Der Wettbewerb im Technologiesektor ist stets in vollem Gange. Kürzlich aktualisierte das Team des chinesischen KI-Start-ups DeepSeek sein V3-Basismodell auf unauffällige Weise und ohne großes Aufsehen. DeepSeek-V3-0324 wurde in aller Stille auf der Hugging Face-Plattform für Entwickler zum Download und zur Bereitstellung freigegeben. Trotz der geringen Bekanntheit dieses Updates haben die bedeutenden Verbesserungen des neuen Modells in Bezug auf die Code-Fähigkeit schnell ein großes Interesse und hitzige Diskussionen in der technischen Gemeinschaft ausgelöst.
Vor ein paar Stunden hat DeepSeek-AI eine aktualisierte Version von DeepSeekV3, Version 0324, veröffentlicht, die am 24. März 2025 auf HuggingFace hochgeladen und über das MIT-Protokoll zugänglich gemacht wurde.
Die Modellkonfigurationsinformationen zeigen, dass DeepSeekV3-0324 ein großes MoE-Modell bleibt, das 256 Routing-Experten und einen gemeinsamen Experten für jeden Token Verwendet 8 Experten für die Inferenz. DeepSeekV3-0324 skaliert über RoPE auf eine maximale Kontextlänge von 163840 (160K). Die Größe des Modellvokabulars beträgt 129280 und integriert den LoRA-Mechanismus zur Unterstützung einer leichten Feinabstimmung.
Keiner dieser Parameter hat sich seit der Veröffentlichung von DeepSeekV3 am 26. Dezember 2024 geändert, was bedeutet, dass diese Aktualisierung höchstwahrscheinlich das Ergebnis eines fortgesetzten Trainings oder Nachtrainings des ursprünglichen Modells ist.
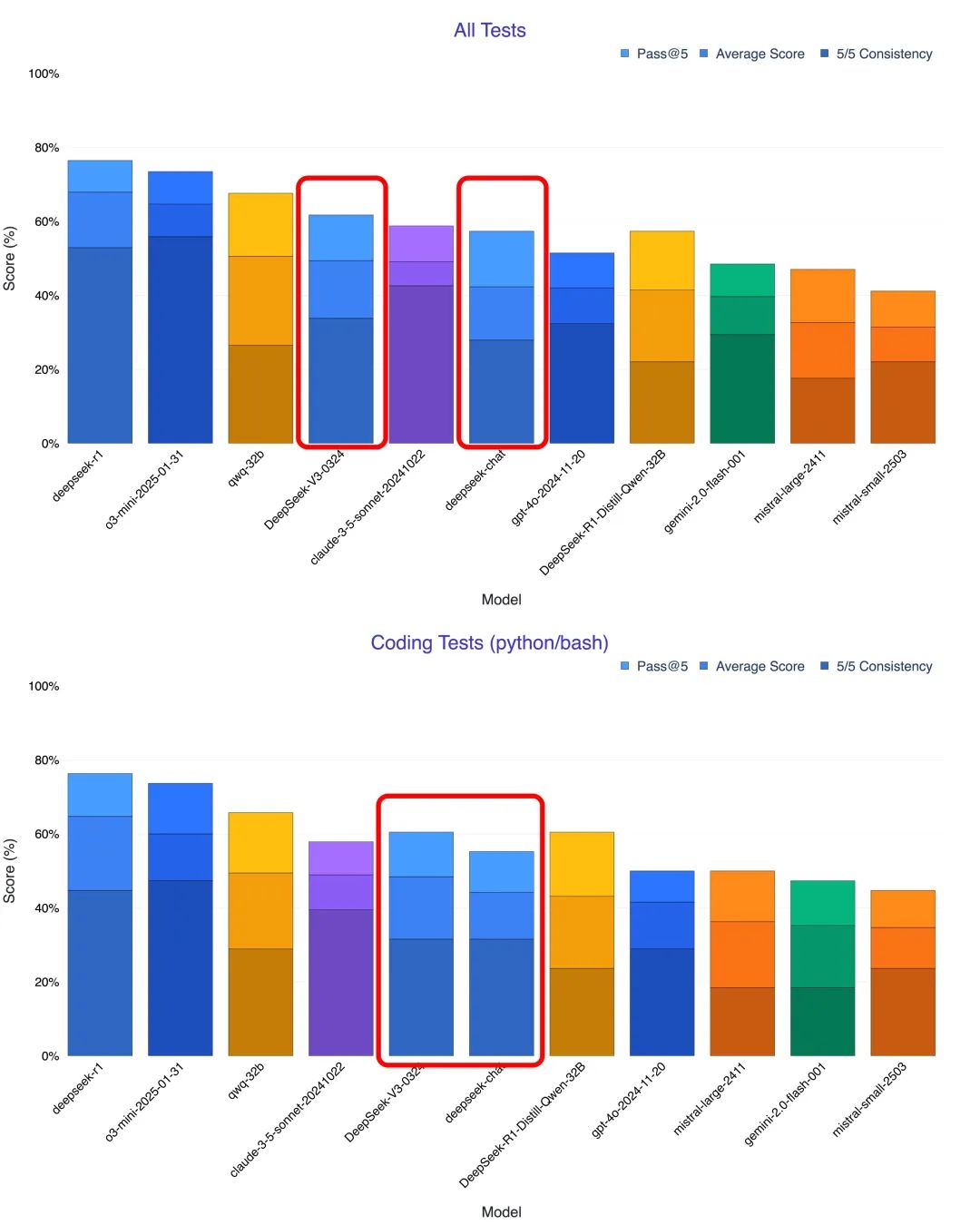
Code-Fähigkeiten auf Close-Source-Benchmarks hochgeschraubt
Erste Eindrücke von Anwendern und mehrere Tests deuten darauf hin, dass die auffallendste Verbesserung in DeepSeek-V3-0324 die Codegenerierungs- und -verstehensfähigkeiten sind. Viele Tester stellten fest, dass die neue Version in Bereichen wie mathematisches Denken und Front-End-Entwicklung sogar die Claude 3.5 und Claude 3.7 Sonnet. Der Blogger @KuittinenPetri auf der Social-Media-Plattform X war sogar noch deutlicher, als er sagte, dass DeepSeek-V3-0324 es einfach und kostenlos macht, schönen HTML5-, CSS- und Frontend-Code zu erstellen, was eine großartige Möglichkeit für die Anthropisch und OpenAI stellen neue Herausforderungen dar.
