenziellen Verzerrung muss dennoch im Auge behalten werden.
Der entsprechende Code und die vollständige Dokumentation werden in Kürze auf folgender Website verfügbar sein EQ-Bench Lagerhaus Freigabe.
💗 EQ-Bench (Legacy): Benchmarks zur Erkennung von Emotionen
frühe Generation EQ-Bench Er wurde entwickelt, um die emotionale Intelligenz von Sprachmodellen zu bewerten, die ein entscheidender Teil der Benutzererfahrung ist und von anderen Benchmarks nicht explizit getestet wurde. Sein einzigartiger Vorteil besteht darin, dass es relativ schwierig ist, die Punktzahl durch Feinabstimmung "aufzupolieren", so dass die Rangliste die wahren Fähigkeiten des Modells besser widerspiegelt.
Der Test ist so aufgebaut, dass das Modell den Dialog lesen und die Stärke der möglichen emotionalen Reaktionen einer der Figuren bewerten soll (für 4 vordefinierte Emotionen). Der Bewertungsprozess erfordert kein Eingreifen eines Referenzmodells, ist kostengünstig (nur 171 Fragen) und die Ergebnisse stimmen mit den menschlichen Präferenzen überein (Arena ELO) und Multi-Domain-Benchmarks (MMLU) zeigten eine starke Korrelation.
🧙 MAGI-Hard: Eine Untergruppe von hochschwierigen Unterscheidungstests
Angesichts der Tatsache, dass die bestehenden LLM-Benchmarks eine gesättigte Leistung aufweisen und es schwierig ist, zwischen Spitzenmodellen zu unterscheiden.MAGI-Hard vorgestellt wurde. Es ist ein Beispiel für ein Beispiel aus dem MMLU im Gesang antworten AGIEval Eine sorgfältig ausgewählte Teilmenge dieser Modelle soll die Differenzierung von Modellen mit hohem Leistungsvermögen verbessern. Entwickler können die Vorteile der bereitgestellten EleutherAI lm-evaluation-harness Verzweigung zur Ausführung MAGI Test-Sets.
🎨 Kreatives Schreiben v3: Verbesserte Bewertung des kreativen Schreibens
Der Creative Writing Benchmark hat eine neue Version 3 erhalten, die wichtige Aktualisierungen enthält:
- Neuer Tipp. Ziel ist es, besser zu differenzieren und zu prüfen, ob ein "Gefühl für Atmosphäre" vorliegt.
- Hybrides Scoring-System. Kombiniert die Rubriken und
EloBewertungssystem, das die Unterscheidungsfähigkeit des Spitzenmodells und den dynamischen Bereich des Tests erheblich verbessert. - Verbesserte Beispiel-Ausgabeseite.
Benchmarking-Prozess.
- Das Modell wurde für 3 Iterationen (insgesamt 96 Items) mit 32 Schreibaufforderungen durchgeführt, wobei die Temperatur auf 0,7 und min_p auf 0,1 gesetzt wurde.
- ausnutzen
Claude 3.7 SonnetAls Schiedsrichter werten Sie die Ergebnisse nach den umfassenden Wertungsregeln. - Ursprüngliches Inferenzmodell auf der Grundlage von Regelbewertungen
EloBewertung. - Es werden paarweise Vergleiche mit benachbarten Modellen auf der Bestenliste (sparse sampling) durchgeführt, wobei der Gewinner bis zu 5 "+" auf der Grundlage mehrerer Kriterienbewertungen erhält.
- ausnutzen
GlickoPunktesystem (geändert, um die Gewinnmarge der Anzahl der "+" zu berücksichtigen) BerechnungenEloPunkte, bis sich die Rangliste stabilisiert. - Zur Berechnung der endgültigen Rangliste wurden umfassende Vergleiche mit den fertiggestellten Nachbarmodellen angestellt
Elo.
Wertungsregeln Punkte gegen Elo-Punkte.