So konnte DeepSeek-V3-0324 beispielsweise mit einem einfachen Befehl eine großartig aussehende responsive Homepage für ein KI-Unternehmen namens NexusAI generieren, wobei alle Elemente in eine einzige HTML5-Datei integriert wurden. Der resultierende Code war 958 Zeilen lang und führte zu einer interaktiven und mobilfreundlichen Website, die sogar die erforderlichen Bildressourcen enthielt. Laut @KuittinenPetri ist DeepSeek-V3-0324 DeepSeek Das beste derzeit verfügbare Nicht-Inferenz-Modell ist nicht nur großartig im kreativen Schreiben, sondern ist jetzt auch noch besser bei der Generierung von HTML5 + CSS + Front-End-Code als R1. Einem anderen Nutzer gelang es, DeepSeek-V3-0324 dazu zu bringen, eine Website zu erstellen, bei der das Modell in einem Durchgang über 800 Zeilen Code generierte und das Layout der Website recht erfolgreich war.
Multi-Szenario-Praxistests, die ein starkes Programmierpotenzial zeigen
Um die Programmierfähigkeiten von DeepSeek-V3-0324 umfassender zu bewerten, haben viele Forscher Tests mit verschiedenen Szenarien durchgeführt und sie mit Modellen wie der alten V3, Claude 3.7 und o1 pro verglichen. Die Ergebnisse der Tests belegen die deutliche Verbesserung der neuen Version von V3 in Bezug auf die Programmierung.
- Text zu Visualisierungsseiten: Im Test der Umwandlung von Textbeschreibungen in interaktive Webseiten zeigt DeepSeek-V3-0324 einen Quantensprung gegenüber der alten V3-Version. Die von der neuen Version erzeugten Webseiten sind nicht nur inhaltlich reicher, sondern haben auch ein deutlich verbessertes Design und Layout der Benutzeroberfläche, das sogar das Upgrade von Claude 3.5 auf 3.7 übertrifft. Es ist erwähnenswert, dass DeepSeek-V3-0324 in der Lage ist, detaillierte Anweisungen zu befolgen, um den Inhalt einer PDF-Datei in eine schöne chinesische Visualisierung einer Webseite umzuwandeln, was oft als eine der Stärken von Claude 3.7 angesehen wird.