Es gibt zwei Arten der Bewertung. Das Regel-Scoring ist das Ergebnis der unabhängigen Bewertung der einzelnen Modellergebnisse durch einen Schiedsrichter;Elo Bei der Bewertung hingegen handelt es sich um eine relative Rangfolge, die durch direkte Gegenüberstellung von zwei Modellen erstellt wird. Der Unterschied zwischen den beiden Modellen ergibt sich aus der Art der Bewertung: Paarweise Vergleiche machen es den Richtern leichter, Nuancen zu erkennen, können aber auch zu unterschiedlichen Verzerrungen führen. Auch die Bewertungskriterien unterscheiden sich zwischen den beiden Modellen.
Standardisierung der Noten.
Zum Gegensteuern Elo Die Hinzufügung neuer Modelle zum System hat dazu geführt, dass die Gesamtpunktzahl driftet, und die Ranglisten werden DeepSeek-R1 mit einer bei 1500 verankerten Punktzahl.ministral-3b Verankert bei 200.
Benchmarking-Philosophie.
Es ist sehr schwierig, kreatives Schreiben zuverlässig und im Einklang mit menschlichen Vorlieben zu beurteilen. Die Version v3 erschwert die Beurteilung kreativen Schreibens durch die Einführung von paarweisen Vergleichen und Elo Einstufungssystem zur besseren Differenzierung. Die Aufforderungswörter werden sorgfältig ausgewählt, um die Schwächen des Modells herauszufordern und so ein steileres Bewertungsgefälle für die Richter zu schaffen. Der Test enthält Aspekte des Humors, der Romantik, des räumlichen Bewusstseins, der nicht-traditionellen Ich-Perspektive und andere Aspekte, die LLMs typischerweise nur schwer auf menschlicher Ebene erreichen können.
Kosten- und Verzerrungsabbau.
Trotz des hybriden Bewertungssystems fallen für die Durchführung einer Bewertung immer noch API-Kosten in Höhe von etwa 10 US-Dollar an. Paarweise Vergleiche brachten neue Probleme mit Verzerrungen mit sich, die das Projektteam zu entschärfen versuchte:
- Längenverzerrung. Kontrolliert durch Abschneiden der Ausgabe auf 4000 Zeichen.
- Voreingenommenheit in der Position. Die Abschwächung wird durch die Bewertung und Mittelung der Werte in beide Richtungen erreicht.
- Komplexe Redundanzverzerrung. Die Punkteskala enthält Abzüge für zu auffälliges Vokabular.
- Poetische Obskurität: Die Voreingenommenheit Das Bewertungsschema versucht, allzu poetische und unzusammenhängende Prosa zu bestrafen.
Unkontrollierte Verzerrungen.
- Selbstvorurteil. Unkontrollierte Schiedsrichter können ihre eigene Leistung begünstigen.
- Positive Voreingenommenheit. Die Richtung und die Auswirkungen sind noch nicht klar.
- Smut Bias. Die Schiedsrichter neigen dazu, Inhalte, die in Richtung Erotik gehen, hart zu bestrafen.
- Stilistische und inhaltliche Verzerrungen: Die Die Präferenzen der Schiedsrichter können sich von den Präferenzen der Benutzer oder der Menschen im Allgemeinen unterscheiden.
- Slop Bias. Die Gutachter können bestimmte Tropen oder Stile bevorzugen, die von LLM häufig verwendet werden.
Kernkriterien für gepaarte Beurteilungsaufforderungen. Authentizität der Charaktere, Spaß und Originalität, Qualität des Schreibens, Kohärenz, Befolgung der Anweisungen, Aufbau von Welt und Atmosphäre, Vermeidung von Klischees, Vermeidung von blumiger Redundanz, Vermeidung von übermäßigen Metaphern.
Beschränkungen.
Die Bewertungsergebnisse sind nur ein grober Hinweis auf die Schreibfähigkeit. Kreatives Schreiben ist in hohem Maße subjektiv, und es wird empfohlen, dass Sie sich in Verbindung mit dem Lesen von Beispielen ein eigenes Urteil bilden. Bei diesem Benchmark handelt es sich nicht um eine Bewertung für Rollenspiele (RP), es werden nicht mehrere Dialogrunden getestet, und er beschränkt sich auf das Schreiben auf Englisch.
🎨 Kreatives Schreiben (Legacy v2): alte Bewertung des kreativen Schreibens
Ältere (v2) Verwendung Claude 3.5 Sonnet fungiert als Schiedsrichter und bewertet die Fähigkeit des Modells, auf eine Reihe von Aufforderungen zu schreiben. Es führt die Metriken "Vocab Complexity" und "GPT-Slop" ein und erlaubt dem Benutzer, die Strafgewichte für beide über einen Schieberegler anzupassen. In dieser Version werden 24 Prompts anhand von Bewertungsregeln und Referenzausgaben bewertet, wobei 10 Iterationen zur Verbesserung der Stabilität durchgeführt werden. In ähnlicher Weise wird versucht, Längenverzerrungen durch die Bewertungskriterien und den Schieberegler für die Längenkontrolle abzuschwächen, aber es wird eingeräumt, dass es immer noch Verzerrungen geben kann.
⚖️ Judgemark V2: Bewertung der Kapazität der Urteilsmodellierung
Judgemark V2 Bewertet wird die Fähigkeit der Sprachmodelle, selbst als "Richter" aufzutreten, d. h. sie bewerten das kreative Schreiben nach detaillierten Regeln. numerische Punktzahl Die Fähigkeit, dies zu tun. Dieser Test ist komplexer als ein einfacher paarweiser Präferenztest, da das Schiedsrichtermodell komplexe Anweisungen verstehen, den Text analysieren und bis zu 36 Dimensionen der literarischen Qualität bewerten muss.
Wichtige Verbesserungen in Version V2.
- Eine 6-fache Erhöhung des Stichprobenumfangs verringert die laufende Varianz.
- Verfeinerte Bewertungsmetriken: Unterscheidungsmerkmale (Unterscheidung zwischen starken und schwachen Texten), Stabilität (Konsistenz der Rangfolge über mehrere Durchläufe hinweg) und Relevanz für menschliche Präferenzen.
- Es stehen rohe und kalibrierte Noten zur Verfügung: Letztere machen sie durch eine Standardisierung der Verteilung zwischen den Richtern besser vergleichbar.
- Um die Robustheit der Ergebnisse zu bewerten, wurde ein Störungsstabilitätstest (temp=0,5, top_k=3) eingeführt.
- Vereinfachte eigenständige Codebasis.
Wiederholbarkeitstests. rechts Llama-3.1-70B-instruct Es wurden zwanzig Tests durchgeführt, wobei sich zeigte, dass die Standardabweichung der Endnote bei etwa 1,0 lag, was auf eine gewisse Stabilität der Ergebnisse hindeutet.
Richterliche Aufgaben. Das Jurymodell liest kurze kreative Stücke, die von 17 verschiedenen Stufen von "Autorenmodellen" erstellt wurden, und gibt auf der Grundlage langer Aufforderungen, die sowohl positive als auch negative Kriterien enthalten, numerische Bewertungen aus (z. B. "detaillierter Charakter: 0-10", "prätentiös: 0-10", wobei letztere umso niedriger ist, je besser sie sind). 10", wobei letzterer umso niedriger ist, je besser er ist). Finale Judgemark Die Punktzahl basiert auf einer gewichteten Summe mehrerer berechneter Metriken wie Diskriminierung, Stabilität und Relevanz für menschliche Vorlieben.
Dies ist eine äußerst anspruchsvolle Aufgabe für LLM, denn sie erfordert akribische literaturkritische Fähigkeiten und die Fähigkeit, mehrdimensionale numerische Bewertungsanweisungen zu befolgen.
🎤 BuzzBench: ein Benchmark für Humoranalysen
BuzzBench Durch die Analyse britischer Musikquizsendungen Never Mind The Buzzcocks Die Fähigkeit der LLM, Humor zu verstehen, wurde bewertet, indem den Gästen der Show Witze vorgestellt wurden. Die Aufgabe bestand nicht nur darin, die Funktionsweise des Witzes zu erklären, sondern auch vorherzusagen, wie "lustig" der Witz für das Publikum und den Comedy-Autor sein würde.