- Erzeugen Sie 3D-Animationen: Bei Tests zur Erstellung interaktiver 3D-Präsentationen aus der JS-Codebasis war das neue V3 in der Lage, jeden Schritt der Schokoladenherstellung zu modellieren und Interaktionen mit Registerkarten und Seitenleisten zu unterstützen. Obwohl es noch Raum für Verbesserungen gegenüber Claude gibt, übertrifft es die Fähigkeiten des alten V3 deutlich.
- Entwurf von UI-Komponenten: Im Test der UI-Komponente für die Wettervorhersage hat V3-0324 seine Animationsleistung und die Genauigkeit der Wettertextbeschriftung verbessert, was zeigt, dass es besser in der Lage ist, praktische Benutzeroberflächen zu erstellen.
- Simulation der physischen Welt: In einem Test, der einen Ball simuliert, der in einem rotierenden Sechseck aufprallt, setzt DeepSeek-V3-0324 den Ballkollisionseffekt genau um. Obwohl es noch einige Schwächen gibt, ist die Gesamtleistung besser als die alte V3 und vergleichbar mit der o1 pro.
- AI Game Generation: Besonders bemerkenswert ist, dass DeepSeek-V3-0324 ein spielbares Pixelschlangenspiel mit Soundeffekten und KI-unterstützten Modi mit nur einem Satz an Anweisungen erzeugt. Auch wenn er in Bezug auf Komplexität und Perfektion hinter dem erweiterten Denkmodus von Claude 3.7 zurückbleibt, ist die Tatsache, dass er ein voll funktionsfähiges Spiel fertigstellen konnte, ein großartiger Beweis für seine leistungsstarken Programmierfähigkeiten.
Technische Merkmale und Kostenvorteile
DeepSeek-V3-0324 hat noch keine detaillierte Modellkarte veröffentlicht, aber es ist bekannt, dass sie eine Parametergröße von 685 Milliarden hat. Es ist erwähnenswert, dass DeepSeek V3 die Hybride Expertenmodellierung (MoE) Architektur mit 671 Milliarden Parametern, von denen nur 37 Milliarden pro Schlussfolgerung aktiviert werden. (Anmerkung des Herausgebers: Das MoE-Modell reduziert die Rechenkosten und die Latenzzeit erheblich, indem es große Modelle in mehrere "Experten"-Teilnetze zerlegt und dabei die Modellleistung beibehält). Um das Problem der unausgewogenen Expertenbelastung im traditionellen MoE-Modell zu lösen, schlägt DeepSeek in V3 innovativ vor, dass Hilfsverlustfreie Lastausgleichsstrategie V3 verwendet auch einen "Bias-Term" zur dynamischen Anpassung der Expertenlast, um die Modellleistung und die Trainingseffizienz zu verbessern. Darüber hinaus übernimmt V3 auch Knotenbeschränkte Routing-Mechanismen zur Verringerung der Kommunikationskosten bei groß angelegten verteilten Schulungen.
Neben der starken Leistung setzt DeepSeek-V3-0324 das entspannte MIT-Open-Source-Protokoll fort. Noch wichtiger ist, dass seine API im Vergleich zu der von OpenAI preislich konkurrenzfähig ist o1-pro Mindestens 50 Mal billiger. Im Vergleich zu Claude 3.7 kostet DeepSeek v3 etwa ein Zehntel des Preises für den Input, während der Output-Preis etwa ein Dreizehntel des Preises während der Standardstunden und sogar ein Siebenundzwanzigstel des Preises während der Sonderstunden beträgt. Dieser attraktive Preisvorteil in Verbindung mit seinem Open-Source-Charakter wird zweifellos einen starken Anreiz für die Verbreitung und Entwicklung der KI-Programmierung bieten.
DeepSeek-V3-0324 Modellmerkmale

DeepSeek-V3-0324 weist gegenüber seinem Vorgänger DeepSeek-V3 in mehreren Schlüsselbereichen erhebliche Verbesserungen auf.