Anspruchsvolle Designs.
- Die Auswahl der Programmwitze erhöhte die Schwierigkeit, LLM zu identifizieren, aufgrund ihrer Vielfalt an Stilen (subtil, abenteuerlich, plump, obskur, offensichtlich, clever).
- Die Vorhersage des "Belustigungsgrads" erfordert die Modellierung menschlicher Reaktionen.
- Verwenden Sie von Menschen geschriebene "goldene Antworten" als Maßstab für die Bewertung der Juroren.
Der Benchmark wurde entwickelt, um das theoretische mentale Verständnis und das komplexe Wissen über die Funktionsweise von Witzen zu testen. Das Modell des Schiedsrichters wurde gewählt Claude 3.5 SonnetDenn es ist in der Judgemark hoch bewerteten und offenbar eine geringere Vorliebe für langatmige, überanalysierte Antworten hatten. Auch hier muss auf die zugrundeliegenden Selbstpräferenzen der Gutachter geachtet werden.
🌍 DiploBench: Ein Rahmen zur Bewertung strategischer Verhandlungen (experimentell)
DiploBench Es ist ein Brettspiel, bei dem Strategie Diplomacy Ein experimenteller Rahmen zur Bewertung der strategischen Verhandlungsfähigkeiten von LLM. Das getestete Modell spielt Austria-Hungary (Österreich-Ungarn), eine herausfordernde Rolle, die hervorragendes Verhandlungsgeschick und strategische Planung erfordert. Die Modelle müssen mit anderen KI-Spielern kommunizieren, Allianzen schließen, Täuschungen erkennen und taktische Entscheidungen treffen.
Wesentliche Merkmale.
- Voller Druck. Mehrere Verhandlungsrunden im Vorfeld der Operation.
- Multi-intelligente Körperumgebungen. Jedes Land wird von einem unabhängigen LLM kontrolliert.
- Realistische diplomatische Simulation. Testen Sie die Fähigkeit, sich anzupassen, zu verhandeln und Täuschungen zu erkennen.
- Anspruchsvolle Eröffnung.
Austria-HungarySeine zentrale Lage macht ihn verwundbar, aber strategisch wichtig.
Das Spiel läuft über bis zu 50 Runden, mit 4 Verhandlungsrunden vor jeder Aktionsrunde. Der Rahmen testet auf einzigartige Weise die LLM-Fähigkeiten in den Bereichen langfristige strategische Planung, Multi-Intelligenz-Verhandlungen, theoretische Achtsamkeit und Täuschungserkennung.
Hinweis: Aufgrund der großen Streuung der Ergebnisse des Spieldurchlaufs ist dieDiploBench Es handelt sich noch um einen experimentellen Rahmen und die Ergebnisse sollten mit Vorsicht interpretiert werden.
Abschließende Gedanken
EQ-Bench Serie bietet ein wertvolles Instrumentarium, das die LLM-Bewertung über die traditionellen Maßstäbe hinaus auf komplexe Kompetenzdimensionen ausweitet, die den Bedürfnissen der menschlichen Interaktion besser gerecht werden. Auch wenn Herausforderungen wie die Voreingenommenheit von Schiedsrichtern und die Subjektivität der Bewertung bestehen bleiben, stellen das Design und die Weiterentwicklung dieser Benchmarks (z. B. Verbesserungen in v2, v3, explizite Diskussion von Voreingenommenheit und Versuche, diese abzuschwächen) einen wichtigen Schritt dar, um das Feld der LLM-Bewertung auf eine tiefere, nuanciertere Ebene zu bringen. Für Entwickler und Forscher bieten diese Instrumente nicht nur einen Maßstab für die Messung des Modellfortschritts, sondern weisen auch in die Richtung zukünftiger Schlüsselverbesserungen der Modellfähigkeiten: emotionale Intelligenz, Kreativität, Urteilsvermögen und effektive Kommunikation in komplexen sozialen Interaktionen.
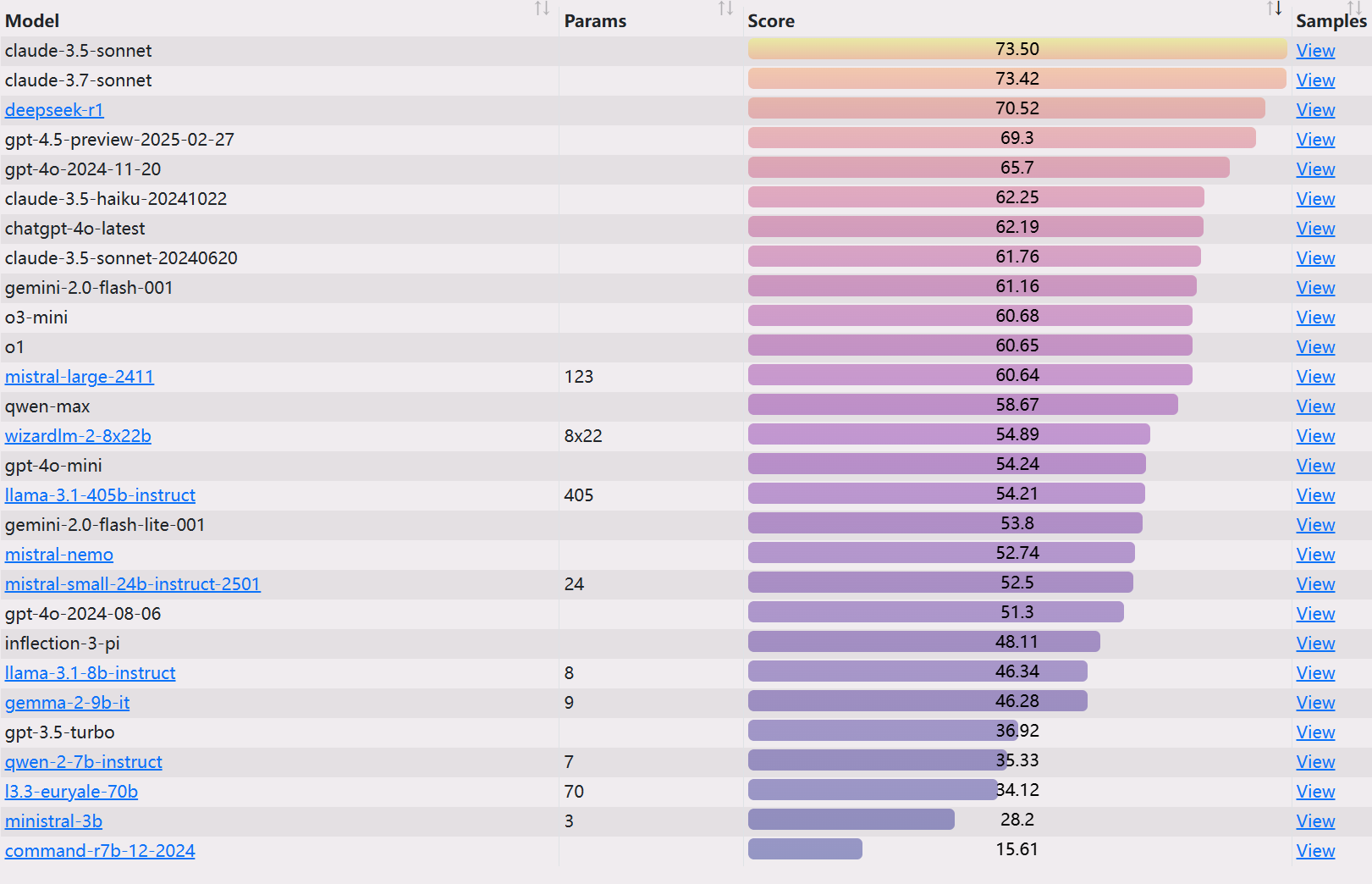
EQ-Bench 3 Rangliste
https://eqbench.com/