- Das logische Denkvermögen wird verbessert:
- MMLU-Pro: 75,9 → 81,2 (+5,3)
- GPQA: 59,1 → 68,4 (+9,3)
- AIME: 39,6 → 59,4 (+19,8)
- LiveCodeBench: 39,2 → 49,2 (+10,0)
- Verbesserte Front-End-Webentwicklungsfunktionen:
- Verbesserung der Code-Ausführung
- Web- und Spiele-Frontends sind ästhetisch ansprechender
- Verbesserung der chinesischen Schreibkenntnisse:
- Die Qualität von Stil und Inhalt wurde verbessert:
- Näher am R1-Schreibstil
- Höhere Qualität der mittellangen Texte
- Funktionserweiterung
- Verbesserte interaktive Mehrrunden-Umschreibefunktion
- Optimierung der Qualität von Übersetzung und Korrespondenz
- Die Qualität von Stil und Inhalt wurde verbessert:
- Verbesserung der chinesischen Suchfunktionen:
- Detailliertere Ausgabe von Anforderungen zur Berichtsanalyse
- Funktion Aufruf der Funktion verbessert:
- Funktion Aufrufen Verbesserte Genauigkeit, Behebung von Altlasten aus der Version V3
Empfehlungen für die Verwendung
System-Eingabeaufforderung
Dieselben Systemwarnungen mit spezifischen Daten werden auch in der offiziellen DeepSeek Web/App verwendet.
该助手为DeepSeek Chat,由深度求索公司创造。
今天是{current date}。
Beispiel:
该助手为DeepSeek Chat,由深度求索公司创造。
今天是3月24日,星期一。
Einstellung der Temperaturparameter
In den DeepSeek-Web- und Anwendungsumgebungen wird der Temperaturparameter (TModell) ist auf 0,3 gesetzt. Da viele Benutzer die Standardtemperatur von 1,0 in API-Aufrufen verwenden, hat DeepSeek die API-Temperatur (Tapi) Mapping-Mechanismus, der den API-Eingangstemperaturwert von 1,0 an die am besten geeignete Modelltemperatureinstellung von 0,3 anpasst.
TModell = Tapi × 0.3 (0 ≤ Tapi ≤ 1)
TModell = Tapi - 0.7 (1 < Tapi ≤ 2)
Wenn Sie also V3 über die API aufrufen, entspricht die Temperatur 1,0 der Modelltemperatur 0,3.
Aufforderungen zum Hochladen von Dateien und zur Websuche
Für das Hochladen von Dateien erstellen Sie Eingabeaufforderungen nach der folgenden Vorlage, wobei {file_name}und{file_content} im Gesang antworten {question} als Parameter.
file_template = \
"""[file name]: {file_name}
[file content begin]
{file_content}
[file content end]
{question}"""
Für Web-Suchen.{search_results}und{cur_date} im Gesang antworten {question} als Parameter.
Chinesische Abfrage Aufforderung:
search_answer_zh_template = \
'''# 以下内容是基于用户发送的消息的搜索结果:
{search_results}
在我给你的搜索结果中,每个结果都是[webpage X begin]...[webpage X end]格式的,X代表每篇文章的数字索引。请在适当的情况下在句子末尾引用上下文。请按照引用编号[citation:X]的格式在答案中对应部分引用上下文。如果一句话源自多个上下文,请列出所有相关的引用编号,例如[citation:3][citation:5],切记不要将引用集中在最后返回引用编号,而是在答案对应部分列出。
在回答时,请注意以下几点:
- 今天是{cur_date}。
- 并非搜索结果的所有内容都与用户的问题密切相关,你需要结合问题,对搜索结果进行甄别、筛选。
- 对于列举类的问题(如列举所有航班信息),尽量将答案控制在10个要点以内,并告诉用户可以查看搜索来源、获得完整信息。优先提供信息完整、最相关的列举项;如非必要,不要主动告诉用户搜索结果未提供的内容。
- 对于创作类的问题(如写论文),请务必在正文的段落中引用对应的参考编号,例如[citation:3][citation:5],不能只在文章末尾引用。你需要解读并概括用户的题目要求,选择合适的格式,充分利用搜索结果并抽取重要信息,生成符合用户要求、极具思想深度、富有创造力与专业性的答案。你的创作篇幅需要尽可能延长,对于每一个要点的论述要推测用户的意图,给出尽可能多角度的回答要点,且务必信息量大、论述详尽。
- 如果回答很长,请尽量结构化、分段落总结。如果需要分点作答,尽量控制在5个点以内,并合并相关的内容。
- 对于客观类的问答,如果问题的答案非常简短,可以适当补充一到两句相关信息,以丰富内容。
- 你需要根据用户要求和回答内容选择合适、美观的回答格式,确保可读性强。
- 你的回答应该综合多个相关网页来回答,不能重复引用一个网页。
- 除非用户要求,否则你回答的语言需要和用户提问的语言保持一致。
# 用户消息为:
{question}'''
Englische Anfrage Prompt:
search_answer_en_template = \
'''# The following contents are the search results related to the user's message:
{search_results}
In the search results I provide to you, each result is formatted as [webpage X begin]...[webpage X end], where X represents the numerical index of each article. Please cite the context at the end of the relevant sentence when appropriate. Use the citation format [citation:X] in the corresponding part of your answer. If a sentence is derived from multiple contexts, list all relevant citation numbers, such as [citation:3][citation:5]. Be sure not to cluster all citations at the end; instead, include them in the corresponding parts of the answer.
When responding, please keep the following points in mind:
- Today is {cur_date}.
- Not all content in the search results is closely related to the user's question. You need to evaluate and filter the search results based on the question.
- For listing-type questions (e.g., listing all flight information), try to limit the answer to 10 key points and inform the user that they can refer to the search sources for complete information. Prioritize providing the most complete and relevant items in the list. Avoid mentioning content not provided in the search results unless necessary.
- For creative tasks (e.g., writing an essay), ensure that references are cited within the body of the text, such as [citation:3][citation:5], rather than only at the end of the text. You need to interpret and summarize the user's requirements, choose an appropriate format, fully utilize the search results, extract key information, and generate an answer that is insightful, creative, and professional. Extend the length of your response as much as possible, addressing each point in detail and from multiple perspectives, ensuring the content is rich and thorough.
- If the response is lengthy, structure it well and summarize it in paragraphs. If a point-by-point format is needed, try to limit it to 5 points and merge related content.
- For objective Q&A, if the answer is very brief, you may add one or two related sentences to enrich the content.
- Choose an appropriate and visually appealing format for your response based on the user's requirements and the content of the answer, ensuring strong readability.
- Your answer should synthesize information from multiple relevant webpages and avoid repeatedly citing the same webpage.
- Unless the user requests otherwise, your response should be in the same language as the user's question.
# The user's message is:
{question}'''
Lokale Laufmethoden
Die Modellstruktur von DeepSeek-V3-0324 ist identisch mit DeepSeek-V3. Weitere Informationen zur lokalen Ausführung dieses Modells finden Sie auf der Seite DeepSeek-V3 Code-Repository.
Das Modell unterstützt Funktionen wie Funktionsaufrufe, JSON-Ausgabe und FIM-Vervollständigung. Anleitungen zum Erstellen von Prompts zur Verwendung dieser Funktionen finden Sie in der DeepSeek-V2.5 Code-Repository.
DeepSeek-V3-0324 ist ein unauffälliges Update, das in der Tech-Welt viel Aufmerksamkeit erregt hat. Es hat beeindruckende Fortschritte bei seinen Programmierfähigkeiten gemacht und zeigt nicht nur Stärke bei einer Reihe von Programmieraufgaben, sondern kann in mancher Hinsicht mit Spitzenmodellen wie Claude 3.5/3.7 Sonnet mithalten. Sein quelloffener, effizienter und kostengünstiger Charakter verheißt Gutes für die Zukunft. Die Ära der Universalität der KI-Programmierung könnte sich beschleunigen DeepSeek. Da immer mehr Plattformen von Drittanbietern mit der neuen V3-Version von DeepSeek verbunden werden, werden Entwickler und Nutzer gleichermaßen in der Lage sein, fortschrittliche KI-Programmierfunktionen zu geringeren Kosten zu nutzen. Dies wird zweifellos dem gesamten KI-Ökosystem neuen Schwung verleihen und das Entstehen innovativer Anwendungen fördern. Mit der leistungsstarken Code-Fähigkeit V3 und der Top-Reasoning-Fähigkeit R1 lohnt es sich, auf das zukünftige R2-Modell von DeepSeek zu warten.
Dieses Update von DeepSeekV3 beweist einmal mehr, dass sich Chinas KI-Technologie schnell entwickelt und aufholt. Die Open-Source- und kostenlose kommerzielle Lizenzierungsstrategie von DeepSeek-V3-0324 wird zweifellos mehr Entwickler und Unternehmen dazu bewegen, sich an der Entwicklung von KI-Anwendungen zu beteiligen und gemeinsam den Fortschritt und die Popularität der KI-Technologie zu fördern.